BBDD Relacionales SQL
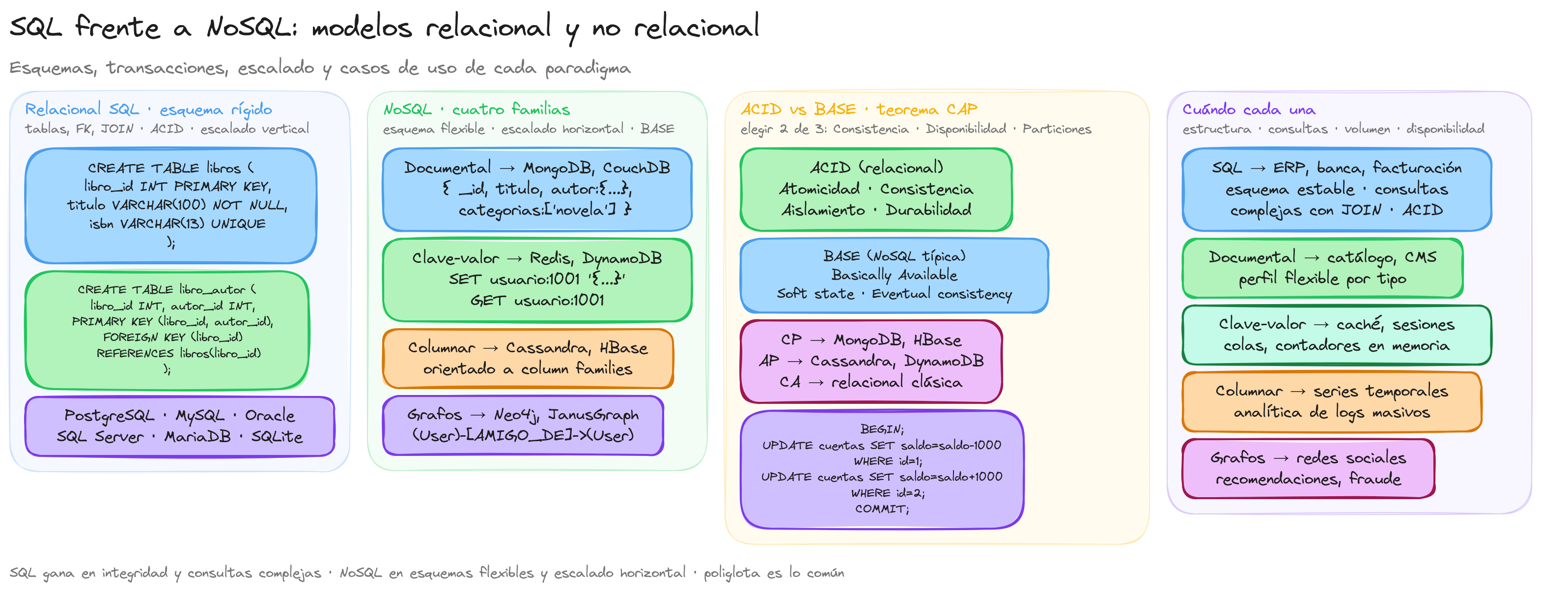
Las bases de datos relacionales constituyen el fundamento de la gestión de datos estructurados en sistemas informáticos desde hace más de cuatro décadas. Estas bases de datos organizan la información en tablas bidimensionales que se relacionan entre sí mediante claves, permitiendo representar y consultar datos de manera eficiente y consistente.
Fundamentos del modelo relacional
El modelo relacional, propuesto por Edgar F. Codd en 1970, se basa en la teoría de conjuntos y la lógica de predicados. Sus componentes fundamentales son:
- Tablas (relaciones): Estructuras bidimensionales compuestas por filas y columnas donde se almacenan los datos.
- Tuplas (filas): Cada fila representa un registro o instancia de la entidad que modela la tabla.
- Atributos (columnas): Definen las propiedades o características de la entidad.
- Claves primarias: Identificadores únicos para cada registro en una tabla.
- Claves foráneas: Referencias a claves primarias de otras tablas que establecen relaciones.
Características principales
Las bases de datos relacionales SQL se caracterizan por:
- Integridad de datos: Implementan restricciones como claves primarias, foráneas y reglas de validación que garantizan la consistencia de la información.
