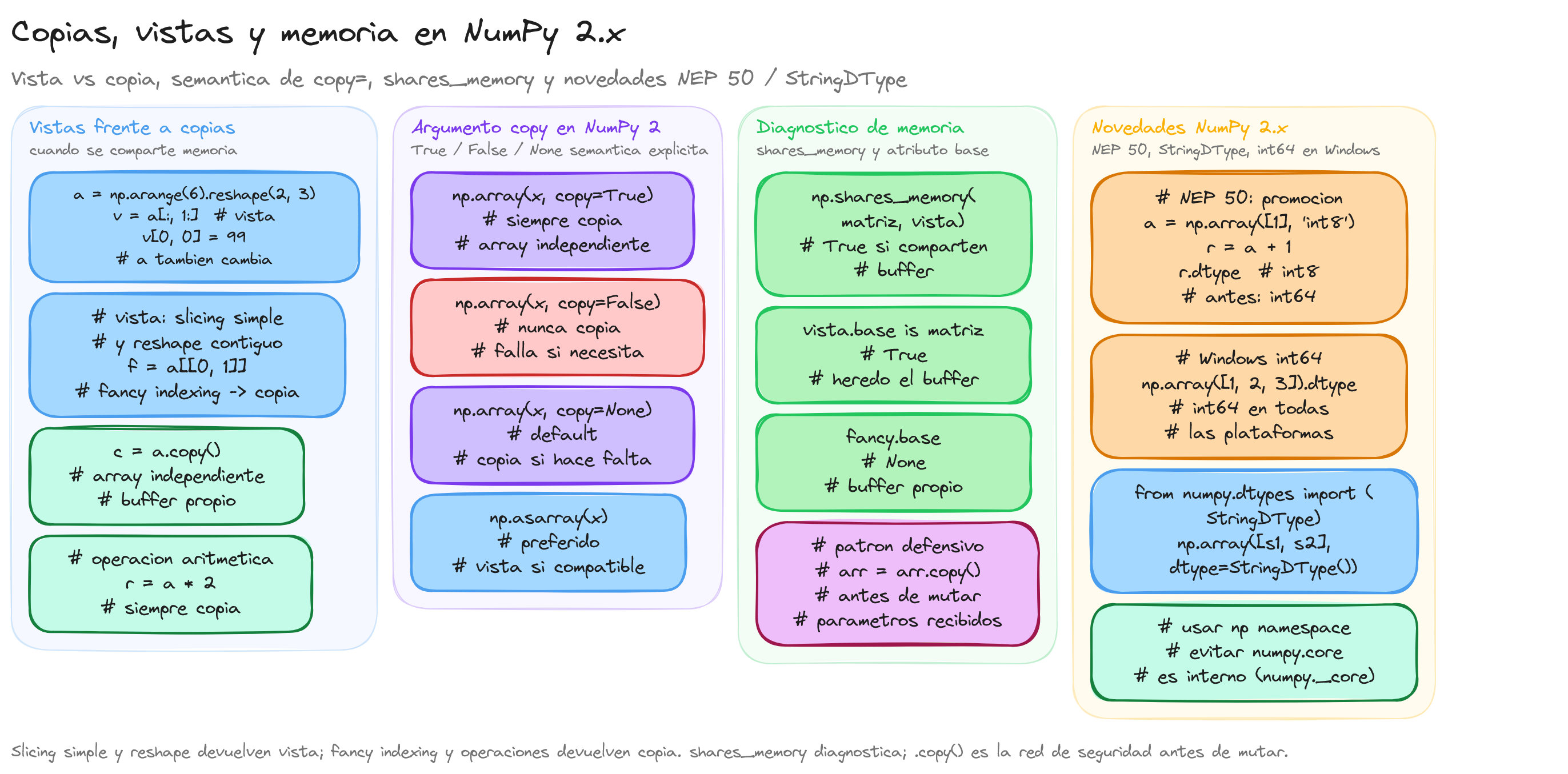
Vistas frente a copias
Muchas operaciones de NumPy no duplican datos: devuelven una vista del mismo bloque de memoria con otra forma o otro recorrido (por ejemplo slicing simple a[1:5] o reshape cuando la memoria es contigua). Otras operaciones crean un nuevo array con datos copiados.
Regla práctica: si modificas un subarray y cambia el original, probablemente trabajabas con una vista; si el original no cambia, obtuviste una copia.
import numpy as np
a = np.arange(6).reshape(2, 3)
v = a[:, 1:] # suele ser vista
v[0, 0] = 99
print(a) # el original puede verse afectado
Usa .copy() cuando necesites un array independiente antes de mutar.
Cambios en NumPy 2: argumento copy
A partir de NumPy 2.0, el comportamiento del parámetro copy en np.array y np.asarray es más estricto y explícito:
copy=True: siempre copia.copy=False: nunca copia; si no puede obtener una vista sin copiar, puede fallar.copy=None(valor por defecto en muchas rutas): comportamiento equivalente al antiguo "copiar solo si hace falta".
Si migras código de NumPy 1.x que usaba np.array(x, copy=False) esperando "a veces copiar", revisa la intención: a menudo la alternativa recomendada es np.asarray(x) cuando quieres reutilizar la memoria subyacente sin forzar una copia innecesaria.
import numpy as np
data = [1, 2, 3]
x = np.asarray(data) # preferido para «no copiar de más» cuando el origen ya es compatible
y = np.array(data, copy=True) # copia explícita
Consulta la guía de migración a NumPy 2 para el detalle por función.
Namespace público y numpy.core
En NumPy 2, numpy.core deja de ser API estable: se internaliza como numpy._core. El código de aplicación debe usar el namespace principal np (np.array, np.linalg, etc.), no depender de rutas internas que puedan cambiar sin aviso.
Promoción de tipos (NEP 50)
NumPy 2.0 introduce nuevas reglas de promoción de tipos definidas en NEP 50. El cambio principal es que al combinar un escalar de Python con un array de NumPy, el resultado mantiene el dtype del array en lugar de promocionar al tipo del escalar.
import numpy as np
a = np.array([1, 2, 3], dtype=np.int8)
# En NumPy 2: el resultado conserva int8 (antes se promocionaba a int64)
resultado = a + 1
print(resultado.dtype) # int8
Esto puede producir resultados inesperados en código migrado desde NumPy 1.x, especialmente desbordamientos en tipos de precisión baja. Si se necesita mayor precisión, hay que hacer el cast de forma explícita con astype.
Entero por defecto en Windows
A partir de NumPy 2.0, el tipo entero por defecto en Windows es int64 en plataformas de 64 bits, igualando el comportamiento de Linux y macOS. En versiones anteriores, Windows usaba int32 como entero por defecto, lo que podía generar inconsistencias entre plataformas.
import numpy as np
a = np.array([1, 2, 3])
print(a.dtype) # int64 en todas las plataformas de 64 bits (incluido Windows)
StringDType: cadenas de ancho variable
NumPy 2.0 introduce StringDType en el módulo numpy.dtypes, un nuevo dtype para cadenas de texto de ancho variable codificadas en UTF-8. A diferencia de los dtypes de cadena fija (U o S), no requiere especificar una longitud máxima y almacena solo los bytes necesarios.
import numpy as np
from numpy.dtypes import StringDType
datos = np.array(["texto largo de ejemplo", "corto"], dtype=StringDType())
print(datos) # ['texto largo de ejemplo' 'corto']
print(datos.dtype) # StringDType()
StringDType es el reemplazo recomendado para arrays de strings que antes usaban dtype=object. Soporta operaciones de cadena a través del nuevo namespace numpy.strings, que expone operaciones de texto como ufuncs optimizadas.
Resumen
| Necesidad | Enfoque típico |
|-----------|----------------|
| Evitar copias al convertir | np.asarray |
| Garantizar array independiente | .copy() o np.array(..., copy=True) |
| Entender efectos al mutar | Preguntarse si el resultado es vista o copia |
| Código compatible NumPy 2 | Revisar usos de copy=False y evitar np.core |
| Promoción de tipos | Verificar casts explícitos si se mezclan escalares con arrays de baja precisión |
| Cadenas de ancho variable | Usar StringDType() en lugar de dtype=object para arrays de texto |
Este conocimiento reduce bugs silenciosos al combinar Pandas, Scikit-learn y NumPy en pipelines donde las vistas comparten memoria entre objetos.
Diagnóstico práctico: vista, copia o base compartida
Cuando hay dudas, np.shares_memory y el atributo base permiten comprobar si dos arrays comparten almacenamiento. Es la forma fiable de auditar bugs de mutación accidental en pipelines.
import numpy as np
matriz = np.arange(12).reshape(3, 4)
# Slicing basico: crea una vista
vista = matriz[:, 1:3]
print(np.shares_memory(matriz, vista)) # True
print(vista.base is matriz) # True (hereda el buffer)
# Fancy indexing: crea copia
fancy = matriz[[0, 2]]
print(np.shares_memory(matriz, fancy)) # False
print(fancy.base) # None (buffer propio)
# Operacion aritmetica: siempre crea copia
resultado = matriz * 2
print(np.shares_memory(matriz, resultado)) # False
La regla operativa en equipos que manejan datasets de producción es simple: cuando una función recibe un ndarray que proviene de otro módulo y va a mutarlo, lo primero debe ser un array = array.copy() defensivo; cuando una función solo lee, basta con np.asarray para evitar copias innecesarias.
Caso B2B: pipeline de forecasting de demanda
En un equipo de retail con ventas diarias por tienda, el pipeline lee un CSV mensual, aplica ventanas móviles para suavizar ruido y entrena modelos de predicción de demanda. Una copia mal gestionada puede duplicar el consumo de memoria al procesar miles de SKUs, o peor, provocar que el suavizado escriba accidentalmente sobre los datos originales y contamine las métricas de validación.
import numpy as np
def suavizar(ventas: np.ndarray, ventana: int = 7) -> np.ndarray:
"""Devuelve la media movil sin mutar el array original."""
# Paso 1: copia defensiva (no queremos tocar ventas)
buffer = ventas.astype(np.float32, copy=True)
# Paso 2: calculo vectorizado con vista (sin copia extra)
n = len(buffer)
salida = np.empty(n, dtype=np.float32)
for i in range(n):
inicio = max(0, i - ventana + 1)
salida[i] = buffer[inicio : i + 1].mean()
return salida
ventas_sku = np.array([120, 135, 110, 180, 200, 95, 140], dtype=np.int32)
suavizadas = suavizar(ventas_sku)
# El array original sigue intacto, el pipeline downstream puede reutilizarlo
assert ventas_sku.dtype == np.int32
assert not np.shares_memory(ventas_sku, suavizadas)
En pipelines reales con millones de filas, el patrón se repite en cada transformer: decidir conscientemente si se necesita copia (para garantizar inmutabilidad) o vista (para ahorrar memoria y evitar la sobrecarga de duplicación).
Resumen del flujo de memoria
flowchart LR
Datos[np.ndarray fuente] --> Slice[Slicing simple]
Datos --> Fancy[Fancy indexing]
Datos --> Aritmetica[Operación aritmetica]
Datos --> Asarray[np.asarray]
Slice -->|vista| Compartida[Memoria compartida]
Asarray -->|vista si compatible| Compartida
Fancy -->|copia| Independiente[Buffer nuevo]
Aritmetica -->|copia| Independiente
Compartida -->|mutación| Riesgo[Efecto colateral]
Independiente -->|mutación| Seguro[Sin efecto colateral]
Dominar este diagrama es la base para construir pipelines NumPy reproducibles y auditables en proyectos B2B de analítica avanzada, forecasting o scoring, donde cualquier mutación accidental se traduce en informes con números distintos en cada ejecución.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, NumPy es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de NumPy
Explora más contenido relacionado con NumPy y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Distinguir vistas y copias de un ndarray, usar np.asarray y el argumento copy en NumPy 2, comprender la promoción de tipos NEP 50, y conocer StringDType para cadenas de ancho variable.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje