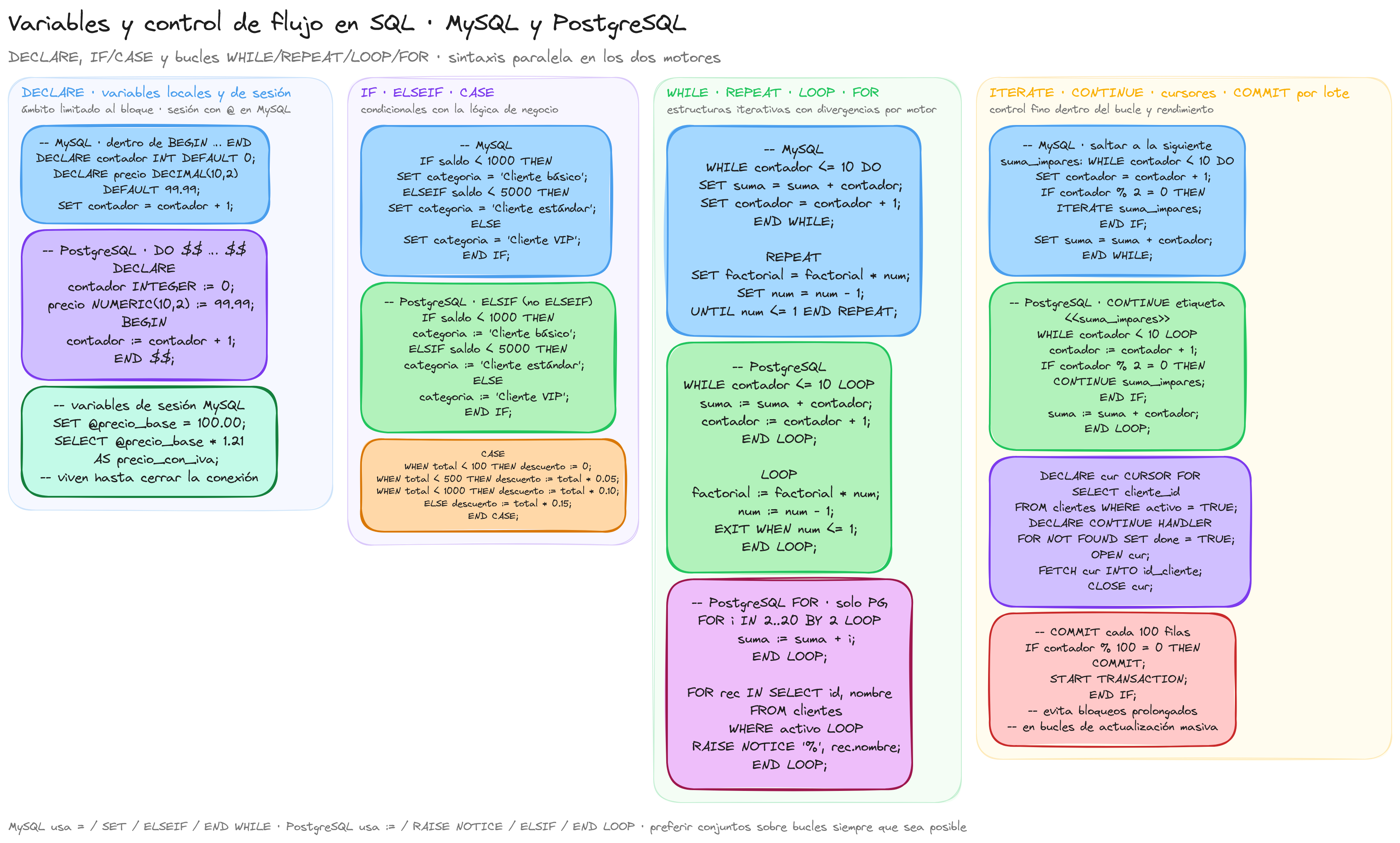
Declaración de variables
En SQL, las variables nos permiten almacenar valores temporales durante la ejecución de scripts o procedimientos. A diferencia de otros lenguajes de programación, las variables en SQL tienen un ámbito limitado y se utilizan principalmente en la programación de procedimientos almacenados, funciones y bloques de código.
