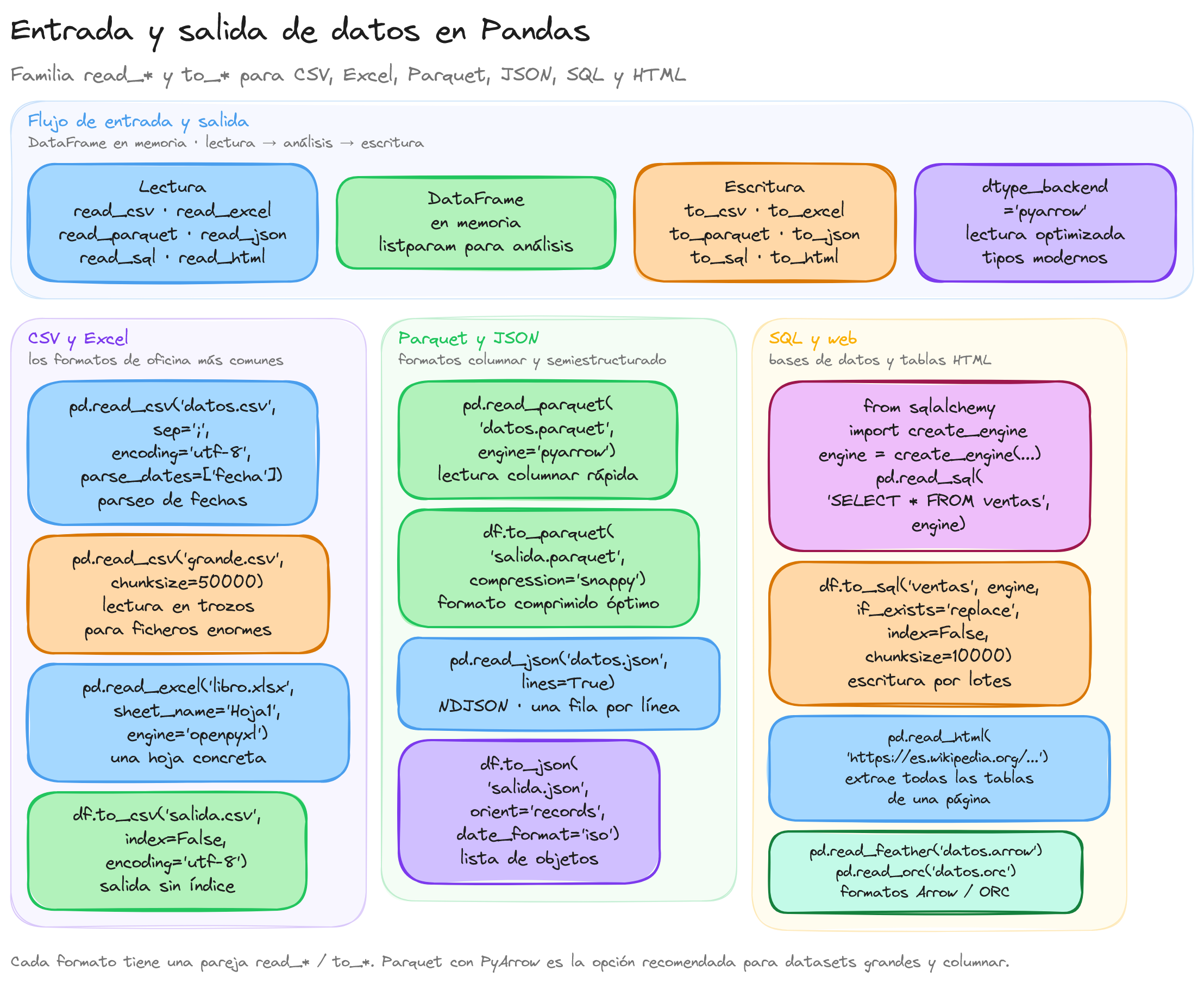
Formas de cargar datos externos en Pandas
Pandas proporciona múltiples métodos para cargar datos externos en un DataFrame.
A continuación, se detallan las formas más comunes y recomendadas según la documentación oficial de Pandas:
graph TB
SRC[Fuentes externas] -->|read_csv| CSV[Archivos CSV]
SRC -->|read_excel| XLS[Archivos Excel xlsx]
SRC -->|read_parquet| PAR[Apache Parquet columnar]
SRC -->|read_json| JSN["JSON / JSONL"]
SRC -->|read_sql| SQL[Bases de datos SQLAlchemy]
SRC -->|read_html| HTM[Tablas HTML web]
SRC -->|read_feather| FT[Feather Arrow]
SRC --> DF[DataFrame en memoria]
DF -->|to_csv| OUT1[Salida CSV]
DF -->|to_parquet| OUT2[Salida Parquet]
DF -->|to_sql| OUT3[Tabla SQL]
DF -->|to_excel| OUT4[Excel]
1.- Cargar datos desde un archivo CSV: Pandas incluye la función read_csv() para leer archivos CSV. Es posible especificar parámetros como el delimitador, la codificación, las columnas a utilizar, entre otros.
import pandas as pd
df = pd.read_csv('ruta/al/archivo.csv', delimiter=',', encoding='utf-8')
Para obtener tipos de datos optimizados basados en PyArrow, se puede utilizar el parámetro dtype_backend:
df = pd.read_csv('ruta/al/archivo.csv', dtype_backend='pyarrow')
Al leer un archivo CSV que contiene caracteres especiales, el parámetro encoding de la función read_csv() permite especificar la codificación de caracteres, garantizando así una correcta interpretación de los datos. Algunas codificaciones comunes son:
'utf-8': Codificación universal que soporta la mayoría de los caracteres.'latin-1': También conocida como ISO-8859-1, es común en archivos generados en sistemas europeos.'ascii': Codificación básica que solo soporta caracteres en inglés.'windows-1252': Codificación de Windows utilizada en documentos de Microsoft.
2.- Cargar datos desde un archivo Excel: Con read_excel(), Pandas permite leer datos desde archivos Excel. Es posible seleccionar hojas específicas y manejar diferentes formatos de archivo (xls, xlsx). Es posible seleccionar hojas específicas utilizando el parámetro sheet_name, el cual acepta tanto el nombre de la hoja (como una cadena de texto) como su índice (un número entero donde 0 es la primera hoja). Si un archivo Excel contiene múltiples hojas, puedes cargar varias hojas al mismo tiempo especificando una lista de nombres de hojas o utilizar el valor None para cargar todas las hojas en un diccionario de DataFrames.
df = pd.read_excel('ruta/al/archivo.xlsx', sheet_name='Hoja1')
Parámetros clave de read_excel():
sheet_name: Permite especificar qué hoja del archivo Excel cargar. Puedes pasar:- El nombre de la hoja (como una cadena).
- El índice de la hoja (como un entero, donde
0es la primera hoja). - Una lista de hojas para cargar varias hojas a la vez.
- None para cargar todas las hojas en un diccionario de DataFrames.
df = pd.read_excel('ruta/al/archivo.xlsx', sheet_name=None)
usecols: Selecciona columnas específicas al leer el archivo Excel.
df = pd.read_excel('ruta/al/archivo.xlsx', usecols='A:C')
engine: Específica el motor de lectura. El motorcalaminees una alternativa más rápida para leer archivos Excel, especialmente con archivos grandes.
df = pd.read_excel('ruta/al/archivo.xlsx', engine='calamine')
3.- Cargar datos desde una base de datos SQL: Pandas ofrece la función read_sql() para ejecutar consultas SQL directamente y cargar los resultados en un DataFrame. Es necesario tener una conexión establecida con la base de datos.
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://usuario:contraseña@localhost/nombre_base_datos')
df = pd.read_sql('SELECT * FROM tabla', con=engine)
Parámetros clave de read_sql():
sql: Consulta SQL a ejecutar. Puede ser un comando SQL en formato de cadena o un objeto SQL.con: Conexión a la base de datos.index_col: Define una columna específica para usarla como índice del DataFrame.
df = pd.read_sql('SELECT * FROM tabla', con=engine, index_col='id')
Pandas soporta también conexiones ADBC (Apache Arrow Database Connectivity) como alternativa a SQLAlchemy. Las conexiones ADBC ofrecen mejor rendimiento al devolver los datos directamente en formato Arrow, evitando conversiones intermedias.
import adbc_driver_postgresql.dbapi
with adbc_driver_postgresql.dbapi.connect('postgresql://localhost/nombre_base_datos') as conn:
df = pd.read_sql('SELECT * FROM tabla', con=conn)
4.- Cargar datos desde un archivo JSON: La función read_json() permite cargar datos desde un archivo JSON. Es posible especificar el tipo de orientación de los datos, como 'records' o 'index'. La orientación por defecto es 'records', que organiza los datos como una lista de registros.
df = pd.read_json('ruta/al/archivo.json', orient='records')
Parámetros clave de read_json():
orient:Define cómo se organizan los datos. Las opciones comunes son:'records'o'index'.lines: Si está enTrue, espera que el archivo JSON tenga un objeto por línea, útil para archivos de gran tamaño.
df = pd.read_json('ruta/al/archivo.json', lines=True)
5.- Cargar datos desde un archivo Parquet: Con read_parquet(), Pandas facilita la lectura de archivos Parquet, que son eficientes en términos de almacenamiento y velocidad de lectura.
df = pd.read_parquet('ruta/al/archivo.parquet')
Parámetros clave de read_parquet():
columns: Específica las columnas a cargar del archivo Parquet.
df = pd.read_parquet('ruta/al/archivo.parquet', columns=['columna1', 'columna2'])
engine: Específica el motor a utilizar para leer el archivo (opciones:'auto','pyarrow','fastparquet').
df = pd.read_parquet('ruta/al/archivo.parquet', engine='pyarrow')
filters: Filtra las filas que cumplen condiciones específicas (disponible conpyarrow).
df = pd.read_parquet('ruta/al/archivo.parquet', filters=[('columna', '=', 'valor')])
dtype_backend: Específica el backend de tipos de datos para las columnas cargadas. Las opciones son'numpy_nullable'y'pyarrow'. El backendpyarrowofrece mejor rendimiento y soporte nativo de nulos.
df = pd.read_parquet('ruta/al/archivo.parquet', dtype_backend='pyarrow')
6.- Cargar datos desde una API web: Pandas puede manejar la respuesta de una API web utilizando la biblioteca requests. Los datos JSON obtenidos pueden ser convertidos en un DataFrame.
import requests
response = requests.get('https://api.ejemplo.com/data')
data_json = response.json()
df = pd.DataFrame(data_json)
Parámetros clave:
timeout: Tiempo de espera para la respuesta de la API, evitando bloqueos por respuestas lentas.
response = requests.get('https://api.ejemplo.com/data', timeout=5)
7.- Cargar datos desde una tabla HTML: Utilizando read_html(), Pandas puede extraer tablas de datos directamente desde una página web. Esta función devuelve una lista de DataFrames, uno por cada tabla encontrada.
url = 'https://www.ejemplo.com/tables.html'
dfs = pd.read_html(url)
df = dfs[0] # Asumiendo que se necesita la primera tabla
Parámetros clave de read_html():
match: Permite buscar tablas en función de un patrón de coincidencia en el contenido de la tabla.
dfs = pd.read_html(url, match='Nombre de la tabla')
Cada uno de estos métodos ofrece múltiples parámetros adicionales para personalizar la carga de datos según las necesidades específicas del proyecto. La elección del método adecuado depende del formato de los datos de origen y de los requisitos de procesamiento posteriores.
Formas de exportar un DataFrame
Pandas proporciona diversas funcionalidades para exportar un DataFrame a diferentes formatos de archivo, lo que facilita la integración con otras aplicaciones y sistemas. A continuación, se describen las formas más comunes y recomendadas para exportar un DataFrame según la documentación oficial de Pandas:
1.- Exportar a un archivo CSV: Utilizando la función to_csv(), se puede exportar un DataFrame a un archivo CSV. Es posible especificar parámetros como el delimitador, la codificación y si se desea incluir el índice. Por defecto, Pandas exporta el índice del DataFrame, pero si no deseas incluirlo en el archivo, debes establecer el parámetro index en False.
import pandas as pd
# Crear un DataFrame de ejemplo
df = pd.DataFrame({
'Columna1': [1, 2, 3],
'Columna2': ['A', 'B', 'C']
})
# Exportar a CSV sin incluir el índice
df.to_csv('ruta/al/archivo.csv', sep=',', encoding='utf-8', index=False)
Parámetros clave de to_csv():
sep: Define el delimitador para separar las columnas en el archivo (por defecto,).encoding: Define la codificación de caracteres a utilizar (ej.:'utf-8','latin-1').index: Indica si se debe exportar el índice o no (por defectoTrue).header: Si se establece enFalse, no exporta los nombres de las columnas.
df.to_csv('ruta/al/archivo.csv', sep=',', encoding='utf-8', index=False, header=False)
2.- Exportar a un archivo Excel: La función to_excel() permite exportar un DataFrame a un archivo Excel. Se pueden especificar la hoja de destino y otros parámetros como la inclusión del índice.
# Exportar a Excel
df.to_excel('ruta/al/archivo.xlsx', sheet_name='Hoja1', index=False)
Parámetros clave de to_excel():
sheet_name: Define el nombre de la hoja en el archivo Excel (por defecto es'Sheet1').index: Excluye el índice si se establece enFalse.startrowystartcol: Permiten definir en qué fila y columna comenzarán los datos en la hoja de cálculo.
df.to_excel('ruta/al/archivo.xlsx', startrow=2, startcol=1, index=False)
Nota: Para exportar archivos en formato .xlsx, es necesario tener instalada la librería openpyxl.
3.- Exportar a una base de datos SQL: Con to_sql(), es posible escribir un DataFrame en una tabla de una base de datos SQL. Es necesario establecer una conexión con la base de datos.
from sqlalchemy import create_engine
# Crear una conexión a la base de datos
engine = create_engine('mysql+pymysql://usuario:contraseña@localhost/nombre_base_datos')
# Exportar a SQL
df.to_sql('nombre_tabla', con=engine, if_exists='replace', index=False)
Parámetros clave de to_sql():
con: Conexión a la base de datos.if_exists: Controla el comportamiento si la tabla ya existe. Opciones:'fail': Lanza un error si la tabla existe.'replace': Borra la tabla existente y la reemplaza.'append': Agrega los datos a la tabla existente.
index: Indica si se debe exportar el índice del DataFrame o no.
4.- Exportar a un archivo JSON: Utilizando la función to_json(), se puede exportar un DataFrame a un archivo JSON. Es posible especificar la orientación de los datos, como 'records' o 'index'.
# Exportar a JSON
df.to_json('ruta/al/archivo.json', orient='records')
Parámetros clave de to_json():
orient: Define la forma de organizar los datos. Opciones comunes:'split','records','index','columns','values'.
lines: Si está enTrue, los objetos JSON se guardan línea por línea, útil para grandes volúmenes de datos.
df.to_json('ruta/al/archivo.json', orient='records', lines=True)
5.- Exportar a un archivo Parquet: La función to_parquet() permite exportar un DataFrame a un archivo Parquet, que es eficiente en términos de almacenamiento y velocidad de lectura.
# Exportar a Parquet
df.to_parquet('ruta/al/archivo.parquet')
Parámetros clave de to_parquet():
engine: Específica el motor a usar para escribir el archivo. Las opciones comunes son'auto','pyarrow', y'fastparquet'.compressión: Permite definir el tipo de compresión, como'snappy','gzip', o'brotli'.
df.to_parquet('ruta/al/archivo.parquet', compression='snappy')
6.- Exportar a HTML: Con to_html(), se puede convertir un DataFrame en una tabla HTML, lo que facilita la visualización de datos en páginas web.
# Exportar a HTML
df.to_html('ruta/al/archivo.html', index=False)
Parámetros clave de to_html():
index: Excluye el índice del DataFrame si se establece enFalse.border: Define el tamaño del borde de la tabla en la página HTML.
df.to_html('ruta/al/archivo.html', index=False, border=0)
7.- Exportar a un archivo HDF5: Utilizando la función to_hdf(), es posible exportar un DataFrame a un archivo HDF5, adecuado para grandes volúmenes de datos.
# Exportar a HDF5
df.to_hdf('ruta/al/archivo.h5', key='df', mode='w')
Parámetros clave de to_hdf():
key: Nombre del objeto en el archivo HDF5 bajo el cual se almacenarán los datos.mode: Modo de apertura del archivo. Opciones:'r': Solo lectura.'w': Escritura, borra el contenido existente.'a': Lectura y escritura sin borrar el contenido existente.
Nota: Es necesario tener instalada la librería PyTables para trabajar con archivos HDF5.
Cada uno de estos métodos ofrece múltiples parámetros adicionales para personalizar la exportación de datos según las necesidades específicas del proyecto. La elección del método adecuado depende del formato de destino y de los requisitos de integración con otras herramientas y sistemas.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Pandas es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Pandas
Explora más contenido relacionado con Pandas y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Cargar datos desde archivos CSV en Pandas. Leer datos desde archivos Excel. Conectar y extraer datos desde bases de datos SQL. Cargar datos desde archivos JSON y Parquet. Obtener datos desde APIs web y tablas HTML. Exportar DataFrames a múltiples formatos como CSV, Excel, SQL, JSON, Parquet, HTML y HDF5. Configurar parámetros adicionales para la personalización de carga y exportación de datos.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje