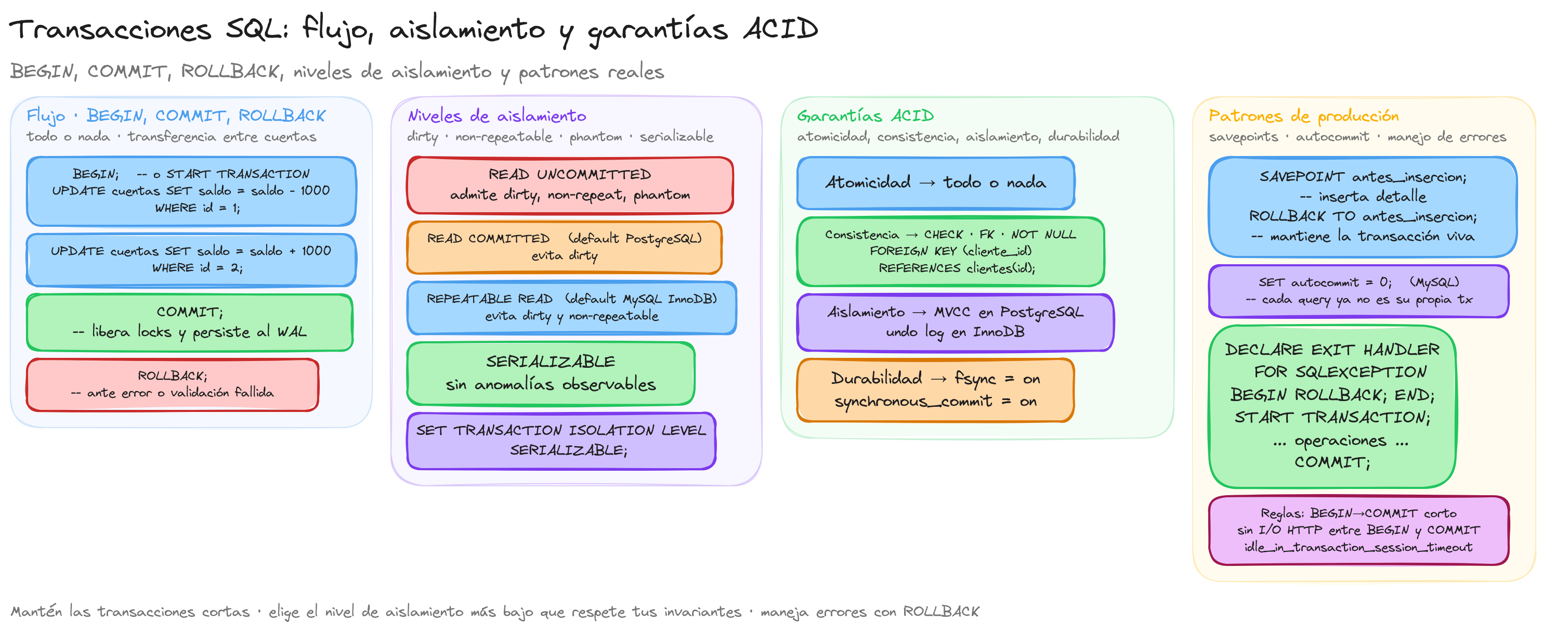
Concepto transacción
Una transacción en SQL representa una unidad lógica de trabajo que se ejecuta de manera completa o no se ejecuta en absoluto. Imagina que estás realizando una transferencia bancaria: debes restar dinero de una cuenta y sumarlo a otra. Ambas operaciones deben completarse correctamente o ninguna debe realizarse, para evitar inconsistencias en los datos.
Las transacciones son fundamentales para mantener la integridad de los datos en sistemas donde múltiples operaciones relacionadas deben tratarse como una sola unidad. Cada transacción debe cumplir con las propiedades ACID:
- Atomicidad: La transacción se ejecuta por completo o no se ejecuta.
- Consistencia: La base de datos pasa de un estado válido a otro estado válido.
- Aislamiento: Las transacciones se ejecutan de forma aislada, sin interferencias entre ellas.
- Durabilidad: Una vez completada la transacción, los cambios persisten incluso ante fallos del sistema.
Cuándo usar transacciones
Las transacciones son especialmente útiles en situaciones como:
- Operaciones financieras: Transferencias, pagos, compras.
- Gestión de inventario: Actualizar stock y registrar ventas simultáneamente.
- Reservas: Verificar disponibilidad y crear reserva en un solo paso.
