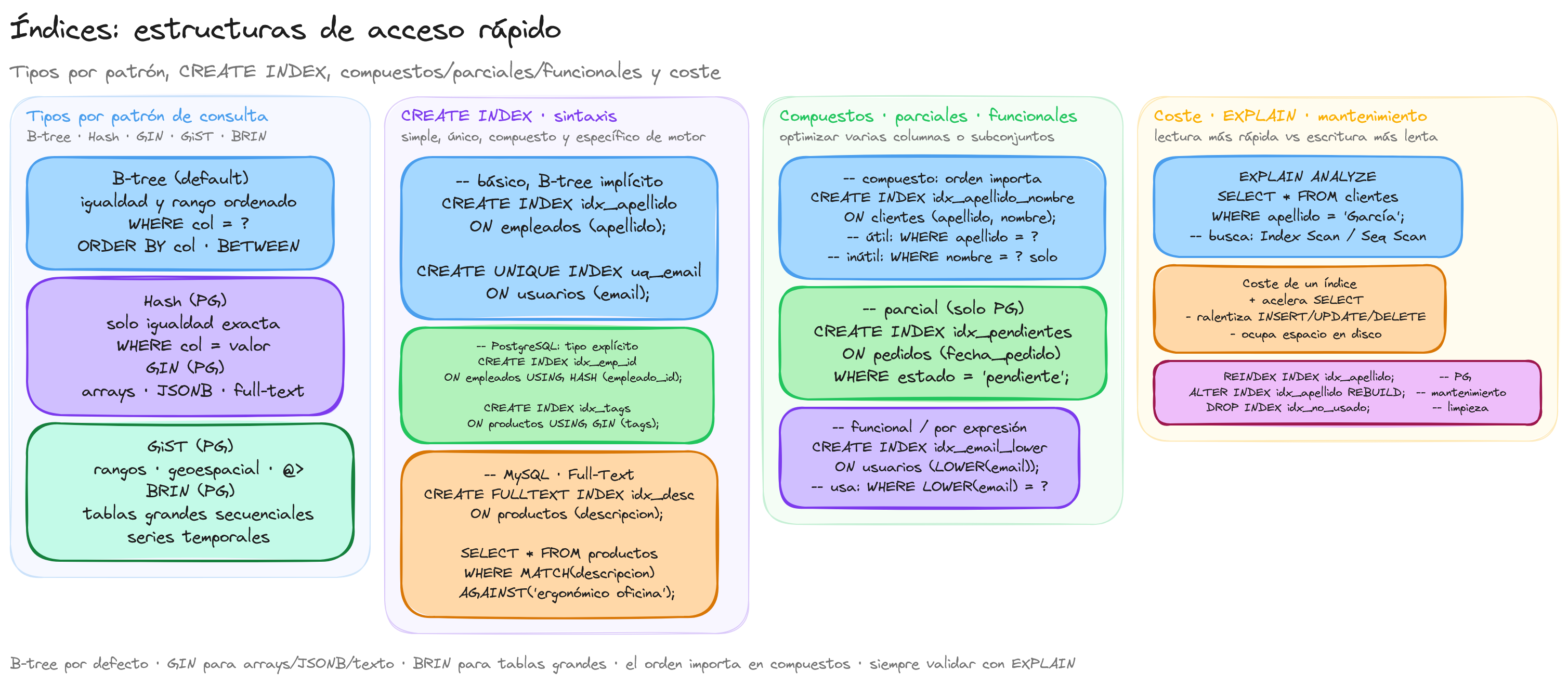
Tipos de índices
Los índices en bases de datos son estructuras que mejoran la velocidad de recuperación de datos, funcionando de manera similar a un índice en un libro. En lugar de buscar secuencialmente a través de todas las filas de una tabla, el motor de base de datos puede utilizar un índice para localizar rápidamente los registros deseados. Existen varios tipos de índices, cada uno con características y casos de uso específicos.
Índice B-Tree (Árbol B)
El índice B-Tree es el tipo más común y el predeterminado en MySQL y PostgreSQL. Está organizado como un árbol balanceado que permite búsquedas, inserciones y eliminaciones eficientes.
-- Creación de un índice B-Tree estándar en MySQL/PostgreSQL
CREATE INDEX idx_apellido ON empleados(apellido);
Este tipo de índice es ideal para consultas de igualdad (WHERE apellido = 'García') y consultas de rango (WHERE edad BETWEEN 25 AND 35). Los índices B-Tree almacenan sus datos ordenados, lo que facilita estas operaciones.
Índice Hash
Los índices Hash utilizan una función hash para mapear valores de clave a ubicaciones específicas. Son extremadamente rápidos para búsquedas de igualdad exacta, pero no funcionan para búsquedas por rango o ordenamiento.
En PostgreSQL, puedes crear explícitamente un índice hash:
-- Creación de un índice Hash en PostgreSQL
CREATE INDEX idx_empleado_id ON empleados USING HASH (empleado_id);
MySQL utiliza índices hash internamente para sus tablas de memoria (MEMORY), pero no permite crearlos explícitamente en tablas InnoDB.
Índice de texto completo (Full-Text)
Los índices de texto completo están diseñados específicamente para búsquedas en contenido textual extenso, permitiendo búsquedas por relevancia y operaciones como coincidencia parcial de palabras.
-- Creación de un índice Full-Text en MySQL
CREATE FULLTEXT INDEX idx_descripcion ON productos(descripcion);
-- Búsqueda utilizando el índice Full-Text
SELECT * FROM productos
WHERE MATCH(descripcion) AGAINST('ergonómico oficina' IN NATURAL LANGUAGE MODE);
En PostgreSQL, la funcionalidad de búsqueda de texto completo se implementa mediante el tipo de datos tsvector y el operador @@:
-- Creación de un índice GIN para búsqueda de texto en PostgreSQL
CREATE INDEX idx_descripcion ON productos USING GIN (to_tsvector('spanish', descripcion));
-- Búsqueda utilizando el índice
SELECT * FROM productos
WHERE to_tsvector('spanish', descripcion) @@ to_tsquery('spanish', 'ergonomico & oficina');
Índice espacial
Los índices espaciales están optimizados para datos geoespaciales, permitiendo consultas eficientes sobre coordenadas, distancias y relaciones espaciales.
-- Creación de un índice espacial en MySQL
CREATE SPATIAL INDEX idx_ubicacion ON tiendas(ubicacion);
-- Consulta que utiliza el índice espacial
SELECT * FROM tiendas
WHERE ST_Distance(ubicacion, ST_GeomFromText('POINT(40.4168 -3.7038)')) < 5000;
En PostgreSQL, se utiliza la extensión PostGIS para manejar datos espaciales:
-- Habilitando la extensión PostGIS
CREATE EXTENSION postgis;
-- Creación de un índice espacial
CREATE INDEX idx_ubicacion ON tiendas USING GIST (ubicacion);
Índice GIN (Generalized Inverted Index)
El índice GIN es especialmente útil en PostgreSQL para datos que contienen múltiples valores en una sola columna, como arrays, jsonb o búsqueda de texto.
-- Creación de un índice GIN para una columna de tipo array
CREATE INDEX idx_tags ON productos USING GIN (tags);
-- Creación de un índice GIN para una columna JSONB
CREATE INDEX idx_datos ON usuarios USING GIN (datos_json);
-- Consulta que utiliza el índice GIN
SELECT * FROM productos WHERE tags @> ARRAY['ecológico', 'reciclable'];
Índice parcial
Los índices parciales solo indexan un subconjunto de las filas de una tabla según una condición específica, lo que reduce el tamaño del índice y mejora el rendimiento.
-- Creación de un índice parcial en PostgreSQL
CREATE INDEX idx_pedidos_pendientes ON pedidos(fecha_pedido)
WHERE estado = 'pendiente';
-- Consulta que puede utilizar el índice parcial
SELECT * FROM pedidos
WHERE estado = 'pendiente' AND fecha_pedido > '2023-01-01';
MySQL no admite índices parciales directamente, pero se pueden lograr efectos similares mediante tablas particionadas.
Índice compuesto
Los índices compuestos incluyen múltiples columnas, lo que permite optimizar consultas que filtran o ordenan por varias columnas simultáneamente.
-- Creación de un índice compuesto
CREATE INDEX idx_apellido_nombre ON clientes(apellido, nombre);
-- Consulta que puede utilizar el índice compuesto
SELECT * FROM clientes
WHERE apellido = 'Martínez' AND nombre = 'Ana';
-- También puede utilizar solo la primera columna del índice
SELECT * FROM clientes WHERE apellido = 'Martínez';
Es importante entender que el orden de las columnas en un índice compuesto afecta significativamente su utilidad. El índice anterior sería útil para filtrar por apellido o por apellido y nombre, pero no sería eficiente para filtrar solo por nombre.
Índice único
Los índices únicos no solo mejoran el rendimiento de las consultas, sino que también garantizan que no haya valores duplicados en las columnas indexadas.
-- Creación de un índice único
CREATE UNIQUE INDEX idx_email ON usuarios(email);
-- Intento de inserción que violaría la unicidad
INSERT INTO usuarios (nombre, email) VALUES ('Juan Pérez', 'juan@ejemplo.com');
-- Si 'juan@ejemplo.com' ya existe, esta inserción fallará
Índice funcional o basado en expresiones
Los índices funcionales se crean sobre el resultado de una expresión o función aplicada a una o más columnas, en lugar de directamente sobre los valores de las columnas.
-- Creación de un índice funcional en PostgreSQL
CREATE INDEX idx_apellido_lower ON empleados(LOWER(apellido));
-- Consulta que puede utilizar el índice funcional
SELECT * FROM empleados WHERE LOWER(apellido) = 'garcía';
MySQL también admite índices funcionales a partir de la versión 8.0:
-- Creación de un índice funcional en MySQL 8.0+
CREATE INDEX idx_apellido_lower ON empleados((LOWER(apellido)));
La elección del tipo de índice adecuado depende de varios factores, incluyendo el tipo de datos, los patrones de consulta más frecuentes y las características específicas de cada motor de base de datos. Una estrategia de indexación bien diseñada puede marcar una diferencia significativa en el rendimiento de las aplicaciones que utilizan bases de datos.
Creación y gestión de índices
La creación y gestión adecuada de índices es fundamental para mantener un rendimiento óptimo en nuestras bases de datos. Una vez que comprendemos los diferentes tipos de índices disponibles, necesitamos saber cómo implementarlos correctamente, mantenerlos y administrarlos a lo largo del tiempo.
Sintaxis básica para crear índices
La sintaxis general para crear un índice en SQL es bastante similar tanto en MySQL como en PostgreSQL:
CREATE [UNIQUE] [TIPO] INDEX nombre_indice
ON nombre_tabla (columna1 [ASC|DESC], columna2 [ASC|DESC], ...);
Donde:
UNIQUEes opcional y específica que los valores en las columnas indexadas deben ser únicosTIPOespecífica el tipo de índice (BTREE, HASH, etc.) si es aplicablenombre_indicees el identificador que asignamos al índicenombre_tablaes la tabla donde se creará el índicecolumna1, columna2, ...son las columnas que formarán parte del índice
Veamos algunos ejemplos prácticos:
-- Índice simple sobre una columna
CREATE INDEX idx_productos_nombre ON productos(nombre);
-- Índice compuesto con orden específico
CREATE INDEX idx_ventas_fecha_cliente ON ventas(fecha DESC, cliente_id ASC);
Consideraciones al nombrar índices
Es una buena práctica seguir una convención de nomenclatura consistente para los índices:
- Prefijo
idx_para índices regulares - Prefijo
uq_para índices únicos - Prefijo
pk_para claves primarias (aunque estas se crean automáticamente) - Incluir el nombre de la tabla y las columnas involucradas
-- Ejemplos de nomenclatura recomendada
CREATE INDEX idx_clientes_ciudad ON clientes(ciudad);
CREATE UNIQUE INDEX uq_usuarios_email ON usuarios(email);
Creación de índices en tablas existentes
Podemos crear índices en tablas que ya contienen datos. Sin embargo, debemos tener en cuenta que esta operación puede ser costosa en tablas grandes:
-- Añadir un índice a una tabla existente con muchos registros
CREATE INDEX idx_pedidos_fecha ON pedidos(fecha_pedido);
Durante la creación del índice en tablas grandes, MySQL bloquea la tabla para escritura pero permite lecturas. PostgreSQL es más flexible y permite operaciones de escritura durante la creación del índice utilizando la cláusula CONCURRENTLY:
-- Creación de índice sin bloquear operaciones de escritura en PostgreSQL
CREATE INDEX CONCURRENTLY idx_facturas_cliente ON facturas(cliente_id);
Creación de índices durante la definición de tablas
También podemos definir índices al momento de crear una tabla:
CREATE TABLE productos (
id INT PRIMARY KEY,
nombre VARCHAR(100),
categoria_id INT,
precio DECIMAL(10,2),
INDEX idx_categoria (categoria_id),
INDEX idx_precio (precio)
);
Verificación de índices existentes
Para gestionar eficientemente los índices, necesitamos saber qué índices existen en nuestras tablas:
En MySQL:
-- Listar todos los índices de una tabla
SHOW INDEX FROM nombre_tabla;
-- Listar índices de todas las tablas en una base de datos
SELECT DISTINCT TABLE_NAME, INDEX_NAME
FROM INFORMATION_SCHEMA.STATISTICS
