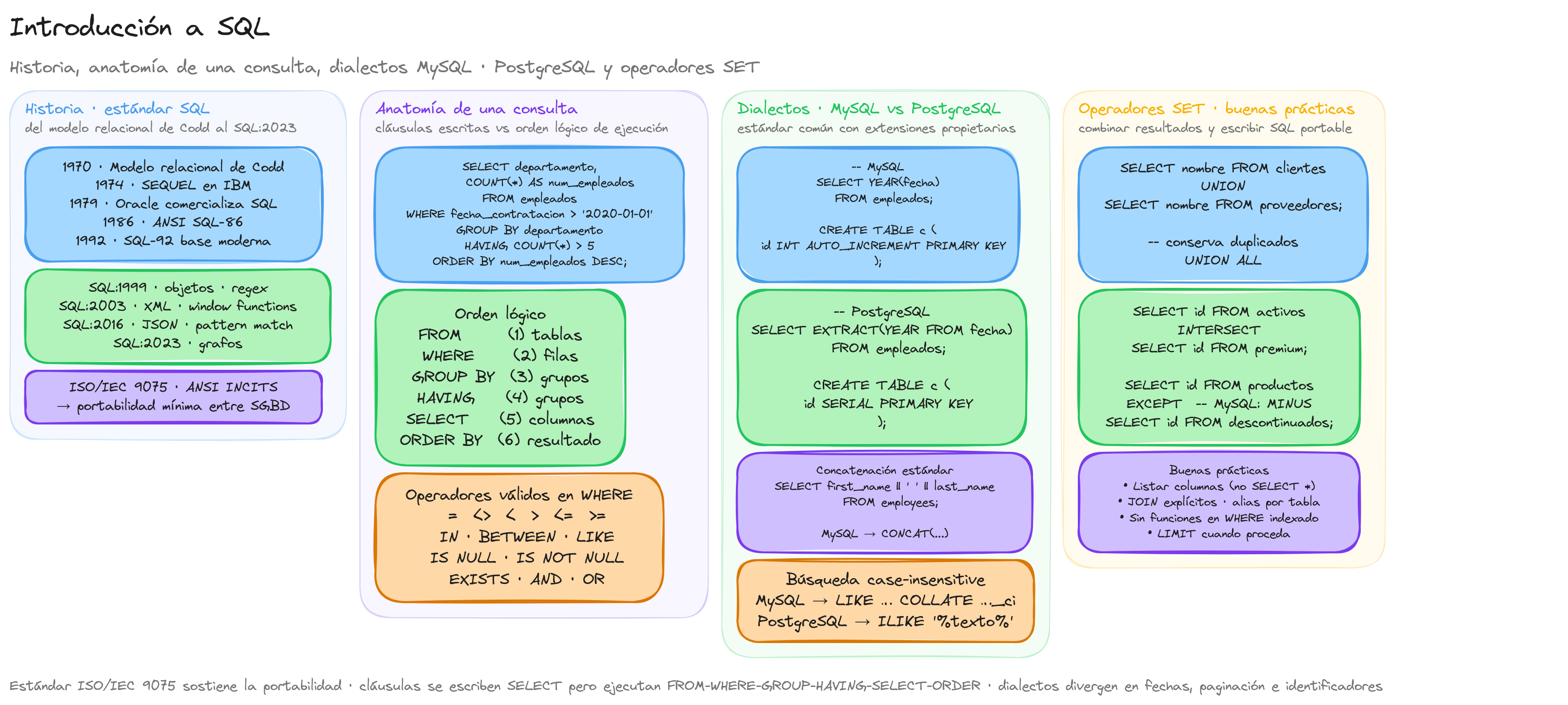
Historia de SQL
El lenguaje SQL (Structured Query Language) tiene sus raíces en la década de 1970, cuando la necesidad de gestionar grandes volúmenes de datos de manera eficiente se convirtió en una prioridad para las organizaciones. Su desarrollo está estrechamente ligado a la evolución de las bases de datos relacionales, un modelo que revolucionó la forma en que almacenamos y accedemos a la información.
Orígenes en IBM
Todo comenzó en 1970 cuando el matemático e informático Edgar F. Codd, mientras trabajaba en IBM, publicó su influyente artículo "A Relational Model of Data for Large Shared Data Banks". Este documento sentó las bases teóricas del modelo relacional, proponiendo que los datos se organizaran en tablas bidimensionales (relaciones) con filas y columnas, conectadas mediante valores comunes.
Basándose en estas ideas, un equipo de IBM liderado por Donald D. Chamberlin y Raymond F. Boyce desarrolló en 1974 un lenguaje llamado SEQUEL (Structured English Query Language). Este primer lenguaje estaba diseñado para manipular y recuperar datos almacenados en System R, el sistema de gestión de bases de datos experimentales de IBM.
-- Ejemplo de sintaxis temprana de SEQUEL (1974)
SELECT EMPNO, LASTNAME, SALARY
FROM EMPLOYEE
WHERE DEPT = 'RESEARCH'
De SEQUEL a SQL
Por cuestiones legales, el nombre SEQUEL tuvo que cambiarse a SQL (Structured Query Language). Durante los años siguientes, IBM continuó refinando el lenguaje mientras desarrollaba System R, el primer sistema que implementó SQL. En 1979, Oracle Corporation (entonces llamada Relational Software, Inc.) se convirtió en la primera empresa en comercializar un sistema de gestión de bases de datos basado en SQL, adelantándose incluso a IBM.
Estandarización
Un hito crucial en la historia de SQL fue su estandarización. En 1986, el American National Standards Institute (ANSI) publicó el primer estándar oficial de SQL, conocido como SQL-86. Dos años después, en 1988, este estándar fue adoptado por la Organización Internacional de Normalización (ISO), consolidando a SQL como el lenguaje estándar para bases de datos relacionales a nivel mundial.
Las principales versiones del estándar SQL han sido:
- SQL-86: Primera versión estandarizada
- SQL-89: Revisión menor con algunas mejoras
- SQL-92: Expansión significativa que añadió numerosas características
- SQL:1999: Introdujo características orientadas a objetos
- SQL:2003: Añadió funciones XML y características para almacenes de datos
- SQL:2008: Incorporó funcionalidades para servicios web
- SQL:2011: Mejoró el soporte para datos temporales
- SQL:2016: Añadió características para JSON y análisis de patrones
- SQL:2023: Última versión con mejoras en funciones de ventana y expresiones de tabla comunes
Popularización y adopción comercial
Durante la década de 1980, SQL experimentó una rápida adopción gracias a su simplicidad conceptual y su capacidad para gestionar datos de manera eficiente. Numerosas empresas desarrollaron sus propios sistemas de gestión de bases de datos relacionales (RDBMS) basados en SQL:
- Oracle Database (1979)
- DB2 de IBM (1983)
- SQL Server de Microsoft (1989)
- PostgreSQL (1989, inicialmente como Postgres)
- MySQL (1995)
Cada uno de estos sistemas implementó el estándar SQL con sus propias extensiones y optimizaciones, dando lugar a los dialectos SQL que conocemos hoy.
La revolución de las bases de datos de código abierto
Un capítulo importante en la historia de SQL fue el surgimiento de sistemas de código abierto en la década de 1990. PostgreSQL, desarrollado originalmente en la Universidad de California en Berkeley, y MySQL, creado por Michael Widenius y David Axmark, democratizaron el acceso a las bases de datos relacionales al ofrecer alternativas gratuitas y de código abierto a los costosos sistemas comerciales.
-- Ejemplo de consulta SQL moderna
SELECT
departments.name AS department,
COUNT(employees.id) AS employee_count,
AVG(employees.salary) AS average_salary
FROM
employees
JOIN
departments ON employees.department_id = departments.id
GROUP BY
departments.name
HAVING
COUNT(employees.id) > 10
ORDER BY
average_salary DESC;
SQL en la era de Internet
Con la explosión de Internet en los años 90 y 2000, SQL se convirtió en la columna vertebral de innumerables aplicaciones web. Las bases de datos relacionales gestionadas con SQL pasaron a almacenar desde información de usuarios y productos en tiendas online hasta contenido de redes sociales y aplicaciones empresariales.
SQL en la actualidad
A pesar del surgimiento de alternativas NoSQL para ciertos casos de uso específicos, SQL ha demostrado una notable resiliencia y capacidad de adaptación. Lejos de volverse obsoleto, SQL ha evolucionado para incorporar características modernas como soporte para datos JSON, análisis espacial, procesamiento de grafos y capacidades analíticas avanzadas.
Hoy, SQL sigue siendo el lenguaje dominante para la gestión de datos estructurados, con millones de desarrolladores y organizaciones que lo utilizan diariamente. Su influencia se extiende incluso a tecnologías NoSQL y Big Data, donde variantes como SparkSQL permiten consultar grandes volúmenes de datos con una sintaxis familiar.
La historia de SQL es un testimonio de cómo un diseño sólido basado en fundamentos matemáticos puede crear una tecnología con décadas de relevancia, capaz de adaptarse a un panorama tecnológico en constante evolución.
Estructura de consultas
Las consultas SQL siguen una estructura lógica que refleja la forma natural en que pensamos sobre los datos. Esta organización permite a los desarrolladores y analistas expresar operaciones complejas sobre bases de datos de manera clara y concisa. Comprender esta estructura es fundamental para dominar el lenguaje SQL.
Anatomía básica de una consulta SQL
Una consulta SQL típica está compuesta por varias cláusulas que se ejecutan en un orden específico. Cada cláusula cumple una función particular dentro de la consulta:
SELECT columna1, columna2
FROM tabla
WHERE condición
GROUP BY columna1
HAVING condición_de_grupo
ORDER BY columna2;
Aunque no todas las cláusulas son obligatorias, esta estructura proporciona un marco consistente para construir consultas desde las más simples hasta las más complejas.
Cláusulas principales y su orden de ejecución
El orden en que escribimos las cláusulas SQL no coincide con el orden en que el motor de base de datos las procesa. Entender esta secuencia de ejecución es crucial para escribir consultas eficientes:
- FROM: Específica la tabla o tablas de donde se obtendrán los datos
- WHERE: Filtra las filas según las condiciones especificadas
- GROUP BY: Agrupa filas que comparten valores en columnas específicas
- HAVING: Filtra grupos según condiciones específicas
- SELECT: Determina qué columnas aparecerán en los resultados
- ORDER BY: Ordena el conjunto de resultados
-- Ejemplo de consulta con múltiples cláusulas
SELECT departamento, COUNT(*) as num_empleados
FROM empleados
WHERE fecha_contratacion > '2020-01-01'
GROUP BY departamento
HAVING COUNT(*) > 5
ORDER BY num_empleados DESC;
Cláusula SELECT
La cláusula SELECT define qué columnas queremos recuperar. Es la única cláusula obligatoria junto con FROM en una consulta básica.
-- Seleccionar columnas específicas
SELECT nombre, apellido, email FROM clientes;
-- Seleccionar todas las columnas
SELECT * FROM productos;
-- Usar alias para renombrar columnas
SELECT
precio * cantidad AS importe_total,
fecha_pedido AS fecha
FROM pedidos;
Es importante señalar que usar SELECT * puede ser conveniente durante el desarrollo, pero en entornos de producción es mejor práctica especificar exactamente las columnas necesarias para mejorar el rendimiento.
