Vistas materializadas
Las vistas materializadas representan una evolución importante en el concepto de vistas en bases de datos relacionales. A diferencia de las vistas regulares (también llamadas vistas virtuales), que son consultas almacenadas que se ejecutan cada vez que se las invoca, las vistas materializadas almacenan físicamente los resultados de la consulta en disco.
Esta característica fundamental convierte a las vistas materializadas en una poderosa herramienta para optimizar el rendimiento de consultas complejas o que procesan grandes volúmenes de datos. Al almacenar los resultados previamente calculados, las consultas posteriores pueden acceder directamente a estos datos sin necesidad de recalcular la consulta original.
Concepto y funcionamiento
Una vista materializada funciona como una tabla física que contiene los resultados de una consulta. Cuando se crea una vista materializada:
- Se define una consulta SQL (similar a una vista regular)
- La base de datos ejecuta esta consulta
- Los resultados se almacenan físicamente en disco
- Las consultas posteriores acceden a estos datos almacenados
Este comportamiento contrasta con las vistas regulares, que no almacenan datos y ejecutan su consulta cada vez que son referenciadas.
Ventajas de las vistas materializadas
-
Mejora del rendimiento: Las consultas complejas se ejecutan una sola vez, y los resultados se almacenan para uso futuro.
-
Reducción de carga: Disminuye la carga del servidor al evitar cálculos repetitivos, especialmente útil para consultas con operaciones costosas como agregaciones o joins múltiples.
-
Acceso rápido a datos agregados: Ideal para almacenar resultados de informes, estadísticas o datos históricos que no cambian con frecuencia.
-
Disponibilidad offline: Los datos están disponibles incluso cuando las tablas de origen no están accesibles (por ejemplo, durante mantenimientos).
Implementación en PostgreSQL
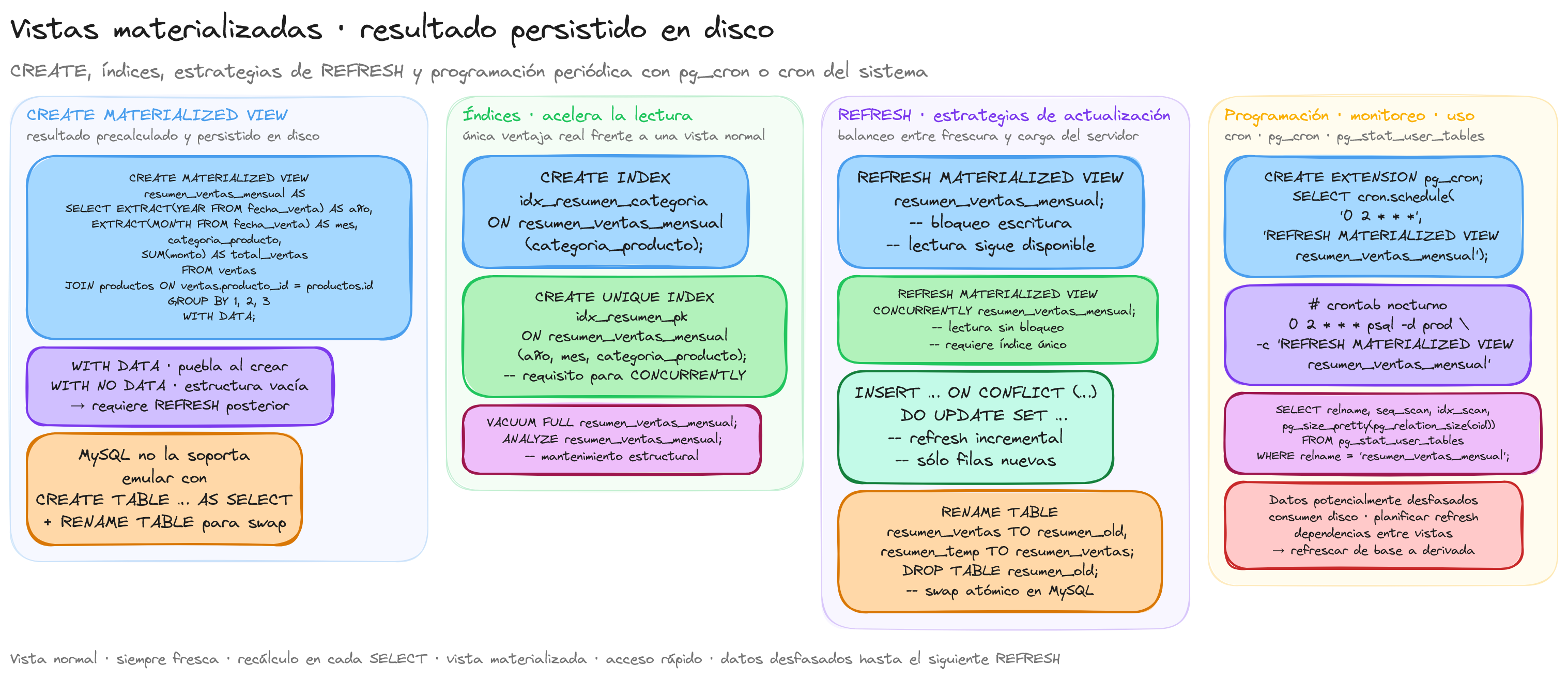
PostgreSQL ofrece soporte nativo para vistas materializadas desde la versión 9.3. La sintaxis básica es:
CREATE MATERIALIZED VIEW nombre_vista AS
SELECT columna1, columna2, ...
FROM tabla
WHERE condición
[WITH DATA | WITH NO DATA];