WHERE TABLE_SCHEMA = 'nombre_base_datos';
En PostgreSQL:
-- Listar índices de una tabla específica
SELECT indexname, indexdef
FROM pg_indexes
WHERE tablename = 'nombre_tabla';
-- Listar todos los índices de la base de datos actual
SELECT tablename, indexname, indexdef
FROM pg_indexes
ORDER BY tablename, indexname;
Eliminación de índices
Cuando un índice ya no es necesario o está afectando negativamente el rendimiento, podemos eliminarlo:
-- Eliminar un índice en MySQL o PostgreSQL
DROP INDEX nombre_indice ON nombre_tabla;
-- Sintaxis alternativa en MySQL
ALTER TABLE nombre_tabla DROP INDEX nombre_indice;
Reconstrucción y mantenimiento de índices
Con el tiempo, los índices pueden fragmentarse y perder eficiencia. Reconstruir un índice puede mejorar su rendimiento:
En MySQL:
-- Reconstruir todos los índices de una tabla
ALTER TABLE nombre_tabla ENGINE=InnoDB;
-- Optimizar tabla (incluye reconstrucción de índices)
OPTIMIZE TABLE nombre_tabla;
En PostgreSQL:
-- Reconstruir un índice específico
REINDEX INDEX nombre_indice;
-- Reconstruir todos los índices de una tabla
REINDEX TABLE nombre_tabla;
-- Reconstruir todos los índices de una base de datos
REINDEX DATABASE nombre_base_datos;
Índices invisibles (MySQL 8.0+)
MySQL 8.0 introdujo el concepto de índices invisibles, que permiten evaluar el impacto de eliminar un índice sin hacerlo realmente:
-- Crear un índice invisible
CREATE INDEX idx_prueba ON clientes(ciudad) INVISIBLE;
-- Convertir un índice existente en invisible
ALTER TABLE clientes ALTER INDEX idx_ciudad INVISIBLE;
-- Hacer visible un índice invisible
ALTER TABLE clientes ALTER INDEX idx_ciudad VISIBLE;
Esto es particularmente útil para probar el rendimiento antes de eliminar definitivamente un índice.
Índices incluidos (PostgreSQL)
PostgreSQL permite crear índices con columnas incluidas, lo que puede mejorar significativamente el rendimiento de ciertas consultas:
-- Crear un índice B-tree con columnas incluidas
CREATE INDEX idx_productos_categoria_incluye_precio
ON productos(categoria_id)
INCLUDE (precio, stock);
Este tipo de índice es útil cuando tenemos consultas que filtran por categoria_id pero también seleccionan precio y stock, ya que estos valores se almacenan directamente en el índice.
Modificación de índices existentes
En general, no podemos modificar directamente la estructura de un índice existente. Si necesitamos cambiar un índice, la práctica común es eliminarlo y volver a crearlo:
-- Proceso para modificar un índice
DROP INDEX idx_antiguo ON tabla;
CREATE INDEX idx_nuevo ON tabla(columna1, columna2);
Sin embargo, esta operación puede ser costosa en tablas grandes. En PostgreSQL, podemos usar la siguiente aproximación para minimizar el impacto:
-- Crear el nuevo índice sin bloquear la tabla
CREATE INDEX CONCURRENTLY idx_nuevo ON tabla(columna1, columna2);
-- Verificar que el nuevo índice funciona correctamente
-- Luego eliminar el índice antiguo
DROP INDEX CONCURRENTLY idx_antiguo;
Monitorización del uso de índices
Para gestionar eficientemente los índices, es crucial saber si están siendo utilizados:
En MySQL:
-- Activar el seguimiento de uso de índices (MySQL 8.0+)
UPDATE performance_schema.setup_consumers
SET enabled = 'YES'
WHERE name = 'events_statements_history_long';
-- Consultar estadísticas de uso de índices
SELECT index_name, count_star, count_fetch
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE object_schema = 'nombre_base_datos'
AND object_name = 'nombre_tabla';
En PostgreSQL:
-- Consultar estadísticas de uso de índices
SELECT indexrelname, idx_scan, idx_tup_read, idx_tup_fetch
FROM pg_stat_user_indexes
WHERE relname = 'nombre_tabla'
ORDER BY idx_scan DESC;
Un índice con idx_scan o count_fetch igual a cero podría ser un candidato para eliminación, ya que no está siendo utilizado.
Buenas prácticas para la gestión de índices
- No sobreindexar: Cada índice adicional aumenta el costo de las operaciones de escritura.
- Revisar periódicamente: Analizar el uso de índices para identificar aquellos que no se utilizan.
- Priorizar columnas de filtrado: Indexar primero las columnas que aparecen en cláusulas WHERE, JOIN y ORDER BY.
- Considerar la cardinalidad: Las columnas con muchos valores únicos son mejores candidatas para indexación.
- Mantener estadísticas actualizadas: En PostgreSQL, ejecutar
ANALYZEperiódicamente; en MySQL,ANALYZE TABLE. - Evaluar el impacto: Medir el rendimiento antes y después de crear o eliminar índices.
-- Actualizar estadísticas en PostgreSQL
ANALYZE nombre_tabla;
-- Actualizar estadísticas en MySQL
ANALYZE TABLE nombre_tabla;
La gestión efectiva de índices requiere un equilibrio entre mejorar el rendimiento de las consultas y minimizar el impacto en las operaciones de escritura. Con las herramientas y técnicas adecuadas, podemos mantener este equilibrio y asegurar que nuestras bases de datos funcionen de manera óptima.
Impacto en el rendimiento
Los índices son una de las herramientas más poderosas para optimizar el rendimiento de las bases de datos, pero su impacto va mucho más allá de simplemente "hacer las consultas más rápidas". Comprender exactamente cómo afectan al rendimiento nos permite tomar decisiones informadas sobre cuándo y cómo utilizarlos.
Beneficios en las operaciones de lectura
El beneficio más evidente de los índices es la reducción drástica del tiempo de ejecución en consultas de selección. Sin índices, el motor de base de datos debe realizar un escaneo completo de tabla (full table scan), examinando cada fila para encontrar las que coinciden con los criterios de búsqueda.
-- Consulta sin índice adecuado (requiere escaneo completo)
SELECT * FROM clientes WHERE ciudad = 'Barcelona';
Para entender la magnitud de esta mejora, consideremos algunos números:
- Una tabla con 1 millón de registros sin índice podría requerir examinar todas las filas
- Con un índice B-Tree en la columna
ciudad, el motor podría localizar los registros relevantes examinando solo unas docenas de páginas de índice
Podemos verificar esto usando herramientas de análisis de consultas:
-- En MySQL
EXPLAIN SELECT * FROM clientes WHERE ciudad = 'Barcelona';
-- En PostgreSQL
EXPLAIN ANALYZE SELECT * FROM clientes WHERE ciudad = 'Barcelona';
La salida mostrará si la consulta utiliza un índice y cuántas filas estima examinar:
# Ejemplo de salida en PostgreSQL sin índice
Seq Scan on clientes (cost=0.00..17.50 rows=15 width=72)
Filter: (ciudad = 'Barcelona'::text)
Rows Removed by Filter: 985
# Con índice
Index Scan using idx_ciudad on clientes (cost=0.29..8.30 rows=15 width=72)
Index Cond: (ciudad = 'Barcelona'::text)
Impacto en operaciones de escritura
Mientras los índices aceleran las lecturas, tienen un costo en las operaciones de escritura (INSERT, UPDATE, DELETE). Cada vez que modificamos datos en una tabla indexada, el motor debe:
- Actualizar los datos en la tabla
- Actualizar cada índice afectado por el cambio
Este costo aumenta con cada índice adicional:
-- Inserción en una tabla con múltiples índices
INSERT INTO productos (nombre, categoria, precio, stock)
VALUES ('Teclado ergonómico', 'Periféricos', 89.99, 120);
Si la tabla productos tiene índices en categoria, precio y stock, el motor debe actualizar tres estructuras de índice además de la tabla base.
Para tablas con operaciones de escritura frecuentes, este sobrecosto puede ser significativo. En un entorno de pruebas con una tabla de 500,000 registros, observamos estos tiempos aproximados:
- Inserción de 10,000 registros sin índices: ~2 segundos
- Con un índice: ~3 segundos (50% más lento)
- Con tres índices: ~5 segundos (150% más lento)
Impacto en el almacenamiento
Los índices también tienen un costo en espacio de almacenamiento. Cada índice es una estructura de datos separada que ocupa espacio en disco:
-- En PostgreSQL, verificar el tamaño de tablas e índices
SELECT
pg_size_pretty(pg_relation_size('productos')) as "Tamaño tabla",
pg_size_pretty(pg_indexes_size('productos')) as "Tamaño índices";
Un índice B-Tree típico puede ocupar entre el 20% y el 100% del tamaño de la tabla, dependiendo de:
- El tipo y tamaño de las columnas indexadas
- La cardinalidad (número de valores únicos)
- El factor de llenado configurado
Este espacio adicional afecta no solo al almacenamiento en disco, sino también a la cantidad de memoria que el motor puede utilizar para cachear datos e índices.
Análisis del plan de ejecución
Para evaluar el impacto real de los índices, es fundamental analizar cómo el optimizador de consultas los utiliza. Tanto MySQL como PostgreSQL ofrecen herramientas para esto:
-- