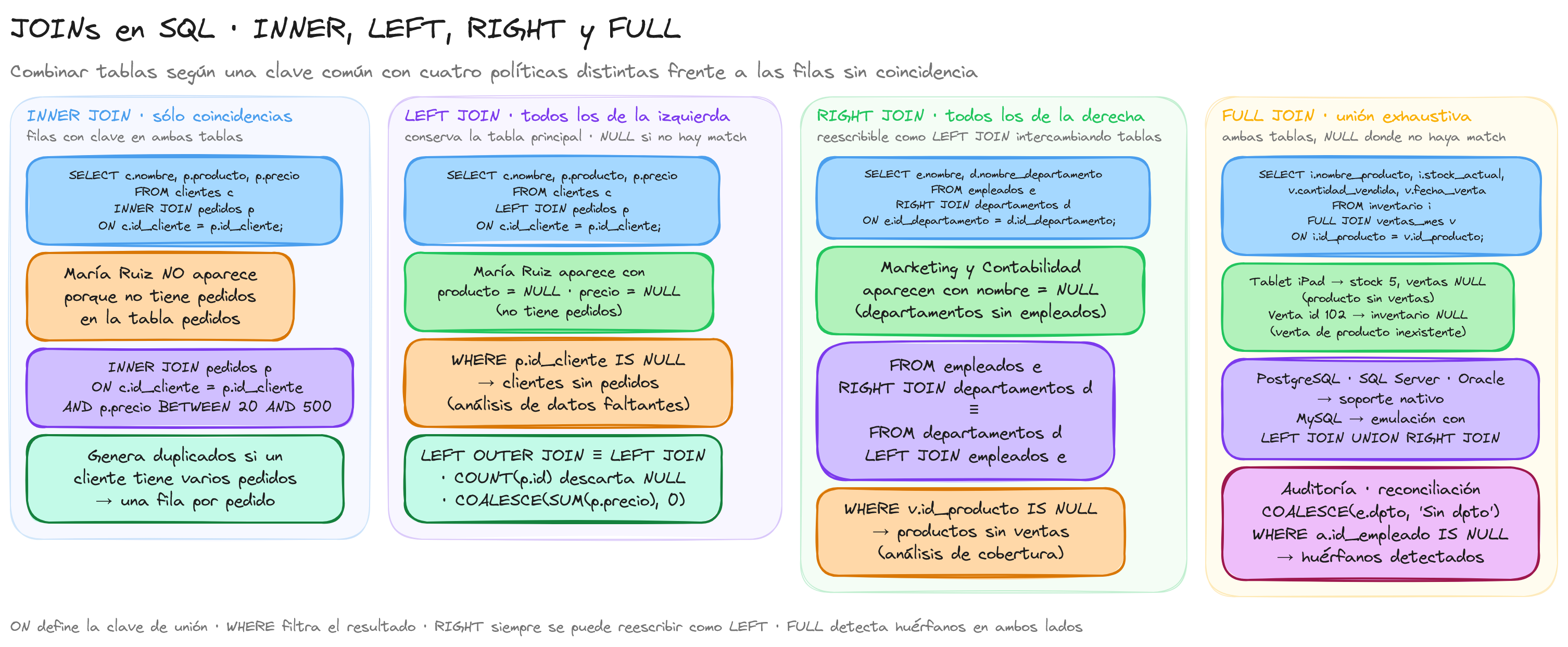
INNER JOIN
El INNER JOIN es la forma más común de combinar datos de dos o más tablas. Se utiliza cuando necesitamos obtener únicamente los registros que tienen valores coincidentes en ambas tablas involucradas en la unión.
Imaginemos que tenemos una base de datos de una tienda online con dos tablas: una tabla clientes con la información personal de los clientes, y una tabla pedidos con los pedidos realizados. Si queremos obtener una lista de clientes junto con sus pedidos, necesitamos unir estas dos tablas basándonos en un campo común, como el id_cliente.
Sintaxis básica
La sintaxis del INNER JOIN sigue esta estructura:
SELECT columna1, columna2, columna3
FROM tabla1
INNER JOIN tabla2
ON tabla1.campo_comun = tabla2.campo_comun;
Los elementos clave de esta sintaxis son:
- SELECT: específica qué columnas queremos mostrar en el resultado
- FROM: indica la primera tabla (tabla principal)
- INNER JOIN: específica la segunda tabla que queremos unir
- ON: define la condición de unión entre las tablas
Ejemplo práctico con clientes y pedidos
Supongamos que tenemos las siguientes tablas:
Tabla clientes:
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nombre VARCHAR(100),
email VARCHAR(100)
);
INSERT INTO clientes VALUES
(1, 'Ana García', 'ana@email.com'),
(2, 'Carlos López', 'carlos@email.com'),
(3, 'María Ruiz', 'maria@email.com');
Tabla pedidos:
CREATE TABLE pedidos (
id_pedido INT PRIMARY KEY,
id_cliente INT,
producto VARCHAR(100),
precio DECIMAL(10,2)
);
INSERT INTO pedidos VALUES
(101, 1, 'Portátil', 899.99),
(102, 2, 'Ratón inalámbrico', 25.50),
(103, 1, 'Monitor', 299.99);
Para obtener una lista de clientes con sus pedidos, utilizamos un INNER JOIN:
SELECT c.nombre, c.email, p.producto, p.precio
FROM clientes c
INNER JOIN pedidos p
ON c.id_cliente = p.id_cliente;
Este query devolvería:
| nombre | email | producto | precio | |--------|-------|----------|---------| | Ana García | ana@email.com | Portátil | 899.99 | | Ana García | ana@email.com | Monitor | 299.99 | | Carlos López | carlos@email.com | Ratón inalámbrico | 25.50 |
Características importantes del INNER JOIN
El comportamiento del INNER JOIN tiene características específicas que debemos entender:
- Solo devuelve coincidencias: únicamente aparecen en el resultado los registros que tienen valores coincidentes en ambas tablas
- Excluye registros sin coincidencias: si un cliente no tiene pedidos o si un pedido no tiene un cliente asociado válido, esos registros no aparecen en el resultado
- Puede generar duplicados: si un cliente tiene múltiples pedidos, aparecerá una fila por cada pedido
En nuestro ejemplo anterior, María Ruiz no aparece en el resultado porque no tiene ningún pedido asociado en la tabla pedidos.
Uso de alias para mejorar la legibilidad
Es una buena práctica utilizar alias para las tablas, especialmente cuando los nombres son largos:
SELECT c.nombre, p.producto, p.precio
FROM clientes c
INNER JOIN pedidos p
ON c.id_cliente = p.id_cliente
WHERE p.precio > 100;
Los alias c y p hacen que el código sea más legible y compacto, especialmente cuando trabajamos con múltiples tablas o consultas complejas.
INNER JOIN con múltiples condiciones
Podemos añadir condiciones adicionales en la cláusula ON para hacer uniones más específicas:
SELECT c.nombre, p.producto, p.precio
FROM clientes c
INNER JOIN pedidos p
ON c.id_cliente = p.id_cliente
AND p.precio BETWEEN 20 AND 500;
También podemos combinar el INNER JOIN con la cláusula WHERE para filtrar los resultados después de la unión:
SELECT c.nombre, p.producto, p.precio
FROM clientes c
INNER JOIN pedidos p
ON c.id_cliente = p.id_cliente
WHERE c.nombre LIKE 'A%'
ORDER BY p.precio DESC;
Esta consulta obtiene los pedidos de clientes cuyos nombres empiezan por 'A', ordenados por precio de mayor a menor.
LEFT JOIN
El LEFT JOIN es un tipo de unión que devuelve todos los registros de la tabla izquierda (primera tabla mencionada), junto con los registros coincidentes de la tabla derecha. Cuando no existe una coincidencia en la tabla derecha, los valores de las columnas de esa tabla aparecen como NULL.
A diferencia del INNER JOIN que solo muestra registros con coincidencias en ambas tablas, el LEFT JOIN garantiza que veamos todos los registros de la tabla principal, incluso aquellos que no tienen datos relacionados en la segunda tabla.
Sintaxis del LEFT JOIN
La estructura básica del LEFT JOIN es:
SELECT columna1, columna2, columna3
FROM tabla_izquierda
LEFT JOIN tabla_derecha
ON tabla_izquierda.campo_comun = tabla_derecha.campo_comun;
También podemos escribir LEFT OUTER JOIN, que es exactamente lo mismo:
SELECT columna1, columna2, columna3
FROM tabla_izquierda
LEFT OUTER JOIN tabla_derecha
ON tabla_izquierda.campo_comun = tabla_derecha.campo_comun;
Ejemplo práctico con todas las coincidencias
Retomando nuestras tablas de clientes y pedidos del ejemplo anterior, veamos cómo el LEFT JOIN muestra todos los clientes, incluidos aquellos sin pedidos:
SELECT c.nombre, c.email, p.producto, p.precio
FROM clientes c
LEFT JOIN pedidos p
ON c.id_cliente = p.id_cliente;
Este query devolvería:
| nombre | email | producto | precio | |--------|-------|----------|---------| | Ana García | ana@email.com | Portátil | 899.99 | | Ana García | ana@email.com | Monitor | 299.99 | | Carlos López | carlos@email.com | Ratón inalámbrico | 25.50 | | María Ruiz | maria@email.com | NULL | NULL |
Observa que María Ruiz aparece en el resultado aunque no tenga pedidos. Sus campos de producto y precio muestran NULL porque no existe información correspondiente en la tabla pedidos.
Cuándo utilizar LEFT JOIN
El LEFT JOIN es especialmente útil en estas situaciones:
- Informes completos: cuando necesitamos mostrar todos los registros de la tabla principal, independientemente de si tienen datos relacionados
- Análisis de datos faltantes: para identificar registros que no tienen información asociada en otras tablas
- Relaciones opcionales: cuando la relación entre tablas no es obligatoria
Identificar registros sin coincidencias
Una técnica común con LEFT JOIN es encontrar registros de la tabla izquierda que no tienen correspondencia en la tabla derecha:
SELECT c.nombre, c.email
FROM clientes c
LEFT JOIN pedidos p
ON c.id_cliente = p.id_cliente
WHERE p.id_cliente IS NULL;
Esta consulta nos mostraría solo los clientes que no han realizado ningún pedido. El filtro WHERE p.id_cliente IS NULL es clave para identificar estos casos.
Ejemplo con múltiples tablas
Supongamos que añadimos una tabla categorias para clasificar a nuestros clientes:
CREATE TABLE categorias (
id_categoria INT PRIMARY KEY,
nombre_categoria VARCHAR(50)
);
INSERT INTO categorias VALUES
(1, 'VIP'),
(2, 'Regular'),
(3, 'Nuevo');
-- Añadimos la columna categoria a la tabla clientes
ALTER TABLE clientes ADD COLUMN id_categoria INT;
UPDATE clientes SET id_categoria = 1 WHERE id_cliente = 1;
UPDATE clientes SET id_categoria = 2 WHERE id_cliente = 2;
-- María no tiene categoría asignada (NULL)
Podemos combinar múltiples LEFT JOIN para obtener información completa:
SELECT
c.nombre,
c.email,
cat.nombre_categoria,
p.producto,
p.precio
FROM clientes c
LEFT JOIN categorias cat
ON c.id_categoria = cat.id_categoria
LEFT JOIN pedidos p
ON c.id_cliente = p.id_cliente
ORDER BY c.nombre, p.precio DESC;
Agregaciones con LEFT JOIN
El LEFT JOIN es muy útil para calcular estadísticas que incluyan todos los registros de la tabla principal:
SELECT
c.nombre,
c.email,
COUNT(p.id_pedido) as total_pedidos,
COALESCE(SUM(p.precio), 0) as gasto_total
FROM clientes c
LEFT JOIN pedidos p
ON c.id_cliente = p.id_cliente
GROUP BY c.id_cliente, c.nombre, c.email;
En este ejemplo:
- COUNT(p.id_pedido) cuenta solo los pedidos existentes (no cuenta NULL)
- COALESCE(SUM(p.precio), 0) convierte NULL en 0 para clientes sin pedidos
- GROUP BY agrupa por cliente para obtener estadísticas individuales
Diferencias clave con INNER JOIN
Para clarificar las diferencias, comparemos ambos tipos de JOIN:
INNER JOIN:
- Solo muestra registros con coincidencias en ambas tablas
- María Ruiz no aparecería en el resultado
- Útil cuando necesitamos datos completos de ambas tablas
LEFT JOIN:
- Muestra todos los registros de la tabla izquierda
- María Ruiz aparece con valores NULL en las columnas de pedidos
- Útil cuando la tabla izquierda es la principal y queremos preservar todos sus registros
RIGHT JOIN
El RIGHT JOIN es el opuesto conceptual del LEFT JOIN. Mientras que el LEFT JOIN conserva todos los registros de la tabla izquierda, el RIGHT JOIN garantiza que aparezcan todos los registros de la tabla derecha (la segunda tabla mencionada), junto con los registros coincidentes de la tabla izquierda.
Cuando no existe una coincidencia en la tabla izquierda, los valores de las columnas de esa tabla aparecen como NULL en el resultado final. Este tipo de unión es menos común en la práctica, pero resulta útil en situaciones específicas donde la tabla derecha es la referencia principal.
Sintaxis del RIGHT JOIN
La estructura básica del RIGHT JOIN es:
SELECT columna1, columna2, columna3
FROM tabla_izquierda
RIGHT JOIN tabla_derecha
ON tabla_izquierda.campo_comun = tabla_derecha.campo_comun;
Al igual que con LEFT JOIN, podemos utilizar RIGHT OUTER JOIN, que es exactamente equivalente:
SELECT columna1, columna2, columna3
FROM tabla_izquierda
RIGHT OUTER JOIN tabla_derecha
ON tabla_izquierda.campo_comun = tabla_derecha.campo_comun;
Ejemplo práctico con departamentos y empleados
Para ilustrar el RIGHT JOIN, creemos un nuevo escenario con tablas de empleados y departamentos:
CREATE TABLE departamentos (
id_departamento INT PRIMARY KEY,
nombre_departamento VARCHAR(100)
);
INSERT INTO departamentos VALUES
(1, 'Recursos Humanos'),
(2, 'Desarrollo'),
(3, 'Marketing'),
(4, 'Contabilidad');
CREATE TABLE empleados (
id_empleado INT PRIMARY KEY,
nombre VARCHAR(100),
id_departamento INT
);
INSERT INTO empleados VALUES
(1, 'Laura Martín', 1),
(2, 'Diego Fernández', 2),
(3, 'Carmen Silva', 2);
Ahora utilizamos RIGHT JOIN para obtener todos los departamentos, incluso aquellos sin empleados:
SELECT e.nombre, d.nombre_departamento
FROM empleados e
RIGHT JOIN departamentos d
ON e.id_departamento = d.id_departamento;
El resultado sería:
| nombre | nombre_departamento | |--------|---------------------| | Laura Martín | Recursos Humanos | | Diego Fernández | Desarrollo | | Carmen Silva | Desarrollo | | NULL | Marketing | | NULL | Contabilidad |
Comparación directa: LEFT vs RIGHT JOIN
Para comprender mejor las diferencias, comparemos ambos tipos de JOIN con las mismas tablas:
LEFT JOIN (prioriza empleados):
SELECT e.nombre, d.nombre_departamento
FROM empleados e
LEFT JOIN departamentos d
ON e.id_departamento = d.id_departamento;
Este query mostraría todos los empleados, incluso si no tienen departamento asignado.
RIGHT JOIN (prioriza departamentos):
SELECT e.nombre, d.nombre_departamento
FROM empleados e
RIGHT JOIN departamentos d
ON e.id_departamento = d.id_departamento;
Este query muestra todos los departamentos, incluso si no tienen empleados asignados.
Equivalencia con LEFT JOIN
Una característica importante del RIGHT JOIN es que siempre puede reescribirse como un LEFT JOIN intercambiando el orden de las tablas:
RIGHT JOIN original:
SELECT e.nombre, d.nombre_departamento
FROM empleados e
RIGHT JOIN departamentos d
ON e.id_departamento = d.id_departamento;
Equivalente con LEFT JOIN:
SELECT e.nombre, d.nombre_departamento
FROM departamentos d
LEFT JOIN empleados e
ON d.id_departamento = e.id_departamento;
Ambas consultas producen exactamente el mismo resultado. Por esta razón, muchos desarrolladores prefieren usar únicamente LEFT JOIN para mantener consistencia en el código.
Casos prácticos para RIGHT JOIN
Aunque es menos frecuente, el RIGHT JOIN es útil en estas situaciones:
- Análisis de cobertura: identificar elementos de un catálogo (productos, servicios, departamentos) que no tienen actividad asociada
- Auditorías de integridad: verificar qué registros de referencia no tienen datos dependientes
- Informes de disponibilidad: mostrar todos los recursos disponibles, incluso los no utilizados
Ejemplo con análisis de ventas
Supongamos que tenemos una tabla de productos y otra de ventas:
CREATE TABLE productos (
id_producto INT PRIMARY KEY,
nombre_producto VARCHAR(100),
categoria VARCHAR(50)
);
INSERT INTO productos VALUES
(1, 'Smartphone Pro', 'Electrónica'),
(2, 'Auriculares Bluetooth', 'Electrónica'),
(3, 'Camiseta Básica', 'Ropa'),
(4, 'Zapatillas Deportivas', 'Calzado');
CREATE TABLE ventas (
id_venta INT PRIMARY KEY,
id_producto INT,
cantidad INT,
fecha_venta DATE
);
INSERT INTO ventas VALUES
(1, 1, 5, '2024-01-15'),
(2, 2, 3, '2024-01-16'),
(3, 1, 2, '2024-01-17');
Para identificar productos sin ventas, utilizamos RIGHT JOIN:
SELECT
p.nombre_producto,
p.categoria,
COALESCE(SUM(v.cantidad), 0) as total_vendido
FROM ventas v
RIGHT JOIN productos p
ON v.id_producto = p.id_producto
GROUP BY p.id_producto, p.nombre_producto, p.categoria
ORDER BY total_vendido ASC;
Esta consulta nos mostraría todos los productos ordenados por ventas, con los productos sin ventas al principio (total_vendido = 0).
Filtrado con RIGHT JOIN
Podemos combinar RIGHT JOIN con condiciones WHERE para análisis más específicos:
SELECT p.nombre_producto, p.categoria
FROM ventas v
RIGHT JOIN productos p
ON v.id_producto = p.id_producto
WHERE v.id_producto IS NULL;
Esta consulta identifica exclusivamente los productos que no han tenido ventas, utilizando la condición WHERE v.id_producto IS NULL para filtrar solo los registros sin coincidencias.
Consideraciones de rendimiento
Aunque RIGHT JOIN es funcionalmente equivalente a LEFT JOIN, es importante considerar:
- La legibilidad del código mejora cuando la tabla principal aparece en la posición lógicamente esperada
- Los optimizadores de consultas modernos manejan ambos tipos de JOIN de manera similar
- La consistencia en el equipo de desarrollo es más importante que el tipo específico de JOIN elegido
En la práctica, la mayoría de desarrolladores prefieren LEFT JOIN por su mayor intuitividad, reservando RIGHT JOIN para casos donde la estructura de la consulta lo haga más claro semánticamente.
FULL JOIN
El FULL JOIN (también conocido como FULL OUTER JOIN) es el tipo de unión más inclusivo de todos. Combina los resultados de LEFT JOIN y RIGHT JOIN en una sola operación, devolviendo todos los registros de ambas tablas, independientemente de si tienen coincidencias o no.
Cuando no existe una coincidencia en alguna de las tablas, los valores de las columnas correspondientes aparecen como NULL. Esta característica hace que el FULL JOIN sea especialmente útil para obtener una vista completa de los datos de ambas tablas sin perder información.
Sintaxis del FULL JOIN
La estructura básica del FULL JOIN es:
SELECT columna1, columna2, columna3
FROM tabla1
FULL JOIN tabla2
ON tabla1.campo_comun = tabla2.campo_comun;
También podemos escribir FULL OUTER JOIN, que es exactamente equivalente:
SELECT columna1, columna2, columna3
FROM tabla1
FULL OUTER JOIN tabla2
ON tabla1.campo_comun = tabla2.campo_comun;
Ejemplo práctico con inventario y ventas
Para ilustrar el FULL JOIN, creemos un escenario donde tenemos productos en inventario y registros de ventas. Queremos obtener una vista completa que incluya tanto productos vendidos como no vendidos, y también detectar ventas de productos que ya no están en inventario:
CREATE TABLE inventario (
id_producto INT PRIMARY KEY,
nombre_producto VARCHAR(100),
stock_actual INT
);
INSERT INTO inventario VALUES
(1, 'Smartphone Galaxy', 15),
(2, 'Auriculares Sony', 8),
(3, 'Tablet iPad', 5);
CREATE TABLE ventas_mes (
id_venta INT PRIMARY KEY,
id_producto INT,
cantidad_vendida INT,
fecha_venta DATE
);
INSERT INTO ventas_mes VALUES
(101, 1, 3, '2024-01-10'),
(102, 4, 1, '2024-01-12'), -- Producto no existe en inventario
(103, 2, 2, '2024-01-15');
Aplicamos FULL JOIN para obtener el panorama completo:
SELECT
i.nombre_producto,
i.stock_actual,
v.cantidad_vendida,
v.fecha_venta
FROM inventario i
FULL JOIN ventas_mes v
ON i.id_producto = v.id_producto;
El resultado sería:
| nombre_producto | stock_actual | cantidad_vendida | fecha_venta | |----------------|--------------|------------------|-------------| | Smartphone Galaxy | 15 | 3 | 2024-01-10 | | Auriculares Sony | 8 | 2 | 2024-01-15 | | Tablet iPad | 5 | NULL | NULL | | NULL | NULL | 1 | 2024-01-12 |
Análisis del resultado
El resultado del FULL JOIN nos proporciona información valiosa:
- Productos con ventas: Smartphone Galaxy y Auriculares Sony aparecen con sus datos completos
- Productos sin ventas: Tablet iPad aparece con valores NULL en las columnas de ventas
- Ventas sin producto: La venta del producto ID 4 aparece con NULL en las columnas de inventario
Esta visibilidad completa es fundamental para análisis de negocio, auditorías de datos y detección de inconsistencias.
Compatibilidad entre sistemas de bases de datos
Es importante conocer que el soporte para FULL JOIN varía entre sistemas de bases de datos:
Sistemas con soporte nativo:
- PostgreSQL
- SQL Server
- Oracle
- SQLite (versiones recientes)
Sistemas sin soporte nativo:
- MySQL (requiere emulación)
Emulación de FULL JOIN en MySQL
En MySQL, podemos simular un FULL JOIN combinando LEFT JOIN y RIGHT JOIN con UNION:
SELECT
i.nombre_producto,
i.stock_actual,
v.cantidad_vendida,
v.fecha_venta
FROM inventario i
LEFT JOIN ventas_mes v
ON i.id_producto = v.id_producto
UNION
SELECT
i.nombre_producto,
i.stock_actual,
v.cantidad_vendida,
v.fecha_venta
FROM inventario i
RIGHT JOIN ventas_mes v
ON i.id_producto = v.id_producto
WHERE i.id_producto IS NULL;
Esta técnica produce exactamente el mismo resultado que un FULL JOIN nativo.
Casos de uso prácticos
El FULL JOIN es especialmente útil en estas situaciones:
- Auditorías de datos: comparar dos tablas para identificar discrepancias o registros huérfanos
- Análisis de cobertura: determinar qué elementos de un conjunto no tienen correspondencia en otro
- Reconciliación de sistemas: verificar la consistencia entre diferentes fuentes de datos
- Informes completos: generar reportes que requieren mostrar toda la información disponible
Ejemplo con análisis de empleados y proyectos
Supongamos que queremos analizar la asignación de empleados a proyectos:
CREATE TABLE empleados_activos (
id_empleado INT PRIMARY KEY,
nombre VARCHAR(100),
departamento VARCHAR(50)
);
INSERT INTO empleados_activos VALUES
(1, 'Ana López', 'Desarrollo'),
(2, 'Carlos Ruiz', 'Marketing'),
(3, 'María García', 'Desarrollo');
CREATE TABLE asignaciones_proyecto (
id_asignacion INT PRIMARY KEY,
id_empleado INT,
nombre_proyecto VARCHAR(100),
horas_asignadas INT
);
INSERT INTO asignaciones_proyecto VALUES
(1, 1, 'App Móvil', 40),
(2, 4, 'Web Corporativa', 30), -- Empleado no activo
(3, 2, 'Campaña Digital', 25);
Con FULL JOIN obtenemos un análisis completo:
SELECT
e.nombre AS empleado,
e.departamento,
a.nombre_proyecto,
a.horas_asignadas
FROM empleados_activos e
FULL JOIN asignaciones_proyecto a
ON e.id_empleado = a.id_empleado
ORDER BY e.nombre, a.nombre_proyecto;
Agregaciones con FULL JOIN
Podemos combinar FULL JOIN con funciones agregadas para obtener estadísticas completas:
SELECT
COALESCE(e.departamento, 'Sin departamento') AS departamento,
COUNT(e.id_empleado) AS empleados_activos,
COUNT(a.id_asignacion) AS proyectos_asignados,
COALESCE(SUM(a.horas_asignadas), 0) AS total_horas
FROM empleados_activos e
FULL JOIN asignaciones_proyecto a
ON e.id_empleado = a.id_empleado
GROUP BY e.departamento
ORDER BY total_horas DESC;
En este ejemplo:
- COALESCE maneja los valores NULL para mostrar etiquetas descriptivas
- COUNT cuenta solo los registros no NULL de cada tabla
- SUM calcula el total de horas, convirtiendo NULL en 0
Identificar registros sin coincidencias
Una técnica útil con FULL JOIN es identificar registros que solo existen en una de las tablas:
Empleados sin proyectos asignados:
SELECT e.nombre, e.departamento
FROM empleados_activos e
FULL JOIN asignaciones_proyecto a
ON e.id_empleado = a.id_empleado
WHERE a.id_empleado IS NULL;
Proyectos asignados a empleados inactivos:
SELECT a.nombre_proyecto, a.horas_asignadas
FROM empleados_activos e
FULL JOIN asignaciones_proyecto a
ON e.id_empleado = a.id_empleado
WHERE e.id_empleado IS NULL;
Consideraciones de rendimiento
El FULL JOIN puede ser más costoso computacionalmente que otros tipos de JOIN porque:
- Requiere procesar todos los registros de ambas tablas
- Genera el conjunto de resultados más grande posible
- En sistemas sin soporte nativo, requiere múltiples operaciones (UNION de LEFT y RIGHT JOIN)
Para optimizar el rendimiento:
- Asegúrate de tener índices en las columnas de unión
- Considera filtrar con WHERE después del JOIN si no necesitas todos los registros
- Evalúa si realmente necesitas la funcionalidad completa del FULL JOIN o si LEFT/RIGHT JOIN serían suficientes
El FULL JOIN es una herramienta valiosa para análisis exhaustivos de datos, especialmente cuando necesitamos garantizar que no se pierda información de ninguna de las tablas involucradas.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la función y sintaxis del INNER JOIN para obtener registros coincidentes entre tablas. Aprender a utilizar LEFT JOIN para incluir todos los registros de la tabla izquierda, incluso sin coincidencias. Entender el uso y equivalencia del RIGHT JOIN para incluir todos los registros de la tabla derecha. Conocer el FULL JOIN para combinar todos los registros de ambas tablas, con o sin coincidencias. Aplicar JOINs en consultas reales para análisis de datos, informes y auditorías.