Relación One to One
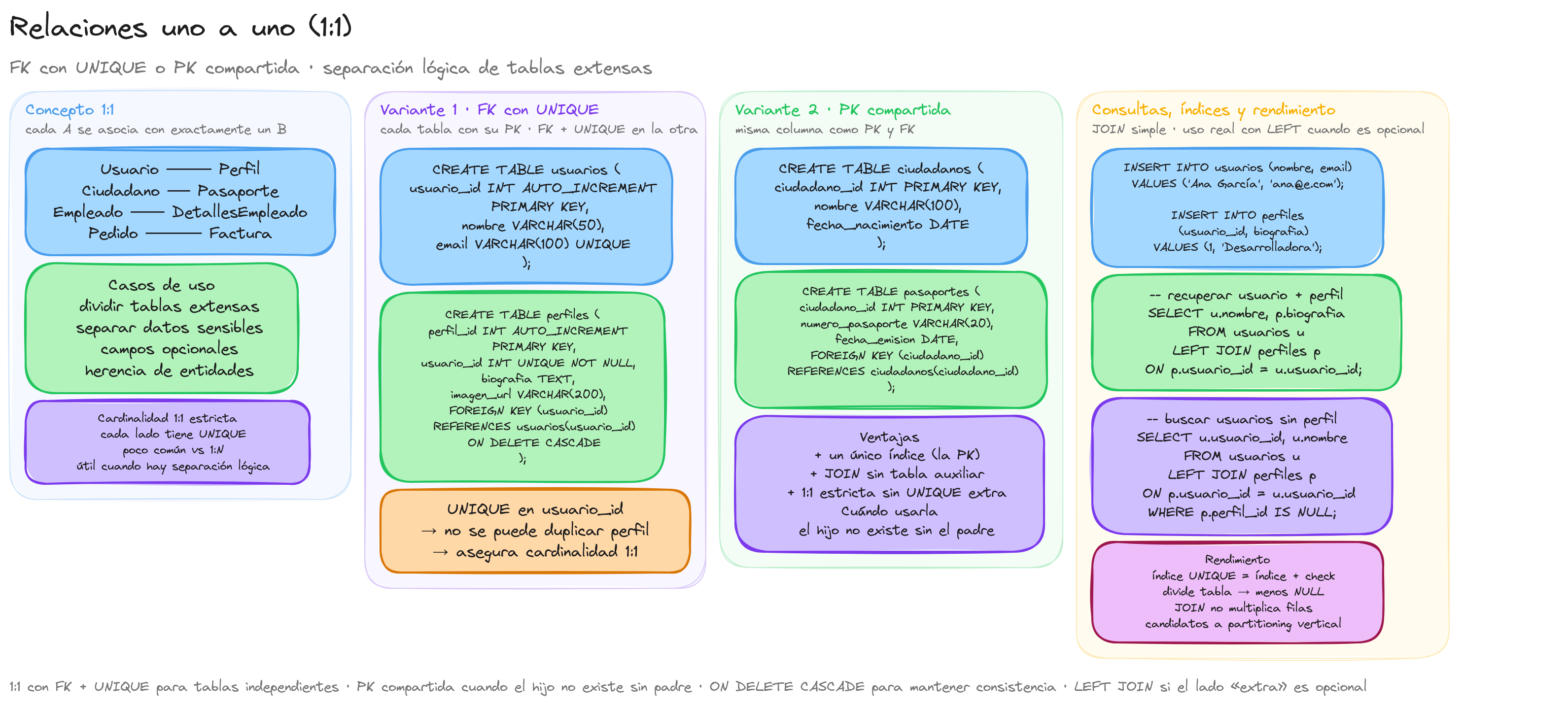
Una relación uno a uno (One to One) representa una asociación entre dos entidades donde cada registro de la primera tabla está relacionado con exactamente un registro de la segunda tabla, y viceversa. Esta es la relación más restrictiva entre tablas en un modelo de base de datos relacional.
En el diseño de bases de datos, las relaciones uno a uno suelen utilizarse en situaciones específicas que requieren una separación lógica de datos que conceptualmente pertenecen a la misma entidad. A diferencia de las relaciones uno a muchos, donde un registro puede estar asociado con múltiples registros de otra tabla, en las relaciones uno a uno existe una correspondencia directa y exclusiva.
Características principales
- Cada registro en la tabla A se relaciona con exactamente un registro en la tabla B
- Cada registro en la tabla B se relaciona con exactamente un registro en la tabla A
- La cardinalidad en ambos extremos de la relación es 1:1
- Se implementa mediante claves primarias y claves foráneas con restricciones de unicidad
Cuándo utilizar relaciones One to One
Las relaciones uno a uno son menos comunes que las relaciones uno a muchos, pero resultan útiles en varios escenarios:
-
Dividir tablas extensas: Cuando una tabla tiene muchas columnas, algunas de las cuales se utilizan con poca frecuencia, puede ser beneficioso separar esos campos en una tabla relacionada.
-
Información opcional: Para almacenar datos que no siempre están presentes para todas las entidades, evitando valores NULL en la tabla principal.
-
Seguridad de datos: Para restringir el acceso a cierta información sensible, colocándola en una tabla separada con permisos diferentes.
-
Herencia de entidades: Para implementar un tipo de herencia donde una entidad especializada extiende una entidad base.
-
Normalización: Como parte del proceso de normalización para eliminar dependencias parciales o transitivas.
Estructura básica
Para implementar una relación uno a uno, necesitamos establecer una clave foránea en una de las tablas que haga referencia a la clave primaria de la otra tabla. Además, esta clave foránea debe tener una restricción UNIQUE para garantizar que no se pueda relacionar más de un registro con la misma clave primaria.
Veamos un ejemplo conceptual:
CREATE TABLE empleados (
empleado_id INT PRIMARY KEY,
nombre VARCHAR(100),
apellido VARCHAR(100),
fecha_contratacion DATE
);
CREATE TABLE detalles_empleado (
detalle_id INT PRIMARY KEY,
empleado_id INT UNIQUE,
direccion VARCHAR(200),
telefono VARCHAR(20),
informacion_bancaria VARCHAR(100),
FOREIGN KEY (empleado_id) REFERENCES empleados(empleado_id)
);
En este ejemplo, cada empleado puede tener exactamente un registro de detalles, y cada registro de detalles pertenece a exactamente un empleado. La restricción UNIQUE en empleado_id en la tabla detalles_empleado garantiza que no podamos asignar múltiples registros de detalles al mismo empleado.
Decisiones de diseño
Al implementar una relación uno a uno, debemos decidir en qué tabla colocar la clave foránea. Esta decisión puede basarse en varios factores:
-
Opcionalidad: Si una de las entidades puede existir sin la otra, la clave foránea debería estar en la tabla que requiere la otra entidad.
-
Frecuencia de acceso: La clave foránea podría colocarse en la tabla que se consulta con más frecuencia para evitar joins innecesarios.
-
Integridad referencial: Considerar cómo afectará la eliminación de registros en cada escenario.
Por ejemplo, en nuestro caso de empleados y detalles, si los detalles son opcionales (un empleado puede existir sin tener detalles registrados), tiene sentido colocar la clave foránea en la tabla detalles_empleado.
Variantes de implementación
Existen diferentes formas de implementar relaciones uno a uno:
- Clave primaria compartida: Ambas tablas utilizan la misma clave primaria, que actúa también como clave foránea en la tabla secundaria.
CREATE TABLE pasaportes (
ciudadano_id INT PRIMARY KEY,
numero_pasaporte VARCHAR(20),
fecha_emision DATE,
fecha_vencimiento DATE,
FOREIGN KEY (ciudadano_id) REFERENCES ciudadanos(ciudadano_id)
);
- Claves primarias independientes: Cada tabla tiene su propia clave primaria autogenerada, y se establece una relación mediante una clave foránea con restricción de unicidad.
CREATE TABLE usuarios (
usuario_id INT PRIMARY KEY AUTO_INCREMENT,
nombre_usuario VARCHAR(50),
email VARCHAR(100)
);
CREATE TABLE perfiles (
perfil_id INT PRIMARY KEY AUTO_INCREMENT,
usuario_id INT UNIQUE,
biografia TEXT,
imagen_url VARCHAR(200),
FOREIGN KEY (usuario_id) REFERENCES usuarios(usuario_id)
);
La elección entre estas variantes dependerá de los requisitos específicos de la aplicación y consideraciones de rendimiento.
Consideraciones de rendimiento
Las relaciones uno a uno pueden tener implicaciones en el rendimiento de la base de datos:
-
Joins: Aunque las relaciones uno a uno son eficientes para joins (ya que no multiplican filas), siguen requiriendo operaciones de join que pueden afectar el rendimiento en tablas grandes.
-
Índices: La clave foránea en la relación uno a uno debe estar indexada para optimizar las consultas de join.
-
Espacio de almacenamiento: Dividir los datos en múltiples tablas puede reducir el espacio necesario si muchos campos son opcionales (NULL).
Ejemplo práctico en MySQL
Veamos un ejemplo más completo en MySQL de una relación uno a uno entre un usuario y su configuración de perfil:
-- Tabla principal de usuarios
CREATE TABLE usuarios (
usuario_id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL UNIQUE,
fecha_registro DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- Tabla de configuraciones con relación uno a uno
CREATE TABLE configuraciones_usuario (
configuracion_id INT AUTO_INCREMENT PRIMARY KEY,
usuario_id INT UNIQUE NOT NULL,
tema VARCHAR(20) DEFAULT 'claro',
notificaciones_email BOOLEAN DEFAULT TRUE,
idioma VARCHAR(10) DEFAULT 'es',
FOREIGN KEY (usuario_id) REFERENCES usuarios(usuario_id) ON DELETE CASCADE
);
-- Insertar un usuario
INSERT INTO usuarios (nombre, email) VALUES ('Ana García', 'ana@ejemplo.com');
-- Insertar su configuración
INSERT INTO configuraciones_usuario (usuario_id, tema, idioma)
VALUES (1, 'oscuro', 'en');
En este ejemplo, la cláusula ON DELETE CASCADE asegura que si se elimina un usuario, su configuración también se eliminará automáticamente, manteniendo la integridad de los datos.
Ejemplo práctico en PostgreSQL
PostgreSQL ofrece características adicionales para implementar relaciones uno a uno, como la posibilidad de usar restricciones de exclusión:
-- Tabla principal de estudiantes
CREATE TABLE estudiantes (
estudiante_id SERIAL PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
apellido VARCHAR(100) NOT NULL,
fecha_nacimiento DATE
);
-- Tabla de expedientes académicos con relación uno a uno
CREATE TABLE expedientes_academicos (
expediente_id SERIAL PRIMARY KEY,
estudiante_id INTEGER UNIQUE NOT NULL,
promedio_general DECIMAL(4,2),
creditos_aprobados INTEGER DEFAULT 0,
fecha_ultima_actualizacion DATE DEFAULT CURRENT_DATE,
FOREIGN KEY (estudiante_id) REFERENCES estudiantes(estudiante_id) ON DELETE CASCADE
);
-- Crear un índice para mejorar el rendimiento de las consultas
CREATE INDEX idx_expedientes_estudiante ON expedientes_academicos(estudiante_id);
El índice creado en la clave foránea estudiante_id mejorará el rendimiento de las consultas que relacionen ambas tablas.
Consultas en relaciones One to One
Para recuperar datos de tablas relacionadas uno a uno, utilizamos joins. Como cada registro se relaciona con exactamente un registro en la otra tabla, los joins no aumentan el número de filas en el resultado:
-- Consulta básica con JOIN
SELECT u.nombre, u.email, c.tema, c.idioma
FROM usuarios u
JOIN configuraciones_usuario c ON u.usuario_id = c.usuario_id;
-- Consulta con LEFT JOIN (incluye usuarios sin configuración)
SELECT e.nombre, e.apellido, ea.promedio_general
FROM estudiantes e
LEFT JOIN expedientes_academicos ea ON e.estudiante_id = ea.estudiante_id;
El uso de LEFT JOIN es útil cuando la relación es opcional y queremos incluir registros de la tabla principal que no tienen correspondencia en la tabla relacionada.
Implementación práctica
La implementación de una relación One to One requiere atención a detalles específicos para garantizar que la integridad de los datos se mantenga correctamente. Vamos a explorar diferentes escenarios prácticos y técnicas para implementar este tipo de relación en MySQL y PostgreSQL.
Implementación con clave primaria compartida
Una de las formas más eficientes de implementar una relación One to One es utilizando la misma clave primaria en ambas tablas. Esta técnica es especialmente útil cuando ambas entidades tienen una dependencia existencial fuerte.
-- Tabla de personas
CREATE TABLE personas (
persona_id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
apellido VARCHAR(100) NOT NULL,
fecha_nacimiento DATE
);
-- Tabla de licencias de conducir (relación 1:1 con personas)
CREATE TABLE licencias_conducir (
persona_id INT PRIMARY KEY,
numero_licencia VARCHAR(20) NOT NULL UNIQUE,
fecha_emision DATE NOT NULL,
fecha_vencimiento DATE NOT NULL,
tipo_licencia CHAR(2) NOT NULL,
FOREIGN KEY (persona_id) REFERENCES personas(persona_id) ON DELETE CASCADE
);
En este ejemplo, persona_id actúa como clave primaria en ambas tablas, lo que garantiza automáticamente la relación uno a uno. Esta implementación:
- Elimina la necesidad de una columna adicional de ID en la tabla secundaria
- Optimiza las consultas de join al utilizar la misma columna
- Reduce el espacio de almacenamiento necesario
Implementación con claves primarias independientes
Cuando las entidades son más independientes o cuando necesitamos mayor flexibilidad, podemos usar claves primarias separadas con una restricción UNIQUE:
-- Tabla de productos
CREATE TABLE productos (
producto_id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
precio DECIMAL(10,2) NOT NULL,
categoria VARCHAR(50)
);
-- Tabla de detalles técnicos (relación 1:1 con productos)
CREATE TABLE detalles_tecnicos (
detalle_id INT AUTO_INCREMENT PRIMARY KEY,
producto_id INT UNIQUE NOT NULL,
dimensiones VARCHAR(50),
peso DECIMAL(6,2),
material VARCHAR(100),
pais_fabricacion VARCHAR(50),
FOREIGN KEY (producto_id) REFERENCES productos(producto_id) ON DELETE CASCADE
);
Esta implementación ofrece:
- Mayor flexibilidad para gestionar cada entidad de forma independiente
- Posibilidad de crear el registro secundario en un momento diferente
- Facilidad para convertir la relación a uno a muchos en el futuro si los requisitos cambian
Implementación con restricciones adicionales
En algunos casos, necesitamos agregar restricciones adicionales para garantizar la integridad de la relación:
-- Tabla de empresas
CREATE TABLE empresas (
empresa_id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
direccion VARCHAR(200),
telefono VARCHAR(20)
);
-- Tabla de información fiscal (relación 1:1 con empresas)
CREATE TABLE informacion_fiscal (
info_fiscal_id INT AUTO_INCREMENT PRIMARY KEY,
empresa_id INT NOT NULL,
nif VARCHAR(15) NOT NULL UNIQUE,
regimen_fiscal VARCHAR(50),
fecha_constitucion DATE,
CONSTRAINT uc_empresa UNIQUE (empresa_id),
FOREIGN KEY (empresa_id) REFERENCES empresas(empresa_id) ON DELETE CASCADE
);
Aquí, la restricción UNIQUE se define como una restricción de tabla separada (CONSTRAINT uc_empresa), lo que permite nombrarla y facilita su gestión.
Implementación con opcionalidad
Muchas relaciones uno a uno son opcionales en uno de los lados. Por ejemplo, un empleado puede tener o no un vehículo de empresa asignado:
-- Tabla de empleados
CREATE TABLE empleados (
empleado_id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
departamento VARCHAR(50),
fecha_contratacion DATE
);
-- Tabla de vehículos de empresa (relación 1:1 opcional con empleados)
CREATE TABLE vehiculos_empresa (
vehiculo_id INT AUTO_INCREMENT PRIMARY KEY,
matricula VARCHAR(10) NOT NULL UNIQUE,
modelo VARCHAR(50) NOT NULL,
año INT,
empleado_id INT UNIQUE,
FOREIGN KEY (empleado_id) REFERENCES empleados(empleado_id) ON DELETE SET NULL
);
Observa que:
empleado_iden la tablavehiculos_empresapermite valores NULL- La cláusula
ON DELETE SET NULLestablece que si se elimina un empleado, el vehículo quedará sin asignar en lugar de eliminarse - La restricción
UNIQUEsigue aplicándose a los valores no nulos
Implementación bidireccional
En algunos casos, puede ser útil implementar una relación uno a uno bidireccional, donde ambas tablas tienen referencias a la otra:
-- Creamos primero las tablas con sus claves primarias
CREATE TABLE cuentas (
cuenta_id INT AUTO_INCREMENT PRIMARY KEY,
numero_cuenta VARCHAR(20) UNIQUE NOT NULL,
saldo DECIMAL(12,2) DEFAULT 0.00
);
CREATE TABLE titulares (
titular_id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
documento_identidad VARCHAR(15) UNIQUE NOT NULL,
fecha_nacimiento DATE
);
-- Luego añadimos las claves foráneas
ALTER TABLE cuentas
ADD COLUMN titular_id INT UNIQUE,
ADD CONSTRAINT fk_cuenta_titular FOREIGN KEY (titular_id) REFERENCES titulares(titular_id);
ALTER TABLE titulares
ADD COLUMN cuenta_id INT UNIQUE,
ADD CONSTRAINT fk_titular_cuenta FOREIGN KEY (cuenta_id) REFERENCES cuentas(cuenta_id);
Esta implementación es más compleja y puede generar problemas de integridad circular, por lo que generalmente se recomienda evitarla a menos que sea absolutamente necesaria.
Implementación en PostgreSQL con características específicas
PostgreSQL ofrece algunas características adicionales que pueden ser útiles para implementar relaciones uno a uno:
-- Tabla de usuarios
CREATE TABLE usuarios (
usuario_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
fecha_registro TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Tabla de datos biométricos con restricción de exclusión
CREATE TABLE datos_biometricos (
biometrico_id SERIAL PRIMARY KEY,
usuario_id INTEGER UNIQUE NOT NULL,
huella_digital BYTEA,
patron_facial BYTEA,
ultima_actualizacion TIMESTAMP,
FOREIGN KEY (usuario_id) REFERENCES usuarios(usuario_id) ON DELETE CASCADE,
EXCLUDE USING gist (usuario_id WITH =)
);
La restricción EXCLUDE proporciona una forma más flexible de garantizar la unicidad y puede combinarse con otras condiciones en PostgreSQL.
Consultas optimizadas para relaciones One to One
Para trabajar eficientemente con relaciones uno a uno, es importante optimizar las consultas:
-- Consulta básica con JOIN
SELECT p.nombre, p.apellido, l.numero_licencia, l.fecha_vencimiento
FROM personas p
JOIN licencias_conducir l ON p.persona_id = l.persona_id
WHERE p.apellido LIKE 'G%';
-- Consulta con LEFT JOIN para incluir personas sin licencia
SELECT p.nombre, p.apellido, l.numero_licencia
FROM personas p
LEFT JOIN licencias_conducir l ON p.persona_id = l.persona_id
ORDER BY p.apellido;
Para mejorar el rendimiento de estas consultas:
- Crea índices en las columnas de join (aunque las claves primarias ya están indexadas automáticamente)
- Utiliza
EXPLAINpara analizar el plan de ejecución de la consulta - Considera la posibilidad de desnormalizar datos frecuentemente consultados si el rendimiento es crítico
Inserción de datos relacionados
La inserción de datos en tablas con relación uno a uno requiere atención al orden de las operaciones:
-- Inserción en tablas con clave primaria compartida
INSERT INTO personas (nombre, apellido, fecha_nacimiento)
VALUES ('Carlos', 'Martínez', '1985-07-15');
INSERT INTO licencias_conducir (persona_id, numero_licencia, fecha_emision, fecha_vencimiento, tipo_licencia)
VALUES (LAST_INSERT_ID(), 'L12345678', '2020-01-10', '2030-01-10', 'B');
-- Inserción en tablas con claves independientes
INSERT INTO productos (nombre, precio, categoria)
VALUES ('Monitor UltraHD', 299.99, 'Electrónica');
INSERT INTO detalles_tecnicos (producto_id, dimensiones, peso, material, pais_fabricacion)
VALUES (LAST_INSERT_ID(), '60x35x10 cm', 5.2, 'Aluminio y plástico', 'Taiwán');
En MySQL, la función LAST_INSERT_ID() es útil para obtener el ID generado en la última inserción. En PostgreSQL, puedes usar RETURNING:
-- PostgreSQL: inserción con RETURNING
INSERT INTO usuarios (username, email)
VALUES ('ana_garcia', 'ana@ejemplo.com')
RETURNING usuario_id;
-- Usar el ID devuelto para insertar en la tabla relacionada
INSERT INTO datos_biometricos (usuario_id, ultima_actualizacion)
VALUES (1, CURRENT_TIMESTAMP);
Transacciones para mantener la integridad
Para garantizar que ambos lados de una relación uno a uno se creen o modifiquen de manera atómica, es recomendable utilizar transacciones:
-- Transacción para crear un empleado y su vehículo asignado
START TRANSACTION;
INSERT INTO empleados (nombre, departamento, fecha_contratacion)
VALUES ('Laura Sánchez', 'Ventas', '2023-03-15');
INSERT INTO vehiculos_empresa (matricula, modelo, año, empleado_id)
VALUES ('5678 ABC', 'Toyota Corolla', 2022, LAST_INSERT_ID());
COMMIT;
Las transacciones aseguran que:
- O se insertan ambos registros correctamente
- O no se inserta ninguno si ocurre algún error
Migración de datos entre esquemas
Si necesitas cambiar de un esquema a otro (por ejemplo, de claves independientes a clave compartida), puedes hacerlo con consultas de actualización:
-- Migración de esquema con claves independientes a clave compartida
CREATE TABLE nuevos_detalles_tecnicos (
producto_id INT PRIMARY KEY,
dimensiones VARCHAR(50),
peso DECIMAL(6,2),
material VARCHAR(100),
pais_fabricacion VARCHAR(50),
FOREIGN KEY (producto_id) REFERENCES productos(producto_id) ON DELETE CASCADE
);
-- Copiar datos de la tabla antigua a la nueva
INSERT INTO nuevos_detalles_tecnicos (producto_id, dimensiones, peso, material, pais_fabricacion)
SELECT dt.producto_id, dt.dimensiones, dt.peso, dt.material, dt.pais_fabricacion
FROM detalles_tecnicos dt;
-- Renombrar tablas para completar la migración
DROP TABLE detalles_tecnicos;
ALTER TABLE nuevos_detalles_tecnicos RENAME TO detalles_tecnicos;
Esta técnica permite evolucionar el esquema de la base de datos sin perder datos.
Verificación de la integridad de la relación
Para verificar que una relación uno a uno se mantiene correctamente, puedes usar consultas de validación:
-- Verificar que no hay duplicados en la relación
SELECT producto_id, COUNT(*)
FROM detalles_tecnicos
GROUP BY producto_id
HAVING COUNT(*) > 1;
-- Verificar que no hay registros huérfanos (si la relación debe ser obligatoria)
SELECT p.*
FROM productos p
LEFT JOIN detalles_tecnicos dt ON p.producto_id = dt.producto_id
WHERE dt.producto_id IS NULL;
Estas consultas son útiles para auditorías periódicas de la integridad de los datos.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es una relación uno a uno y sus características principales. Identificar cuándo y por qué utilizar relaciones uno a uno en el diseño de bases de datos. Aprender a implementar relaciones uno a uno con claves primarias compartidas o independientes. Conocer las implicaciones de rendimiento y cómo optimizar consultas en relaciones uno a uno. Aplicar técnicas prácticas para mantener la integridad y gestionar datos relacionados en bases de datos SQL.