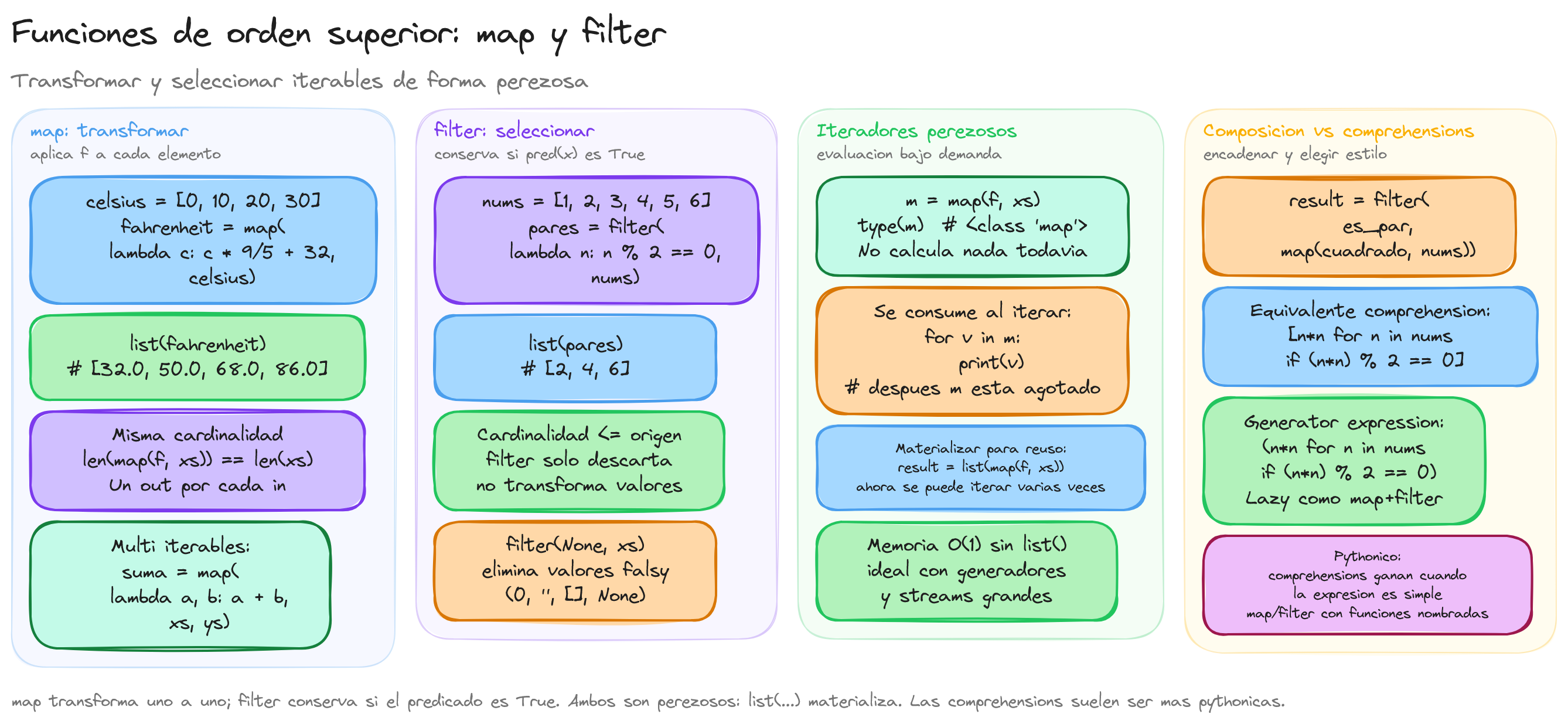
flowchart LR
Source["Iterable origen<br/>[1, 2, 3, 4, 5]"]
Source --> Map["map(f, iter)<br/>aplica f a cada elemento"]
Map -->|"f(x) = x*2"| MapOut["[2, 4, 6, 8, 10]<br/>misma cardinalidad"]
Source --> Filter["filter(p, iter)<br/>selecciona si p(x) True"]
Filter -->|"p(x) = x > 2"| FilterOut["[3, 4, 5]<br/>cardinalidad <= origen"]
MapOut --> Chain["Composición<br/>filter(par, map(cuadrado, xs))"]
FilterOut --> Chain
Chain --> Materialize["list(...) materializa<br/>iteradores perezosos"]
style Source fill:#fff3e0,stroke:#ef6c00
style Map fill:#e3f2fd,stroke:#1565c0
style Filter fill:#e8f5e9,stroke:#2e7d32
style Chain fill:#fce4ec,stroke:#ad1457
Map
La función map es una herramienta fundamental en la programación funcional con Python que permite aplicar una función a cada elemento de un iterable (como listas, tuplas o conjuntos) y devolver un nuevo iterable con los resultados. Esta función representa un enfoque declarativo para transformar datos, centrándonos en el "qué" queremos lograr en lugar del "cómo" lograrlo.
La sintaxis básica de map es:
map(func, iterable, [iterable2, iterable3, ...])
Donde:
- func es la operación que se aplicará a cada elemento
- iterable es la colección de datos a procesar
- Opcionalmente, se pueden pasar múltiples iterables si la función acepta múltiples argumentos
Características principales de map
La función map tiene varias características que la hacen especialmente útil:
- Devuelve un objeto iterable de tipo
mapque puede convertirse a otros tipos de colecciones - Es perezosa (lazy evaluation), lo que significa que no procesa los elementos hasta que se consumen
- No modifica la colección original, siguiendo los principios de la programación funcional
- Puede trabajar con cualquier tipo de función: nombradas, lambda o métodos
Uso básico de map
Veamos un ejemplo simple donde aplicamos una función a cada elemento de una lista:
# Convertir una lista de temperaturas de Celsius a Fahrenheit
celsius = [0, 10, 20, 30, 40]
# Definimos la función de conversión
def celsius_a_fahrenheit(c):
return (c * 9/5) + 32
# Aplicamos map
fahrenheit = map(celsius_a_fahrenheit, celsius)
# Convertimos el resultado a lista para visualizarlo
print(list(fahrenheit)) # [32.0, 50.0, 68.0, 86.0, 104.0]
También podemos usar una función lambda para hacer el código más conciso:
celsius = [0, 10, 20, 30, 40]
fahrenheit = map(lambda c: (c * 9/5) + 32, celsius)
print(list(fahrenheit)) # [32.0, 50.0, 68.0, 86.0, 104.0]
Trabajando con el objeto map
Es importante entender que map() devuelve un objeto iterable que se consume al recorrerlo:
numeros = [1, 2, 3, 4, 5]
cuadrados = map(lambda x: x**2, numeros)
# El objeto map se puede iterar
for cuadrado in cuadrados:
print(cuadrado) # Imprime 1, 4, 9, 16, 25
# Intentar iterar nuevamente no produce resultados
print(list(cuadrados)) # []
Si necesitas usar los resultados múltiples veces, debes convertir el objeto map a una estructura de datos como lista o tupla:
numeros = [1, 2, 3, 4, 5]
cuadrados = list(map(lambda x: x**2, numeros))
# Ahora podemos usar cuadrados múltiples veces
print(cuadrados) # [1, 4, 9, 16, 25]
print(cuadrados[0]) # 1
Map con múltiples iterables
Una característica útil de map es su capacidad para trabajar con múltiples iterables simultáneamente:
# Sumar elementos correspondientes de dos listas
lista1 = [1, 2, 3, 4]
lista2 = [10, 20, 30, 40]
sumas = map(lambda x, y: x + y, lista1, lista2)
print(list(sumas)) # [11, 22, 33, 44]
Si los iterables tienen diferentes longitudes, map se detendrá cuando llegue al final del iterable más corto:
numeros = [1, 2, 3, 4, 5]
potencias = [2, 3] # Solo dos elementos
resultados = map(lambda x, y: x**y, numeros, potencias)
print(list(resultados)) # [1, 8] - Solo procesa los dos primeros elementos
Map con funciones de la biblioteca estándar
Podemos usar map con funciones incorporadas de Python:
# Convertir una lista de cadenas a enteros
numeros_str = ["1", "2", "3", "4", "5"]
numeros_int = map(int, numeros_str)
print(list(numeros_int)) # [1, 2, 3, 4, 5]
# Obtener la longitud de cada cadena en una lista
palabras = ["Python", "es", "genial"]
longitudes = map(len, palabras)
print(list(longitudes)) # [6, 2, 6]
Map con métodos de objetos
También podemos usar map con métodos de objetos:
# Convertir todas las cadenas a mayúsculas
nombres = ["ana", "juan", "maría", "pedro"]
nombres_mayusculas = map(str.upper, nombres)
print(list(nombres_mayusculas)) # ['ANA', 'JUAN', 'MARÍA', 'PEDRO']
# Eliminar espacios en blanco al inicio y final de cada cadena
textos = [" hola ", " mundo ", " python "]
textos_limpios = map(str.strip, textos)
print(list(textos_limpios)) # ['hola', 'mundo', 'python']
Casos de uso prácticos
La función map es especialmente útil en escenarios como:
- Procesamiento de datos: transformar valores en un conjunto de datos
# Redondear todos los valores en una lista de mediciones
mediciones = [12.3456, 23.4567, 34.5678, 45.6789]
redondeados = map(lambda x: round(x, 2), mediciones)
print(list(redondeados)) # [12.35, 23.46, 34.57, 45.68]
- Conversión de tipos: cambiar el tipo de datos de elementos en una colección
# Convertir una lista mixta a sus representaciones de cadena
datos = [10, 3.14, True, "Python"]
cadenas = map(str, datos)
print(list(cadenas)) # ['10', '3.14', 'True', 'Python']
- Aplicación de fórmulas: calcular nuevos valores basados en datos existentes
# Calcular el área de varios círculos a partir de sus radios
import math
radios = [1, 2, 3, 4, 5]
areas = map(lambda r: math.pi * r**2, radios)
print(list(areas)) # [3.141592653589793, 12.566370614359172, 28.274333882308138, 50.26548245743669, 78.53981633974483]
Rendimiento y consideraciones
La función map es generalmente más eficiente que los bucles equivalentes para operaciones simples, especialmente cuando se trabaja con grandes conjuntos de datos. Esto se debe a que:
- Está implementada en C, lo que la hace más rápida que el código Python puro
- Utiliza evaluación perezosa, procesando elementos solo cuando se necesitan
- Reduce la sobrecarga de las llamadas a funciones Python
Sin embargo, para operaciones muy complejas o cuando la legibilidad es prioritaria, las comprensiones de listas pueden ser una mejor opción.
# Comparación de rendimiento (conceptual)
import time
numeros = list(range(1000000))
# Usando map
inicio = time.time()
cuadrados_map = list(map(lambda x: x**2, numeros))
fin = time.time()
print(f"Tiempo con map: {fin - inicio} segundos")
# Usando un bucle for
inicio = time.time()
cuadrados_for = []
for n in numeros:
cuadrados_for.append(n**2)
fin = time.time()
print(f"Tiempo con for: {fin - inicio} segundos")
Integración con otras funciones funcionales
La función map se combina perfectamente con otras funciones de programación funcional como filter y reduce:
from functools import reduce
# Calcular la suma de los cuadrados de los números pares
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Primero filtramos los números pares
pares = filter(lambda x: x % 2 == 0, numeros)
# Luego calculamos sus cuadrados
cuadrados = map(lambda x: x**2, pares)
# Finalmente sumamos todos los cuadrados
suma = reduce(lambda x, y: x + y, cuadrados)
print(suma) # 220 (4 + 16 + 36 + 64 + 100)
Este enfoque de encadenamiento de operaciones es muy común en la programación funcional y permite crear flujos de procesamiento de datos elegantes y expresivos.
Filter
La función filter es una herramienta esencial en la programación funcional de Python que permite seleccionar elementos de un iterable basándose en una función de prueba. A diferencia de map que transforma cada elemento, filter decide qué elementos conservar en el resultado final, eliminando aquellos que no cumplen con un criterio específico.
