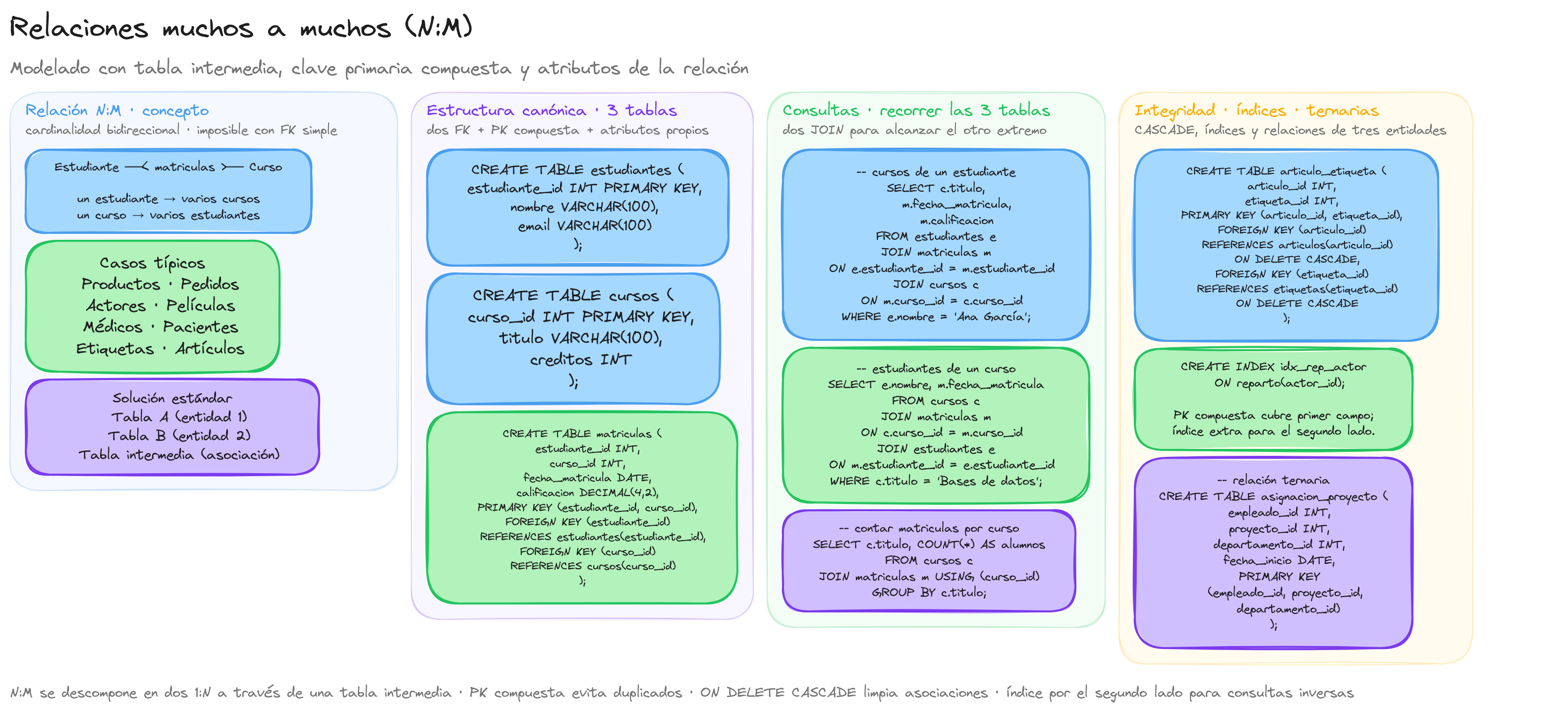
Relación M:N
Las relaciones muchos a muchos (M:N) representan uno de los tipos de asociaciones más versátiles y complejos en el diseño de bases de datos relacionales. A diferencia de las relaciones uno a uno (1:1) o uno a muchos (1:N), en una relación M:N cada registro de una tabla puede estar asociado con múltiples registros de otra tabla, y viceversa.
Imagina una biblioteca donde cada libro puede ser escrito por varios autores, y cada autor puede escribir múltiples libros. Esta es una relación muchos a muchos clásica que no puede modelarse directamente con claves foráneas simples como en las relaciones 1:N.
Características de las relaciones M:N
Las relaciones M:N tienen varias características distintivas:
- Bidireccionalidad: La asociación funciona en ambas direcciones con cardinalidad múltiple.
- Imposibilidad de implementación directa: No pueden implementarse directamente mediante claves foráneas simples en las tablas principales.
- Necesidad de descomposición: Requieren descomponerse en dos relaciones 1:N mediante una tabla intermedia.
- Flexibilidad: Permiten modelar asociaciones complejas del mundo real donde las entidades pueden relacionarse con múltiples instancias de otras entidades.
Ejemplos comunes de relaciones M:N
Algunos ejemplos típicos de relaciones muchos a muchos incluyen:
- Estudiantes y cursos: Un estudiante puede matricularse en varios cursos, y cada curso puede tener múltiples estudiantes.
- Productos y pedidos: Un pedido puede contener varios productos, y cada producto puede aparecer en múltiples pedidos.
- Actores y películas: Un actor puede participar en varias películas, y cada película puede tener múltiples actores.
- Médicos y pacientes: Un médico puede atender a varios pacientes, y un paciente puede ser atendido por varios médicos.
Modelado de relaciones M:N
Para modelar una relación M:N en una base de datos relacional, necesitamos crear una estructura de tres tablas:
- Tabla A: Representa una de las entidades principales
- Tabla B: Representa la otra entidad principal
- Tabla intermedia: Conecta ambas entidades y almacena las asociaciones
Veamos un ejemplo concreto con estudiantes y cursos:
-- Tabla de estudiantes
CREATE TABLE estudiantes (
estudiante_id INT PRIMARY KEY,
nombre VARCHAR(100),
email VARCHAR(100)
);
-- Tabla de cursos
CREATE TABLE cursos (
curso_id INT PRIMARY KEY,
titulo VARCHAR(100),
creditos INT
);
-- Tabla intermedia (tabla de unión)
CREATE TABLE matriculas (
estudiante_id INT,
curso_id INT,
fecha_matricula DATE,
calificacion DECIMAL(4,2),
PRIMARY KEY (estudiante_id, curso_id),
FOREIGN KEY (estudiante_id) REFERENCES estudiantes(estudiante_id),
FOREIGN KEY (curso_id) REFERENCES cursos(curso_id)
);
En este modelo:
- La tabla
estudiantescontiene información sobre cada estudiante - La tabla
cursosalmacena los detalles de cada curso - La tabla
matriculases la tabla intermedia que establece las relaciones entre estudiantes y cursos
Clave primaria en relaciones M:N
La tabla intermedia generalmente utiliza una clave primaria compuesta formada por las claves foráneas de ambas tablas principales. En nuestro ejemplo:
PRIMARY KEY (estudiante_id, curso_id)
Esta clave compuesta garantiza que un estudiante no pueda matricularse más de una vez en el mismo curso, lo que suele ser el comportamiento deseado en este tipo de relaciones.
Atributos adicionales en la relación
Una ventaja importante de las relaciones M:N es que la tabla intermedia puede contener atributos propios de la relación. En nuestro ejemplo de matriculación:
fecha_matricula: Cuándo se matriculó el estudiantecalificación: La nota obtenida por el estudiante en ese curso
Estos atributos no pertenecen ni al estudiante ni al curso por separado, sino a la relación entre ambos.
Consulta de datos en relaciones M:N
Para consultar datos en una relación M:N, necesitamos unir las tres tablas. Por ejemplo, para obtener todos los cursos de un estudiante específico:
SELECT c.titulo, m.fecha_matricula, m.calificacion
FROM estudiantes e
JOIN matriculas m ON e.estudiante_id = m.estudiante_id
JOIN cursos c ON m.curso_id = c.curso_id
WHERE e.nombre = 'Ana García';
O para encontrar todos los estudiantes matriculados en un curso particular:
SELECT e.nombre, e.email, m.fecha_matricula
FROM cursos c
JOIN matriculas m ON c.curso_id = m.curso_id
JOIN estudiantes e ON m.estudiante_id = e.estudiante_id
WHERE c.titulo = 'Bases de Datos';
Consideraciones de diseño
Al implementar relaciones M:N, es importante considerar:
- Nomenclatura de la tabla intermedia: Generalmente se nombra combinando los nombres de las dos entidades principales (ej.
estudiante_curso) o utilizando un sustantivo que describa la relación (ej.matriculas). - Restricciones de integridad: Las claves foráneas deben configurarse con las acciones adecuadas (CASCADE, RESTRICT, etc.) para mantener la integridad referencial.
- Índices: Además de la clave primaria compuesta, puede ser útil crear índices adicionales en la tabla intermedia para mejorar el rendimiento de las consultas.
Ejemplo práctico adicional: Sistema de etiquetado
Otro ejemplo común de relación M:N es un sistema de etiquetado para artículos o publicaciones:
-- Tabla de artículos
CREATE TABLE articulos (
articulo_id INT PRIMARY KEY,
titulo VARCHAR(200),
contenido TEXT,
fecha_publicacion DATE
);
-- Tabla de etiquetas
CREATE TABLE etiquetas (
etiqueta_id INT PRIMARY KEY,
nombre VARCHAR(50) UNIQUE
);
-- Tabla intermedia
CREATE TABLE articulo_etiqueta (
articulo_id INT,
etiqueta_id INT,
PRIMARY KEY (articulo_id, etiqueta_id),
FOREIGN KEY (articulo_id) REFERENCES articulos(articulo_id) ON DELETE CASCADE,
FOREIGN KEY (etiqueta_id) REFERENCES etiquetas(etiqueta_id) ON DELETE CASCADE
);
En este caso, la tabla intermedia articulo_etiqueta no necesita atributos adicionales, ya que simplemente establece la asociación entre artículos y etiquetas. La cláusula ON DELETE CASCADE asegura que si se elimina un artículo o una etiqueta, también se eliminarán automáticamente las asociaciones correspondientes en la tabla intermedia.
Para encontrar todos los artículos con una etiqueta específica:
SELECT a.titulo, a.fecha_publicacion
FROM etiquetas e
JOIN articulo_etiqueta ae ON e.etiqueta_id = ae.etiqueta_id
JOIN articulos a ON ae.articulo_id = a.articulo_id
WHERE e.nombre = 'SQL';
Las relaciones M:N son fundamentales para modelar correctamente muchas situaciones del mundo real en bases de datos relacionales, y su implementación adecuada mediante tablas intermedias es una habilidad esencial para cualquier desarrollador de bases de datos.
Tablas de unión
Las tablas de unión (también conocidas como tablas de enlace, tablas puente o tablas de intersección) son estructuras fundamentales para implementar relaciones muchos a muchos (M:N) en bases de datos relacionales. Estas tablas especializadas actúan como intermediarias entre dos entidades principales, permitiendo establecer asociaciones complejas que no podrían modelarse directamente.
Estructura básica de una tabla de unión
Una tabla de unión típicamente contiene:
- Claves foráneas que referencian a las tablas principales
- Una clave primaria compuesta formada por estas claves foráneas
- Opcionalmente, atributos adicionales que describen la relación
El siguiente diagrama conceptual muestra la estructura básica:
Tabla A <----> Tabla de unión <----> Tabla B
Convenciones de nomenclatura
Existen varias convenciones para nombrar las tablas de unión:
- Combinación de nombres: Unir los nombres de ambas tablas principales (ej.
producto_categoria) - Nombre descriptivo: Utilizar un sustantivo que describa la relación (ej.
matriculas,asignaciones) - Prefijo de unión: Añadir un prefijo como
rel_omap_(ej.rel_usuario_rol)
La elección depende de las convenciones del proyecto y la claridad que aporte al modelo.
Implementación de tablas de unión
Veamos un ejemplo práctico de una tabla de unión para gestionar la relación entre películas y actores:
-- Tabla principal: películas
CREATE TABLE peliculas (
pelicula_id INT PRIMARY KEY,
titulo VARCHAR(200),
año_lanzamiento INT,
duracion_minutos INT
);
-- Tabla principal: actores
CREATE TABLE actores (
actor_id INT PRIMARY KEY,
nombre VARCHAR(100),
fecha_nacimiento DATE
);
-- Tabla de unión: reparto
CREATE TABLE reparto (
pelicula_id INT,
actor_id INT,
personaje VARCHAR(100),
es_protagonista BOOLEAN,
PRIMARY KEY (pelicula_id, actor_id),
FOREIGN KEY (pelicula_id) REFERENCES peliculas(pelicula_id),
FOREIGN KEY (actor_id) REFERENCES actores(actor_id)
);
En este ejemplo, la tabla reparto es nuestra tabla de unión que:
- Conecta películas con actores mediante claves foráneas
- Establece una clave primaria compuesta para evitar duplicados
- Incluye atributos adicionales como
personajeyes_protagonista
Atributos en tablas de unión
Una característica valiosa de las tablas de unión es su capacidad para almacenar información contextual sobre la relación. Estos atributos pueden incluir:
- Metadatos temporales: Fechas de inicio/fin de la relación
- Información cuantitativa: Cantidades, porcentajes, puntuaciones
- Datos de estado: Estado actual de la relación
- Información descriptiva: Detalles específicos de la asociación
Por ejemplo, en un sistema de comercio electrónico:
CREATE TABLE pedido_producto (
pedido_id INT,
producto_id INT,
cantidad INT,
precio_unitario DECIMAL(10,2),
descuento_aplicado DECIMAL(5,2),
PRIMARY KEY (pedido_id, producto_id),
FOREIGN KEY (pedido_id) REFERENCES pedidos(pedido_id),
FOREIGN KEY (producto_id) REFERENCES productos(producto_id)
);
Aquí, cantidad, precio_unitario y descuento_aplicado son atributos que pertenecen específicamente a la relación entre un pedido y un producto.
Restricciones de integridad
Las tablas de unión requieren una configuración adecuada de restricciones de integridad referencial para mantener la consistencia de los datos:
CREATE TABLE usuario_grupo (
usuario_id INT,
grupo_id INT,
fecha_union TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
rol VARCHAR(50),
PRIMARY KEY (usuario_id, grupo_id),
FOREIGN KEY (usuario_id) REFERENCES usuarios(usuario_id)
ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (grupo_id) REFERENCES grupos(grupo_id)
ON DELETE CASCADE ON UPDATE CASCADE
);
Las cláusulas ON DELETE y ON UPDATE determinan qué ocurre cuando se elimina o actualiza un registro en las tablas principales:
- CASCADE: Propaga la eliminación/actualización a la tabla de unión
- RESTRICT/NO ACTION: Impide la eliminación/actualización si existen registros relacionados
- SET NULL: Establece como NULL las referencias en la tabla de unión
La elección depende de los requisitos específicos de la aplicación.
Optimización de tablas de unión
Para mejorar el rendimiento de las consultas que involucran tablas de unión:
- Índices adicionales: Además de la clave primaria compuesta, considere crear índices en columnas frecuentemente utilizadas en consultas:
CREATE INDEX idx_reparto_actor ON reparto(actor_id);
CREATE INDEX idx_reparto_protagonista ON reparto(es_protagonista);
- Orden de las columnas: En la clave primaria compuesta, coloque primero la columna más utilizada en las condiciones de filtrado:
-- Si filtramos más por película que por actor:
PRIMARY KEY (pelicula_id, actor_id)
-- Si filtramos más por actor que por película:
PRIMARY KEY (actor_id, pelicula_id)
Patrones de consulta comunes
Las tablas de unión requieren patrones específicos para consultar información efectivamente:
1. Encontrar todas las relaciones para una entidad
-- Todos los actores de una película específica
SELECT a.nombre, r.personaje
FROM actores a
JOIN reparto r ON a.actor_id = r.actor_id
WHERE r.pelicula_id = 123;
2. Contar relaciones
-- Número de películas por actor
SELECT a.nombre, COUNT(r.pelicula_id) AS num_peliculas
FROM actores a
JOIN reparto r ON a.actor_id = r.actor_id
GROUP BY a.actor_id, a.nombre;
3. Filtrar por atributos de la relación
-- Actores protagonistas en películas de 2023
SELECT a.nombre, p.titulo
FROM actores a
JOIN reparto r ON a.actor_id = r.actor_id
JOIN peliculas p ON r.pelicula_id = p.pelicula_id
WHERE p.año_lanzamiento = 2023
AND r.es_protagonista = TRUE;
Casos de uso avanzados
Tablas de unión con clave primaria independiente
En algunos casos, puede ser preferible utilizar una clave primaria independiente en lugar de una clave compuesta:
CREATE TABLE inscripciones (
inscripcion_id INT PRIMARY KEY AUTO_INCREMENT,
estudiante_id INT,
curso_id INT,
fecha_inscripcion DATE,
estado VARCHAR(20),
UNIQUE KEY (estudiante_id, curso_id),
FOREIGN KEY (estudiante_id) REFERENCES estudiantes(estudiante_id),
FOREIGN KEY (curso_id) REFERENCES cursos(curso_id)
);
Ventajas de este enfoque:
- Facilita las referencias a registros específicos de la relación
- Simplifica las actualizaciones de datos
- Permite relaciones múltiples entre las mismas entidades (si se elimina la restricción UNIQUE)
Tablas de unión para relaciones ternarias
Las tablas de unión también pueden modelar relaciones entre tres o más entidades:
CREATE TABLE asignacion_proyecto (
empleado_id INT,
proyecto_id INT,
departamento_id INT,
fecha_inicio DATE,
fecha_fin DATE,
horas_asignadas INT,
PRIMARY KEY (empleado_id, proyecto_id, departamento_id),
FOREIGN KEY (empleado_id) REFERENCES empleados(empleado_id),
FOREIGN KEY (proyecto_id) REFERENCES proyectos(proyecto_id),
FOREIGN KEY (departamento_id) REFERENCES departamentos(departamento_id)
);
Este diseño permite modelar situaciones donde un empleado trabaja en un proyecto para un departamento específico, con diferentes asignaciones de tiempo según el departamento.
Consideraciones prácticas
Al diseñar tablas de unión, tenga en cuenta:
- Cardinalidad real: Asegúrese de que realmente necesita una relación M:N y no una 1:N
- Evolución del modelo: Las tablas de unión facilitan la evolución del modelo si las relaciones cambian
- Normalización: Mantenga en la tabla de unión solo los atributos que pertenecen a la relación
- Documentación: Documente claramente el propósito de cada atributo en la tabla de unión
Las tablas de unión son estructuras fundamentales que permiten implementar relaciones complejas en bases de datos relacionales, proporcionando flexibilidad y capacidad para modelar escenarios del mundo real con precisión.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué son las relaciones muchos a muchos y sus características principales. Aprender a modelar relaciones M:N mediante tablas intermedias o de unión. Identificar la estructura y claves primarias compuestas en tablas de unión. Conocer cómo añadir atributos propios a la relación en la tabla intermedia. Aplicar consultas SQL para manejar y consultar datos en relaciones M:N. Entender las consideraciones de diseño, integridad referencial y optimización en tablas de unión.