Sintaxis básica en MySQL
En MySQL, la declaración de variables se realiza mediante la palabra clave DECLARE dentro de bloques de código, o utilizando la notación de @ para variables de sesión. Veamos ambos enfoques:
- Variables locales con DECLARE:
DELIMITER //
BEGIN
-- Declaración de variables
DECLARE contador INT DEFAULT 0;
DECLARE nombre VARCHAR(50);
DECLARE precio DECIMAL(10,2) DEFAULT 99.99;
DECLARE fecha_actual DATE DEFAULT CURRENT_DATE();
-- Asignación de valores
SET nombre = 'Producto ejemplo';
SET contador = contador + 1;
-- Uso de las variables
SELECT contador, nombre, precio, fecha_actual;
END //
DELIMITER ;
- Variables de sesión con @:
-- Declaración y asignación en un solo paso
SET @contador = 0;
SET @nombre = 'Producto ejemplo';
SET @precio = 99.99;
-- Otra forma de asignación
SELECT @fecha_actual := CURRENT_DATE();
-- Uso de las variables
SELECT @contador, @nombre, @precio, @fecha_actual;
Sintaxis básica en PostgreSQL
PostgreSQL utiliza una sintaxis ligeramente diferente para la declaración de variables:
DO $$
DECLARE
contador INTEGER := 0;
nombre VARCHAR(50);
precio NUMERIC(10,2) := 99.99;
fecha_actual DATE := CURRENT_DATE;
BEGIN
-- Asignación de valores
nombre := 'Producto ejemplo';
contador := contador + 1;
-- Uso de las variables
RAISE NOTICE 'Contador: %, Nombre: %, Precio: %, Fecha: %',
contador, nombre, precio, fecha_actual;
END $$;
Tipos de datos para variables
Al declarar variables, es necesario especificar su tipo de datos. Algunos de los tipos más comunes son:
-
Tipos numéricos:
-
INToINTEGER: Números enteros -
DECIMAL(p,s)oNUMERIC(p,s): Números decimales con precisión p y escala s -
FLOAT: Números de punto flotante -
Tipos de texto:
-
CHAR(n): Cadena de caracteres de longitud fija -
VARCHAR(n): Cadena de caracteres de longitud variable -
TEXT: Texto de longitud variable sin límite específico -
Tipos de fecha y hora:
-
DATE: Solo fecha (YYYY-MM-DD) -
TIME: Solo hora (HH:MM:SS) -
DATETIMEoTIMESTAMP: Fecha y hora combinadas -
Otros tipos:
-
BOOLEAN: Valores verdadero/falso -
BINARYyVARBINARY: Datos binarios
Inicialización de variables
Las variables pueden inicializarse en el momento de su declaración:
En MySQL:
DECLARE contador INT DEFAULT 0;
DECLARE fecha_actual DATETIME DEFAULT NOW();
En PostgreSQL:
DECLARE
contador INTEGER := 0;
fecha_actual TIMESTAMP := NOW();
Asignación de valores
Existen varias formas de asignar valores a las variables después de declararlas:
En MySQL:
-- Usando SET
SET variable_nombre = valor;
-- Usando SELECT INTO
SELECT columna INTO variable_nombre FROM tabla WHERE condicion;
En PostgreSQL:
-- Asignación directa
variable_nombre := valor;
-- Usando SELECT INTO
SELECT columna INTO variable_nombre FROM tabla WHERE condicion;
Variables de sistema
Tanto MySQL como PostgreSQL proporcionan variables de sistema que contienen información sobre la configuración y el estado del servidor:
En MySQL, se accede a ellas con doble arroba:
-- Mostrar el valor de una variable de sistema
SELECT @@max_connections;
SELECT @@version;
En PostgreSQL, se utilizan funciones o la vista pg_settings:
-- Mostrar variables de sistema
SHOW max_connections;
SELECT current_setting('max_connections');
SELECT name, setting FROM pg_settings WHERE name = 'max_connections';
Ámbito de las variables
Es importante entender el ámbito o alcance de las variables en SQL:
-
Variables locales (declaradas con
DECLARE): Solo existen dentro del bloque de código donde se declaran (procedimiento, función o bloque anónimo). -
Variables de sesión (con
@en MySQL): Existen durante toda la sesión de conexión actual. -
Variables de sistema: Son configuraciones del servidor de base de datos y tienen un ámbito global o de sesión.
Ejemplo práctico
Veamos un ejemplo que muestra cómo utilizar variables para calcular el precio total de productos con descuento:
En MySQL:
SET @precio_base = 100.00;
SET @porcentaje_descuento = 15;
SET @precio_con_descuento = @precio_base - (@precio_base * @porcentaje_descuento / 100);
SET @impuesto = 0.21;
SET @precio_final = @precio_con_descuento * (1 + @impuesto);
SELECT
@precio_base AS 'Precio Base',
@porcentaje_descuento AS 'Descuento (%)',
@precio_con_descuento AS 'Precio con Descuento',
@impuesto AS 'Impuesto',
@precio_final AS 'Precio Final';
En PostgreSQL:
DO $$
DECLARE
precio_base NUMERIC(10,2) := 100.00;
porcentaje_descuento NUMERIC(5,2) := 15;
precio_con_descuento NUMERIC(10,2);
impuesto NUMERIC(4,2) := 0.21;
precio_final NUMERIC(10,2);
BEGIN
precio_con_descuento := precio_base - (precio_base * porcentaje_descuento / 100);
precio_final := precio_con_descuento * (1 + impuesto);
RAISE NOTICE 'Precio Base: %, Descuento: %%, Precio con Descuento: %, Impuesto: %, Precio Final: %',
precio_base, porcentaje_descuento, precio_con_descuento, impuesto, precio_final;
END $$;
Consideraciones importantes
- Las variables en SQL son sensibles a mayúsculas y minúsculas en PostgreSQL, pero no en MySQL.
- Las variables declaradas con
DECLAREdeben definirse al principio del bloque, antes de cualquier otra instrucción. - Las variables de sesión (con
@en MySQL) persisten hasta que se cierra la conexión o se les asigna un valorNULL. - En PostgreSQL, el operador de asignación dentro de bloques PL/pgSQL es
:=, mientras que en consultas SQL se usa=. - Las variables no pueden tener el mismo nombre que las columnas de las tablas en el mismo contexto para evitar ambigüedades.
Estructuras de control condicional
Las estructuras de control condicional en SQL permiten ejecutar bloques de código de manera selectiva según se cumplan determinadas condiciones. Estas estructuras son fundamentales para crear lógica de negocio dentro de procedimientos almacenados, funciones y bloques de código.
Sentencia IF-THEN-ELSE
La estructura condicional más básica en SQL es la sentencia IF-THEN-ELSE, que evalúa una condición y ejecuta un bloque de código u otro dependiendo del resultado.
En MySQL, la sintaxis es la siguiente:
IF condicion THEN
-- Instrucciones si la condición es verdadera
ELSE
-- Instrucciones si la condición es falsa
END IF;
En PostgreSQL:
IF condicion THEN
-- Instrucciones si la condición es verdadera
ELSE
-- Instrucciones si la condición es falsa
END IF;
Veamos un ejemplo práctico en MySQL:
DELIMITER //
BEGIN
DECLARE edad INT DEFAULT 25;
DECLARE mensaje VARCHAR(100);
IF edad >= 18 THEN
SET mensaje = 'Es mayor de edad';
ELSE
SET mensaje = 'Es menor de edad';
END IF;
SELECT mensaje;
END //
DELIMITER ;
Y el equivalente en PostgreSQL:
DO $$
DECLARE
edad INTEGER := 25;
mensaje VARCHAR(100);
BEGIN
IF edad >= 18 THEN
mensaje := 'Es mayor de edad';
ELSE
mensaje := 'Es menor de edad';
END IF;
RAISE NOTICE '%', mensaje;
END $$;
Sentencia IF-THEN-ELSEIF
Para evaluar múltiples condiciones, podemos utilizar la estructura IF-THEN-ELSEIF:
En MySQL:
IF condicion1 THEN
-- Instrucciones si condicion1 es verdadera
ELSEIF condicion2 THEN
-- Instrucciones si condicion2 es verdadera
ELSEIF condicion3 THEN
-- Instrucciones si condicion3 es verdadera
ELSE
-- Instrucciones si ninguna condición es verdadera
END IF;
En PostgreSQL:
IF condicion1 THEN
-- Instrucciones si condicion1 es verdadera
ELSIF condicion2 THEN
-- Instrucciones si condicion2 es verdadera
ELSIF condicion3 THEN
-- Instrucciones si condicion3 es verdadera
ELSE
-- Instrucciones si ninguna condición es verdadera
END IF;
Ejemplo práctico en MySQL para clasificar clientes según su saldo:
DELIMITER //
BEGIN
DECLARE saldo DECIMAL(10,2) DEFAULT 5000.00;
DECLARE categoria VARCHAR(50);
IF saldo < 1000 THEN
SET categoria = 'Cliente básico';
ELSEIF saldo >= 1000 AND saldo < 5000 THEN
SET categoria = 'Cliente estándar';
ELSEIF saldo >= 5000 AND saldo < 10000 THEN
SET categoria = 'Cliente premium';
ELSE
SET categoria = 'Cliente VIP';
END IF;
SELECT saldo, categoria;
END //
DELIMITER ;
Y en PostgreSQL (nótese la diferencia en la palabra clave ELSIF):
DO $$
DECLARE
saldo NUMERIC(10,2) := 5000.00;
categoria VARCHAR(50);
BEGIN
IF saldo < 1000 THEN
categoria := 'Cliente básico';
ELSIF saldo >= 1000 AND saldo < 5000 THEN
categoria := 'Cliente estándar';
ELSIF saldo >= 5000 AND saldo < 10000 THEN
categoria := 'Cliente premium';
ELSE
categoria := 'Cliente VIP';
END IF;
RAISE NOTICE 'Saldo: %, Categoría: %', saldo, categoria;
END $$;
Sentencia CASE
La sentencia CASE proporciona una alternativa más elegante al IF-THEN-ELSEIF cuando necesitamos evaluar múltiples condiciones. Existen dos formas de utilizar CASE:
CASE simple (comparación de valores)
En MySQL y PostgreSQL:
CASE expresion
WHEN valor1 THEN resultado1
WHEN valor2 THEN resultado2
...
ELSE resultadoN
END CASE;
CASE buscado (evaluación de condiciones)
En MySQL y PostgreSQL:
CASE
WHEN condicion1 THEN resultado1
WHEN condicion2 THEN resultado2
...
ELSE resultadoN
END CASE;
Ejemplo de CASE simple en MySQL:
DELIMITER //
BEGIN
DECLARE dia_semana INT DEFAULT DAYOFWEEK(CURRENT_DATE());
DECLARE nombre_dia VARCHAR(20);
CASE dia_semana
WHEN 1 THEN SET nombre_dia = 'Domingo';
WHEN 2 THEN SET nombre_dia = 'Lunes';
WHEN 3 THEN SET nombre_dia = 'Martes';
WHEN 4 THEN SET nombre_dia = 'Miércoles';
WHEN 5 THEN SET nombre_dia = 'Jueves';
WHEN 6 THEN SET nombre_dia = 'Viernes';
WHEN 7 THEN SET nombre_dia = 'Sábado';
ELSE SET nombre_dia = 'Día desconocido';
END CASE;
SELECT dia_semana, nombre_dia;
END //
DELIMITER ;
Y en PostgreSQL:
DO $$
DECLARE
dia_semana INTEGER := EXTRACT(DOW FROM CURRENT_DATE);
nombre_dia VARCHAR(20);
BEGIN
CASE dia_semana
WHEN 0 THEN nombre_dia := 'Domingo';
WHEN 1 THEN nombre_dia := 'Lunes';
WHEN 2 THEN nombre_dia := 'Martes';
WHEN 3 THEN nombre_dia := 'Miércoles';
WHEN 4 THEN nombre_dia := 'Jueves';
WHEN 5 THEN nombre_dia := 'Viernes';
WHEN 6 THEN nombre_dia := 'Sábado';
ELSE nombre_dia := 'Día desconocido';
END CASE;
RAISE NOTICE 'Día de la semana: %, Nombre: %', dia_semana, nombre_dia;
END $$;
Ejemplo de CASE buscado en MySQL para calcular descuentos:
DELIMITER //
BEGIN
DECLARE total_compra DECIMAL(10,2) DEFAULT 750.00;
DECLARE descuento DECIMAL(10,2);
CASE
WHEN total_compra < 100 THEN SET descuento = 0;
WHEN total_compra >= 100 AND total_compra < 500 THEN SET descuento = total_compra * 0.05;
WHEN total_compra >= 500 AND total_compra < 1000 THEN SET descuento = total_compra * 0.10;
ELSE SET descuento = total_compra * 0.15;
END CASE;
SELECT total_compra, descuento, (total_compra - descuento) AS precio_final;
END //
DELIMITER ;
Y en PostgreSQL:
DO $$
DECLARE
total_compra NUMERIC(10,2) := 750.00;
descuento NUMERIC(10,2);
precio_final NUMERIC(10,2);
BEGIN
CASE
WHEN total_compra < 100 THEN descuento := 0;
WHEN total_compra >= 100 AND total_compra < 500 THEN descuento := total_compra * 0.05;
WHEN total_compra >= 500 AND total_compra < 1000 THEN descuento := total_compra * 0.10;
ELSE descuento := total_compra * 0.15;
END CASE;
precio_final := total_compra - descuento;
RAISE NOTICE 'Total compra: %, Descuento: %, Precio final: %',
total_compra, descuento, precio_final;
END $$;
CASE en consultas SELECT
Una característica muy útil es que la expresión CASE también puede utilizarse directamente en consultas SELECT, sin necesidad de estar dentro de un bloque de código:
-- MySQL y PostgreSQL
SELECT
producto_id,
nombre,
precio,
CASE
WHEN precio < 10 THEN 'Económico'
WHEN precio >= 10 AND precio < 50 THEN 'Estándar'
WHEN precio >= 50 AND precio < 100 THEN 'Premium'
ELSE 'Lujo'
END AS categoria_precio
FROM productos;
Operador IF en MySQL
MySQL ofrece una función condicional IF que puede utilizarse en expresiones:
-- Solo en MySQL
SELECT
producto_id,
nombre,
precio,
IF(precio > 50, 'Caro', 'Barato') AS valoracion
FROM productos;
Operadores COALESCE y NULLIF
Tanto MySQL como PostgreSQL soportan funciones condicionales adicionales:
- COALESCE: Devuelve el primer valor no nulo de una lista.
-- MySQL y PostgreSQL
SELECT
cliente_id,
COALESCE(telefono_movil, telefono_fijo, 'Sin teléfono') AS contacto
FROM clientes;
- NULLIF: Compara dos expresiones y devuelve NULL si son iguales, o la primera expresión si son diferentes.
-- MySQL y PostgreSQL
SELECT
producto_id,
precio_actual,
precio_anterior,
NULLIF(precio_actual, precio_anterior) AS precio_cambiado
FROM productos;
Diferencias entre MySQL y PostgreSQL
Aunque las estructuras condicionales son similares en ambos sistemas, existen algunas diferencias importantes:
- En PostgreSQL, la palabra clave para múltiples condiciones es
ELSIF, mientras que en MySQL esELSEIF. - PostgreSQL utiliza
:=como operador de asignación dentro de bloques PL/pgSQL, mientras que MySQL usa=o:=. - MySQL ofrece la función
IF()que puede usarse en consultas, mientras que PostgreSQL no tiene un equivalente directo. - La forma de mostrar mensajes difiere: MySQL usa
SELECT, mientras que PostgreSQL utilizaRAISE NOTICE.
Consideraciones de rendimiento
- Las estructuras condicionales pueden afectar al rendimiento cuando se utilizan en procedimientos que procesan grandes volúmenes de datos.
- Es preferible utilizar CASE en lugar de múltiples IF-THEN cuando sea posible, ya que suele optimizarse mejor.
- Cuando se utilizan condiciones en consultas, es recomendable asegurarse de que las columnas involucradas estén indexadas para mejorar el rendimiento.
Las estructuras de control condicional son herramientas fundamentales para implementar lógica de negocio en SQL, permitiendo crear código más dinámico y adaptable a diferentes situaciones y requisitos.
Estructuras de control iterativo
Las estructuras de control iterativo en SQL permiten ejecutar un bloque de código repetidamente mientras se cumpla una condición específica. Estas estructuras son esenciales para procesar conjuntos de datos, realizar cálculos acumulativos o ejecutar operaciones secuenciales dentro de procedimientos almacenados y bloques de código.
A diferencia de los lenguajes de programación tradicionales, las iteraciones en SQL se utilizan principalmente en la programación de procedimientos almacenados y no en consultas regulares, donde se prefiere un enfoque basado en conjuntos.
Bucle WHILE
El bucle WHILE es la estructura iterativa más común en SQL. Ejecuta un bloque de código mientras una condición especificada sea verdadera.
En MySQL, la sintaxis es:
WHILE condicion DO
-- Instrucciones a ejecutar
END WHILE;
En PostgreSQL:
WHILE condicion LOOP
-- Instrucciones a ejecutar
END LOOP;
Veamos un ejemplo básico en MySQL que calcula la suma de los primeros 10 números naturales:
DELIMITER //
BEGIN
DECLARE contador INT DEFAULT 1;
DECLARE suma INT DEFAULT 0;
WHILE contador <= 10 DO
SET suma = suma + contador;
SET contador = contador + 1;
END WHILE;
SELECT suma AS 'Suma total';
END //
DELIMITER ;
El equivalente en PostgreSQL:
DO $$
DECLARE
contador INTEGER := 1;
suma INTEGER := 0;
BEGIN
WHILE contador <= 10 LOOP
suma := suma + contador;
contador := contador + 1;
END LOOP;
RAISE NOTICE 'Suma total: %', suma;
END $$;
Bucle REPEAT (MySQL) / LOOP (PostgreSQL)
MySQL ofrece la estructura REPEAT, que ejecuta un bloque de código al menos una vez y luego repite la ejecución mientras la condición especificada sea verdadera:
REPEAT
-- Instrucciones a ejecutar
UNTIL condicion
END REPEAT;
En PostgreSQL, se puede lograr un comportamiento similar con LOOP y una condición de salida:
LOOP
-- Instrucciones a ejecutar
EXIT WHEN condicion;
END LOOP;
Ejemplo en MySQL para calcular el factorial de un número:
DELIMITER //
BEGIN
DECLARE num INT DEFAULT 5;
DECLARE factorial BIGINT DEFAULT 1;
REPEAT
SET factorial = factorial * num;
SET num = num - 1;
UNTIL num <= 1
END REPEAT;
SELECT factorial AS 'Resultado factorial';
END //
DELIMITER ;
Y en PostgreSQL:
DO $$
DECLARE
num INTEGER := 5;
factorial BIGINT := 1;
BEGIN
LOOP
factorial := factorial * num;
num := num - 1;
EXIT WHEN num <= 1;
END LOOP;
RAISE NOTICE 'Resultado factorial: %', factorial;
END $$;
Bucle LOOP con EXIT en PostgreSQL
PostgreSQL ofrece una estructura de bucle simple llamada LOOP que continúa indefinidamente hasta que se encuentra una instrucción EXIT:
LOOP
-- Instrucciones a ejecutar
IF condicion THEN
EXIT; -- Sale del bucle
END IF;
END LOOP;
También se puede utilizar EXIT WHEN como atajo:
LOOP
-- Instrucciones a ejecutar
EXIT WHEN condicion; -- Sale del bucle cuando la condición es verdadera
END LOOP;
Ejemplo de generación de la secuencia Fibonacci en PostgreSQL:
DO $$
DECLARE
i INTEGER := 0;
fib1 INTEGER := 0;
fib2 INTEGER := 1;
temp INTEGER;
BEGIN
RAISE NOTICE 'Secuencia Fibonacci:';
RAISE NOTICE '%', fib1;
RAISE NOTICE '%', fib2;
LOOP
temp := fib1 + fib2;
RAISE NOTICE '%', temp;
fib1 := fib2;
fib2 := temp;
i := i + 1;
EXIT WHEN i >= 8; -- Generamos 10 números en total
END LOOP;
END $$;
Bucle FOR en PostgreSQL
PostgreSQL proporciona una estructura FOR que simplifica la iteración sobre rangos numéricos:
FOR variable IN valor_inicial..valor_final LOOP
-- Instrucciones a ejecutar
END LOOP;
También se puede especificar un paso (incremento) con la cláusula BY:
FOR variable IN valor_inicial..valor_final BY paso LOOP
-- Instrucciones a ejecutar
END LOOP;
Ejemplo de suma de números pares entre 1 y 20:
DO $$
DECLARE
i INTEGER;
suma INTEGER := 0;
BEGIN
FOR i IN 2..20 BY 2 LOOP
suma := suma + i;
END LOOP;
RAISE NOTICE 'Suma de números pares entre 1 y 20: %', suma;
END $$;
Bucle ITERATE (MySQL) / CONTINUE (PostgreSQL)
En MySQL, la instrucción ITERATE permite saltar a la siguiente iteración del bucle:
etiqueta: WHILE condicion DO
IF otra_condicion THEN
ITERATE etiqueta; -- Salta a la siguiente iteración
END IF;
-- Resto de instrucciones
END WHILE;
En PostgreSQL, se utiliza CONTINUE para el mismo propósito:
<<etiqueta>>
WHILE condicion LOOP
IF otra_condicion THEN
CONTINUE etiqueta; -- Salta a la siguiente iteración
END IF;
-- Resto de instrucciones
END LOOP;
Ejemplo en MySQL que suma solo los números impares del 1 al 10:
DELIMITER //
BEGIN
DECLARE contador INT DEFAULT 0;
DECLARE suma INT DEFAULT 0;
suma_impares: WHILE contador < 10 DO
SET contador = contador + 1;
IF contador % 2 = 0 THEN
ITERATE suma_impares; -- Salta los números pares
END IF;
SET suma = suma + contador;
END WHILE;
SELECT suma AS 'Suma de impares';
END //
DELIMITER ;
Y en PostgreSQL:
DO $$
DECLARE
contador INTEGER := 0;
suma INTEGER := 0;
BEGIN
<<suma_impares>>
WHILE contador < 10 LOOP
contador := contador + 1;
IF contador % 2 = 0 THEN
CONTINUE suma_impares; -- Salta los números pares
END IF;
suma := suma + contador;
END LOOP;
RAISE NOTICE 'Suma de impares: %', suma;
END $$;
Iteración sobre resultados de consultas
Una técnica común es iterar sobre los resultados de una consulta utilizando cursores. Esto permite procesar filas una por una:
En MySQL:
DELIMITER //
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE id_cliente INT;
DECLARE nombre_cliente VARCHAR(100);
-- Declarar cursor
DECLARE cur CURSOR FOR
SELECT cliente_id, nombre
FROM clientes
WHERE activo = TRUE;
-- Declarar handler para cuando no hay más filas
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
-- Abrir cursor
OPEN cur;
-- Bucle de lectura
read_loop: LOOP
FETCH cur INTO id_cliente, nombre_cliente;
IF done THEN
LEAVE read_loop;
END IF;
-- Procesar cada fila
SELECT CONCAT('Procesando cliente: ', id_cliente, ' - ', nombre_cliente);
END LOOP;
-- Cerrar cursor
CLOSE cur;
END //
DELIMITER ;
En PostgreSQL:
DO $$
DECLARE
rec RECORD;
BEGIN
FOR rec IN SELECT cliente_id, nombre FROM clientes WHERE activo = TRUE LOOP
-- Procesar cada fila
RAISE NOTICE 'Procesando cliente: % - %', rec.cliente_id, rec.nombre;
END LOOP;
END $$;
Ejemplo práctico: Tabla de multiplicar
Veamos un ejemplo completo que genera una tabla de multiplicar utilizando bucles anidados:
En MySQL:
DELIMITER //
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE j INT;
DECLARE resultado VARCHAR(1000) DEFAULT '';
WHILE i <= 5 DO
SET j = 1;
SET resultado = CONCAT(resultado, 'Tabla del ', i, ':\n');
WHILE j <= 10 DO
SET resultado = CONCAT(resultado, i, ' x ', j, ' = ', i*j, '\n');
SET j = j + 1;
END WHILE;
SET resultado = CONCAT(resultado, '\n');
SET i = i + 1;
END WHILE;
SELECT resultado;
END //
DELIMITER ;
En PostgreSQL:
DO $$
DECLARE
i INTEGER := 1;
j INTEGER;
resultado TEXT := '';
BEGIN
WHILE i <= 5 LOOP
j := 1;
resultado := resultado || 'Tabla del ' || i || E':\n';
WHILE j <= 10 LOOP
resultado := resultado || i || ' x ' || j || ' = ' || (i*j) || E'\n';
j := j + 1;
END LOOP;
resultado := resultado || E'\n';
i := i + 1;
END LOOP;
RAISE NOTICE '%', resultado;
END $$;
Consideraciones de rendimiento
-
Enfoque basado en conjuntos: En SQL, siempre que sea posible, es preferible utilizar un enfoque basado en conjuntos (consultas que procesan múltiples filas a la vez) en lugar de iteraciones fila por fila, ya que el motor de base de datos está optimizado para operaciones de conjuntos.
-
Límites de iteración: Es recomendable establecer límites máximos en los bucles para evitar bucles infinitos que puedan bloquear recursos del servidor.
-
Transacciones: Cuando se procesan grandes volúmenes de datos en bucles, considere utilizar transacciones y commits intermedios para evitar bloqueos prolongados y problemas de rendimiento.
-- Ejemplo de procesamiento por lotes en MySQL
DELIMITER //
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE id_cliente INT;
DECLARE contador INT DEFAULT 0;
DECLARE cur CURSOR FOR SELECT cliente_id FROM clientes WHERE actualizado = FALSE;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
START TRANSACTION;
OPEN cur;
read_loop: LOOP
FETCH cur INTO id_cliente;
IF done THEN
LEAVE read_loop;
END IF;
-- Procesar cliente
UPDATE clientes SET actualizado = TRUE WHERE cliente_id = id_cliente;
SET contador = contador + 1;
-- Commit cada 100 registros
IF contador % 100 = 0 THEN
COMMIT;
START TRANSACTION;
END IF;
END LOOP;
COMMIT;
CLOSE cur;
END //
DELIMITER ;
Diferencias clave entre MySQL y PostgreSQL
- Sintaxis: MySQL utiliza
END WHILE,END REPEAT, mientras que PostgreSQL usaEND LOOPpara todos los tipos de bucles. - Bucle FOR: PostgreSQL ofrece un bucle FOR nativo para iterar sobre rangos numéricos, mientras que MySQL no tiene esta característica.
- Etiquetas: En PostgreSQL, las etiquetas se encierran entre
<<y>>, mientras que en MySQL se separan con dos puntos. - Cursores: PostgreSQL permite una sintaxis más concisa para iterar sobre resultados de consultas con
FOR rec IN SELECT.... - Salto de iteración: MySQL utiliza
ITERATE, mientras que PostgreSQL usaCONTINUE.
Las estructuras de control iterativo son herramientas fundamentales para implementar lógica de programación avanzada en SQL, permitiendo crear procedimientos almacenados y funciones que pueden procesar datos de manera eficiente y flexible.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender cómo declarar y utilizar variables en SQL en MySQL y PostgreSQL. Aprender a implementar estructuras condicionales como IF, ELSEIF y CASE. Conocer las estructuras iterativas WHILE, REPEAT/LOOP y FOR para controlar la ejecución repetitiva. Diferenciar las particularidades sintácticas y funcionales entre MySQL y PostgreSQL. Aplicar estructuras de control para crear lógica de negocio en procedimientos almacenados y bloques de código.