- Registro de usuarios: Crear cuenta y configurar permisos iniciales.
Ejemplo básico de transacción
Veamos un ejemplo sencillo de una transacción que transfiere fondos entre dos cuentas:
-- Transferir 100 de la cuenta 1 a la cuenta 2
UPDATE cuentas SET saldo = saldo - 100 WHERE id = 1;
UPDATE cuentas SET saldo = saldo + 100 WHERE id = 2;
Sin una transacción, si la primera actualización se completa pero la segunda falla, el dinero "desaparecería" de la cuenta 1 sin llegar a la cuenta 2. Usando transacciones, podemos asegurar que ambas operaciones se completan o ninguna se realiza.
Estructura de una transacción
Una transacción típica en SQL sigue esta estructura básica:
- Inicio de la transacción: Marca el punto donde comienza la unidad lógica de trabajo.
- Operaciones SQL: Las consultas que modifican los datos (INSERT, UPDATE, DELETE).
- Finalización de la transacción: Puede ser un COMMIT (confirmar cambios) o un ROLLBACK (deshacer cambios).
Comportamiento de las transacciones
Cuando trabajamos con transacciones, es importante entender su comportamiento:
- Las transacciones bloquean recursos mientras están en progreso, lo que puede afectar al rendimiento si son muy largas.
- Cada sistema de gestión de bases de datos implementa las transacciones de manera ligeramente diferente.
- En MySQL, las tablas con motor InnoDB soportan transacciones, mientras que las tablas MyISAM no.
- PostgreSQL ofrece soporte completo para transacciones en todas sus tablas.
Ejemplo práctico en MySQL y PostgreSQL
Veamos cómo se vería una transacción simple en ambos sistemas:
-- Ejemplo en MySQL o PostgreSQL
START TRANSACTION;
-- Registrar una venta
INSERT INTO ventas (producto_id, cliente_id, cantidad, fecha)
VALUES (101, 202, 5, CURRENT_DATE);
-- Actualizar el inventario
UPDATE inventario SET stock = stock - 5
WHERE producto_id = 101;
-- Si todo está correcto, confirmar los cambios
COMMIT;
Si en algún momento detectamos un problema durante la transacción, podemos cancelarla:
-- Si hay algún problema
ROLLBACK;
Transacciones implícitas y explícitas
Existen dos formas de trabajar con transacciones:
- Transacciones explícitas: Las que iniciamos manualmente con START TRANSACTION o BEGIN.
- Transacciones implícitas: Algunas bases de datos ejecutan cada sentencia SQL como una transacción independiente si no se ha iniciado una transacción explícita.
En MySQL, podemos controlar este comportamiento con la variable autocommit:
-- Desactivar autocommit (cada sentencia ya no es una transacción independiente)
SET autocommit = 0;
-- Realizar operaciones...
-- Confirmar cambios manualmente
COMMIT;
-- Volver a activar autocommit
SET autocommit = 1;
Consideraciones prácticas
Al trabajar con transacciones, ten en cuenta estas recomendaciones:
- Mantén las transacciones lo más cortas posible para reducir bloqueos.
- No incluyas operaciones que no modifiquen datos (SELECT) a menos que necesites garantizar la consistencia de lectura.
- Evita interacciones con el usuario dentro de una transacción abierta.
- Asegúrate de manejar correctamente los errores para ejecutar ROLLBACK cuando sea necesario.
Las transacciones son una herramienta fundamental para garantizar la integridad de los datos en aplicaciones que requieren operaciones atómicas. Dominar su uso te permitirá desarrollar sistemas más robustos y confiables.
BEGIN/COMMIT
El control de transacciones en SQL se realiza principalmente mediante los comandos BEGIN y COMMIT, que permiten delimitar el inicio y la confirmación de una unidad lógica de trabajo. Estos comandos son fundamentales para implementar transacciones en bases de datos relacionales como MySQL y PostgreSQL.
Iniciando una transacción con BEGIN
Para iniciar una transacción explícita en SQL, utilizamos el comando BEGIN o alguna de sus variantes. Este comando indica a la base de datos que las operaciones siguientes deben tratarse como una unidad atómica:
-- Iniciar una transacción en PostgreSQL
BEGIN;
-- Alternativas en MySQL
START TRANSACTION;
-- o simplemente
BEGIN;
Una vez iniciada la transacción, todas las operaciones de modificación de datos (INSERT, UPDATE, DELETE) quedan en un estado pendiente hasta que se confirmen o se deshagan. Es importante entender que estos cambios son visibles para la conexión actual, pero no para otras conexiones a la base de datos.
Confirmando cambios con COMMIT
Cuando estamos seguros de que todas las operaciones dentro de la transacción se han completado correctamente, utilizamos el comando COMMIT para hacer permanentes los cambios:
-- Confirmar todos los cambios pendientes
COMMIT;
El comando COMMIT tiene los siguientes efectos:
- Hace que todos los cambios realizados durante la transacción sean permanentes
- Libera los bloqueos establecidos durante la transacción
- Marca el final de la unidad de trabajo
- Hace que los cambios sean visibles para otras conexiones
Ejemplo práctico: Registro de pedido
Veamos un ejemplo práctico donde usamos BEGIN y COMMIT para registrar un pedido y actualizar el inventario:
-- Iniciar la transacción
BEGIN;
-- Registrar el pedido
INSERT INTO pedidos (cliente_id, fecha, total)
VALUES (1001, CURRENT_DATE, 150.75);
-- Obtener el ID del pedido recién creado (PostgreSQL)
-- En MySQL usaríamos LAST_INSERT_ID()
SELECT @pedido_id := LAST_INSERT_ID();
-- Registrar los detalles del pedido
INSERT INTO detalles_pedido (pedido_id, producto_id, cantidad, precio_unitario)
VALUES (@pedido_id, 101, 2, 75.38);
-- Actualizar el inventario
UPDATE productos
SET stock = stock - 2
WHERE producto_id = 101;
-- Confirmar todos los cambios
COMMIT;
En este ejemplo, todas las operaciones se ejecutan como una unidad atómica. Si alguna de ellas fallara (por ejemplo, si no hay suficiente stock), podríamos cancelar toda la transacción con ROLLBACK en lugar de COMMIT.
Transacciones anidadas
Es importante mencionar que MySQL y PostgreSQL manejan las transacciones anidadas de manera diferente:
- PostgreSQL permite puntos de guardado (SAVEPOINT) dentro de una transacción, lo que proporciona un nivel de anidamiento parcial.
- MySQL con InnoDB no admite transacciones anidadas reales; un BEGIN dentro de una transacción existente simplemente se ignora.
-- En PostgreSQL podemos usar savepoints
BEGIN;
-- Operaciones iniciales
SAVEPOINT punto1;
-- Más operaciones
-- Si hay problemas con las últimas operaciones
ROLLBACK TO punto1;
-- Continuar con otras operaciones
COMMIT;
Autocommit
Tanto MySQL como PostgreSQL tienen un modo autocommit que, cuando está activado, trata cada sentencia SQL individual como una transacción separada. Por defecto, autocommit está activado en ambos sistemas.
-- Verificar el estado de autocommit en MySQL
SELECT @@autocommit;
-- Desactivar autocommit en MySQL
SET autocommit = 0;
-- En PostgreSQL
SHOW autocommit;
SET autocommit = OFF;
Cuando autocommit está desactivado, debemos usar COMMIT explícitamente para confirmar nuestros cambios, o estos permanecerán en un estado pendiente hasta que cerremos la conexión (lo que normalmente provocará un ROLLBACK).
Buenas prácticas con BEGIN/COMMIT
Para trabajar eficientemente con transacciones:
-
Mantén las transacciones cortas: Las transacciones largas mantienen bloqueos por más tiempo, afectando el rendimiento.
-
Agrupa operaciones relacionadas: Incluye en la misma transacción solo las operaciones que deben ejecutarse como una unidad lógica.
-
Evita operaciones externas: No incluyas llamadas a APIs o interacciones con el usuario dentro de una transacción abierta.
-
Maneja los errores adecuadamente: Implementa manejo de excepciones para ejecutar ROLLBACK cuando sea necesario.
-- Ejemplo de patrón en un procedimiento almacenado (MySQL)
DELIMITER //
CREATE PROCEDURE transferir_fondos(origen INT, destino INT, monto DECIMAL)
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
ROLLBACK;
SELECT 'Error en la transacción' AS mensaje;
END;
START TRANSACTION;
UPDATE cuentas SET saldo = saldo - monto WHERE id = origen;
UPDATE cuentas SET saldo = saldo + monto WHERE id = destino;
COMMIT;
SELECT 'Transferencia completada' AS mensaje;
END //
DELIMITER ;
Diferencias entre MySQL y PostgreSQL
Aunque los conceptos básicos son similares, existen algunas diferencias en la sintaxis y comportamiento:
- En PostgreSQL, puedes usar
BEGIN TRANSACTIONo simplementeBEGIN. - En MySQL, se prefiere
START TRANSACTION, aunqueBEGINtambién funciona. - PostgreSQL ofrece opciones adicionales como
BEGIN ISOLATION LEVEL...para especificar el nivel de aislamiento. - MySQL requiere tablas InnoDB para soporte de transacciones completo.
-- PostgreSQL: iniciar transacción con nivel de aislamiento específico
BEGIN ISOLATION LEVEL SERIALIZABLE;
-- MySQL: verificar que la tabla use InnoDB
SHOW TABLE STATUS WHERE Name = 'nombre_tabla';
Dominar el uso de BEGIN y COMMIT es esencial para desarrollar aplicaciones que manipulen datos de forma segura y mantengan la integridad de la información en situaciones donde múltiples operaciones deben ejecutarse como una unidad atómica.
Niveles de aislamiento
Los niveles de aislamiento en SQL definen el grado en que las operaciones de una transacción permanecen aisladas de otras transacciones concurrentes. Estos niveles determinan cómo se comportan las transacciones cuando múltiples usuarios o procesos acceden simultáneamente a los mismos datos, estableciendo un equilibrio entre consistencia y rendimiento.
El estándar SQL define cuatro niveles de aislamiento, cada uno con diferentes garantías respecto a los fenómenos de concurrencia que pueden ocurrir:
- Lecturas sucias: Una transacción lee datos que otra transacción ha modificado pero aún no ha confirmado.
- Lecturas no repetibles: Una transacción relee datos y encuentra que otra transacción los ha modificado después de la primera lectura.
- Lecturas fantasma: Una transacción ejecuta una consulta que devuelve un conjunto de filas, pero otra transacción inserta nuevas filas que cumplirían con los criterios de la consulta original.
Nivel READ UNCOMMITTED
Este es el nivel de aislamiento más bajo y ofrece el mejor rendimiento a costa de la consistencia. En este nivel:
-- Establecer el nivel de aislamiento en MySQL
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- En PostgreSQL
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
Características principales:
- Permite lecturas sucias: una transacción puede ver cambios no confirmados realizados por otras transacciones.
- No proporciona protección contra lecturas no repetibles ni lecturas fantasma.
- Ofrece el máximo rendimiento pero la menor consistencia.
Ejemplo de situación problemática:
-- Transacción 1
BEGIN;
UPDATE productos SET precio = 150 WHERE id = 1;
-- Sin COMMIT todavía
-- Transacción 2 (en otra conexión, con READ UNCOMMITTED)
BEGIN;
SELECT precio FROM productos WHERE id = 1; -- Podría ver el precio 150 aunque no esté confirmado
COMMIT;
-- Transacción 1 decide cancelar
ROLLBACK; -- El precio vuelve al valor original
En este escenario, la Transacción 2 ha basado su operación en un dato que nunca llegó a existir realmente.
Nivel READ COMMITTED
Este nivel es el predeterminado en PostgreSQL y proporciona un mejor equilibrio entre rendimiento y consistencia:
-- Establecer el nivel de aislamiento
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
Características principales:
- Evita lecturas sucias: una transacción solo puede ver cambios que han sido confirmados por otras transacciones.
- No protege contra lecturas no repetibles ni lecturas fantasma.
- Es adecuado para entornos donde la consistencia absoluta no es crítica.
Ejemplo práctico:
-- Transacción 1
BEGIN;
UPDATE clientes SET saldo = saldo - 100 WHERE id = 1;
-- Sin COMMIT todavía
-- Transacción 2 (en otra conexión, con READ COMMITTED)
BEGIN;
SELECT saldo FROM clientes WHERE id = 1; -- Verá el saldo original, no el modificado
COMMIT;
-- Transacción 1 ahora confirma
COMMIT;
-- Si Transacción 2 vuelve a consultar, verá el nuevo valor
BEGIN;
SELECT saldo FROM clientes WHERE id = 1; -- Ahora verá el saldo actualizado
COMMIT;
Nivel REPEATABLE READ
Este nivel es el predeterminado en MySQL (InnoDB) y proporciona mayor consistencia:
-- Establecer el nivel de aislamiento
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Características principales:
- Evita lecturas sucias y no repetibles: garantiza que si una transacción lee una fila, esa fila aparecerá igual en lecturas posteriores dentro de la misma transacción.
- En MySQL (InnoDB), también evita lecturas fantasma mediante bloqueos de rango.
- En PostgreSQL, no protege completamente contra lecturas fantasma.
Ejemplo ilustrativo:
-- Transacción 1
BEGIN;
SELECT * FROM productos WHERE precio < 100; -- Devuelve productos A, B, C
-- Transacción 2 (en otra conexión)
BEGIN;
UPDATE productos SET precio = 90 WHERE nombre = 'D'; -- Producto D ahora cuesta menos de 100
COMMIT;
-- Transacción 1 continúa
SELECT * FROM productos WHERE precio < 100; -- Sigue devolviendo solo A, B, C en REPEATABLE READ
COMMIT;
Nivel SERIALIZABLE
Este es el nivel de aislamiento más estricto y garantiza la máxima consistencia:
-- Establecer el nivel de aislamiento
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Características principales:
- Evita todos los problemas de concurrencia: lecturas sucias, lecturas no repetibles y lecturas fantasma.
- Las transacciones se comportan como si se ejecutaran una después de otra (en serie).
- Puede provocar más bloqueos y tiempos de espera, afectando al rendimiento.
Ejemplo de uso:
-- Transacción 1
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SELECT SUM(cantidad) FROM inventario WHERE producto_id = 101;
-- Usa este valor para tomar decisiones
-- Transacción 2 (en otra conexión)
BEGIN;
INSERT INTO inventario (producto_id, cantidad, ubicacion) VALUES (101, 50, 'Almacén B');
COMMIT;
-- Transacción 1 continúa
-- En SERIALIZABLE, esta consulta devolverá el mismo resultado que antes,
-- o la transacción fallará con un error de serialización
SELECT SUM(cantidad) FROM inventario WHERE producto_id = 101;
COMMIT;
Diferencias entre MySQL y PostgreSQL
Aunque ambos sistemas implementan los cuatro niveles estándar, existen algunas diferencias importantes:
-
MySQL (InnoDB):
-
El nivel predeterminado es REPEATABLE READ.
-
Implementa REPEATABLE READ de manera que también previene lecturas fantasma en la mayoría de los casos.
-
Utiliza bloqueos de rango para implementar SERIALIZABLE.
-
PostgreSQL:
-
El nivel predeterminado es READ COMMITTED.
-
Implementa SERIALIZABLE mediante un sistema de control de concurrencia multiversión (MVCC) con detección de conflictos de serialización.
-
Puede generar errores de serialización que requieren reintentar la transacción.
Selección del nivel adecuado
La elección del nivel de aislamiento depende de los requisitos específicos de tu aplicación:
-
READ UNCOMMITTED: Raramente recomendado, excepto para operaciones de solo lectura donde la consistencia no es crítica, como informes aproximados.
-
READ COMMITTED: Adecuado para la mayoría de las aplicaciones donde se necesita un buen equilibrio entre rendimiento y consistencia.
-
REPEATABLE READ: Recomendado cuando necesitas garantizar que los datos no cambien durante una transacción, como en cálculos financieros.
-
SERIALIZABLE: Necesario para aplicaciones que requieren la máxima consistencia, como sistemas bancarios o de reservas, donde cualquier anomalía podría tener consecuencias graves.
Configuración a nivel de sesión o transacción
Puedes establecer el nivel de aislamiento para toda la sesión o solo para una transacción específica:
-- Nivel de aislamiento para toda la sesión
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Nivel solo para la próxima transacción
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN;
-- Operaciones...
COMMIT;
Verificación del nivel actual
Para verificar el nivel de aislamiento actual:
-- En MySQL
SELECT @@transaction_isolation;
-- En PostgreSQL
SHOW transaction_isolation;
Entender y utilizar correctamente los niveles de aislamiento es fundamental para desarrollar aplicaciones de bases de datos robustas que manejen adecuadamente la concurrencia. El nivel apropiado te permitirá equilibrar la consistencia de los datos con el rendimiento del sistema según las necesidades específicas de tu aplicación.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el concepto y las propiedades ACID de las transacciones. Aprender a iniciar, confirmar y deshacer transacciones con BEGIN, COMMIT y ROLLBACK. Diferenciar entre transacciones explícitas e implícitas y su manejo en MySQL y PostgreSQL. Conocer los niveles de aislamiento y su impacto en la concurrencia y consistencia de datos. Aplicar buenas prácticas para el uso eficiente y seguro de transacciones en bases de datos relacionales.