Cláusula FROM
La cláusula FROM indica la fuente de los datos. Puede ser una tabla, múltiples tablas unidas, o incluso subconsultas (conocidas como "tablas derivadas").
-- Tabla simple
FROM clientes
-- Múltiples tablas con JOIN
FROM pedidos
JOIN clientes ON pedidos.cliente_id = clientes.id
-- Subconsulta como tabla
FROM (SELECT id, SUM(importe) as total FROM ventas GROUP BY id) AS resumen_ventas
Cláusula WHERE
La cláusula WHERE filtra las filas según condiciones específicas. Funciona como un "filtro horizontal" que reduce el número de filas procesadas.
-- Condición simple
WHERE edad > 18
-- Múltiples condiciones con operadores lógicos
WHERE categoria = 'Electrónica' AND precio < 500
-- Condiciones de rango
WHERE fecha_pedido BETWEEN '2023-01-01' AND '2023-12-31'
-- Búsqueda de patrones
WHERE nombre LIKE 'A%'
Los operadores de comparación más comunes incluyen:
- Igualdad:
=,<>(o!=en algunos dialectos) - Comparación:
<,>,<=,>= - Pertenencia:
IN,NOT IN - Existencia:
EXISTS,NOT EXISTS - Patrones:
LIKE,NOT LIKE - Valores nulos:
IS NULL,IS NOT NULL
Cláusula GROUP BY
La cláusula GROUP BY agrupa filas que comparten valores en una o más columnas, permitiendo realizar cálculos agregados sobre cada grupo.
-- Agrupar ventas por región
SELECT region, SUM(importe) as ventas_totales
FROM ventas
GROUP BY region;
-- Agrupar por múltiples columnas
SELECT categoria, subcategoria, COUNT(*) as num_productos
FROM productos
GROUP BY categoria, subcategoria;
Cláusula HAVING
Mientras que WHERE filtra filas individuales, HAVING filtra grupos creados por GROUP BY. Esta cláusula se aplica después de que los datos han sido agrupados.
-- Filtrar grupos con más de 100 ventas
SELECT producto_id, COUNT(*) as total_ventas
FROM ventas
GROUP BY producto_id
HAVING COUNT(*) > 100;
-- Filtrar por valor agregado
SELECT departamento, AVG(salario) as salario_promedio
FROM empleados
GROUP BY departamento
HAVING AVG(salario) > 50000;
Cláusula ORDER BY
La cláusula ORDER BY ordena los resultados según una o más columnas, en orden ascendente (ASC, predeterminado) o descendente (DESC).
-- Ordenar por una columna en orden ascendente
SELECT nombre, precio FROM productos ORDER BY precio;
-- Ordenar por múltiples columnas
SELECT apellido, nombre FROM clientes ORDER BY apellido, nombre;
-- Ordenar en orden descendente
SELECT producto, ventas FROM estadisticas ORDER BY ventas DESC;
-- Ordenar por posición de columna (menos recomendado)
SELECT nombre, fecha_registro FROM usuarios ORDER BY 2 DESC;
Consultas anidadas y subconsultas
Las subconsultas permiten usar el resultado de una consulta dentro de otra. Pueden aparecer en diferentes partes de la consulta principal:
-- Subconsulta en la cláusula WHERE
SELECT nombre
FROM productos
WHERE categoria_id IN (SELECT id FROM categorias WHERE nombre = 'Electrónica');
-- Subconsulta en la cláusula FROM
SELECT dept_nombre, promedio_salario
FROM (
SELECT departamento_id, AVG(salario) as promedio_salario
FROM empleados
GROUP BY departamento_id
) AS promedios
JOIN departamentos ON promedios.departamento_id = departamentos.id;
-- Subconsulta en la cláusula SELECT
SELECT
nombre,
(SELECT COUNT(*) FROM pedidos WHERE pedidos.cliente_id = clientes.id) AS total_pedidos
FROM clientes;
Operadores SET
Los operadores SET permiten combinar resultados de múltiples consultas:
-- UNION: combina y elimina duplicados
SELECT nombre FROM clientes
UNION
SELECT nombre FROM proveedores;
-- UNION ALL: combina manteniendo duplicados
SELECT producto_id FROM ventas_2022
UNION ALL
SELECT producto_id FROM ventas_2023;
-- INTERSECT: filas que aparecen en ambos conjuntos
SELECT cliente_id FROM clientes_activos
INTERSECT
SELECT cliente_id FROM clientes_premium;
-- EXCEPT/MINUS: filas del primer conjunto que no están en el segundo
SELECT producto_id FROM productos
EXCEPT -- En MySQL se usa MINUS
SELECT producto_id FROM productos_descontinuados;
Estructura de consultas en MySQL y PostgreSQL
Aunque MySQL y PostgreSQL siguen el estándar SQL, existen algunas diferencias en la sintaxis y funcionalidades:
MySQL:
-- Limitación de resultados en MySQL
SELECT nombre, precio FROM productos ORDER BY precio DESC LIMIT 10;
-- Actualización con JOIN en MySQL
UPDATE productos p
JOIN categorias c ON p.categoria_id = c.id
SET p.precio = p.precio * 1.1
WHERE c.nombre = 'Electrónica';
PostgreSQL:
-- Limitación de resultados en PostgreSQL
SELECT nombre, precio FROM productos ORDER BY precio DESC LIMIT 10;
-- Actualización con FROM en PostgreSQL
UPDATE productos p
SET precio = p.precio * 1.1
FROM categorias c
WHERE p.categoria_id = c.id AND c.nombre = 'Electrónica';
Buenas prácticas en la estructura de consultas
Para escribir consultas SQL eficientes y mantenibles:
- Usa indentación consistente para mejorar la legibilidad:
SELECT
c.nombre,
c.apellido,
COUNT(p.id) AS total_pedidos
FROM
clientes c
LEFT JOIN
pedidos p ON c.id = p.cliente_id
WHERE
c.fecha_registro > '2023-01-01'
GROUP BY
c.nombre, c.apellido
HAVING
COUNT(p.id) > 0
ORDER BY
total_pedidos DESC;
- Nombra las columnas explícitamente en lugar de usar
SELECT * - Utiliza alias de tabla para consultas que involucran múltiples tablas
- Prefiere JOIN explícitos sobre la sintaxis de coma en la cláusula FROM
- Evita funciones en la cláusula WHERE que impidan el uso de índices
- Limita el número de filas cuando sea posible con LIMIT o TOP
La estructura de consultas SQL proporciona un marco flexible pero consistente para interactuar con bases de datos relacionales. Dominar esta estructura es el primer paso para escribir consultas eficientes que puedan resolver problemas complejos de manejo de datos.
Estándares y dialectos
El lenguaje SQL, aunque universalmente reconocido, no se implementa de manera idéntica en todos los sistemas de gestión de bases de datos relacionales (SGBDR). Esta realidad da lugar a la distinción entre el estándar SQL oficial y los diversos dialectos SQL que encontramos en la práctica profesional.
El estándar SQL: la base común
El estándar SQL es mantenido conjuntamente por el Instituto Nacional Estadounidense de Estándares (ANSI) y la Organización Internacional de Normalización (ISO). Este estándar define la sintaxis y semántica que todo sistema compatible con SQL debería implementar, estableciendo un lenguaje común para la manipulación de datos relacionales.
La evolución del estándar ha sido gradual, con cada nueva versión añadiendo funcionalidades para adaptarse a las necesidades cambiantes:
- SQL-92 (o SQL2): Estableció las bases sólidas del lenguaje moderno
- SQL:1999: Introdujo características orientadas a objetos y expresiones regulares
- SQL:2003: Añadió soporte para XML y funciones de ventana (window functions)
- SQL:2008: Incorporó la ordenación por collations y mejoras en OLAP
- SQL:2011: Amplió el soporte para datos temporales
- SQL:2016: Integró funcionalidades para JSON y análisis de patrones
Estas especificaciones oficiales garantizan cierto nivel de portabilidad entre sistemas, permitiendo que el conocimiento básico de SQL sea transferible entre diferentes plataformas.
Dialectos SQL: la realidad práctica
En la práctica, cada sistema de gestión de bases de datos implementa su propia variante o dialecto de SQL, que generalmente incluye:
- Un subconjunto del estándar oficial
- Extensiones propietarias que añaden funcionalidades específicas
- Variaciones sintácticas para ciertas operaciones
Los dialectos más relevantes para nuestro curso son:
MySQL
MySQL, ahora propiedad de Oracle, presenta un dialecto con características distintivas:
-- Limitación de resultados (extensión de MySQL)
SELECT nombre, precio FROM productos
ORDER BY precio DESC
LIMIT 10;
-- Uso de comillas invertidas para identificadores
SELECT `id`, `nombre` FROM `clientes`;
-- Funciones específicas de MySQL
SELECT CONCAT_WS(' ', nombre, apellido) AS nombre_completo
FROM empleados;
Particularidades de MySQL:
- Uso de
AUTO_INCREMENTpara columnas de incremento automático - Diversos motores de almacenamiento (InnoDB, MyISAM)
- Sintaxis específica para gestión de índices y particiones
- Funciones de fecha y texto propias
PostgreSQL
PostgreSQL, conocido por su adherencia a estándares y robustez, ofrece:
-- Operador de texto específico para PostgreSQL
SELECT nombre FROM productos
WHERE descripcion ILIKE '%digital%';
-- Tipos de datos específicos
CREATE TABLE geometrias (
id SERIAL PRIMARY KEY,
ubicacion POINT,
region POLYGON
);
-- Funciones de ventana avanzadas
SELECT
departamento,
empleado,
salario,
RANK() OVER (PARTITION BY departamento ORDER BY salario DESC)
FROM empleados;
Características distintivas de PostgreSQL:
- Soporte avanzado para tipos de datos (arrays, JSON, geoespaciales)
- Operadores específicos como
ILIKE(LIKE insensible a mayúsculas/minúsculas) - Secuencias mediante
SERIALoIDENTITY - Herencia de tablas y otras características orientadas a objetos
Diferencias comunes entre dialectos
Algunas áreas donde los dialectos suelen diferir incluyen:
Funciones de cadena
-- Concatenación en estándar SQL
SELECT first_name || ' ' || last_name FROM employees;
-- En MySQL
SELECT CONCAT(first_name, ' ', last_name) FROM employees;
-- En PostgreSQL (soporta ambas formas)
SELECT CONCAT(first_name, ' ', last_name) FROM employees;
SELECT first_name || ' ' || last_name FROM employees;
Funciones de fecha y hora
-- Extraer el año en MySQL
SELECT YEAR(fecha_nacimiento) FROM empleados;
-- En PostgreSQL
SELECT EXTRACT(YEAR FROM fecha_nacimiento) FROM empleados;
Paginación y límites
-- Limitar resultados en MySQL y PostgreSQL
SELECT * FROM productos ORDER BY precio LIMIT 10;
-- En SQL Server
SELECT TOP 10 * FROM productos ORDER BY precio;
-- Paginación en MySQL y PostgreSQL
SELECT * FROM productos ORDER BY id LIMIT 10 OFFSET 20;
-- En SQL Server (versiones más recientes)
SELECT * FROM productos ORDER BY id OFFSET 20 ROWS FETCH NEXT 10 ROWS ONLY;
Valores autoincrementales
-- En MySQL
CREATE TABLE clientes (
id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100)
);
-- En PostgreSQL
CREATE TABLE clientes (
id SERIAL PRIMARY KEY,
nombre VARCHAR(100)
);
Operaciones con cadenas de texto
-- Búsqueda insensible a mayúsculas/minúsculas
-- MySQL
SELECT * FROM productos WHERE nombre LIKE '%tablet%' COLLATE utf8mb4_general_ci;
-- PostgreSQL
SELECT * FROM productos WHERE nombre ILIKE '%tablet%';
Estrategias para manejar las diferencias entre dialectos
Como desarrollador, existen varias estrategias para lidiar con las diferencias entre dialectos:
-
Ceñirse al estándar ANSI SQL cuando sea posible, evitando características específicas de cada dialecto.
-
Usar capas de abstracción como ORMs (Object-Relational Mappers) que manejan las diferencias entre dialectos automáticamente.
-
Implementar código condicional según la base de datos:
# Ejemplo en Python con diferentes dialectos
if database_type == "mysql":
query = "SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM employees"
elif database_type == "postgresql":
query = "SELECT first_name || ' ' || last_name AS full_name FROM employees"
- Documentar las dependencias específicas de cada dialecto en el código.
Compatibilidad y portabilidad
Al desarrollar aplicaciones que podrían necesitar cambiar de sistema de base de datos:
- Identifica las áreas críticas donde los dialectos difieren (funciones de fecha, manejo de texto, paginación)
- Encapsula las consultas específicas del dialecto en funciones o métodos separados
- Prueba regularmente con diferentes sistemas de bases de datos
- Mantén un registro de las características específicas de cada dialecto utilizadas
Herramientas de compatibilidad
Existen herramientas que pueden ayudar a gestionar las diferencias entre dialectos:
- SQLines: Herramienta para convertir SQL entre diferentes dialectos
- Frameworks ORM: Como Hibernate (Java), SQLAlchemy (Python) o Entity Framework (C#)
- Middleware de base de datos: Sistemas que proporcionan una capa de abstracción sobre diferentes bases de datos
Consideraciones para elegir un dialecto
Al seleccionar un sistema de gestión de bases de datos, considera:
- Requisitos funcionales: ¿Necesitas características específicas como soporte geoespacial avanzado?
- Rendimiento: ¿Qué sistema se adapta mejor a tu patrón de carga de trabajo?
- Ecosistema: Herramientas, comunidad y soporte disponibles
- Licenciamiento: Costos y restricciones de uso
- Familiaridad del equipo: La experiencia previa puede reducir la curva de aprendizaje
Tendencias en la estandarización
En los últimos años, hemos visto una tendencia hacia mayor compatibilidad:
- Los sistemas de bases de datos están implementando más partes del estándar SQL
- Las extensiones propietarias útiles tienden a ser adoptadas por otros sistemas
- Las herramientas de abstracción están mejorando su capacidad para manejar diferencias
MySQL y PostgreSQL, en particular, han mejorado significativamente su adherencia al estándar SQL, aunque mantienen sus características distintivas que les dan ventajas en diferentes escenarios de uso.
Recomendaciones prácticas
Para nuestro curso, donde trabajaremos principalmente con MySQL y PostgreSQL:
- Aprende primero la sintaxis estándar cuando esté disponible
- Familiarízate con las particularidades de cada sistema
- Práctica identificando qué partes de una consulta son estándar y cuáles son específicas del dialecto
- Desarrolla el hábito de consultar la documentación oficial cuando tengas dudas sobre compatibilidad
Dominar tanto el estándar SQL como las particularidades de los dialectos más comunes te convertirá en un desarrollador de bases de datos más versátil y efectivo, capaz de adaptarte a diferentes entornos y requisitos técnicos.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender los orígenes y evolución histórica de SQL. Identificar la estructura y cláusulas principales de una consulta SQL. Diferenciar entre el estándar SQL y los dialectos más comunes. Reconocer las particularidades de MySQL y PostgreSQL en la implementación de SQL. Aplicar buenas prácticas para escribir consultas eficientes y portables.