- Normalización: Proceso de diseño que minimiza la redundancia y dependencias mediante la división de tablas grandes en otras más pequeñas y relacionadas. Las formas normales (1FN, 2FN, 3FN, etc.) proporcionan guías para este proceso.
- Transacciones ACID: Garantizan que las operaciones cumplan con las propiedades de:
- Atomicidad: Las transacciones se ejecutan completamente o no se ejecutan.
- Consistencia: La base de datos pasa de un estado válido a otro válido.
- Aislamiento: Las transacciones concurrentes no interfieren entre sí.
- Durabilidad: Los cambios confirmados persisten incluso ante fallos del sistema.
- Lenguaje SQL estandarizado: Proporciona una interfaz común para definir, manipular y consultar datos.
Estructura de una base de datos relacional
Una base de datos relacional típica se organiza en varios niveles:
- Base de datos: Contenedor principal que agrupa todas las estructuras de datos relacionadas.
- Esquemas: Agrupaciones lógicas de objetos dentro de una base de datos.
- Tablas: Estructuras que almacenan los datos en filas y columnas.
- Vistas: Tablas virtuales basadas en consultas que presentan datos de una o más tablas.
- Índices: Estructuras que optimizan la búsqueda y recuperación de datos.
- Procedimientos almacenados y funciones: Código SQL que encapsula lógica de negocio.
Ejemplo de estructura relacional
Consideremos un sistema simple de gestión de una biblioteca:
-- Tabla de autores
CREATE TABLE autores (
autor_id INT PRIMARY KEY,
nombre VARCHAR(50) NOT NULL,
apellido VARCHAR(50) NOT NULL,
fecha_nacimiento DATE
);
-- Tabla de libros
CREATE TABLE libros (
libro_id INT PRIMARY KEY,
titulo VARCHAR(100) NOT NULL,
isbn VARCHAR(13) UNIQUE,
anio_publicacion INT,
editorial VARCHAR(50)
);
-- Tabla de relación entre libros y autores (muchos a muchos)
CREATE TABLE libro_autor (
libro_id INT,
autor_id INT,
PRIMARY KEY (libro_id, autor_id),
FOREIGN KEY (libro_id) REFERENCES libros(libro_id),
FOREIGN KEY (autor_id) REFERENCES autores(autor_id)
);
Este ejemplo muestra cómo se implementa una relación muchos a muchos entre libros y autores, donde un libro puede tener varios autores y un autor puede escribir varios libros.
Sistemas de gestión de bases de datos relacionales (RDBMS)
Los principales sistemas que implementan el modelo relacional incluyen:
- MySQL: Sistema de código abierto, ahora propiedad de Oracle, conocido por su rendimiento y facilidad de uso.
- PostgreSQL: Sistema de código abierto con características avanzadas y extensible.
- Oracle Database: Sistema comercial con amplio soporte para aplicaciones empresariales.
- Microsoft SQL Server: Solución de Microsoft para entornos empresariales.
- MariaDB: Fork de MySQL con licencia completamente abierta.
- SQLite: Base de datos ligera basada en archivos, ideal para aplicaciones embebidas.
Ventajas de las bases de datos relacionales
- Madurez y estabilidad: Tecnología probada con décadas de desarrollo y optimización.
- Consistencia de datos: Garantías ACID que aseguran la integridad de la información.
- Flexibilidad en consultas: SQL permite realizar consultas complejas de manera declarativa.
- Soporte para transacciones: Manejo adecuado de operaciones concurrentes.
- Escalabilidad vertical: Aprovechan eficientemente recursos de hardware más potentes.
- Amplio ecosistema: Herramientas, documentación y profesionales disponibles.
Limitaciones
- Escalabilidad horizontal: Presentan desafíos para distribuirse en múltiples servidores.
- Esquemas rígidos: Los cambios en la estructura pueden ser complejos una vez que hay datos.
- Impedancia objeto-relacional: Requieren mapeo adicional cuando se usan con lenguajes orientados a objetos.
- Rendimiento con grandes volúmenes: Pueden presentar cuellos de botella con conjuntos de datos extremadamente grandes.
Casos de uso ideales
Las bases de datos relacionales SQL son particularmente adecuadas para:
- Sistemas financieros y bancarios: Donde la integridad transaccional es crítica.
- Sistemas de gestión empresarial (ERP, CRM): Con relaciones complejas entre entidades.
- Aplicaciones con esquemas bien definidos: Donde la estructura de datos es estable.
- Sistemas que requieren consultas complejas: Análisis de datos con múltiples relaciones.
- Aplicaciones con requisitos de cumplimiento normativo: Donde se necesita garantizar la integridad y trazabilidad.
Las bases de datos relacionales SQL siguen siendo la opción predominante para la mayoría de las aplicaciones empresariales debido a su robustez, confiabilidad y capacidad para manejar datos estructurados con garantías de integridad.
Modelos NoSQL
Las bases de datos NoSQL (Not Only SQL) surgieron como respuesta a las limitaciones que presentan las bases de datos relacionales tradicionales para ciertos casos de uso modernos. Estos sistemas de gestión de datos están diseñados específicamente para manejar grandes volúmenes de información no estructurada o semiestructurada, ofrecer alta disponibilidad y facilitar la escalabilidad horizontal.
Tipos principales de bases de datos NoSQL
Existen cuatro categorías fundamentales de bases de datos NoSQL, cada una optimizada para diferentes patrones de datos y casos de uso:
- Bases de datos de documentos: Almacenan datos en documentos similares a JSON o BSON. Cada documento contiene pares de campo-valor y puede tener una estructura flexible. Ejemplos:
{
"_id": "libro123",
"titulo": "Cien años de soledad",
"autor": {
"nombre": "Gabriel",
"apellido": "García Márquez"
},
"categorias": ["novela", "realismo mágico"],
"disponible": true,
"prestamos": [
{ "usuario": "user456", "fecha": "2023-05-10" }
]
}
MongoDB, CouchDB y Amazon DocumentDB son implementaciones populares de este modelo.
- Bases de datos clave-valor: El modelo más simple, donde cada elemento se almacena como un par clave-valor. Son extremadamente eficientes para operaciones de lectura/escritura simples:
SET usuario:1001 "{"nombre":"Ana","email":"ana@ejemplo.com"}"
GET usuario:1001
Redis, DynamoDB y Riak son ejemplos destacados de este tipo.
- Bases de datos columnares: Organizan los datos por columnas en lugar de por filas, lo que resulta muy eficiente para consultas analíticas sobre grandes conjuntos de datos:
RowKey | familia:columna1 | familia:columna2
-------+------------------+------------------
row1 | valor1 | valor2
row2 | valor3 | valor4
Cassandra, HBase y Google Bigtable son implementaciones conocidas.
- Bases de datos de grafos: Optimizadas para datos interconectados, almacenan entidades como nodos y relaciones como aristas, permitiendo recorrer eficientemente redes complejas de información:
(Usuario {nombre: "Juan"}) -[AMIGO_DE]-> (Usuario {nombre: "María"})
(Usuario {nombre: "María"}) -[COMPRÓ]-> (Producto {nombre: "Laptop"})
Neo4j, JanusGraph y Amazon Neptune son sistemas populares de este tipo.
Características comunes de los sistemas NoSQL
A pesar de sus diferencias, las bases de datos NoSQL comparten varias características fundamentales:
- Esquemas flexibles: A diferencia de las bases de datos relacionales, los sistemas NoSQL generalmente no requieren un esquema predefinido. Los datos pueden tener estructuras variables, lo que facilita la evolución de las aplicaciones sin migraciones complejas.
- Escalabilidad horizontal: Están diseñadas para distribuirse fácilmente entre múltiples servidores mediante técnicas de particionamiento (sharding) y replicación. Esto permite añadir capacidad simplemente agregando más nodos al cluster.
- Teorema CAP: Las bases de datos NoSQL se diseñan considerando el teorema CAP, que establece que un sistema distribuido solo puede garantizar simultáneamente dos de estas tres propiedades:
- Consistencia: Todos los nodos ven los mismos datos al mismo tiempo
- Disponibilidad: Cada petición recibe una respuesta
- Tolerancia a particiones: El sistema continúa funcionando a pesar de fallos en la red
- Consistencia eventual: Muchos sistemas NoSQL priorizan la disponibilidad sobre la consistencia inmediata, implementando un modelo de consistencia eventual donde los cambios se propagan gradualmente a todos los nodos.
- Alto rendimiento: Optimizadas para operaciones específicas según su tipo, ofrecen mejor desempeño que las bases de datos relacionales en ciertos escenarios.
Patrones de diseño NoSQL
El diseño de datos en NoSQL difiere significativamente del enfoque relacional:
- Desnormalización: En lugar de normalizar los datos en múltiples tablas, a menudo se duplican para optimizar las consultas. Por ejemplo, en una base de datos documental, podríamos incluir información del autor directamente en el documento del libro.
- Diseño orientado a consultas: La estructura de los datos se diseña pensando en los patrones de acceso específicos de la aplicación, no en minimizar la redundancia.
- Agregados: Los datos relacionados se agrupan en "agregados" que se manipulan como una unidad, reduciendo la necesidad de operaciones que abarquen múltiples colecciones.
// Documento que representa un pedido completo con sus líneas
{
"pedido_id": "ord123",
"cliente": "cli456",
"fecha": "2023-06-15",
"estado": "enviado",
"lineas": [
{ "producto": "prod789", "cantidad": 2, "precio": 29.99 },
{ "producto": "prod555", "cantidad": 1, "precio": 49.99 }
],
"total": 109.97
}
Casos de uso ideales para NoSQL
Las bases de datos NoSQL destacan particularmente en:
- Big Data: Manejo de volúmenes masivos de datos que superan la capacidad práctica de los sistemas relacionales.
- Aplicaciones web a gran escala: Sitios como redes sociales que requieren alta disponibilidad y escalabilidad.
- Internet de las cosas (IoT): Captura y procesamiento de flujos continuos de datos de sensores.
- Análisis en tiempo real: Procesamiento de grandes volúmenes de datos para obtener insights inmediatos.
- Catálogos de productos: Especialmente cuando los productos tienen atributos variables (como en e-commerce).
- Gestión de contenidos: Sistemas que manejan contenido con estructura flexible.
- Aplicaciones móviles: Que requieren sincronización offline y eventual consistency.
Implementaciones populares
Algunas de las bases de datos NoSQL más utilizadas incluyen:
- MongoDB: Base de datos documental de propósito general, con un equilibrio entre funcionalidad y facilidad de uso.
- Redis: Almacén clave-valor en memoria con estructuras de datos avanzadas y persistencia opcional.
- Cassandra: Base de datos columnar distribuida diseñada para alta disponibilidad y escalabilidad lineal.
- Neo4j: Base de datos de grafos con un potente lenguaje de consulta (Cypher) para recorrer relaciones.
- Elasticsearch: Motor de búsqueda distribuido que también funciona como base de datos documental.
- DynamoDB: Servicio de base de datos NoSQL totalmente gestionado por Amazon Web Services.
Consideraciones para la elección
Al evaluar si una base de datos NoSQL es adecuada para un proyecto, es importante considerar:
- Estructura de los datos: ¿Son altamente estructurados o variables?
- Patrones de consulta: ¿Se necesitan consultas complejas con múltiples joins?
- Requisitos de consistencia: ¿Es aceptable la consistencia eventual?
- Volumen y velocidad: ¿Qué cantidad de datos y qué tasa de crecimiento se espera?
- Disponibilidad requerida: ¿Cuál es el tiempo de inactividad aceptable?
Las bases de datos NoSQL no reemplazan a los sistemas relacionales, sino que los complementan, ofreciendo soluciones optimizadas para casos de uso específicos donde las bases de datos tradicionales muestran limitaciones. La elección entre SQL y NoSQL debe basarse en un análisis cuidadoso de los requisitos del proyecto y las características de cada tecnología.
SQL vs NoSQL: criterios
La elección entre bases de datos SQL y NoSQL representa una de las decisiones arquitectónicas más importantes al diseñar sistemas de información modernos. Cada paradigma ofrece ventajas distintas y está optimizado para diferentes escenarios. Comprender los criterios clave de comparación permite seleccionar la tecnología más adecuada para cada proyecto específico.
Estructura de datos y esquema
- SQL: Impone un esquema rígido donde la estructura de datos debe definirse antes de insertar información. Cualquier modificación posterior requiere operaciones ALTER TABLE que pueden ser costosas en bases de datos grandes.
CREATE TABLE productos (
id INT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
precio DECIMAL(10,2),
categoria_id INT,
FOREIGN KEY (categoria_id) REFERENCES categorias(id)
);
- NoSQL: Ofrece esquemas flexibles o incluso ausencia de esquema predefinido. En bases documentales como MongoDB, dos documentos en la misma colección pueden tener estructuras diferentes:
// Primer documento
{
"_id": "prod1",
"nombre": "Laptop",
"precio": 899.99,
"especificaciones": {
"ram": "16GB",
"procesador": "i7"
}
}
// Segundo documento en la misma colección
{
"_id": "prod2",
"nombre": "Smartphone",
"precio": 499.99,
"colores_disponibles": ["negro", "blanco", "azul"]
}
Esta flexibilidad facilita la evolución de aplicaciones sin migraciones complejas, pero requiere que la lógica de validación se implemente en la capa de aplicación.
Modelo de consulta
- SQL: Utiliza un lenguaje declarativo estandarizado (SQL) que permite realizar consultas complejas con múltiples condiciones, agrupaciones y joins entre tablas:
SELECT c.nombre AS categoria, AVG(p.precio) AS precio_promedio
FROM productos p
JOIN categorias c ON p.categoria_id = c.id
WHERE p.precio > 100
GROUP BY c.nombre
HAVING COUNT(*) > 5
ORDER BY precio_promedio DESC;
- NoSQL: Cada tipo de base de datos NoSQL implementa su propio modelo de consulta especializado, generalmente optimizado para patrones de acceso específicos:
// Consulta en MongoDB
db.productos.aggregate([
{ $match: { precio: { $gt: 100 } } },
{ $lookup: {
from: "categorias",
localField: "categoria_id",
foreignField: "_id",
as: "categoria"
}
},
{ $unwind: "$categoria" },
{ $group: {
_id: "$categoria.nombre",
precio_promedio: { $avg: "$precio" },
count: { $sum: 1 }
}
},
{ $match: { count: { $gt: 5 } } },
{ $sort: { precio_promedio: -1 } }
]);
Las bases NoSQL suelen ofrecer APIs específicas para cada lenguaje de programación, mientras que SQL proporciona una interfaz universal.
Transacciones y consistencia de datos
- SQL: Implementa el modelo ACID completo, garantizando que las transacciones sean atómicas, consistentes, aisladas y duraderas. Esto es crucial para aplicaciones donde la integridad de los datos es prioritaria:
BEGIN TRANSACTION;
UPDATE cuentas SET saldo = saldo - 1000 WHERE id = 1;
UPDATE cuentas SET saldo = saldo + 1000 WHERE id = 2;
COMMIT;
- NoSQL: Muchas bases de datos NoSQL siguen el modelo BASE (Basically Available, Soft state, Eventually consistent):
- Disponibilidad básica: El sistema responde la mayoría del tiempo
- Estado flexible: El estado puede cambiar sin intervención externa
- Consistencia eventual: El sistema será consistente en algún momento
Algunas bases NoSQL modernas como MongoDB han incorporado soporte para transacciones ACID, pero generalmente con limitaciones o impacto en el rendimiento:
// Transacción en MongoDB
const session = db.getMongo().startSession();
session.startTransaction();
try {
db.cuentas.updateOne(
{ _id: 1 }, { $inc: { saldo: -1000 } }, { session }
);
db.cuentas.updateOne(
{ _id: 2 }, { $inc: { saldo: 1000 } }, { session }
);
session.commitTransaction();
} catch (error) {
session.abortTransaction();
}
Escalabilidad
SQL: Tradicionalmente optimizado para escalabilidad vertical (aumentar recursos en un único servidor). La implementación de clusters distribuidos es posible pero compleja y a menudo requiere soluciones comerciales costosas.
NoSQL: Diseñado desde su concepción para escalabilidad horizontal mediante la distribución de datos entre múltiples nodos. Implementa técnicas como:
- Particionamiento (sharding): División de datos entre servidores según algún criterio
- Replicación: Copias redundantes para aumentar disponibilidad y rendimiento
// Configuración de sharding en MongoDB
sh.enableSharding("miBaseDeDatos");
sh.shardCollection("miBaseDeDatos.productos", { categoria: 1 });
Esta arquitectura distribuida permite a las bases NoSQL manejar volúmenes de datos masivos y cargas de trabajo intensivas.
Rendimiento
SQL: Ofrece rendimiento optimizado para:
- Consultas complejas con múltiples joins
- Operaciones transaccionales
- Datos altamente relacionados
NoSQL: Proporciona mejor rendimiento en:
- Operaciones de lectura/escritura simples a gran escala
- Datos con estructura variable
- Consultas por clave primaria
- Escrituras masivas de datos
Las bases NoSQL suelen sacrificar algunas capacidades de consulta para lograr mayor rendimiento en operaciones específicas.
Madurez y ecosistema
SQL: Tecnología con más de 40 años de desarrollo, cuenta con:
- Amplia documentación y recursos de aprendizaje
- Herramientas maduras de administración y monitoreo
- Estándares bien establecidos
- Gran cantidad de profesionales experimentados
NoSQL: Tecnologías relativamente más recientes con:
- Ecosistemas en rápida evolución
- Menor estandarización entre diferentes implementaciones
- Comunidades activas pero más pequeñas
- Menos herramientas de terceros para administración
Casos de uso óptimos
- SQL es preferible cuando:
- La estructura de datos es predecible y estable
- Se requieren transacciones complejas que afecten múltiples registros
- Las relaciones entre entidades son fundamentales
- Se necesitan consultas ad-hoc complejas
- La integridad referencial es crítica
-- Consulta analítica compleja en SQL
SELECT
d.nombre_departamento,
COUNT(e.id) AS num_empleados,
AVG(e.salario) AS salario_promedio,
SUM(v.monto) AS ventas_totales
FROM empleados e
JOIN departamentos d ON e.departamento_id = d.id
LEFT JOIN ventas v ON v.empleado_id = e.id
WHERE e.fecha_contratacion > '2020-01-01'
GROUP BY d.nombre_departamento
HAVING COUNT(e.id) > 5
ORDER BY ventas_totales DESC;
- NoSQL es preferible cuando:
- Se manejan grandes volúmenes de datos no estructurados o semiestructurados
- Se requiere alta disponibilidad y tolerancia a fallos
- El esquema de datos evoluciona frecuentemente
- La aplicación necesita escalabilidad horizontal
- Los patrones de acceso son simples y predecibles
// Operación de alta disponibilidad en Cassandra
// Escritura con nivel de consistencia LOCAL_QUORUM
session.execute(
'INSERT INTO sensores (id, timestamp, temperatura, humedad) VALUES (?, ?, ?, ?)',
[sensorId, new Date(), 22.5, 65],
{ consistency: cassandra.consistencies.localQuorum }
);
Enfoque híbrido
Muchas organizaciones implementan arquitecturas políglota persistencia, utilizando diferentes bases de datos para distintos componentes del sistema:
- SQL: Para datos transaccionales críticos y reportes complejos
- Documentales (MongoDB): Para contenido con estructura variable
- Clave-valor (Redis): Para caché y datos temporales
- Columnares (Cassandra): Para series temporales y telemetría
- Grafos (Neo4j): Para datos altamente relacionados
┌─────────────────────────────────────┐
│ Aplicación │
└───────────┬─────────┬───────────────┘
│ │
┌───────────▼─┐ ┌─────▼───────┐ ┌─────▼─────┐
│ PostgreSQL │ │ MongoDB │ │ Redis │
│ (Finanzas) │ │ (Catálogo) │ │ (Caché) │
└─────────────┘ └─────────────┘ └───────────┘
Consideraciones de migración
Al evaluar una migración entre paradigmas, es importante considerar:
- Complejidad de transformación: Convertir un modelo relacional a NoSQL (o viceversa) puede requerir rediseño significativo.
- Curva de aprendizaje: El equipo necesitará adquirir nuevas habilidades.
- Impacto en aplicaciones existentes: Posibles cambios en la lógica de negocio y capa de acceso a datos.
- Costos operativos: Diferentes requisitos de infraestructura y administración.
La decisión entre SQL y NoSQL no debe basarse en tendencias tecnológicas, sino en un análisis detallado de los requisitos específicos del proyecto, considerando factores como estructura de datos, patrones de consulta, volumen esperado, requisitos de consistencia y escalabilidad futura.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el modelo relacional y sus componentes fundamentales. Identificar las características y ventajas de las bases de datos relacionales SQL. Conocer los diferentes tipos de bases de datos NoSQL y sus características comunes. Analizar criterios para elegir entre bases de datos SQL y NoSQL según el caso de uso. Reconocer las implicaciones de escalabilidad, consistencia y rendimiento en ambos paradigmas.