CREATE PROCEDURE
flowchart TB
Cliente["Cliente: aplicación o psql"] --> Call[CALL procedimiento argumentos]
Call --> Server[Servidor de base de datos]
Server --> Plan[Plan precompilado en cache]
Plan --> Exec["Ejecutor: variables, control de flujo"]
Exec --> Vars["DECLARE: variables locales"]
Exec --> If["IF/WHILE/FOR: control de flujo"]
Exec --> SQL["SQL embebido: SELECT, INSERT, UPDATE"]
SQL --> Resultado[Resultado o filas afectadas]
Resultado --> OutParams["Parámetros OUT/INOUT actualizados"]
OutParams --> Cliente
Server -. PostgreSQL: PL/pgSQL .-> Lang[CREATE FUNCTION LANGUAGE plpgsql]
Server -. MySQL .-> Mysql[CREATE PROCEDURE BEGIN END]
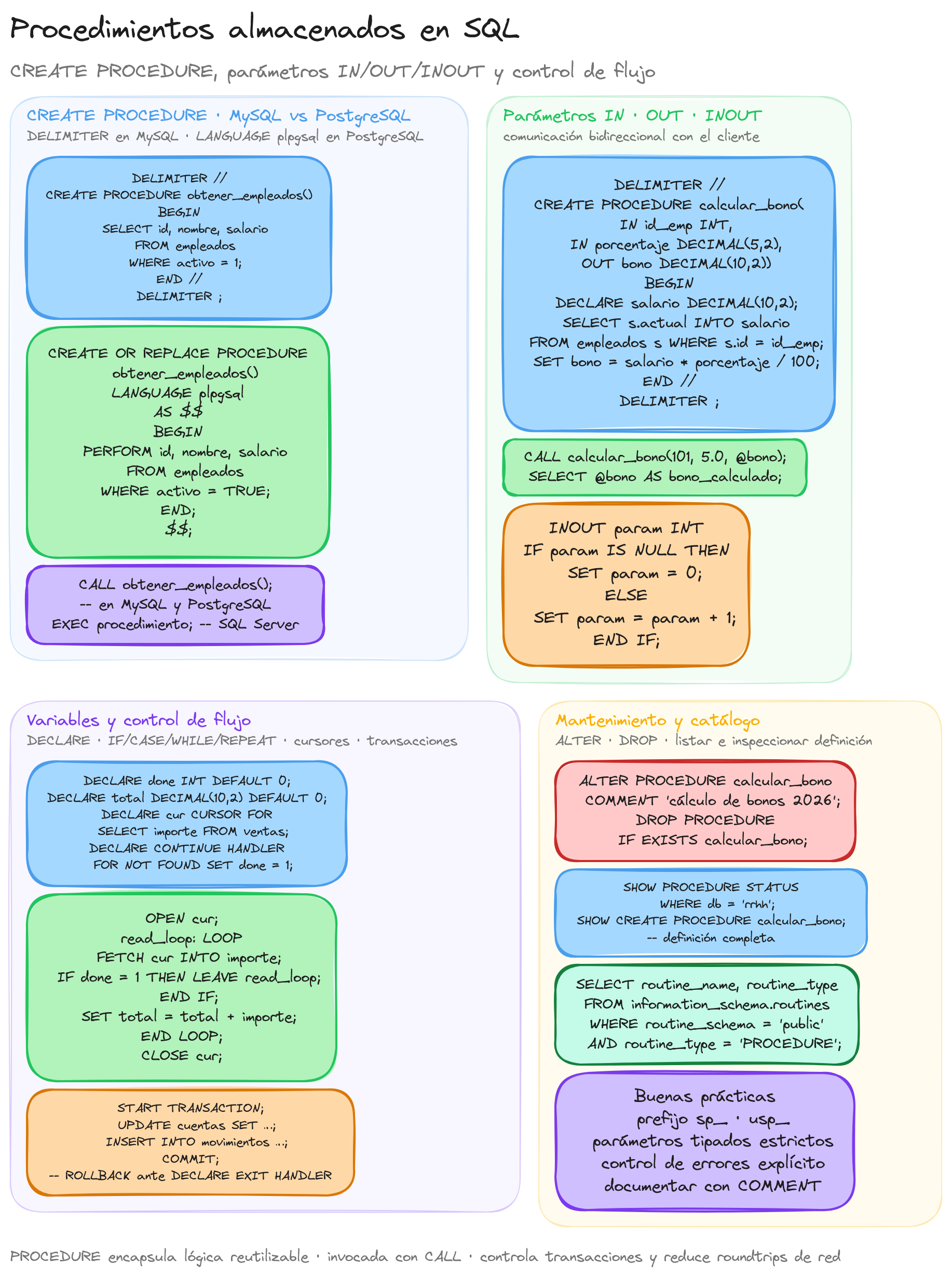
Los procedimientos almacenados son bloques de código SQL que se guardan en la base de datos para su posterior reutilización. Funcionan como pequeños programas que encapsulan lógica de negocio y operaciones complejas, permitiendo ejecutarlas mediante una simple llamada.
Sintaxis básica
La creación de un procedimiento almacenado se realiza mediante la sentencia CREATE PROCEDURE. La sintaxis general es:
CREATE PROCEDURE nombre_procedimiento ([parámetros])
BEGIN
-- Cuerpo del procedimiento (instrucciones SQL)
END;
En MySQL, es necesario cambiar temporalmente el delimitador antes de crear un procedimiento, ya que el cuerpo del mismo contiene puntos y comas que podrían confundirse con el final de la sentencia:
DELIMITER //
CREATE PROCEDURE obtener_empleados()
BEGIN
SELECT * FROM empleados;
END //
DELIMITER ;
En PostgreSQL, la sintaxis es ligeramente diferente:
CREATE OR REPLACE PROCEDURE obtener_empleados()
LANGUAGE plpgsql
AS $$
BEGIN
SELECT * FROM empleados;
END;
$$;
Estructura de un procedimiento
Un procedimiento almacenado puede contener:
- Declaraciones de variables locales
- Instrucciones SQL (SELECT, INSERT, UPDATE, DELETE)
- Estructuras de control (IF, CASE, WHILE, REPEAT)
- Manejo de errores
- Transacciones
Veamos un ejemplo más completo en MySQL:
DELIMITER //
CREATE PROCEDURE calcular_bono_empleado(IN id_emp INT, IN porcentaje DECIMAL(5,2))
BEGIN
DECLARE salario_actual DECIMAL(10,2);
-- Obtener el salario actual
SELECT salario INTO salario_actual
FROM empleados
WHERE id = id_emp;
-- Actualizar el salario con el bono
UPDATE empleados
SET salario = salario_actual + (salario_actual * porcentaje / 100)
WHERE id = id_emp;
-- Registrar la operación
INSERT INTO registro_bonos (id_empleado, porcentaje, fecha)
VALUES (id_emp, porcentaje, NOW());
END //
DELIMITER ;
Ventajas de usar CREATE PROCEDURE
Los procedimientos almacenados ofrecen varias ventajas importantes:
- Reutilización de código: Escribes el código una vez y lo ejecutas múltiples veces.
- Seguridad mejorada: Puedes otorgar permisos para ejecutar un procedimiento sin dar acceso directo a las tablas subyacentes.
- Rendimiento optimizado: Los procedimientos se compilan al crearse, lo que mejora el tiempo de ejecución.
- Reducción del tráfico de red: Solo se envía la llamada al procedimiento, no todas las sentencias SQL.
- Mantenimiento centralizado: Los cambios en la lógica de negocio se realizan en un solo lugar.
Modificación y eliminación de procedimientos
Para modificar un procedimiento existente, generalmente se elimina y se vuelve a crear:
DROP PROCEDURE IF EXISTS nombre_procedimiento;
-- Luego se crea de nuevo con CREATE PROCEDURE
En PostgreSQL, se puede usar directamente:
CREATE OR REPLACE PROCEDURE nombre_procedimiento...
Para eliminar un procedimiento:
DROP PROCEDURE [IF EXISTS] nombre_procedimiento;
Procedimientos con lógica condicional
Los procedimientos pueden incluir estructuras de control para implementar lógica de negocio compleja:
DELIMITER //
CREATE PROCEDURE actualizar_estado_pedido(IN id_pedido INT)
BEGIN
DECLARE total_pedido DECIMAL(10,2);
-- Obtener el total del pedido
SELECT SUM(precio * cantidad) INTO total_pedido
FROM detalles_pedido
WHERE pedido_id = id_pedido;
-- Aplicar lógica de negocio
IF total_pedido > 1000 THEN
UPDATE pedidos SET estado = 'Premium', descuento = 10
WHERE id = id_pedido;
ELSEIF total_pedido > 500 THEN
UPDATE pedidos SET estado = 'Regular', descuento = 5
WHERE id = id_pedido;
ELSE
UPDATE pedidos SET estado = 'Normal', descuento = 0
WHERE id = id_pedido;
END IF;
END //
DELIMITER ;
Procedimientos con transacciones
Para operaciones que requieren atomicidad (todo o nada), podemos incluir transacciones:
DELIMITER //
CREATE PROCEDURE transferir_fondos(
IN cuenta_origen INT,
IN cuenta_destino INT,
IN monto DECIMAL(10,2),
OUT resultado VARCHAR(100)
)
BEGIN
DECLARE saldo_origen DECIMAL(10,2);
-- Iniciar transacción
START TRANSACTION;
-- Verificar saldo suficiente
SELECT saldo INTO saldo_origen FROM cuentas WHERE id = cuenta_origen FOR UPDATE;
IF saldo_origen >= monto THEN
-- Restar de la cuenta origen
UPDATE cuentas SET saldo = saldo - monto WHERE id = cuenta_origen;
-- Sumar a la cuenta destino
UPDATE cuentas SET saldo = saldo + monto WHERE id = cuenta_destino;
-- Registrar la transacción
INSERT INTO movimientos (cuenta_origen, cuenta_destino, monto, fecha)
VALUES (cuenta_origen, cuenta_destino, monto, NOW());
-- Confirmar cambios
COMMIT;
SET resultado = 'Transferencia exitosa';
ELSE
-- Deshacer cambios
ROLLBACK;
SET resultado = 'Saldo insuficiente';
END IF;
END //
DELIMITER ;
Comentarios en procedimientos
Es una buena práctica documentar los procedimientos almacenados con comentarios:
DELIMITER //
CREATE PROCEDURE calcular_estadisticas_ventas(IN fecha_inicio DATE, IN fecha_fin DATE)
/*
Autor: Ana Martínez
Fecha: 2023-05-15
Descripción: Calcula estadísticas de ventas en un período específico
Parámetros:
- fecha_inicio: Fecha inicial del período (inclusive)
- fecha_fin: Fecha final del período (inclusive)
*/
BEGIN
-- Calcular total de ventas
SELECT
COUNT(*) AS total_ventas,
SUM(monto) AS monto_total,
AVG(monto) AS promedio_venta,
MAX(monto) AS venta_maxima
FROM ventas
WHERE fecha_venta BETWEEN fecha_inicio AND fecha_fin;
END //
DELIMITER ;
Procedimientos con cursores
Para operaciones que requieren procesar filas una por una, podemos usar cursores:
DELIMITER //
CREATE PROCEDURE actualizar_precios_productos()
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE prod_id INT;
DECLARE prod_costo DECIMAL(10,2);
-- Declarar cursor
DECLARE cur CURSOR FOR
SELECT id, costo FROM productos WHERE actualizado = 0;
-- Declarar handler para cuando no hay más filas
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
-- Abrir cursor
OPEN cur;
-- Iniciar bucle de lectura
read_loop: LOOP
-- Obtener siguiente fila
FETCH cur INTO prod_id, prod_costo;
-- Salir si no hay más filas
IF done THEN
LEAVE read_loop;
END IF;
-- Actualizar precio (costo + 20%)
UPDATE productos
SET precio_venta = prod_costo * 1.2, actualizado = 1
WHERE id = prod_id;
END LOOP;
-- Cerrar cursor
CLOSE cur;
END //
DELIMITER ;
Los procedimientos almacenados son herramientas fundamentales para implementar lógica de negocio compleja directamente en la base de datos, mejorando tanto el rendimiento como la seguridad de las aplicaciones.
Parámetros IN/OUT
Los procedimientos almacenados pueden intercambiar información con el entorno que los invoca mediante parámetros. Estos parámetros permiten enviar datos al procedimiento y también recibir resultados después de su ejecución, lo que aumenta significativamente su flexibilidad y utilidad.
En SQL, existen tres tipos principales de parámetros para los procedimientos almacenados:
- IN: Parámetros de entrada
- OUT: Parámetros de salida
- INOUT: Parámetros que funcionan tanto de entrada como de salida
Parámetros de entrada (IN)
Los parámetros IN son los más comunes y permiten pasar valores al procedimiento. Estos valores son de solo lectura dentro del procedimiento y cualquier modificación que se les haga no afectará a la variable original en el entorno que realizó la llamada.
DELIMITER //
CREATE PROCEDURE calcular_impuesto(
IN precio DECIMAL(10,2),
IN tasa_impuesto DECIMAL(5,2)
)
BEGIN
DECLARE impuesto DECIMAL(10,2);
SET impuesto = precio * (tasa_impuesto / 100);
SELECT
precio AS precio_base,
tasa_impuesto AS porcentaje,
impuesto AS monto_impuesto,
precio + impuesto AS precio_final;
END //
DELIMITER ;
En este ejemplo, precio y tasa_impuesto son parámetros de entrada que se utilizan para realizar cálculos dentro del procedimiento.
Parámetros de salida (OUT)
Los parámetros OUT permiten devolver valores desde el procedimiento al entorno que lo invocó. Estos parámetros no tienen un valor inicial dentro del procedimiento (se consideran NULL al inicio) y deben ser asignados durante la ejecución.
DELIMITER //
CREATE PROCEDURE obtener_estadisticas_cliente(
IN cliente_id INT,
OUT total_pedidos INT,
OUT valor_total DECIMAL(12,2),
OUT ultimo_pedido DATE
)
BEGIN
-- Obtener número total de pedidos
SELECT COUNT(*) INTO total_pedidos
FROM pedidos
WHERE id_cliente = cliente_id;
-- Obtener valor total de todos los pedidos
SELECT COALESCE(SUM(monto), 0) INTO valor_total
FROM pedidos
WHERE id_cliente = cliente_id;
-- Obtener fecha del último pedido
SELECT MAX(fecha_pedido) INTO ultimo_pedido
FROM pedidos
WHERE id_cliente = cliente_id;
END //
DELIMITER ;
En este procedimiento, cliente_id es un parámetro de entrada, mientras que total_pedidos, valor_total y ultimo_pedido son parámetros de salida que contendrán información después de la ejecución.
Parámetros de entrada/salida (INOUT)
Los parámetros INOUT combinan las características de los parámetros IN y OUT. Permiten pasar un valor inicial al procedimiento y también devolver un valor modificado al entorno que lo invocó.
DELIMITER //
CREATE PROCEDURE aplicar_descuento(
INOUT precio DECIMAL(10,2),
IN porcentaje_descuento DECIMAL(5,2)
)
BEGIN
DECLARE descuento DECIMAL(10,2);
-- Calcular el descuento
SET descuento = precio * (porcentaje_descuento / 100);
-- Aplicar el descuento al precio
SET precio = precio - descuento;
-- El parámetro precio ahora contiene el valor con descuento
-- y será devuelto al entorno que invocó el procedimiento
END //
DELIMITER ;
En este ejemplo, precio es un parámetro INOUT que recibe un valor inicial y devuelve el precio con el descuento aplicado.
Diferencias entre MySQL y PostgreSQL
La implementación de parámetros varía ligeramente entre sistemas de gestión de bases de datos:
MySQL:
CREATE PROCEDURE ejemplo_parametros(
IN param_entrada INT,
OUT param_salida VARCHAR(50),
INOUT param_entrada_salida DECIMAL(10,2)
)
BEGIN
-- Cuerpo del procedimiento
END;
PostgreSQL:
CREATE OR REPLACE PROCEDURE ejemplo_parametros(
param_entrada IN INT,
param_salida OUT VARCHAR,
param_entrada_salida INOUT NUMERIC(10,2)
)
LANGUAGE plpgsql
AS $$
BEGIN
-- Cuerpo del procedimiento
END;
$$;
En PostgreSQL, la posición de los modificadores IN/OUT/INOUT es después del nombre del parámetro, mientras que en MySQL es antes.
Validación de parámetros
Una buena práctica es validar los parámetros de entrada al inicio del procedimiento:
DELIMITER //
CREATE PROCEDURE registrar_venta(
IN producto_id INT,
IN cantidad INT,
IN precio_unitario DECIMAL(10,2),
OUT resultado VARCHAR(100)
)
BEGIN
-- Validar parámetros
IF producto_id IS NULL OR producto_id <= 0 THEN
SET resultado = 'Error: ID de producto inválido';
RETURN;
END IF;
IF cantidad IS NULL OR cantidad <= 0 THEN
SET resultado = 'Error: Cantidad debe ser mayor que cero';
RETURN;
END IF;
IF precio_unitario IS NULL OR precio_unitario < 0 THEN
SET resultado = 'Error: Precio no puede ser negativo';
RETURN;
END IF;
-- Proceder con la lógica principal
INSERT INTO ventas (producto_id, cantidad, precio_unitario, fecha)
VALUES (producto_id, cantidad, precio_unitario, NOW());
SET resultado = 'Venta registrada correctamente';
END //
DELIMITER ;
Parámetros con valores predeterminados
En MySQL, podemos asignar valores predeterminados a los parámetros de entrada:
DELIMITER //
CREATE PROCEDURE calcular_precio_final(
IN precio_base DECIMAL(10,2),
IN tasa_impuesto DECIMAL(5,2) DEFAULT 21.00,
IN descuento DECIMAL(5,2) DEFAULT 0.00,
OUT precio_final DECIMAL(10,2)
)
BEGIN
DECLARE impuesto DECIMAL(10,2);
DECLARE monto_descuento DECIMAL(10,2);
SET impuesto = precio_base * (tasa_impuesto / 100);
SET monto_descuento = precio_base * (descuento / 100);
SET precio_final = precio_base + impuesto - monto_descuento;
END //
DELIMITER ;
En este ejemplo, si no se proporcionan valores para tasa_impuesto o descuento, se utilizarán los valores predeterminados (21% y 0% respectivamente).
Uso de parámetros para control de flujo
Los parámetros también pueden utilizarse para controlar el flujo de ejecución dentro del procedimiento:
DELIMITER //
CREATE PROCEDURE generar_reporte_ventas(
IN fecha_inicio DATE,
IN fecha_fin DATE,
IN tipo_reporte CHAR(1),
OUT mensaje VARCHAR(100)
)
BEGIN
-- Validar fechas
IF fecha_inicio > fecha_fin THEN
SET mensaje = 'Error: La fecha inicial no puede ser posterior a la fecha final';
RETURN;
END IF;
-- Generar reporte según el tipo solicitado
CASE tipo_reporte
WHEN 'D' THEN
-- Reporte detallado
SELECT
v.id, v.fecha, c.nombre AS cliente, p.nombre AS producto,
v.cantidad, v.precio_unitario, (v.cantidad * v.precio_unitario) AS total
FROM ventas v
JOIN clientes c ON v.cliente_id = c.id
JOIN productos p ON v.producto_id = p.id
WHERE v.fecha BETWEEN fecha_inicio AND fecha_fin;
SET mensaje = 'Reporte detallado generado';
WHEN 'R' THEN
-- Reporte resumido
SELECT
DATE(v.fecha) AS fecha,
COUNT(*) AS total_ventas,
SUM(v.cantidad * v.precio_unitario) AS monto_total
FROM ventas v
WHERE v.fecha BETWEEN fecha_inicio AND fecha_fin
GROUP BY DATE(v.fecha);
SET mensaje = 'Reporte resumido generado';
ELSE
SET mensaje = 'Error: Tipo de reporte no válido. Use D (detallado) o R (resumido)';
END CASE;
END //
DELIMITER ;
Consideraciones de rendimiento
Al trabajar con parámetros, es importante tener en cuenta algunas consideraciones de rendimiento:
- Los parámetros OUT e INOUT requieren más recursos que los parámetros IN, ya que necesitan mantener una referencia a la variable original.
- Evita usar demasiados parámetros en un procedimiento (más de 5-6 puede indicar que el procedimiento está haciendo demasiadas cosas).
- Para conjuntos grandes de resultados, considera usar tablas temporales o resultados directos (SELECT) en lugar de múltiples parámetros OUT.
-- Mejor enfoque para devolver muchos valores
DELIMITER //
CREATE PROCEDURE obtener_resumen_ventas(IN año INT)
BEGIN
-- Devolver directamente un conjunto de resultados
SELECT
MONTH(fecha) AS mes,
COUNT(*) AS total_ventas,
SUM(monto) AS ingresos_totales,
AVG(monto) AS venta_promedio,
MAX(monto) AS venta_maxima
FROM ventas
WHERE YEAR(fecha) = año
GROUP BY MONTH(fecha)
ORDER BY MONTH(fecha);
END //
DELIMITER ;
Los parámetros son una herramienta fundamental para crear procedimientos almacenados flexibles y reutilizables, permitiendo la comunicación bidireccional entre el procedimiento y el entorno que lo invoca.
Llamada y ejecución
Una vez que hemos creado un procedimiento almacenado, necesitamos saber cómo invocarlo para aprovechar la lógica de negocio que encapsula. La ejecución de procedimientos almacenados es un proceso sencillo pero con algunas particularidades según el sistema de gestión de bases de datos que estemos utilizando.
Sintaxis básica para llamar a procedimientos
Para ejecutar un procedimiento almacenado, utilizamos la sentencia CALL seguida del nombre del procedimiento y los parámetros necesarios entre paréntesis:
CALL nombre_procedimiento(param1, param2, ...);
Esta sintaxis es común tanto en MySQL como en PostgreSQL, aunque existen algunas diferencias en el manejo de los parámetros de salida.
Llamada a procedimientos sin parámetros
La forma más simple de invocar un procedimiento es cuando este no requiere parámetros:
CALL listar_clientes();
Este tipo de llamada es ideal para procedimientos que realizan tareas como generar informes predefinidos o ejecutar operaciones de mantenimiento programadas.
Llamada con parámetros de entrada (IN)
Para procedimientos que requieren datos de entrada, simplemente pasamos los valores en el mismo orden en que fueron definidos:
-- Procedimiento que calcula el total de ventas en un período
CALL calcular_ventas_periodo('2023-01-01', '2023-03-31');
-- Procedimiento que registra un nuevo producto
CALL registrar_producto('Teclado mecánico', 'Periféricos', 89.99, 50);
Los valores pueden ser literales (como en los ejemplos anteriores) o variables:
SET @fecha_inicio = '2023-01-01';
SET @fecha_fin = '2023-03-31';
CALL calcular_ventas_periodo(@fecha_inicio, @fecha_fin);
Captura de parámetros de salida (OUT)
Para capturar los valores devueltos por un procedimiento a través de parámetros OUT, debemos declarar variables que recibirán estos valores:
En MySQL:
-- Declarar variables para recibir los resultados
SET @total_ventas = 0;
SET @promedio_venta = 0;
SET @cliente_top = '';
-- Llamar al procedimiento pasando las variables como parámetros OUT
CALL obtener_estadisticas_ventas('2023-01-01', '2023-12-31', @total_ventas, @promedio_venta, @cliente_top);
-- Consultar los valores obtenidos
SELECT @total_ventas AS 'Total de ventas',
@promedio_venta AS 'Venta promedio',
@cliente_top AS 'Cliente con mayor compra';
En PostgreSQL:
-- Declarar variables para recibir los resultados
DO $$
DECLARE
v_total_ventas INTEGER;
v_promedio_venta NUMERIC(10,2);
v_cliente_top VARCHAR(100);
BEGIN
-- Llamar al procedimiento
CALL obtener_estadisticas_ventas('2023-01-01', '2023-12-31', v_total_ventas, v_promedio_venta, v_cliente_top);
-- Usar los valores obtenidos
RAISE NOTICE 'Total de ventas: %', v_total_ventas;
RAISE NOTICE 'Venta promedio: %', v_promedio_venta;
RAISE NOTICE 'Cliente con mayor compra: %', v_cliente_top;
END $$;
Uso de parámetros INOUT
Los parámetros INOUT permiten tanto enviar como recibir valores. Su uso es similar a los parámetros OUT, pero requieren inicialización previa:
En MySQL:
-- Inicializar la variable con un valor
SET @precio = 100.00;
-- Llamar al procedimiento que aplicará un descuento
CALL aplicar_descuento(@precio, 15);
-- Consultar el precio con descuento aplicado
SELECT @precio AS 'Precio con descuento'; -- Mostrará 85.00
Ejecución desde aplicaciones cliente
Los procedimientos almacenados también pueden ser ejecutados desde aplicaciones cliente utilizando las APIs de acceso a bases de datos:
Java (JDBC):
// Llamada a procedimiento sin parámetros de salida
CallableStatement stmt = connection.prepareCall("{CALL actualizar_inventario(?, ?)}");
stmt.setInt(1, productoId);
stmt.setInt(2, cantidad);
stmt.execute();
// Llamada a procedimiento con parámetros de salida
CallableStatement stmt = connection.prepareCall("{CALL calcular_precio_final(?, ?, ?, ?)}");
stmt.setDouble(1, precioBase);
stmt.setDouble(2, tasaImpuesto);
stmt.setDouble(3, descuento);
stmt.registerOutParameter(4, Types.DECIMAL);
stmt.execute();
// Obtener el valor de salida
double precioFinal = stmt.getDouble(4);
Python (con psycopg2 para PostgreSQL):
# Llamada a procedimiento sin parámetros de salida
cursor.execute("CALL registrar_venta(%s, %s, %s)", (cliente_id, producto_id, cantidad))
# Llamada a procedimiento con parámetros de salida (PostgreSQL)
cursor.execute("""
DO $$
DECLARE
v_resultado VARCHAR;
BEGIN
CALL procesar_pedido(%s, %s, v_resultado);
RAISE NOTICE '%%', v_resultado;
END $$;
""", (pedido_id, estado_nuevo))
Ejecución con resultados múltiples
Algunos procedimientos pueden devolver múltiples conjuntos de resultados:
DELIMITER //
CREATE PROCEDURE informe_completo_ventas(IN año INT)
BEGIN
-- Primer conjunto de resultados: Resumen anual
SELECT
SUM(monto) AS total_anual,
COUNT(*) AS num_ventas,
AVG(monto) AS promedio_venta
FROM ventas
WHERE YEAR(fecha) = año;
-- Segundo conjunto de resultados: Ventas por mes
SELECT
MONTH(fecha) AS mes,
SUM(monto) AS total_mensual
FROM ventas
WHERE YEAR(fecha) = año
GROUP BY MONTH(fecha)
ORDER BY MONTH(fecha);
-- Tercer conjunto de resultados: Top 5 clientes
SELECT
c.nombre,
SUM(v.monto) AS total_compras
FROM ventas v
JOIN clientes c ON v.cliente_id = c.id
WHERE YEAR(v.fecha) = año
GROUP BY c.id, c.nombre
ORDER BY total_compras DESC
LIMIT 5;
END //
DELIMITER ;
Para manejar estos múltiples conjuntos de resultados:
En MySQL (cliente de línea de comandos):
CALL informe_completo_ventas(2023);
-- Los resultados se mostrarán secuencialmente
En aplicaciones cliente (Java):
CallableStatement stmt = connection.prepareCall("{CALL informe_completo_ventas(?)}");
stmt.setInt(1, 2023);
boolean hasResults = stmt.execute();
// Procesar el primer conjunto de resultados
if (hasResults) {
ResultSet rs = stmt.getResultSet();
// Procesar rs
rs.close();
}
// Procesar el segundo conjunto de resultados
hasResults = stmt.getMoreResults();
if (hasResults) {
ResultSet rs = stmt.getResultSet();
// Procesar rs
rs.close();
}
// Procesar el tercer conjunto de resultados
hasResults = stmt.getMoreResults();
if (hasResults) {
ResultSet rs = stmt.getResultSet();
// Procesar rs
rs.close();
}
Ejecución con manejo de errores
Es importante manejar posibles errores durante la ejecución de procedimientos:
En MySQL:
-- Declarar variables para capturar resultados y mensajes de error
SET @resultado = '';
SET @error_mensaje = '';
-- Llamar al procedimiento con manejo de errores
CALL transferir_fondos(101, 202, 500.00, @resultado, @error_mensaje);
-- Verificar el resultado
IF @error_mensaje != '' THEN
SELECT @error_mensaje AS 'Error';
ELSE
SELECT @resultado AS 'Resultado';
END IF;
En aplicaciones cliente:
try {
CallableStatement stmt = connection.prepareCall("{CALL transferir_fondos(?, ?, ?, ?)}");
stmt.setInt(1, cuentaOrigen);
stmt.setInt(2, cuentaDestino);
stmt.setDouble(3, monto);
stmt.registerOutParameter(4, Types.VARCHAR);
stmt.execute();
String resultado = stmt.getString(4);
System.out.println("Resultado: " + resultado);
} catch (SQLException e) {
System.err.println("Error al ejecutar el procedimiento: " + e.getMessage());
}
Verificación de la existencia de un procedimiento
Antes de llamar a un procedimiento, podemos verificar si existe:
En MySQL:
SELECT ROUTINE_NAME
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_TYPE = 'PROCEDURE'
AND ROUTINE_SCHEMA = 'nombre_base_datos'
AND ROUTINE_NAME = 'nombre_procedimiento';
-- Si devuelve filas, el procedimiento existe
En PostgreSQL:
SELECT proname
FROM pg_proc
WHERE proname = 'nombre_procedimiento';
-- Si devuelve filas, el procedimiento existe
Ejecución programada de procedimientos
Los procedimientos almacenados pueden ser programados para ejecutarse automáticamente:
En MySQL:
-- Crear un evento que ejecute un procedimiento diariamente
CREATE EVENT evento_limpieza_diaria
ON SCHEDULE EVERY 1 DAY
STARTS '2023-01-01 00:00:00'
DO
CALL limpiar_registros_temporales();
En PostgreSQL: PostgreSQL no tiene eventos integrados, pero se puede usar pgAgent o cron para programar la ejecución:
# Ejemplo de entrada en crontab para ejecutar un procedimiento diariamente
0 0 * * * psql -U usuario -d basedatos -c "CALL limpiar_registros_temporales();"
Buenas prácticas para la ejecución de procedimientos
- Transacciones: Cuando llames a procedimientos que modifican datos críticos, considera envolverlos en transacciones explícitas si el procedimiento no las maneja internamente.
START TRANSACTION;
CALL procesar_pedido(123, 'ENVIADO', @resultado);
IF @resultado = 'OK' THEN
COMMIT;
ELSE
ROLLBACK;
END IF;
- Monitoreo de rendimiento: Para procedimientos complejos o que se ejecutan frecuentemente, considera monitorear su rendimiento:
SET @tiempo_inicio = NOW();
CALL procedimiento_complejo();
SELECT TIMEDIFF(NOW(), @tiempo_inicio) AS 'Tiempo de ejecución';
- Documentación: Mantén documentación actualizada sobre cómo llamar a tus procedimientos, incluyendo ejemplos de uso y descripción de parámetros.
La correcta ejecución de procedimientos almacenados es fundamental para aprovechar al máximo la lógica de negocio encapsulada en la base de datos, mejorando tanto el rendimiento como la consistencia de las operaciones en tu aplicación.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Comprender la sintaxis y estructura básica para crear procedimientos almacenados en MySQL y PostgreSQL.
- Aprender a definir y utilizar parámetros IN, OUT e INOUT para la comunicación bidireccional con procedimientos.
- Saber cómo invocar procedimientos almacenados y capturar sus resultados desde SQL y aplicaciones cliente.
- Conocer las ventajas y buenas prácticas en el uso de procedimientos almacenados, incluyendo manejo de transacciones y cursores.
- Entender cómo modificar, eliminar y programar la ejecución de procedimientos almacenados.