El parámetro WITH DATA (predeterminado) indica que la vista debe poblarse inmediatamente, mientras que WITH NO DATA crea la estructura pero no la llena hasta un refresh explícito.
Ejemplo práctico de una vista materializada para un informe de ventas mensuales:
CREATE MATERIALIZED VIEW resumen_ventas_mensual AS
SELECT
EXTRACT(YEAR FROM fecha_venta) AS año,
EXTRACT(MONTH FROM fecha_venta) AS mes,
categoria_producto,
SUM(monto) AS total_ventas,
COUNT(*) AS numero_transacciones,
AVG(monto) AS venta_promedio
FROM ventas
JOIN productos ON ventas.producto_id = productos.id
GROUP BY
EXTRACT(YEAR FROM fecha_venta),
EXTRACT(MONTH FROM fecha_venta),
categoria_producto
WITH DATA;
Implementación en MySQL
MySQL incorporó soporte para vistas materializadas a partir de la versión 8.0, aunque con una implementación diferente a PostgreSQL. En MySQL, se utilizan tablas derivadas con la característica de actualización automática:
CREATE TABLE resumen_ventas_mensual AS
SELECT
YEAR(fecha_venta) AS año,
MONTH(fecha_venta) AS mes,
categoria_producto,
SUM(monto) AS total_ventas,
COUNT(*) AS numero_transacciones,
AVG(monto) AS venta_promedio
FROM ventas
JOIN productos ON ventas.producto_id = productos.id
GROUP BY
YEAR(fecha_venta),
MONTH(fecha_venta),
categoria_producto;
Diferencias con vistas regulares
Para entender mejor el valor de las vistas materializadas, es importante compararlas con las vistas regulares:
| Característica | Vista regular | Vista materializada | |----------------|---------------|---------------------| | Almacenamiento | No almacena datos | Almacena resultados físicamente | | Actualización | Siempre muestra datos actuales | Requiere actualización explícita | | Rendimiento | Recalcula cada vez | Acceso directo a resultados precalculados | | Índices | No permite índices propios | Permite crear índices | | Uso de recursos | Mayor uso de CPU en cada consulta | Mayor uso de almacenamiento |
Casos de uso ideales
Las vistas materializadas son especialmente útiles en los siguientes escenarios:
-
Data warehousing: Para almacenar agregaciones y cálculos complejos utilizados en análisis de datos.
-
Informes periódicos: Cuando se necesitan generar informes recurrentes sobre datos que no cambian constantemente.
-
Aplicaciones con lectura intensiva: Sistemas donde las operaciones de lectura superan ampliamente a las de escritura.
-
Cálculos costosos: Consultas que involucran funciones de ventana, agregaciones complejas o múltiples joins.
-
Réplica parcial de datos: Para mantener copias locales de datos remotos que se actualizan periódicamente.
Ejemplo de vista materializada para un dashboard de análisis de rendimiento:
CREATE MATERIALIZED VIEW metricas_rendimiento_app AS
SELECT
fecha::date AS dia,
modulo_app,
COUNT(DISTINCT usuario_id) AS usuarios_activos,
AVG(tiempo_respuesta) AS tiempo_respuesta_promedio,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY tiempo_respuesta) AS p95_tiempo_respuesta,
COUNT(CASE WHEN codigo_error IS NOT NULL THEN 1 END) AS total_errores
FROM logs_aplicacion
WHERE fecha > CURRENT_DATE - INTERVAL '30 days'
GROUP BY fecha::date, modulo_app
WITH DATA;
Consideraciones de diseño
Al implementar vistas materializadas, es importante considerar:
-
Frecuencia de actualización: Determinar cuán actualizados necesitan estar los datos.
-
Tamaño de almacenamiento: Evaluar el espacio que ocuparán los resultados materializados.
-
Complejidad de la consulta original: Cuanto más compleja sea la consulta, mayor será el beneficio de materializarla.
-
Patrones de acceso: Analizar con qué frecuencia se accede a los datos y desde qué partes de la aplicación.
-
Índices adicionales: Considerar la creación de índices en la vista materializada para optimizar aún más las consultas.
Limitaciones
A pesar de sus ventajas, las vistas materializadas presentan algunas limitaciones:
-
Datos potencialmente desactualizados: Los datos pueden no reflejar el estado actual de las tablas base hasta que se actualice la vista.
-
Consumo de espacio: Requieren espacio de almacenamiento adicional.
-
Mantenimiento adicional: Necesitan un plan de actualización que debe ser gestionado.
-
Soporte variable: La implementación y características varían entre diferentes sistemas de gestión de bases de datos.
Creación y mantenimiento
La creación y mantenimiento de vistas materializadas requiere un enfoque diferente al de las vistas regulares, debido a su naturaleza de almacenamiento físico. Implementar correctamente estas estructuras implica no solo definirlas adecuadamente, sino también establecer estrategias para su mantenimiento a lo largo del tiempo.
Creación de vistas materializadas
En PostgreSQL
Para crear una vista materializada en PostgreSQL, utilizamos la sintaxis CREATE MATERIALIZED VIEW seguida de la consulta que definirá los datos a almacenar:
CREATE MATERIALIZED VIEW nombre_vista_materializada
AS consulta
[WITH [NO] DATA];
El parámetro opcional WITH DATA (predeterminado) indica que la vista debe poblarse inmediatamente con los resultados de la consulta, mientras que WITH NO DATA crea la estructura vacía que deberá ser poblada posteriormente.
Ejemplo práctico para un sistema de comercio electrónico:
CREATE MATERIALIZED VIEW productos_mas_vendidos AS
SELECT
p.id,
p.nombre,
p.categoria,
SUM(di.cantidad) AS unidades_vendidas,
SUM(di.cantidad * di.precio_unitario) AS ingresos_totales
FROM productos p
JOIN detalle_items di ON p.id = di.producto_id
JOIN pedidos pe ON di.pedido_id = pe.id
WHERE pe.fecha_compra >= CURRENT_DATE - INTERVAL '30 days'
GROUP BY p.id, p.nombre, p.categoria
ORDER BY unidades_vendidas DESC
WITH DATA;
En MySQL
MySQL no tiene una sintaxis específica para vistas materializadas, pero podemos simularlas mediante tablas derivadas:
CREATE TABLE nombre_vista_materializada AS
SELECT columnas
FROM tablas
WHERE condiciones;
Ejemplo equivalente al anterior para MySQL:
CREATE TABLE productos_mas_vendidos AS
SELECT
p.id,
p.nombre,
p.categoria,
SUM(di.cantidad) AS unidades_vendidas,
SUM(di.cantidad * di.precio_unitario) AS ingresos_totales
FROM productos p
JOIN detalle_items di ON p.id = di.producto_id
JOIN pedidos pe ON di.pedido_id = pe.id
WHERE pe.fecha_compra >= DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY)
GROUP BY p.id, p.nombre, p.categoria
ORDER BY unidades_vendidas DESC;
Optimización con índices
Una de las ventajas clave de las vistas materializadas es la posibilidad de crear índices sobre ellas, lo que permite optimizar aún más las consultas que las utilizan.
En PostgreSQL:
CREATE INDEX idx_productos_vendidos_categoria
ON productos_mas_vendidos(categoria);
CREATE INDEX idx_productos_vendidos_ingresos
ON productos_mas_vendidos(ingresos_totales DESC);
En MySQL:
ALTER TABLE productos_mas_vendidos
ADD INDEX idx_categoria (categoria),
ADD INDEX idx_ingresos (ingresos_totales DESC);
La creación de índices debe planificarse cuidadosamente, considerando:
- Las columnas más consultadas en la vista materializada
- Los patrones de filtrado más comunes
- Las operaciones de ordenamiento frecuentes
Gestión del almacenamiento
Las vistas materializadas ocupan espacio en disco, por lo que es importante gestionar este aspecto:
- Estimar el tamaño antes de crear la vista materializada:
-- PostgreSQL: Estimar tamaño aproximado
SELECT pg_size_pretty(
(SELECT COUNT(*) FROM (
SELECT columnas FROM tablas WHERE condiciones
) AS subquery) * 30
) AS tamaño_estimado;
- Monitorear el crecimiento de las vistas materializadas:
-- PostgreSQL: Verificar tamaño actual
SELECT pg_size_pretty(pg_relation_size('productos_mas_vendidos'));
-- MySQL: Verificar tamaño actual
SELECT
table_name,
ROUND((data_length + index_length) / 1024 / 1024, 2) AS "Tamaño (MB)"
FROM information_schema.tables
WHERE table_schema = 'nombre_base_datos'
AND table_name = 'productos_mas_vendidos';
Mantenimiento de dependencias
Es crucial documentar y gestionar las dependencias entre las vistas materializadas y sus tablas base. Cualquier cambio en el esquema de las tablas base puede afectar a las vistas materializadas.
En PostgreSQL, podemos consultar estas dependencias:
SELECT
d.refobjid::regclass AS tabla_base,
d.refobjsubid AS columna_id,
a.attname AS columna_nombre
FROM pg_depend d
JOIN pg_class c ON c.oid = d.objid
JOIN pg_attribute a ON a.attrelid = d.refobjid AND a.attnum = d.refobjsubid
WHERE c.relname = 'productos_mas_vendidos'
AND d.refobjsubid > 0;
Estrategias de mantenimiento
El mantenimiento de vistas materializadas implica principalmente dos aspectos:
- Actualización de datos (que veremos en detalle en la siguiente sección)
- Mantenimiento estructural
Para el mantenimiento estructural:
- Reconstrucción periódica para optimizar el almacenamiento:
-- PostgreSQL
VACUUM FULL productos_mas_vendidos;
-- MySQL
OPTIMIZE TABLE productos_mas_vendidos;
- Análisis de estadísticas para mejorar el rendimiento de consultas:
-- PostgreSQL
ANALYZE productos_mas_vendidos;
-- MySQL
ANALYZE TABLE productos_mas_vendidos;
Modificación de vistas materializadas
En ocasiones, necesitaremos modificar la estructura o definición de una vista materializada:
En PostgreSQL
PostgreSQL no permite modificar directamente una vista materializada. El enfoque habitual es:
BEGIN;
-- Crear una nueva vista materializada con la definición actualizada
CREATE MATERIALIZED VIEW productos_mas_vendidos_nueva AS
SELECT
p.id,
p.nombre,
p.categoria,
p.subcategoria, -- Nueva columna añadida
SUM(di.cantidad) AS unidades_vendidas,
SUM(di.cantidad * di.precio_unitario) AS ingresos_totales
FROM productos p
JOIN detalle_items di ON p.id = di.producto_id
JOIN pedidos pe ON di.pedido_id = pe.id
WHERE pe.fecha_compra >= CURRENT_DATE - INTERVAL '30 days'
GROUP BY p.id, p.nombre, p.categoria, p.subcategoria
ORDER BY unidades_vendidas DESC
WITH DATA;
-- Recrear los índices en la nueva vista
CREATE INDEX idx_productos_vendidos_nueva_categoria
ON productos_mas_vendidos_nueva(categoria);
-- Eliminar la vista antigua
DROP MATERIALIZED VIEW productos_mas_vendidos;
-- Renombrar la nueva vista
ALTER MATERIALIZED VIEW productos_mas_vendidos_nueva
RENAME TO productos_mas_vendidos;
COMMIT;
En MySQL
En MySQL, al usar tablas derivadas como vistas materializadas, podemos utilizar ALTER TABLE:
-- Añadir una columna
ALTER TABLE productos_mas_vendidos
ADD COLUMN subcategoria VARCHAR(50);
-- Actualizar la nueva columna
UPDATE productos_mas_vendidos pm
JOIN productos p ON pm.id = p.id
SET pm.subcategoria = p.subcategoria;
Monitoreo del uso
Para garantizar que las vistas materializadas están siendo utilizadas eficientemente:
- Analizar el uso de las vistas materializadas:
-- PostgreSQL: Verificar si la vista materializada está siendo utilizada
SELECT relname, seq_scan, idx_scan
FROM pg_stat_user_tables
WHERE relname = 'productos_mas_vendidos';
- Identificar consultas que podrían beneficiarse de vistas materializadas:
-- PostgreSQL: Encontrar consultas frecuentes y costosas
SELECT query, calls, total_time, rows
FROM pg_stat_statements
ORDER BY total_time DESC
LIMIT 10;
Documentación y buenas prácticas
Para mantener un sistema organizado:
-
Nombrar las vistas materializadas con un prefijo o sufijo distintivo (ej:
mv_productos_vendidosoproductos_vendidos_mv) -
Documentar el propósito de cada vista materializada:
-- PostgreSQL
COMMENT ON MATERIALIZED VIEW productos_mas_vendidos IS
'Productos más vendidos en los últimos 30 días. Actualización diaria a las 02:00.';
-- MySQL
ALTER TABLE productos_mas_vendidos
COMMENT = 'Productos más vendidos en los últimos 30 días. Actualización diaria a las 02:00.';
- Mantener un registro de las vistas materializadas en una tabla de metadatos:
CREATE TABLE metadatos_vistas_materializadas (
nombre_vista VARCHAR(100) PRIMARY KEY,
descripcion TEXT,
frecuencia_actualizacion VARCHAR(50),
ultima_actualizacion TIMESTAMP,
proxima_actualizacion TIMESTAMP,
dependencias TEXT,
responsable VARCHAR(100)
);
La creación y mantenimiento adecuados de vistas materializadas garantizan que estas estructuras cumplan su propósito de optimización sin convertirse en una carga para el sistema. Un enfoque sistemático para su gestión es fundamental para aprovechar al máximo sus beneficios.
Refresh de datos
El refresh de datos es un aspecto fundamental en la gestión de vistas materializadas, ya que determina cuándo y cómo se actualizan los datos almacenados para reflejar los cambios en las tablas base. A diferencia de las vistas regulares, que siempre muestran datos actualizados, las vistas materializadas requieren un proceso explícito de actualización.
Estrategias de actualización
Existen diferentes enfoques para mantener actualizadas las vistas materializadas:
- Actualización completa: Reconstruye toda la vista materializada.
- Actualización incremental: Actualiza solo los datos que han cambiado.
- Actualización programada: Se ejecuta en momentos específicos.
- Actualización bajo demanda: Se ejecuta cuando es necesario.
La elección de la estrategia depende de factores como el volumen de datos, la frecuencia de cambios y los requisitos de frescura de los datos.
Refresh completo en PostgreSQL
En PostgreSQL, el comando REFRESH MATERIALIZED VIEW permite actualizar completamente una vista materializada:
REFRESH MATERIALIZED VIEW nombre_vista;
Este comando ejecuta nuevamente la consulta que define la vista y reemplaza todos los datos almacenados. Por ejemplo:
REFRESH MATERIALIZED VIEW resumen_ventas_mensual;
Durante la actualización, la vista materializada se bloquea para escritura, pero sigue disponible para lectura. Si necesitamos bloquear también la lectura para una actualización más rápida:
REFRESH MATERIALIZED VIEW CONCURRENTLY resumen_ventas_mensual;
La opción CONCURRENTLY permite que las consultas sigan accediendo a la vista durante la actualización, pero requiere que la vista tenga un índice único:
-- Crear un índice único antes de usar CONCURRENTLY
CREATE UNIQUE INDEX idx_resumen_ventas_pk ON resumen_ventas_mensual (año, mes, categoria_producto);
Simulación de refresh en MySQL
Como MySQL no tiene soporte nativo para vistas materializadas, el proceso de actualización implica recrear la tabla:
-- Actualización completa en MySQL
CREATE TABLE resumen_ventas_mensual_temp AS
SELECT
YEAR(fecha_venta) AS año,
MONTH(fecha_venta) AS mes,
categoria_producto,
SUM(monto) AS total_ventas,
COUNT(*) AS numero_transacciones,
AVG(monto) AS venta_promedio
FROM ventas
JOIN productos ON ventas.producto_id = productos.id
GROUP BY
YEAR(fecha_venta),
MONTH(fecha_venta),
categoria_producto;
-- Intercambiar las tablas
RENAME TABLE
resumen_ventas_mensual TO resumen_ventas_mensual_old,
resumen_ventas_mensual_temp TO resumen_ventas_mensual;
-- Eliminar la tabla antigua
DROP TABLE resumen_ventas_mensual_old;
Este enfoque garantiza que la tabla esté disponible durante la mayor parte del proceso de actualización, minimizando el tiempo de inactividad.
Actualización incremental
La actualización incremental es más eficiente que la completa, especialmente para grandes volúmenes de datos con cambios limitados. En PostgreSQL, no existe un mecanismo nativo para actualizaciones incrementales, pero podemos implementarlo mediante procedimientos almacenados:
CREATE OR REPLACE FUNCTION actualizar_resumen_ventas()
RETURNS void AS $$
BEGIN
-- Insertar nuevos registros
INSERT INTO resumen_ventas_mensual
SELECT
EXTRACT(YEAR FROM fecha_venta) AS año,
EXTRACT(MONTH FROM fecha_venta) AS mes,
categoria_producto,
SUM(monto) AS total_ventas,
COUNT(*) AS numero_transacciones,
AVG(monto) AS venta_promedio
FROM ventas
JOIN productos ON ventas.producto_id = productos.id
WHERE fecha_venta > (SELECT MAX(ultima_actualizacion) FROM metadatos_actualizacion WHERE vista = 'resumen_ventas_mensual')
GROUP BY
EXTRACT(YEAR FROM fecha_venta),
EXTRACT(MONTH FROM fecha_venta),
categoria_producto
ON CONFLICT (año, mes, categoria_producto)
DO UPDATE SET
total_ventas = EXCLUDED.total_ventas,
numero_transacciones = EXCLUDED.numero_transacciones,
venta_promedio = EXCLUDED.venta_promedio;
-- Actualizar metadatos
UPDATE metadatos_actualizacion
SET ultima_actualizacion = NOW()
WHERE vista = 'resumen_ventas_mensual';
END;
$$ LANGUAGE plpgsql;
Este enfoque requiere:
- Una tabla de metadatos para rastrear la última actualización
- Una clave única en la vista materializada
- Lógica personalizada para identificar y aplicar cambios
Programación de actualizaciones
Para mantener las vistas materializadas actualizadas de forma automática, podemos programar las actualizaciones utilizando herramientas del sistema de gestión de bases de datos.
En PostgreSQL con pg_cron
La extensión pg_cron permite programar tareas dentro de PostgreSQL:
-- Instalar la extensión (requiere privilegios de superusuario)
CREATE EXTENSION pg_cron;
-- Programar actualización diaria a las 2 AM
SELECT cron.schedule('0 2 * * *', 'REFRESH MATERIALIZED VIEW resumen_ventas_mensual');
Usando herramientas externas
También podemos utilizar herramientas como cron en sistemas Unix/Linux:
# Actualización diaria a las 2 AM
0 2 * * * psql -U usuario -d basedatos -c "REFRESH MATERIALIZED VIEW resumen_ventas_mensual"
Para MySQL:
0 2 * * * mysql -u usuario -p'contraseña' basedatos -e "SOURCE /ruta/script_actualizacion.sql"
Actualización basada en eventos
En algunos casos, es más eficiente actualizar las vistas materializadas cuando ocurren cambios específicos en las tablas base. Esto se puede implementar mediante triggers:
CREATE OR REPLACE FUNCTION trigger_actualizar_resumen_ventas()
RETURNS TRIGGER AS $$
BEGIN
-- Marcar la vista como desactualizada
UPDATE metadatos_actualizacion
SET requiere_actualizacion = TRUE
WHERE vista = 'resumen_ventas_mensual';
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER actualizar_tras_nueva_venta
AFTER INSERT OR UPDATE ON ventas
FOR EACH STATEMENT
EXECUTE FUNCTION trigger_actualizar_resumen_ventas();
Luego, podemos tener un proceso que verifique periódicamente si se requiere actualización:
CREATE OR REPLACE FUNCTION verificar_actualizaciones()
RETURNS void AS $$
DECLARE
vista_record RECORD;
BEGIN
FOR vista_record IN
SELECT vista FROM metadatos_actualizacion WHERE requiere_actualizacion = TRUE
LOOP
EXECUTE 'REFRESH MATERIALIZED VIEW ' || vista_record.vista;
UPDATE metadatos_actualizacion
SET requiere_actualizacion = FALSE, ultima_actualizacion = NOW()
WHERE vista = vista_record.vista;
END LOOP;
END;
$$ LANGUAGE plpgsql;
Monitoreo de actualizaciones
Es importante monitorear el proceso de actualización para garantizar que se ejecute correctamente y dentro de los tiempos esperados:
-- Crear tabla de registro de actualizaciones
CREATE TABLE log_actualizaciones_vistas (
id SERIAL PRIMARY KEY,
vista VARCHAR(100),
inicio_actualizacion TIMESTAMP,
fin_actualizacion TIMESTAMP,
duracion INTERVAL,
filas_afectadas BIGINT,
estado VARCHAR(20)
);
-- Función para registrar actualizaciones
CREATE OR REPLACE FUNCTION actualizar_con_log(nombre_vista TEXT)
RETURNS void AS $$
DECLARE
inicio TIMESTAMP;
fin TIMESTAMP;
filas BIGINT;
BEGIN
inicio := NOW();
-- Registrar inicio
INSERT INTO log_actualizaciones_vistas (vista, inicio_actualizacion, estado)
VALUES (nombre_vista, inicio, 'EN PROCESO');
-- Ejecutar actualización
EXECUTE 'REFRESH MATERIALIZED VIEW ' || nombre_vista;
-- Obtener recuento de filas
EXECUTE 'SELECT COUNT(*) FROM ' || nombre_vista INTO filas;
fin := NOW();
-- Actualizar registro
UPDATE log_actualizaciones_vistas
SET fin_actualizacion = fin,
duracion = fin - inicio,
filas_afectadas = filas,
estado = 'COMPLETADO'
WHERE vista = nombre_vista AND inicio_actualizacion = inicio;
EXCEPTION WHEN OTHERS THEN
-- Registrar error
UPDATE log_actualizaciones_vistas
SET fin_actualizacion = NOW(),
duracion = NOW() - inicio,
estado = 'ERROR: ' || SQLERRM
WHERE vista = nombre_vista AND inicio_actualizacion = inicio;
RAISE;
END;
$$ LANGUAGE plpgsql;
Optimización del proceso de refresh
Para mejorar el rendimiento de las actualizaciones:
- Programar actualizaciones en horas de baja carga:
-- Actualizar durante la noche
SELECT cron.schedule('0 2 * * *', 'SELECT actualizar_con_log(''resumen_ventas_mensual'')');
- Utilizar paralelismo cuando sea posible:
-- Configurar paralelismo para la sesión
SET max_parallel_workers_per_gather = 4;
REFRESH MATERIALIZED VIEW resumen_ventas_mensual;
- Considerar la frecuencia de actualización según la naturaleza de los datos:
- Datos que cambian constantemente: actualización frecuente
- Datos históricos o que cambian poco: actualización menos frecuente
Gestión de dependencias entre vistas materializadas
Cuando existen dependencias entre vistas materializadas, es importante actualizar primero las vistas base:
-- Función para actualizar vistas materializadas en orden
CREATE OR REPLACE FUNCTION actualizar_vistas_en_orden()
RETURNS void AS $$
BEGIN
-- Primero actualizar vistas de nivel base
REFRESH MATERIALIZED VIEW ventas_por_dia;
-- Luego actualizar vistas que dependen de las anteriores
REFRESH MATERIALIZED VIEW resumen_ventas_mensual;
-- Finalmente actualizar vistas de nivel superior
REFRESH MATERIALIZED VIEW tendencias_anuales;
END;
$$ LANGUAGE plpgsql;
Balanceo entre frescura de datos y rendimiento
El equilibrio entre datos actualizados y rendimiento es crucial. Actualizar con demasiada frecuencia puede sobrecargar el sistema, mientras que actualizaciones poco frecuentes pueden resultar en decisiones basadas en datos obsoletos.
Algunas estrategias para encontrar este balance:
- Actualización por niveles: Datos críticos con mayor frecuencia, datos históricos con menor frecuencia.
- Actualización adaptativa: Ajustar la frecuencia según la tasa de cambio de los datos.
- Actualización híbrida: Combinar actualizaciones programadas con actualizaciones basadas en eventos.
-- Ejemplo de actualización adaptativa
CREATE OR REPLACE FUNCTION programar_siguiente_actualizacion(nombre_vista TEXT)
RETURNS void AS $$
DECLARE
tasa_cambio FLOAT;
ultima_act TIMESTAMP;
intervalo INTERVAL;
BEGIN
-- Obtener tasa de cambio (cambios por hora)
SELECT
COUNT(*) / EXTRACT(EPOCH FROM (NOW() - ultima_actualizacion)) * 3600
INTO tasa_cambio
FROM log_cambios
WHERE tabla IN (SELECT tabla_origen FROM dependencias_vistas WHERE vista = nombre_vista)
AND momento > (SELECT ultima_actualizacion FROM metadatos_actualizacion WHERE vista = nombre_vista);
-- Determinar intervalo basado en la tasa de cambio
IF tasa_cambio > 100 THEN
intervalo := INTERVAL '1 hour';
ELSIF tasa_cambio > 10 THEN
intervalo := INTERVAL '6 hours';
ELSE
intervalo := INTERVAL '1 day';
END IF;
-- Programar próxima actualización
SELECT ultima_actualizacion INTO ultima_act FROM metadatos_actualizacion WHERE vista = nombre_vista;
UPDATE metadatos_actualizacion
SET proxima_actualizacion = ultima_act + intervalo
WHERE vista = nombre_vista;
END;
$$ LANGUAGE plpgsql;
La implementación de una estrategia efectiva de refresh de datos es esencial para maximizar los beneficios de las vistas materializadas, asegurando que proporcionen datos precisos y actualizados mientras se mantiene un rendimiento óptimo del sistema.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el concepto y funcionamiento de las vistas materializadas. Diferenciar entre vistas regulares y materializadas, identificando sus ventajas y limitaciones. Aprender a crear, mantener y optimizar vistas materializadas en PostgreSQL y MySQL. Conocer las estrategias de actualización (refresh) y su implementación para mantener datos actualizados. Aplicar buenas prácticas y técnicas de monitoreo para gestionar eficazmente vistas materializadas en entornos reales.