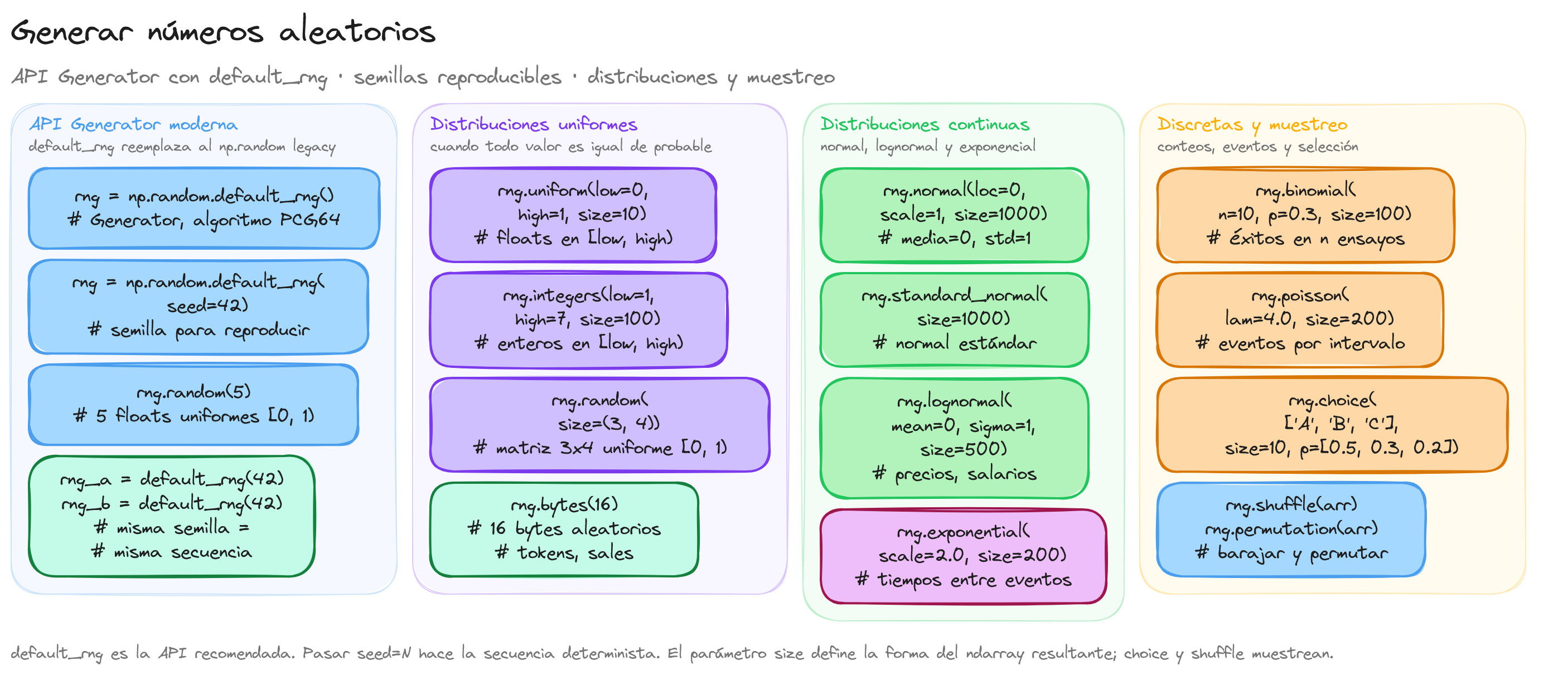
La API Generator y default_rng
NumPy proporciona una API moderna para la generación de números aleatorios basada en la clase Generator. Esta API se crea mediante la función np.random.default_rng() y constituye el mecanismo recomendado frente al módulo legacy np.random.
import numpy as np
# Crear un generador aleatorio
rng = np.random.default_rng()
# Generar 5 números aleatorios entre 0 y 1
valores = rng.random(5)
print(valores)
La función default_rng devuelve un objeto Generator que encapsula un algoritmo generador de bits (por defecto PCG64). Este diseño separa la generación de bits de la producción de distribuciones estadísticas, lo que mejora la calidad de las secuencias generadas.
Semillas para reproducibilidad
En ciencia de datos y experimentación es fundamental obtener resultados reproducibles. Pasar un entero como semilla a default_rng garantiza que la secuencia generada sea siempre la misma.
rng = np.random.default_rng(seed=42)
# Estas líneas producirán siempre los mismos valores
a = rng.random(3)
b = rng.integers(0, 100, size=5)
print(a) # [0.77395605 0.43887844 0.85859792]
print(b) # [Valores fijos con seed=42]
Cada llamada al generador avanza el estado interno, por lo que el orden de las llamadas importa. Para obtener la misma secuencia hay que crear un generador nuevo con la misma semilla.
# Dos generadores con la misma semilla producen la misma secuencia
rng1 = np.random.default_rng(seed=100)
rng2 = np.random.default_rng(seed=100)
print(rng1.random(3)) # Idéntico a rng2.random(3)
print(rng2.random(3))
La API Generator con
default_rnges el estándar recomendado en NumPy. Ofrece mejor calidad estadística, un diseño más limpio y es segura para uso en hilos independientes.
Distribuciones de probabilidad
El objeto Generator incluye métodos para generar muestras de las distribuciones estadísticas más utilizadas. Cada método acepta parámetros específicos de la distribución y un argumento size que define la forma del array resultante.
Distribución uniforme
Genera valores con igual probabilidad dentro de un rango. Se utiliza rng.uniform para valores continuos y rng.integers para enteros.
rng = np.random.default_rng(seed=0)
# Valores continuos entre 10 y 20
uniformes = rng.uniform(low=10, high=20, size=6)
print(uniformes)
# Enteros entre 1 y 6 (simular dado)
dados = rng.integers(low=1, high=7, size=10)
print(dados)
Distribución normal (gaussiana)
La distribución normal es la más común en estadística y modelado. Se parametriza con la media ($\mu$) y la desviación estándar ($\sigma$).
rng = np.random.default_rng(seed=1)
# Alturas de 1000 personas: media 170 cm, desviación 8 cm
alturas = rng.normal(loc=170, scale=8, size=1000)
print(f"Media: {np.mean(alturas):.2f}")
print(f"Desv. std: {np.std(alturas):.2f}")
La distribución normal estándar ($\mu=0$, $\sigma=1$) se obtiene con rng.standard_normal:
# 5 valores de la normal estándar
z = rng.standard_normal(5)
print(z)
Distribución binomial
Modela el número de éxitos en una serie de ensayos independientes, cada uno con probabilidad de éxito $p$.
rng = np.random.default_rng(seed=2)
# 10 ensayos con probabilidad 0.3, repetido 8 veces
exitos = rng.binomial(n=10, p=0.3, size=8)
print(exitos) # Valores entre 0 y 10
Un caso de uso frecuente es simular el número de clics en un anuncio mostrado a un grupo de usuarios.
# Simular clics: 500 impresiones con tasa de clic del 2%
clics = rng.binomial(n=500, p=0.02, size=30)
print(f"Clics promedio: {np.mean(clics):.1f}")
Distribución de Poisson
Modela el número de eventos que ocurren en un intervalo fijo, dado un promedio conocido $\lambda$.
rng = np.random.default_rng(seed=3)
# Llamadas a un call center: promedio 12 llamadas por hora
llamadas = rng.poisson(lam=12, size=24)
print("Llamadas por hora:", llamadas)
print(f"Total del día: {np.sum(llamadas)}")
Las distribuciones normal y uniforme son las más habituales en la generación de datos sintéticos. La binomial y la de Poisson se aplican en modelos de conteo y ensayos repetidos.
Muestreo: choice, shuffle y permutation
Además de generar valores desde distribuciones, el objeto Generator incluye métodos de muestreo que operan sobre arrays existentes.
Selección aleatoria con choice
Selecciona elementos de un array con o sin reemplazo.
rng = np.random.default_rng(seed=10)
colores = np.array(["rojo", "azul", "verde", "amarillo", "negro"])
# Seleccionar 3 colores sin repetición
muestra = rng.choice(colores, size=3, replace=False)
print(muestra)
# Seleccionar 8 colores con repetición
muestra_rep = rng.choice(colores, size=8, replace=True)
print(muestra_rep)
Se pueden asignar probabilidades distintas a cada elemento:
# Dado cargado: el 6 tiene el doble de probabilidad
caras = np.arange(1, 7)
probs = np.array([1, 1, 1, 1, 1, 2]) / 7
tiradas = rng.choice(caras, size=1000, p=probs)
print("Frecuencia del 6:", np.sum(tiradas == 6))
Reordenación con shuffle y permutation
El método shuffle reordena un array in-place (modifica el original). El método permutation devuelve una copia reordenada sin alterar el original.
rng = np.random.default_rng(seed=20)
datos = np.array([10, 20, 30, 40, 50])
# permutation: devuelve copia reordenada
permutado = rng.permutation(datos)
print("Original:", datos) # [10, 20, 30, 40, 50]
print("Permutado:", permutado) # Orden aleatorio
# shuffle: modifica in-place
rng.shuffle(datos)
print("Después de shuffle:", datos) # Orden aleatorio (modificado)
Estos métodos son especialmente útiles para barajar datasets antes de dividirlos en conjuntos de entrenamiento y test.
rng = np.random.default_rng(seed=30)
# Dataset con 100 muestras
X = np.arange(100).reshape(100, 1)
y = np.arange(100)
# Crear índices barajados
indices = rng.permutation(100)
X_barajado = X[indices]
y_barajado = y[indices]
# Dividir 80/20
X_train, X_test = X_barajado[:80], X_barajado[80:]
y_train, y_test = y_barajado[:80], y_barajado[80:]
print(f"Train: {len(X_train)}, Test: {len(X_test)}")
Comparación con el módulo legacy np.random
Antes de la API Generator, NumPy proporcionaba funciones globales en el módulo np.random como np.random.rand, np.random.randn, np.random.randint o np.random.seed. Estas funciones siguen disponibles pero se consideran legacy y no se recomiendan en código nuevo.
flowchart TD
subgraph Legacy[API Legacy]
A["np.random.seed(42)"]
B["np.random.rand(5)"]
C["np.random.randn("3, 3")"]
D["np.random.randint("0, 10, 5")"]
end
subgraph Moderna[API Generator]
E["rng = np.random.default_rng(42)"]
F["rng.random(5)"]
G["rng.standard_normal(("3, 3"))"]
H["rng.integers("0, 10, 5")"]
end
A -.->|Reemplazado por| E
B -.->|Reemplazado por| F
C -.->|Reemplazado por| G
D -.->|Reemplazado por| H
Las principales razones por las que se prefiere la API Generator son:
-
Estado encapsulado: cada objeto Generator mantiene su propio estado, evitando conflictos cuando varias partes del código necesitan secuencias aleatorias independientes. Con el módulo legacy,
np.random.seedafecta a un estado global compartido. -
Mejor calidad estadística: el algoritmo PCG64 (usado por defecto en Generator) produce secuencias con mejores propiedades estadísticas que el Mersenne Twister del módulo legacy.
-
API más consistente: los nombres de los métodos son más descriptivos. Por ejemplo,
rng.integersen lugar denp.random.randint, yrng.randomen lugar denp.random.rand.
# Legacy (no recomendado)
np.random.seed(42)
valores_legacy = np.random.rand(5)
# Moderno (recomendado)
rng = np.random.default_rng(42)
valores_moderno = rng.random(5)
Se recomienda usar siempre
default_rngen lugar de las funciones globales denp.random. El módulo legacy se mantiene por compatibilidad pero no recibe mejoras.
Aplicaciones prácticas
Simulación de Monte Carlo
La simulación de Monte Carlo utiliza muestreo aleatorio repetido para estimar resultados numéricos. Un ejemplo clásico es estimar el valor de $\pi$ lanzando puntos aleatorios dentro de un cuadrado y contando cuántos caen dentro del círculo inscrito.
rng = np.random.default_rng(seed=77)
n_puntos = 1_000_000
# Puntos aleatorios en el cuadrado [0, 1) x [0, 1)
x = rng.random(n_puntos)
y = rng.random(n_puntos)
# Distancia al origen
dentro_circulo = (x**2 + y**2) <= 1.0
# Estimación de pi
pi_estimado = 4 * np.sum(dentro_circulo) / n_puntos
print(f"Pi estimado: {pi_estimado:.6f}") # Cercano a 3.141592
Generación de datos sintéticos
En machine learning es habitual generar datasets sintéticos para pruebas y prototipado. Combinando distribuciones se pueden crear datasets con propiedades controladas.
rng = np.random.default_rng(seed=55)
n_muestras = 500
# Características: edad, ingresos mensuales, horas de trabajo semanales
edad = rng.integers(18, 65, size=n_muestras)
ingresos = rng.normal(2500, 800, size=n_muestras).clip(min=900)
horas = rng.normal(40, 5, size=n_muestras).clip(min=10, max=60)
# Variable objetivo: satisfacción (correlacionada con ingresos y horas)
satisfaccion = (
0.3 * (ingresos / 1000)
- 0.1 * (horas - 40)
+ rng.normal(0, 0.5, size=n_muestras)
)
# Combinar en una matriz
dataset = np.column_stack([edad, ingresos, horas, satisfaccion])
print(f"Forma del dataset: {dataset.shape}") # (500, 4)
print(f"Primeras filas:\n{np.round(dataset[:3], 2)}")
Bootstrap para intervalos de confianza
El método bootstrap estima la variabilidad de una estadística mediante remuestreo con reemplazo del dataset original.
rng = np.random.default_rng(seed=88)
# Datos originales: tiempos de carga de una web (ms)
tiempos = np.array([230, 245, 260, 210, 290, 310, 225, 270, 255, 240])
n_bootstrap = 10_000
# Generar medias bootstrap
medias_bootstrap = np.empty(n_bootstrap)
for i in range(n_bootstrap):
muestra = rng.choice(tiempos, size=len(tiempos), replace=True)
medias_bootstrap[i] = np.mean(muestra)
# Intervalo de confianza al 95%
ic_inferior = np.percentile(medias_bootstrap, 2.5)
ic_superior = np.percentile(medias_bootstrap, 97.5)
print(f"Media original: {np.mean(tiempos):.1f} ms")
print(f"IC 95%: [{ic_inferior:.1f}, {ic_superior:.1f}] ms")

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, NumPy es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de NumPy
Explora más contenido relacionado con NumPy y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Generar números aleatorios reproducibles con la API Generator de NumPy, utilizar distribuciones estadísticas comunes y aplicar métodos de muestreo para simulaciones y datos sintéticos.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje