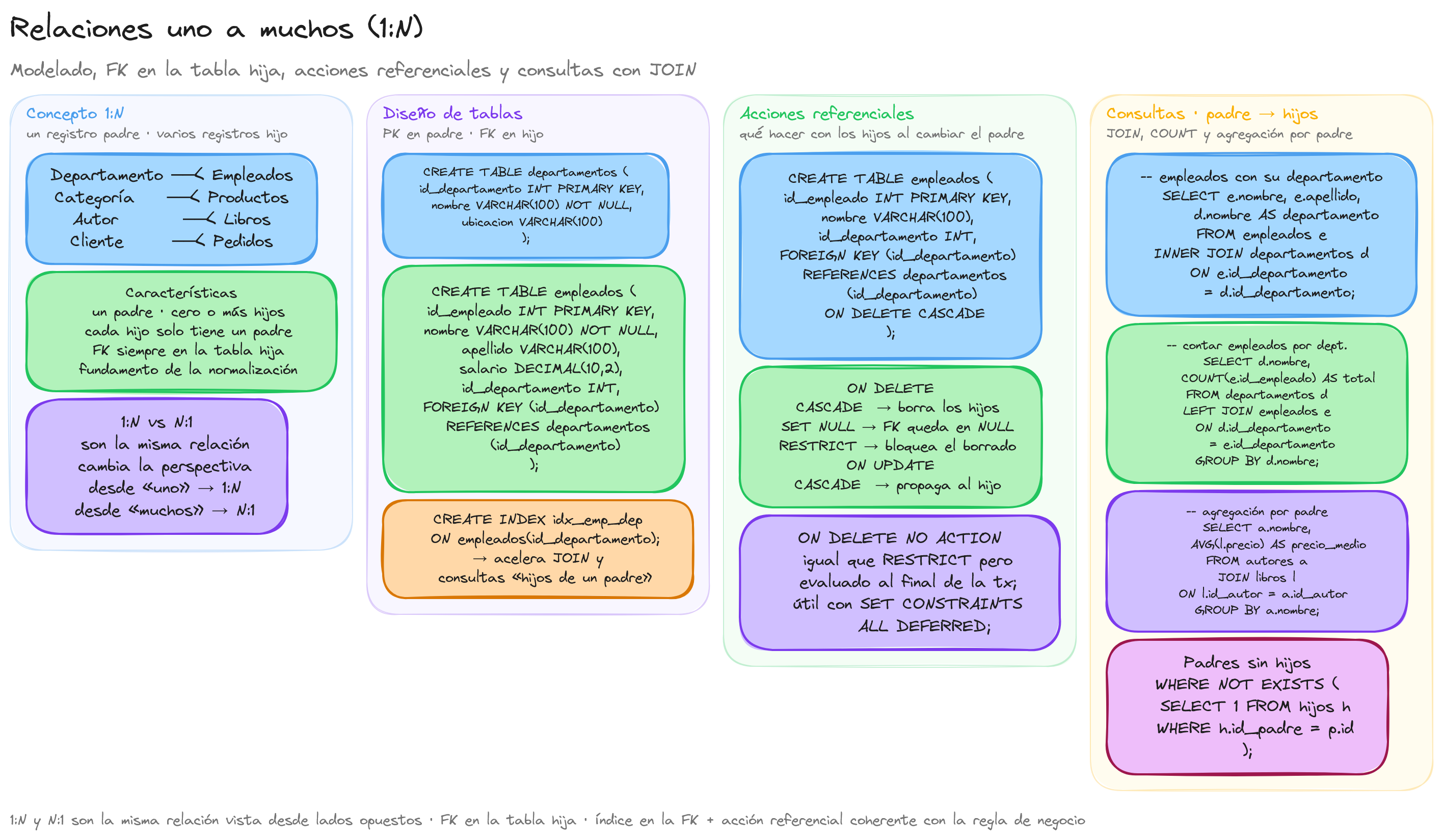
Concepto One-to-Many
La relación One-to-Many (uno a muchos) es uno de los tipos de asociaciones más comunes y fundamentales en el diseño de bases de datos relacionales. Esta relación se establece cuando un registro en la tabla A puede estar vinculado a múltiples registros en la tabla B, pero cada registro en la tabla B solo puede estar asociado a un único registro en la tabla A.
Para entender mejor este concepto, pensemos en ejemplos cotidianos. Un departamento puede tener muchos empleados, pero cada empleado pertenece a un único departamento. De manera similar, un cliente puede realizar muchas compras, pero cada compra está asociada a un solo cliente.
Estructura básica de una relación One-to-Many
En términos de diseño de bases de datos, una relación uno a muchos se implementa mediante el uso de claves foráneas. La tabla del lado "muchos" contiene una columna que hace referencia a la clave primaria de la tabla del lado "uno".
Veamos un ejemplo concreto con departamentos y empleados:
-- Tabla del lado "uno"
CREATE TABLE departamentos (
id_departamento INT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
ubicacion VARCHAR(100)
);
-- Tabla del lado "muchos"
CREATE TABLE empleados (
id_empleado INT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
apellido VARCHAR(100) NOT NULL,
salario DECIMAL(10,2),
id_departamento INT,
FOREIGN KEY (id_departamento) REFERENCES departamentos(id_departamento)
);
En este ejemplo, la columna id_departamento en la tabla empleados es una clave foránea que hace referencia a la clave primaria de la tabla departamentos. Esta estructura permite que un departamento tenga múltiples empleados, mientras que cada empleado pertenece a un solo departamento.
Características principales de las relaciones One-to-Many
-
Integridad referencial: La clave foránea garantiza que cada valor en la columna de referencia exista en la tabla principal, manteniendo así la integridad de los datos.
-
Cardinalidad: La relación se define como 1:N, donde N puede ser cero, uno o muchos registros.
-
Dirección: La relación tiene una dirección natural desde el lado "uno" hacia el lado "muchos".
Consultas en relaciones One-to-Many
Para recuperar datos relacionados en una estructura One-to-Many, utilizamos JOIN para combinar la información de ambas tablas:
-- Listar todos los empleados con su departamento
SELECT e.nombre, e.apellido, d.nombre AS departamento
FROM empleados e
INNER JOIN departamentos d ON e.id_departamento = d.id_departamento;
-- Contar cuántos empleados hay en cada departamento
SELECT d.nombre AS departamento, COUNT(e.id_empleado) AS num_empleados
FROM departamentos d
LEFT JOIN empleados e ON d.id_departamento = e.id_departamento
GROUP BY d.nombre;
Ejemplos prácticos de relaciones One-to-Many
Las relaciones uno a muchos son extremadamente comunes en el diseño de bases de datos. Algunos ejemplos adicionales incluyen:
- Autores y libros: Un autor puede escribir muchos libros, pero cada libro tiene un autor principal.
CREATE TABLE autores (
id_autor INT PRIMARY KEY,
nombre VARCHAR(100),
nacionalidad VARCHAR(50)
);
CREATE TABLE libros (
id_libro INT PRIMARY KEY,
titulo VARCHAR(200),
año_publicacion INT,
id_autor INT,
FOREIGN KEY (id_autor) REFERENCES autores(id_autor)
);
- Categorías y productos: Una categoría puede contener muchos productos, pero cada producto pertenece a una categoría principal.
CREATE TABLE categorias (
id_categoria INT PRIMARY KEY,
nombre VARCHAR(100),
descripcion TEXT
);
CREATE TABLE productos (
id_producto INT PRIMARY KEY,
nombre VARCHAR(100),
precio DECIMAL(10,2),
id_categoria INT,
FOREIGN KEY (id_categoria) REFERENCES categorias(id_categoria)
);
Consideraciones de diseño
Al implementar relaciones One-to-Many, es importante considerar:
- Opciones de eliminación: Definir qué sucede con los registros relacionados cuando se elimina un registro principal. Las opciones comunes son:
ON DELETE CASCADE: Elimina automáticamente los registros relacionados.ON DELETE SET NULL: Establece la clave foránea como NULL.ON DELETE RESTRICT: Impide la eliminación si existen registros relacionados.
-- Ejemplo con ON DELETE CASCADE
CREATE TABLE empleados (
id_empleado INT PRIMARY KEY,
nombre VARCHAR(100),
id_departamento INT,
FOREIGN KEY (id_departamento)
REFERENCES departamentos(id_departamento)
ON DELETE CASCADE
);
- Índices: Es recomendable crear índices en las columnas de clave foránea para mejorar el rendimiento de las consultas JOIN:
-- Crear un índice en la columna de clave foránea
CREATE INDEX idx_empleados_departamento ON empleados(id_departamento);
- Normalización: Las relaciones One-to-Many son fundamentales para la normalización de bases de datos, ayudando a eliminar la redundancia y mejorar la integridad de los datos.
La relación One-to-Many es un pilar fundamental en el diseño de bases de datos relacionales, permitiendo modelar eficientemente las asociaciones jerárquicas entre entidades. Dominar este concepto es esencial para crear esquemas de bases de datos robustos y eficientes que reflejen con precisión las relaciones del mundo real.
Diseño de tablas
El diseño efectivo de tablas para relaciones One-to-Many es fundamental para crear bases de datos robustas y eficientes. Un buen diseño no solo facilita las consultas y el mantenimiento, sino que también garantiza la integridad de los datos y optimiza el rendimiento del sistema.
Principios de diseño para relaciones One-to-Many
Al diseñar tablas para implementar relaciones uno a muchos, debemos seguir varios principios clave:
-
Identificación clara de entidades: Antes de crear tablas, identifica claramente qué entidad estará en el lado "uno" y cuál en el lado "muchos".
-
Selección adecuada de claves primarias: Cada tabla debe tener una clave primaria bien definida, preferiblemente un campo numérico autoincremental o un UUID.
-
Ubicación correcta de la clave foránea: La clave foránea siempre debe colocarse en la tabla del lado "muchos".
-
Nomenclatura consistente: Utiliza un sistema de nomenclatura coherente para facilitar la comprensión del esquema.
Estructura recomendada para tablas en relación One-to-Many
La estructura básica para implementar una relación uno a muchos implica dos tablas con la siguiente configuración:
Tabla principal (lado "uno"):
- Clave primaria
- Atributos propios de la entidad
- Sin referencias a la tabla secundaria
Tabla secundaria (lado "muchos"):
- Clave primaria propia
- Clave foránea que referencia a la tabla principal
- Atributos propios de la entidad
Ejemplo de diseño: Sistema de pedidos
Veamos un ejemplo práctico de diseño para un sistema de pedidos:
-- Tabla de clientes (lado "uno")
CREATE TABLE clientes (
cliente_id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
telefono VARCHAR(20),
fecha_registro DATE DEFAULT CURRENT_DATE
);
-- Tabla de pedidos (lado "muchos")
CREATE TABLE pedidos (
pedido_id INT AUTO_INCREMENT PRIMARY KEY,
cliente_id INT NOT NULL,
fecha_pedido DATETIME DEFAULT CURRENT_TIMESTAMP,
estado VARCHAR(50) DEFAULT 'pendiente',
total DECIMAL(10,2) NOT NULL,
FOREIGN KEY (cliente_id) REFERENCES clientes(cliente_id)
);
En este diseño, la tabla pedidos contiene la clave foránea cliente_id que establece la relación con la tabla clientes. Cada cliente puede tener múltiples pedidos, pero cada pedido pertenece a un único cliente.
Restricciones y opciones de integridad referencial
Al diseñar tablas con relaciones One-to-Many, es crucial definir el comportamiento de la integridad referencial:
- ON DELETE: Define qué sucede con los registros relacionados cuando se elimina un registro principal.
- ON UPDATE: Define qué sucede cuando se actualiza la clave primaria en la tabla principal.
Las opciones más comunes son:
-- Ejemplo con diferentes opciones de integridad referencial
CREATE TABLE pedidos (
pedido_id INT AUTO_INCREMENT PRIMARY KEY,
cliente_id INT NOT NULL,
fecha_pedido DATETIME DEFAULT CURRENT_TIMESTAMP,
total DECIMAL(10,2) NOT NULL,
FOREIGN KEY (cliente_id) REFERENCES clientes(cliente_id)
ON DELETE RESTRICT -- Impide eliminar un cliente si tiene pedidos
ON UPDATE CASCADE -- Actualiza automáticamente si cambia el ID del cliente
);
Otras opciones incluyen:
CASCADE: Propaga la acción (eliminación o actualización) a los registros relacionados.SET NULL: Establece la clave foránea como NULL cuando se elimina el registro principal.NO ACTION: Similar a RESTRICT, verifica al final de la transacción.
Optimización del diseño de tablas
Para mejorar el rendimiento en relaciones One-to-Many:
- Índices adecuados: Crea índices en las columnas de clave foránea para optimizar los JOIN:
-- Crear índice en la columna de clave foránea
CREATE INDEX idx_pedidos_cliente ON pedidos(cliente_id);
- Tipos de datos eficientes: Utiliza los tipos de datos más eficientes para las claves:
-- Uso de tipos de datos eficientes
CREATE TABLE productos (
producto_id SMALLINT UNSIGNED AUTO_INCREMENT PRIMARY KEY, -- Más eficiente que INT para tablas pequeñas
nombre VARCHAR(100) NOT NULL,
precio DECIMAL(8,2) NOT NULL
);
- Normalización adecuada: Evita la redundancia de datos mediante la normalización:
-- Diseño normalizado para direcciones de clientes
CREATE TABLE direcciones (
direccion_id INT AUTO_INCREMENT PRIMARY KEY,
cliente_id INT NOT NULL,
calle VARCHAR(100) NOT NULL,
ciudad VARCHAR(50) NOT NULL,
codigo_postal VARCHAR(10) NOT NULL,
es_principal BOOLEAN DEFAULT FALSE,
FOREIGN KEY (cliente_id) REFERENCES clientes(cliente_id)
ON DELETE CASCADE
);
Patrones de diseño para casos especiales
Relaciones One-to-Many con atributos adicionales
Cuando la relación misma tiene atributos, el diseño se mantiene igual:
-- Relación profesor-curso con atributos adicionales
CREATE TABLE profesores (
profesor_id INT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL
);
CREATE TABLE cursos (
curso_id INT PRIMARY KEY,
titulo VARCHAR(100) NOT NULL,
profesor_id INT NOT NULL,
fecha_inicio DATE NOT NULL,
duracion_semanas INT NOT NULL,
FOREIGN KEY (profesor_id) REFERENCES profesores(profesor_id)
);
Relaciones One-to-Many opcionales
Cuando la relación es opcional (un registro puede no tener relaciones), la clave foránea debe permitir valores NULL:
-- Empleados pueden tener o no un supervisor
CREATE TABLE empleados (
empleado_id INT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
supervisor_id INT,
FOREIGN KEY (supervisor_id) REFERENCES empleados(empleado_id)
);
Consideraciones específicas para MySQL y PostgreSQL
Ambos sistemas de gestión de bases de datos tienen características específicas a considerar:
MySQL:
- Utiliza
InnoDBcomo motor de almacenamiento para garantizar la integridad referencial:
CREATE TABLE pedidos (
pedido_id INT AUTO_INCREMENT PRIMARY KEY,
cliente_id INT NOT NULL,
total DECIMAL(10,2) NOT NULL,
FOREIGN KEY (cliente_id) REFERENCES clientes(cliente_id)
) ENGINE=InnoDB;
PostgreSQL:
- Aprovecha los tipos de datos específicos como
SERIALpara claves autoincrementales:
CREATE TABLE clientes (
cliente_id SERIAL PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL
);
Verificación del diseño
Una vez implementado el diseño, es importante verificar que las relaciones funcionen correctamente:
-- Insertar datos de prueba
INSERT INTO clientes (nombre, email) VALUES ('Ana García', 'ana@ejemplo.com');
INSERT INTO pedidos (cliente_id, total) VALUES (1, 150.75);
-- Verificar la relación con una consulta JOIN
SELECT c.nombre, p.pedido_id, p.total
FROM clientes c
JOIN pedidos p ON c.cliente_id = p.cliente_id;
Evolución del diseño
El diseño de tablas debe ser flexible para adaptarse a cambios futuros:
- Añadir columnas sin romper relaciones:
-- Añadir una columna a la tabla de pedidos sin afectar la relación
ALTER TABLE pedidos ADD COLUMN metodo_pago VARCHAR(50);
- Modificar restricciones de integridad referencial:
-- Cambiar la restricción ON DELETE
ALTER TABLE pedidos
DROP FOREIGN KEY pedidos_ibfk_1;
ALTER TABLE pedidos
ADD CONSTRAINT fk_pedidos_cliente
FOREIGN KEY (cliente_id) REFERENCES clientes(cliente_id)
ON DELETE CASCADE;
Un diseño de tablas bien planificado para relaciones One-to-Many proporciona una base sólida para construir aplicaciones eficientes y mantenibles. Al seguir estos principios y prácticas, podrás crear esquemas de bases de datos que representen fielmente las relaciones del mundo real mientras optimizas el rendimiento y la integridad de los datos.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el concepto y la estructura de una relación One-to-Many. Aprender a implementar relaciones One-to-Many mediante claves foráneas en SQL. Conocer las consideraciones de integridad referencial y opciones de eliminación. Diseñar tablas eficientes y normalizadas para relaciones One-to-Many. Realizar consultas SQL que aprovechen las relaciones One-to-Many para obtener datos relacionados.