Concepto teórico de Many-to-One
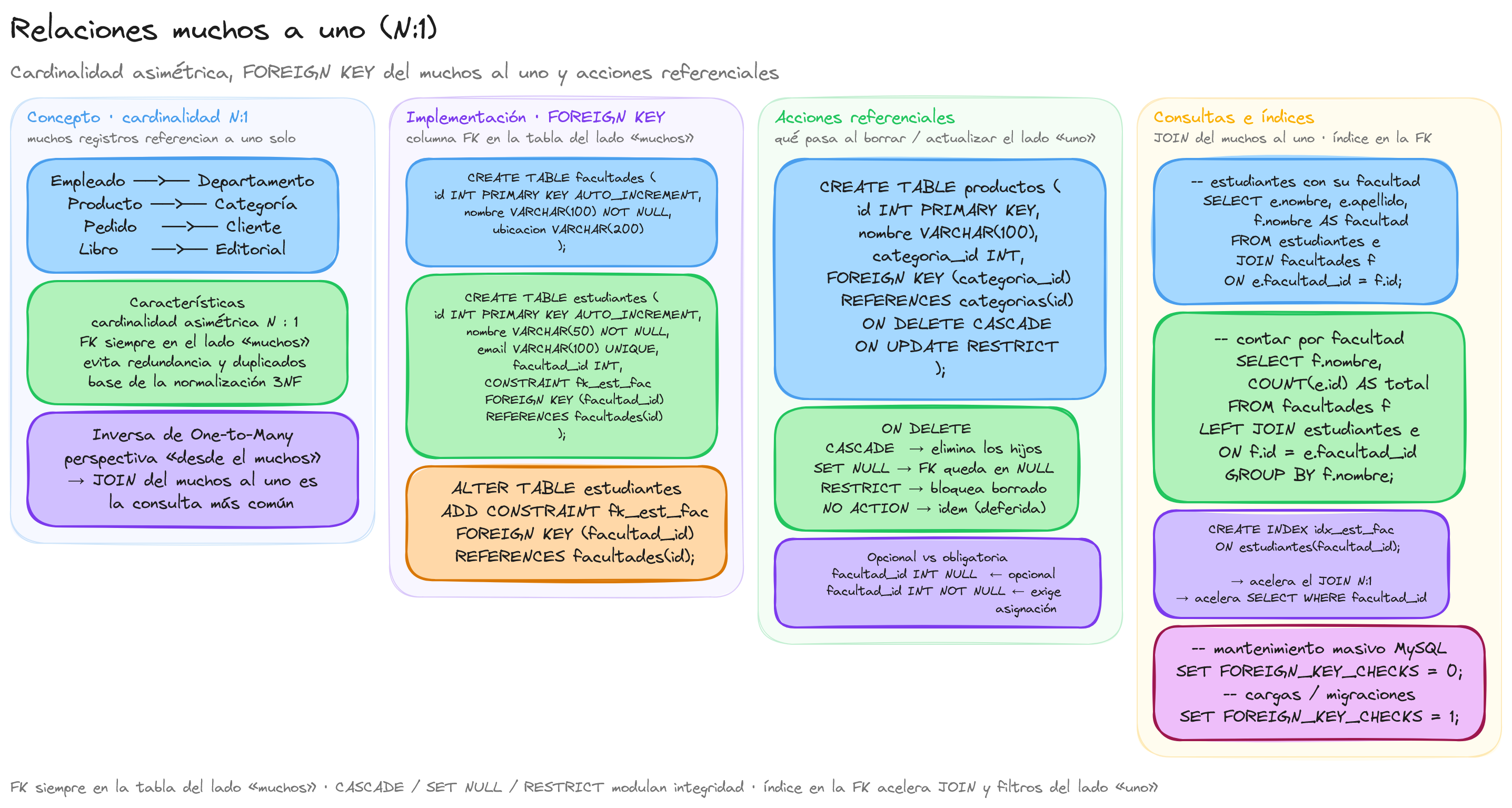
La relación Many-to-One (muchos a uno) representa uno de los tipos fundamentales de asociaciones entre tablas en bases de datos relacionales. Esta estructura permite modelar escenarios donde múltiples registros de una tabla pueden estar asociados con un único registro de otra tabla.
Imagina un sistema de gestión académica donde tenemos estudiantes y facultades. Cada estudiante pertenece a una facultad específica, pero una facultad puede tener muchos estudiantes. Esta es la esencia de una relación muchos a uno: muchos estudiantes se relacionan con una sola facultad.
Características principales
Las relaciones muchos a uno se caracterizan por:
- Cardinalidad asimétrica: En un extremo tenemos "muchos" (N) y en el otro "uno" (1).
- Dependencia direccional: Generalmente, la tabla "muchos" depende de la tabla "uno".
- Integridad referencial: Garantiza que cada registro en la tabla "muchos" tenga una correspondencia válida en la tabla "uno".
Representación conceptual
En un diagrama entidad-relación (ER), una relación muchos a uno se representa típicamente con una línea que conecta dos entidades, donde el extremo "muchos" se marca con una pata de cuervo o un símbolo de infinito, y el extremo "uno" con una línea simple o el número 1.
Ejemplos comunes de relaciones Many-to-One
- Empleados -> Departamento: Muchos empleados trabajan en un departamento.
- Productos -> Categoría: Muchos productos pertenecen a una categoría.
- Pedidos -> Cliente: Muchos pedidos son realizados por un cliente.
- Libros -> Editorial: Muchos libros son publicados por una editorial.
Ventajas de las relaciones Many-to-One
- Normalización de datos: Reduce la redundancia al almacenar información común en una tabla separada.
- Integridad de datos: Asegura que los datos relacionados sean consistentes.
- Eficiencia en almacenamiento: Ahorra espacio al evitar duplicar información.
- Facilidad de mantenimiento: Permite actualizar información en un solo lugar.
Consideraciones de diseño
Al implementar relaciones muchos a uno, es importante considerar:
- Dirección de la relación: Determinar qué tabla contiene la referencia a la otra.
- Obligatoriedad: Decidir si la relación es obligatoria u opcional (si un registro "muchos" debe tener siempre una correspondencia en la tabla "uno").
- Cascada de operaciones: Definir qué sucede con los registros relacionados cuando se modifica o elimina un registro en la tabla "uno".
Diferencia con otras relaciones
Es importante distinguir la relación muchos a uno de otros tipos de relaciones:
- One-to-One (1:1): Cada registro en la tabla A se relaciona con exactamente un registro en la tabla B, y viceversa.
- Many-to-Many (N:M): Múltiples registros en la tabla A pueden relacionarse con múltiples registros en la tabla B, requiriendo una tabla intermedia.
La relación muchos a uno es más restrictiva que la muchos a muchos, pero más flexible que la uno a uno, lo que la hace adecuada para modelar jerarquías y categorizaciones.
Ejemplo conceptual
Consideremos un sistema de biblioteca:
- Tabla Libros: Contiene información sobre cada libro (título, ISBN, año).
- Tabla Autores: Almacena datos de los autores (nombre, biografía).
Si modelamos que cada libro tiene exactamente un autor principal (simplificando), tendríamos una relación muchos a uno donde muchos libros pueden ser escritos por un mismo autor.
En este escenario, la tabla Libros (lado "muchos") contendría una referencia al autor correspondiente, mientras que la tabla Autores (lado "uno") no necesitaría referencias directas a los libros.
Implicaciones en el rendimiento
Las relaciones muchos a uno tienen implicaciones importantes en el rendimiento de las consultas:
- Las consultas que van del lado "muchos" al lado "uno" suelen ser eficientes.
- Las consultas que van del lado "uno" al lado "muchos" pueden requerir optimización adicional, especialmente cuando hay un gran volumen de datos.
Comprender el concepto teórico de las relaciones muchos a uno es fundamental para diseñar bases de datos eficientes y que representen correctamente las relaciones entre entidades del mundo real.
Implementación FK
La implementación de una relación Many-to-One en bases de datos relacionales se realiza mediante el uso de claves foráneas (Foreign Keys o FK). Una clave foránea es un campo o conjunto de campos en una tabla que hace referencia a la clave primaria de otra tabla, estableciendo así una conexión entre ambas.
Estructura básica de implementación
Para implementar una relación muchos a uno, seguimos estos pasos fundamentales:
- Identificar las dos tablas que participarán en la relación
- Determinar cuál es la tabla del lado "muchos" y cuál del lado "uno"
- Añadir una columna en la tabla "muchos" que referenciará a la clave primaria de la tabla "uno"
- Definir esta columna como clave foránea mediante la restricción FOREIGN KEY
Sintaxis para crear una clave foránea
Existen dos formas principales de implementar una clave foránea:
- Durante la creación de la tabla:
CREATE TABLE tabla_muchos (
id INT PRIMARY KEY,
-- otros campos
id_uno INT,
FOREIGN KEY (id_uno) REFERENCES tabla_uno(id)
);
- Alterando una tabla existente:
ALTER TABLE tabla_muchos
ADD FOREIGN KEY (id_uno) REFERENCES tabla_uno(id);
Ejemplo práctico
Implementemos la relación muchos a uno entre estudiantes y facultades que mencionamos conceptualmente:
-- Primero creamos la tabla del lado "uno"
CREATE TABLE facultades (
id INT PRIMARY KEY AUTO_INCREMENT,
nombre VARCHAR(100) NOT NULL,
ubicacion VARCHAR(200),
fecha_fundacion DATE
);
-- Luego creamos la tabla del lado "muchos" con la FK
CREATE TABLE estudiantes (
id INT PRIMARY KEY AUTO_INCREMENT,
nombre VARCHAR(50) NOT NULL,
apellido VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
facultad_id INT,
FOREIGN KEY (facultad_id) REFERENCES facultades(id)
);
En este ejemplo, facultad_id en la tabla estudiantes es la clave foránea que establece la relación muchos a uno con la tabla facultades.
Opciones adicionales para claves foráneas
Al implementar claves foráneas, podemos especificar comportamientos para las operaciones de actualización y eliminación:
CREATE TABLE productos (
id INT PRIMARY KEY AUTO_INCREMENT,
nombre VARCHAR(100) NOT NULL,
precio DECIMAL(10,2),
categoria_id INT,
FOREIGN KEY (categoria_id) REFERENCES categorias(id)
ON DELETE CASCADE
ON UPDATE RESTRICT
);
Las opciones más comunes son:
- ON DELETE CASCADE: Si se elimina un registro en la tabla "uno", se eliminarán automáticamente todos los registros relacionados en la tabla "muchos".
- ON DELETE SET NULL: Si se elimina un registro en la tabla "uno", el campo de clave foránea en los registros relacionados se establecerá como NULL.
- ON DELETE RESTRICT: Impide la eliminación de un registro en la tabla "uno" si existen registros relacionados.
- ON UPDATE CASCADE: Si se actualiza la clave primaria en la tabla "uno", se actualizarán automáticamente todas las referencias en la tabla "muchos".
Nombrando las restricciones de clave foránea
Es una buena práctica nombrar explícitamente las restricciones de clave foránea para facilitar su gestión:
CREATE TABLE pedidos (
id INT PRIMARY KEY,
fecha DATE,
cliente_id INT,
CONSTRAINT fk_pedidos_clientes FOREIGN KEY (cliente_id)
REFERENCES clientes(id)
);
Verificación de la implementación
Para verificar las claves foráneas existentes en MySQL:
SELECT * FROM information_schema.TABLE_CONSTRAINTS
WHERE CONSTRAINT_TYPE = 'FOREIGN KEY'
AND TABLE_SCHEMA = 'nombre_base_datos';
En PostgreSQL:
SELECT
tc.constraint_name, tc.table_name, kcu.column_name,
ccu.table_name AS foreign_table_name,
ccu.column_name AS foreign_column_name
FROM
information_schema.table_constraints AS tc
JOIN information_schema.key_column_usage AS kcu
ON tc.constraint_name = kcu.constraint_name
JOIN information_schema.constraint_column_usage AS ccu
ON ccu.constraint_name = tc.constraint_name
WHERE constraint_type = 'FOREIGN KEY';
Consideraciones de rendimiento
Al implementar claves foráneas, es importante considerar:
- Indexación: Las columnas de clave foránea deben estar indexadas para mejorar el rendimiento de las consultas JOIN:
CREATE INDEX idx_estudiantes_facultad ON estudiantes(facultad_id);
- Tipos de datos compatibles: Los campos relacionados deben tener tipos de datos idénticos o compatibles.
Claves foráneas compuestas
En algunos casos, necesitamos implementar claves foráneas que referencien a claves primarias compuestas:
CREATE TABLE inscripciones (
estudiante_id INT,
curso_id INT,
fecha_inscripcion DATE,
PRIMARY KEY (estudiante_id, curso_id),
FOREIGN KEY (estudiante_id) REFERENCES estudiantes(id),
FOREIGN KEY (curso_id) REFERENCES cursos(id)
);
Consultas comunes con relaciones Many-to-One
Una vez implementada la relación, podemos realizar consultas que aprovechen esta estructura:
-- Obtener todos los estudiantes con su facultad
SELECT e.nombre, e.apellido, f.nombre AS facultad
FROM estudiantes e
JOIN facultades f ON e.facultad_id = f.id;
-- Contar estudiantes por facultad
SELECT f.nombre, COUNT(e.id) AS total_estudiantes
FROM facultades f
LEFT JOIN estudiantes e ON f.id = e.facultad_id
GROUP BY f.nombre;
Desactivación temporal de restricciones
En algunas operaciones de mantenimiento, puede ser necesario desactivar temporalmente las restricciones de clave foránea:
En MySQL:
SET FOREIGN_KEY_CHECKS = 0;
-- Operaciones de mantenimiento
SET FOREIGN_KEY_CHECKS = 1;
En PostgreSQL:
SET CONSTRAINTS ALL DEFERRED;
-- Operaciones de mantenimiento
SET CONSTRAINTS ALL IMMEDIATE;
Relaciones opcionales vs obligatorias
Podemos implementar relaciones muchos a uno opcionales permitiendo valores NULL en la clave foránea:
CREATE TABLE productos (
id INT PRIMARY KEY,
nombre VARCHAR(100),
proveedor_id INT NULL, -- Relación opcional
FOREIGN KEY (proveedor_id) REFERENCES proveedores(id)
);
O hacerlas obligatorias con la restricción NOT NULL:
CREATE TABLE empleados (
id INT PRIMARY KEY,
nombre VARCHAR(100),
departamento_id INT NOT NULL, -- Relación obligatoria
FOREIGN KEY (departamento_id) REFERENCES departamentos(id)
);
La implementación correcta de claves foráneas es fundamental para mantener la integridad referencial de la base de datos, asegurando que las relaciones muchos a uno se mantengan consistentes y reflejen fielmente la lógica del negocio que representan.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el concepto y características de la relación many-to-one en bases de datos. Identificar cómo modelar relaciones many-to-one en diagramas entidad-relación. Implementar relaciones many-to-one usando claves foráneas en SQL. Configurar opciones de integridad referencial y comportamiento ante actualizaciones o eliminaciones. Realizar consultas y optimizaciones relacionadas con relaciones many-to-one.