Concepto partición
El particionamiento de tablas es una técnica de optimización en bases de datos que consiste en dividir tablas grandes en segmentos más pequeños y manejables llamados particiones. En lugar de almacenar todos los datos en una única estructura física, el sistema de base de datos distribuye la información en múltiples fragmentos según criterios específicos.
graph TD
A[Tabla particionada] --> B[Estrategia]
B --> C[RANGE por rangos]
B --> D[LIST por valores discretos]
B --> E[HASH distribución uniforme]
C --> F[Por fechas trimestres]
D --> G[Por país o categoría]
E --> H[Buckets aleatorios]
A --> I[Partition pruning]
I --> J[Lee solo particiones relevantes]
Imagina una tabla de ventas con millones de registros acumulados durante años. Sin particionamiento, cualquier consulta debe examinar potencialmente toda la tabla, incluso si solo necesitas datos de un período específico. Las particiones permiten que el motor de base de datos trabaje únicamente con los segmentos relevantes para cada consulta, mejorando significativamente el rendimiento.
Fundamentos del particionamiento
El particionamiento divide una tabla en unidades lógicas que físicamente se almacenan como objetos independientes. Cada partición mantiene su propia estructura de almacenamiento, pero desde la perspectiva del usuario, la tabla sigue comportándose como una entidad única. Esto significa que puedes seguir realizando consultas normales sin preocuparte por la estructura interna de las particiones.
-- Ejemplo conceptual (la sintaxis exacta varía según el SGBD)
CREATE TABLE ventas (
id_venta INT,
fecha_venta DATE,
monto DECIMAL(10,2),
id_cliente INT
) PARTITION BY RANGE (YEAR(fecha_venta));
Beneficios del particionamiento
El particionamiento ofrece múltiples ventajas que impactan directamente en el rendimiento y la administración de bases de datos:
- Mejora del rendimiento de consultas: Al trabajar solo con las particiones relevantes, las consultas pueden ejecutarse mucho más rápido.
-- Esta consulta solo examinará la partición que contiene datos de 2023
SELECT SUM(monto) FROM ventas WHERE fecha_venta BETWEEN '2023-01-01' AND '2023-12-31';
-
Mantenimiento simplificado: Puedes realizar operaciones de mantenimiento (como respaldos o reconstrucción de índices) en particiones individuales sin afectar a toda la tabla.
-
Mejor gestión de datos históricos: Facilita la implementación de políticas de retención de datos, permitiendo archivar o eliminar particiones antiguas completas.
-
Distribución de carga: En sistemas distribuidos, las particiones pueden ubicarse en diferentes servidores o discos, balanceando la carga de trabajo.
-
Mejora en disponibilidad: Si una partición falla o necesita mantenimiento, el resto de la tabla puede seguir disponible.
Funcionamiento interno
Cuando se ejecuta una consulta en una tabla particionada, el optimizador de consultas analiza las condiciones de filtrado para determinar qué particiones deben examinarse. Este proceso, conocido como eliminación de particiones (partition pruning), es fundamental para obtener los beneficios de rendimiento.
-- Internamente, el motor convierte esta consulta
SELECT * FROM ventas WHERE fecha_venta = '2023-05-15';
-- En algo conceptualmente similar a esto (transparente para el usuario)
SELECT * FROM ventas_2023 WHERE fecha_venta = '2023-05-15';
El motor de base de datos mantiene un mapa de particiones que registra qué rangos de valores corresponden a cada partición física. Este mapa se consulta durante la planificación de la ejecución para determinar qué particiones son relevantes.
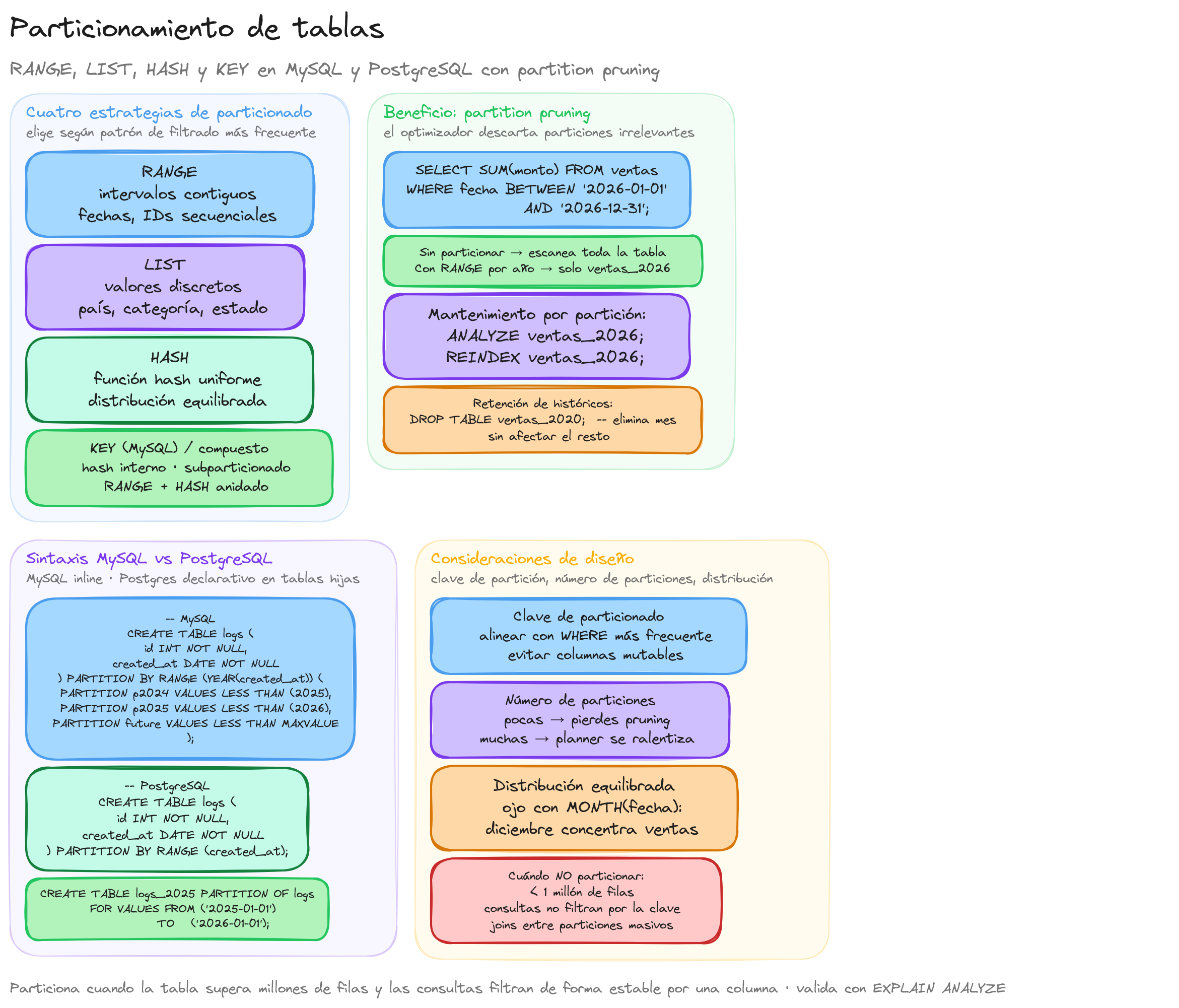
Consideraciones de diseño
Al implementar particiones, es crucial considerar:
-
Clave de particionamiento: Debe elegirse cuidadosamente basándose en los patrones de consulta más frecuentes. Idealmente, debe permitir que las consultas comunes accedan al mínimo número de particiones.
-
Número de particiones: Demasiadas particiones pueden generar sobrecarga administrativa, mientras que muy pocas reducen los beneficios del particionamiento.
-
Distribución de datos: Las particiones desequilibradas (algunas con muchos más datos que otras) pueden afectar negativamente al rendimiento.
-- Ejemplo de partición potencialmente desequilibrada
-- Si la mayoría de ventas ocurren en diciembre
PARTITION BY MONTH(fecha_venta)
-
Índices: En MySQL, los índices se crean por partición, lo que puede aumentar el espacio de almacenamiento pero mejorar el rendimiento de consultas específicas de partición.
-
Restricciones: Algunas bases de datos tienen limitaciones sobre qué tipos de restricciones pueden aplicarse a tablas particionadas.
Diferencias entre MySQL y PostgreSQL
Aunque el concepto es similar, la implementación varía entre sistemas:
MySQL:
CREATE TABLE logs (
id INT NOT NULL,
created_at DATE NOT NULL,
message VARCHAR(255)
)
PARTITION BY RANGE (YEAR(created_at)) (
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION future VALUES LESS THAN MAXVALUE
);
PostgreSQL:
-- PostgreSQL usa particionamiento declarativo
CREATE TABLE logs (
id INT NOT NULL,
created_at DATE NOT NULL,
message VARCHAR(255)
) PARTITION BY RANGE (created_at);
-- Las particiones se crean como tablas separadas
CREATE TABLE logs_2021 PARTITION OF logs
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
CREATE TABLE logs_2022 PARTITION OF logs
FOR VALUES FROM ('2022-01-01') TO ('2023-01-01');
El particionamiento es una técnica avanzada que requiere planificación cuidadosa, pero cuando se implementa correctamente, puede transformar el rendimiento de bases de datos grandes y mejorar significativamente la experiencia del usuario final y la eficiencia operativa del sistema.
Tipos de particionado
Una vez comprendido el concepto de particionamiento, es fundamental conocer los diferentes tipos de particionado que ofrecen los sistemas gestores de bases de datos. Cada tipo utiliza un criterio distinto para dividir los datos y se adapta a diferentes patrones de consulta y distribución de información.
Particionado por rango (RANGE)
El particionado por rango divide la tabla según intervalos de valores contiguos de una o más columnas. Es ideal para datos que siguen una secuencia natural como fechas, números secuenciales o valores monetarios.
-- MySQL: Particionado por rango de fechas
CREATE TABLE facturas (
id INT NOT NULL,
fecha DATE NOT NULL,
total DECIMAL(10,2),
PRIMARY KEY (id, fecha)
)
PARTITION BY RANGE (TO_DAYS(fecha)) (
PARTITION p_2021 VALUES LESS THAN (TO_DAYS('2022-01-01')),
PARTITION p_2022 VALUES LESS THAN (TO_DAYS('2023-01-01')),
PARTITION p_actual VALUES LESS THAN MAXVALUE
);
-- PostgreSQL: Particionado por rango de valores numéricos
CREATE TABLE mediciones (
id SERIAL,
sensor_id INT NOT NULL,
valor DECIMAL(10,2),
fecha_lectura TIMESTAMP
) PARTITION BY RANGE (valor);
CREATE TABLE mediciones_bajas PARTITION OF mediciones
FOR VALUES FROM (0) TO (100);
CREATE TABLE mediciones_medias PARTITION OF mediciones
FOR VALUES FROM (100) TO (500);
CREATE TABLE mediciones_altas PARTITION OF mediciones
FOR VALUES FROM (500) TO (1000);
Este tipo de particionado es especialmente eficiente para consultas que filtran por el rango utilizado como criterio de partición, permitiendo al motor ignorar completamente las particiones que no contienen datos relevantes.
Particionado por lista (LIST)
El particionado por lista agrupa filas según valores discretos específicos de una columna. Es perfecto para columnas con un conjunto limitado de valores posibles, como códigos de país, categorías o estados.
-- MySQL: Particionado por lista de regiones
CREATE TABLE clientes (
id INT NOT NULL,
nombre VARCHAR(100),
region VARCHAR(20),
PRIMARY KEY (id, region)
)
PARTITION BY LIST (region) (
PARTITION p_norte VALUES IN ('Asturias', 'Cantabria', 'Galicia', 'País Vasco'),
PARTITION p_sur VALUES IN ('Andalucía', 'Murcia', 'Extremadura'),
PARTITION p_centro VALUES IN ('Madrid', 'Castilla-La Mancha', 'Castilla y León')
);
-- PostgreSQL: Particionado por lista de categorías
CREATE TABLE productos (
id INT,
nombre VARCHAR(100),
categoria VARCHAR(50),
precio DECIMAL(10,2)
) PARTITION BY LIST (categoria);
CREATE TABLE productos_electronicos PARTITION OF productos
FOR VALUES IN ('Smartphones', 'Ordenadores', 'Tablets', 'Accesorios');
CREATE TABLE productos_hogar PARTITION OF productos
FOR VALUES IN ('Muebles', 'Decoración', 'Electrodomésticos');
Este tipo resulta muy útil cuando las consultas frecuentemente filtran por valores específicos de la columna de particionado, como reportes por región o análisis por categoría.
Particionado hash (HASH)
El particionado hash distribuye los datos utilizando una función hash sobre la columna especificada, creando una distribución uniforme entre un número predefinido de particiones. Es ideal cuando no existe un criterio natural de agrupación pero se desea distribuir la carga equitativamente.
-- MySQL: Particionado hash por ID de cliente
CREATE TABLE transacciones (
id INT NOT NULL,
cliente_id INT,
monto DECIMAL(10,2),
fecha TIMESTAMP,
PRIMARY KEY (id, cliente_id)
)
PARTITION BY HASH (cliente_id)
PARTITIONS 4;
-- PostgreSQL: Particionado hash (requiere implementación manual)
CREATE TABLE eventos (
id SERIAL,
usuario_id INT,
tipo VARCHAR(50),
datos JSONB
) PARTITION BY HASH (usuario_id);
-- Crear particiones individuales
CREATE TABLE eventos_0 PARTITION OF eventos
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE eventos_1 PARTITION OF eventos
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
CREATE TABLE eventos_2 PARTITION OF eventos
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE eventos_3 PARTITION OF eventos
FOR VALUES WITH (MODULUS 4, REMAINDER 3);
Este tipo de particionado es especialmente valioso en entornos distribuidos donde se busca balancear la carga entre diferentes nodos o discos.
Particionado por clave (KEY)
El particionado por clave es similar al hash, pero permite que el sistema de base de datos elija la función hash. En MySQL, puede utilizar múltiples columnas y funciona bien con claves primarias o únicas.
-- MySQL: Particionado por clave usando la clave primaria
CREATE TABLE pedidos (
id INT NOT NULL,
cliente_id INT,
fecha DATE,
estado VARCHAR(20),
PRIMARY KEY (id)
)
PARTITION BY KEY (id)
PARTITIONS 6;
Este tipo ofrece una distribución equilibrada sin requerir conocimiento detallado de la distribución de datos, siendo una opción práctica cuando no se tiene un criterio claro de particionamiento.
Particionado compuesto
Algunos sistemas permiten combinar diferentes estrategias mediante el particionado compuesto (o subparticionado), donde las particiones principales se dividen nuevamente usando un criterio secundario.
-- MySQL: Particionado compuesto (RANGE + HASH)
CREATE TABLE ventas (
id INT NOT NULL,
fecha DATE,
tienda_id INT,
monto DECIMAL(10,2),
PRIMARY KEY (id, fecha, tienda_id)
)
PARTITION BY RANGE (YEAR(fecha))
SUBPARTITION BY HASH (tienda_id)
SUBPARTITIONS 4 (
PARTITION p_2021 VALUES LESS THAN (2022),
PARTITION p_2022 VALUES LESS THAN (2023),
PARTITION p_2023 VALUES LESS THAN (2024)
);
Este enfoque es extremadamente potente para tablas muy grandes donde se necesita optimizar consultas con múltiples criterios de filtrado, como "ventas del año 2022 para la tienda 5".
Particionado por intervalo de tiempo (INTERVAL)
PostgreSQL ofrece un tipo especial de particionado por intervalo que automatiza la creación de particiones basadas en rangos de tiempo.
-- PostgreSQL: Particionado por intervalo (con extensión pg_partman)
-- Primero se crea la tabla particionada por rango
CREATE TABLE metricas (
id SERIAL,
timestamp TIMESTAMP NOT NULL,
valor FLOAT,
origen VARCHAR(50)
) PARTITION BY RANGE (timestamp);
-- Luego se configura pg_partman para crear particiones mensuales automáticamente
SELECT create_parent(
'public.metricas',
'timestamp',
'monthly',
p_start_date := '2023-01-01'
);
Esta técnica es especialmente valiosa para datos de series temporales donde constantemente se añaden nuevos datos y se necesitan crear nuevas particiones de forma automática.
Selección del tipo adecuado
La elección del tipo de particionado debe basarse en:
- Patrones de consulta: Selecciona un tipo que optimice tus consultas más frecuentes
- Distribución de datos: Evita particiones desequilibradas que puedan afectar al rendimiento
- Operaciones de mantenimiento: Considera cómo afectará a tareas como respaldos o purgas de datos
- Crecimiento de datos: Evalúa cómo se comportará el esquema a medida que los datos aumenten
-- Ejemplo: Consulta optimizada para particionado por rango de fechas
-- Solo examinará la partición correspondiente a 2022
SELECT SUM(total)
FROM facturas
WHERE fecha BETWEEN '2022-01-01' AND '2022-12-31';
Cada tipo de particionado tiene sus casos de uso ideales, y la elección correcta puede marcar una diferencia significativa en el rendimiento y la administración de tu base de datos a largo plazo.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el concepto y funcionamiento del particionamiento de tablas en bases de datos. Identificar los beneficios principales del particionamiento para el rendimiento y mantenimiento. Conocer los diferentes tipos de particionado: rango, lista, hash, clave y compuesto. Aprender las diferencias en la implementación de particiones entre MySQL y PostgreSQL. Saber cómo seleccionar el tipo de particionado adecuado según patrones de consulta y distribución de datos.