La sintaxis básica de filter es:
filter(func, iterable)
Donde:
- func es un predicado (función que devuelve un valor booleano) que determina si un elemento debe incluirse
- iterable es la colección de datos a filtrar
Características principales de filter
La función filter presenta varias características importantes:
- Devuelve un objeto iterable de tipo
filterque contiene solo los elementos que pasan la prueba - Implementa evaluación perezosa, procesando elementos solo cuando se consumen
- Preserva la colección original, siguiendo los principios de inmutabilidad
- Acepta
Nonecomo función, lo que filtra elementos que evalúan aFalseen un contexto booleano
Uso básico de filter
Veamos un ejemplo simple donde filtramos números pares de una lista:
# Filtrar números pares de una lista
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Definimos la función de filtrado
def es_par(numero):
return numero % 2 == 0
# Aplicamos filter
pares = filter(es_par, numeros)
# Convertimos el resultado a lista para visualizarlo
print(list(pares)) # [2, 4, 6, 8, 10]
Al igual que con map, podemos usar una función lambda para hacer el código más conciso:
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pares = filter(lambda x: x % 2 == 0, numeros)
print(list(pares)) # [2, 4, 6, 8, 10]
Trabajando con el objeto filter
Es importante entender que filter() devuelve un objeto iterable que se consume al recorrerlo:
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pares = filter(lambda x: x % 2 == 0, numeros)
# El objeto filter se puede iterar
for par in pares:
print(par) # Imprime 2, 4, 6, 8, 10
# Intentar iterar nuevamente no produce resultados
print(list(pares)) # []
Si necesitas usar los resultados múltiples veces, debes convertir el objeto filter a una estructura de datos como lista o tupla:
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pares = list(filter(lambda x: x % 2 == 0, numeros))
# Ahora podemos usar pares múltiples veces
print(pares) # [2, 4, 6, 8, 10]
print(pares[0]) # 2
Usando None como función de filtrado
Una característica interesante de filter es que podemos pasar None como función, lo que filtrará elementos que evalúan a False en un contexto booleano:
# Filtrar valores "falsy" (0, None, False, "", [], {}, etc.)
valores_mixtos = [0, 1, False, True, "", "texto", [], [1, 2], None, 42]
valores_truthy = filter(None, valores_mixtos)
print(list(valores_truthy)) # [1, True, 'texto', [1, 2], 42]
Esto es útil para eliminar rápidamente valores vacíos o nulos de una colección.
Filtrando diferentes tipos de datos
La función filter puede trabajar con cualquier tipo de iterable y cualquier tipo de datos:
Filtrando cadenas
# Filtrar palabras que comienzan con 'p'
palabras = ["python", "programación", "código", "desarrollo", "prueba"]
palabras_con_p = filter(lambda palabra: palabra.startswith('p'), palabras)
print(list(palabras_con_p)) # ['python', 'programación', 'prueba']
Filtrando diccionarios
# Filtrar productos con precio mayor a 50
productos = [
{"nombre": "Teclado", "precio": 45},
{"nombre": "Monitor", "precio": 200},
{"nombre": "Ratón", "precio": 25},
{"nombre": "Disco SSD", "precio": 80}
]
productos_caros = filter(lambda producto: producto["precio"] > 50, productos)
print(list(productos_caros))
# [{'nombre': 'Monitor', 'precio': 200}, {'nombre': 'Disco SSD', 'precio': 80}]
Filtrando objetos personalizados
class Estudiante:
def __init__(self, nombre, calificacion):
self.nombre = nombre
self.calificacion = calificacion
def __repr__(self):
return f"Estudiante({self.nombre}, {self.calificacion})"
estudiantes = [
Estudiante("Ana", 85),
Estudiante("Juan", 70),
Estudiante("María", 92),
Estudiante("Pedro", 65)
]
# Filtrar estudiantes con calificación >= 80 (aprobados con distinción)
aprobados_distincion = filter(lambda e: e.calificacion >= 80, estudiantes)
print(list(aprobados_distincion))
# [Estudiante(Ana, 85), Estudiante(María, 92)]
Casos de uso prácticos
La función filter es especialmente útil en escenarios como:
- Limpieza de datos: eliminar valores no deseados o inválidos
# Eliminar valores nulos o vacíos de una lista de datos
datos = ["valor1", None, "", "valor2", 0, "valor3", [], {}]
datos_limpios = filter(bool, datos) # bool actúa como predicado
print(list(datos_limpios)) # ['valor1', 'valor2', 'valor3']
- Validación de entradas: seleccionar solo entradas válidas
# Filtrar solo números positivos
entradas = [10, -5, 0, 15, -8, 20]
positivos = filter(lambda x: x > 0, entradas)
print(list(positivos)) # [10, 15, 20]
- Búsqueda condicional: encontrar elementos que cumplan criterios específicos
# Encontrar archivos de Python en una lista de archivos
archivos = ["documento.txt", "script.py", "imagen.jpg", "módulo.py", "datos.csv"]
archivos_python = filter(lambda f: f.endswith('.py'), archivos)
print(list(archivos_python)) # ['script.py', 'módulo.py']
Combinando filter con otras funciones
La función filter se integra perfectamente con otras funciones de programación funcional:
# Calcular la suma de los cuadrados de los números impares
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Primero filtramos los números impares
impares = filter(lambda x: x % 2 != 0, numeros)
# Luego calculamos sus cuadrados
cuadrados_impares = map(lambda x: x**2, impares)
# Convertimos a lista y sumamos
resultado = sum(cuadrados_impares)
print(resultado) # 165 (1 + 9 + 25 + 49 + 81)
Patrones comunes con filter
Existen varios patrones comunes al usar filter que vale la pena conocer:
Filtrado por tipo
# Filtrar solo elementos de un tipo específico
elementos = [1, "texto", 3.14, [1, 2], {"clave": "valor"}, 42, "python"]
solo_cadenas = filter(lambda x: isinstance(x, str), elementos)
print(list(solo_cadenas)) # ['texto', 'python']
Filtrado por rango
# Filtrar números dentro de un rango específico
temperaturas = [-5, 0, 10, 15, 25, 30, 35, 40]
temperatura_confortable = filter(lambda t: 18 <= t <= 25, temperaturas)
print(list(temperatura_confortable)) # [25]
Filtrado con múltiples condiciones
# Filtrar con múltiples condiciones (números pares mayores que 5)
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
resultado = filter(lambda x: x % 2 == 0 and x > 5, numeros)
print(list(resultado)) # [6, 8, 10]
Consideraciones de rendimiento
Al igual que map, la función filter es generalmente más eficiente que los bucles equivalentes para operaciones simples:
- Está implementada en C, lo que la hace más rápida que el código Python puro
- Utiliza evaluación perezosa, procesando elementos solo cuando se necesitan
- Reduce la sobrecarga de las llamadas a funciones Python
# Ejemplo de filtrado de una gran lista de números
import time
# Crear una lista grande
numeros = list(range(1000000))
# Usando filter
inicio = time.time()
pares_filter = list(filter(lambda x: x % 2 == 0, numeros))
fin = time.time()
print(f"Tiempo con filter: {fin - inicio} segundos")
# Usando un bucle for
inicio = time.time()
pares_for = []
for n in numeros:
if n % 2 == 0:
pares_for.append(n)
fin = time.time()
print(f"Tiempo con for: {fin - inicio} segundos")
Ejemplos avanzados
Veamos algunos ejemplos más avanzados que muestran el poder de filter:
Filtrado de datos estructurados
# Filtrar registros de una base de datos simulada
registros = [
{"id": 1, "nombre": "Ana", "activo": True, "nivel": 3},
{"id": 2, "nombre": "Juan", "activo": False, "nivel": 2},
{"id": 3, "nombre": "María", "activo": True, "nivel": 4},
{"id": 4, "nombre": "Pedro", "activo": True, "nivel": 1},
{"id": 5, "nombre": "Lucía", "activo": False, "nivel": 5}
]
# Usuarios activos con nivel >= 3
usuarios_avanzados = filter(
lambda u: u["activo"] and u["nivel"] >= 3,
registros
)
print(list(usuarios_avanzados))
# [{'id': 1, 'nombre': 'Ana', 'activo': True, 'nivel': 3},
# {'id': 3, 'nombre': 'María', 'activo': True, 'nivel': 4}]
Filtrado con funciones externas
def cumple_criterios(texto):
"""Verifica si un texto cumple con varios criterios"""
# Debe tener al menos 5 caracteres
if len(texto) < 5:
return False
# Debe contener al menos una letra mayúscula
if not any(c.isupper() for c in texto):
return False
# Debe contener al menos un número
if not any(c.isdigit() for c in texto):
return False
return True
# Lista de posibles contraseñas
contrasenas = [
"abc",
"Password",
"pass123",
"Admin2023",
"secreta",
"P4ssw0rd"
]
# Filtrar contraseñas que cumplen los criterios
contrasenas_seguras = filter(cumple_criterios, contrasenas)
print(list(contrasenas_seguras)) # ['Admin2023', 'P4ssw0rd']
Comparativa map y filter vs comprehensions
Python ofrece múltiples enfoques para transformar y filtrar datos. Mientras que map y filter representan el paradigma de programación funcional, las comprehensions (comprensiones) son una característica distintiva de Python que proporciona una sintaxis más concisa y expresiva para realizar operaciones similares.
Equivalencias básicas
Para entender mejor las diferencias, veamos cómo se traducen las mismas operaciones entre estos enfoques:
Transformación de datos (map vs list comprehensión)
# Usando map
numeros = [1, 2, 3, 4, 5]
cuadrados_map = list(map(lambda x: x**2, numeros))
# Usando list comprehension
cuadrados_comp = [x**2 for x in numeros]
print(cuadrados_map) # [1, 4, 9, 16, 25]
print(cuadrados_comp) # [1, 4, 9, 16, 25]
Filtrado de datos (filter vs list comprehensión)
# Usando filter
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pares_filter = list(filter(lambda x: x % 2 == 0, numeros))
# Usando list comprehension
pares_comp = [x for x in numeros if x % 2 == 0]
print(pares_filter) # [2, 4, 6, 8, 10]
print(pares_comp) # [2, 4, 6, 8, 10]
Combinando transformación y filtrado
# Usando filter y map
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
cuadrados_pares = list(map(lambda x: x**2, filter(lambda x: x % 2 == 0, numeros)))
# Usando list comprehension
cuadrados_pares_comp = [x**2 for x in numeros if x % 2 == 0]
print(cuadrados_pares) # [4, 16, 36, 64, 100]
print(cuadrados_pares_comp) # [4, 16, 36, 64, 100]
Ventajas de las comprehensions
Las comprehensions ofrecen varias ventajas sobre map y filter:
- Legibilidad: La sintaxis de las comprehensions suele ser más intuitiva y fácil de leer, especialmente para programadores que vienen de lenguajes no funcionales.
# Comparación de legibilidad
# map y filter encadenados
resultado = list(map(lambda x: x*2,
filter(lambda x: x > 5,
filter(lambda x: x % 2 == 0, range(20)))))
# Equivalente con list comprehension
resultado_comp = [x*2 for x in range(20) if x % 2 == 0 if x > 5]
print(resultado) # [12, 16, 20, 24, 28, 32, 36]
print(resultado_comp) # [12, 16, 20, 24, 28, 32, 36]
-
Expresividad: Las comprehensions permiten expresar operaciones complejas de manera más concisa y directa.
-
Versatilidad: Existen comprehensions para diferentes estructuras de datos:
# List comprehension (listas)
numeros = [1, 2, 3, 4, 5]
cuadrados = [x**2 for x in numeros]
print(cuadrados) # [1, 4, 9, 16, 25]
# Dict comprehension (diccionarios)
cuadrados_dict = {x: x**2 for x in numeros}
print(cuadrados_dict) # {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
# Set comprehension (conjuntos)
cuadrados_set = {x**2 for x in numeros}
print(cuadrados_set) # {1, 4, 9, 16, 25}
- Rendimiento: En muchos casos, las comprehensions son ligeramente más eficientes que sus equivalentes funcionales.
import timeit
# Comparación de rendimiento para una operación simple
setup = "numeros = list(range(1000))"
tiempo_map = timeit.timeit(
"list(map(lambda x: x**2, numeros))",
setup=setup,
number=10000
)
tiempo_comp = timeit.timeit(
"[x**2 for x in numeros]",
setup=setup,
number=10000
)
print(f"Tiempo con map: {tiempo_map:.6f} segundos")
print(f"Tiempo con comprehension: {tiempo_comp:.6f} segundos")
Ventajas de map y filter
A pesar de las ventajas de las comprehensions, map y filter tienen sus propios puntos fuertes:
- Evaluación perezosa: Los objetos
mapyfilterson iteradores que evalúan elementos bajo demanda, lo que puede ser más eficiente para conjuntos de datos grandes cuando no necesitas procesar todos los elementos inmediatamente.
# map es perezoso (no procesa hasta que se consume)
numeros = range(10**8) # Rango muy grande
cuadrados = map(lambda x: x**2, numeros)
# Solo calculamos los primeros 5 elementos
for i, valor in enumerate(cuadrados):
print(valor)
if i >= 4: # Después del quinto elemento
break
# Imprime: 0, 1, 4, 9, 16
-
Compatibilidad con programación funcional: Para quienes prefieren un estilo de programación funcional más puro o vienen de otros lenguajes funcionales.
-
Flexibilidad con funciones complejas: Cuando la función a aplicar es compleja o ya está definida,
mapyfilterpueden ser más claros.
def es_primo(n):
"""Verifica si un número es primo"""
if n < 2:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
# Usando filter con una función compleja
numeros = range(1, 100)
primos_filter = list(filter(es_primo, numeros))
# Equivalente con comprehension
primos_comp = [n for n in numeros if es_primo(n)]
print(primos_filter[:5]) # [2, 3, 5, 7, 11]
print(primos_comp[:5]) # [2, 3, 5, 7, 11]
Casos de uso específicos
Existen situaciones donde uno de los enfoques puede ser claramente superior:
Cuando preferir comprehensions
- Operaciones simples donde la legibilidad es prioritaria:
# Extraer la primera letra de cada palabra
palabras = ["Python", "es", "un", "lenguaje", "util"]
# Más legible con comprehension
primeras_letras = [palabra[0] for palabra in palabras]
print(primeras_letras) # ['P', 'e', 'u', 'l', 'p']
- Transformaciones que incluyen condiciones complejas:
# Clasificar números según múltiples condiciones
numeros = range(1, 11)
clasificados = ["par" if x % 2 == 0 else "impar" if x % 3 != 0 else "múltiplo de 3" for x in numeros]
print(clasificados)
# ['impar', 'par', 'múltiplo de 3', 'par', 'impar', 'par', 'impar', 'par', 'múltiplo de 3', 'par']
- Creación de estructuras de datos complejas:
# Crear una matriz (lista de listas)
matriz = [[i*j for j in range(1, 6)] for i in range(1, 6)]
for fila in matriz:
print(fila)
# [1, 2, 3, 4, 5]
# [2, 4, 6, 8, 10]
# [3, 6, 9, 12, 15]
# [4, 8, 12, 16, 20]
# [5, 10, 15, 20, 25]
Cuando preferir map y filter
- Cuando trabajas con funciones ya definidas que no quieres reescribir:
import math
# Lista de números
numeros = [4, 9, 16, 25, 36]
# Calcular raíz cuadrada usando la función math.sqrt
raices = list(map(math.sqrt, numeros))
print(raices) # [2.0, 3.0, 4.0, 5.0, 6.0]
- Cuando necesitas aplicar la misma operación a múltiples iterables:
# Sumar elementos correspondientes de tres listas
a = [1, 2, 3, 4]
b = [10, 20, 30, 40]
c = [100, 200, 300, 400]
# map puede trabajar con múltiples iterables
sumas = list(map(lambda x, y, z: x + y + z, a, b, c))
print(sumas) # [111, 222, 333, 444]
# Esto requeriría zip con comprehension
sumas_comp = [x + y + z for x, y, z in zip(a, b, c)]
print(sumas_comp) # [111, 222, 333, 444]
- Cuando necesitas procesamiento perezoso para conjuntos de datos muy grandes:
# Procesamiento de un archivo grande línea por línea
def procesar_linea(linea):
return linea.strip().upper()
# Con map (procesamiento perezoso)
with open('archivo_grande.txt', 'r') as f:
lineas_procesadas = map(procesar_linea, f)
# Las líneas se procesan una a una al iterar
for i, linea in enumerate(lineas_procesadas):
print(f"Línea {i+1}: {linea[:20]}...") # Muestra solo los primeros 20 caracteres
if i >= 4: # Procesar solo 5 líneas como ejemplo
break
Patrones idiomáticos en Python
En la comunidad Python, existen ciertas convenciones sobre cuándo usar cada enfoque:
-
Preferir comprehensions para operaciones simples y cuando la legibilidad es prioritaria.
-
Usar
mapyfiltercuando se trabaja con funciones existentes o cuando se necesita evaluación perezosa. -
Evitar anidar demasiadas funciones
mapyfilter, ya que puede reducir la legibilidad.
# Evitar esto (difícil de leer)
resultado = list(map(lambda x: x**2,
filter(lambda x: x % 2 == 0,
map(lambda x: x + 1, range(10)))))
# Preferir esto
resultado = [x**2 for x in range(10) if (x + 1) % 2 == 0]
# O dividir en pasos si es necesario
paso1 = [x + 1 for x in range(10)]
paso2 = [x for x in paso1 if x % 2 == 0]
resultado = [x**2 for x in paso2]
Consideraciones de estilo y PEP 8
El PEP 8 (la guía de estilo oficial de Python) no establece una preferencia explícita entre comprehensions y funciones como map y filter. Sin embargo, recomienda:
- Mantener la legibilidad como prioridad
- Evitar líneas demasiado largas (máximo 79 caracteres)
- Ser consistente con el estilo elegido en todo el código
# Si una comprehension es demasiado larga, divídela en múltiples líneas
resultado = [
x**2
for x in range(100)
if x % 2 == 0
if x % 5 == 0
]
# O usa variables intermedias para mayor claridad
numeros = range(100)
multiplos_10 = [x for x in numeros if x % 2 == 0 and x % 5 == 0]
resultado = [x**2 for x in multiplos_10]
Resumen comparativo
| Característica | map/filter | Comprehensions | |----------------|------------|----------------| | Sintaxis | Funcional | Expresiva y declarativa | | Legibilidad | Puede ser compleja con anidamiento | Generalmente más legible | | Evaluación | Perezosa (bajo demanda) | Inmediata (genera toda la colección) | | Eficiencia | Buena para operaciones simples | Ligeramente mejor en la mayoría de casos | | Versatilidad | Solo genera iteradores | Puede crear listas, diccionarios y conjuntos | | Múltiples iterables | Soportado directamente | Requiere zip o funciones adicionales | | Funciones complejas | Más claro con funciones predefinidas | Puede volverse confuso |
La elección entre map/filter y comprehensions depende del contexto específico, el estilo de programación preferido y los requisitos del proyecto. En la práctica, muchos programadores Python utilizan ambos enfoques según la situación, aprovechando las fortalezas de cada uno para escribir código más elegante y eficiente.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en Python
Documentación oficial de Python
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Python es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Python
Explora más contenido relacionado con Python y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el funcionamiento y sintaxis de la función map para transformar elementos de iterables. Aprender a usar filter para seleccionar elementos que cumplen una condición. Conocer las características de evaluación perezosa y objetos iterables que devuelven map y filter. Aplicar map y filter en casos prácticos y combinarlos con otras funciones funcionales. Comparar map y filter con las comprehensions de Python, entendiendo ventajas y casos de uso de cada enfoque.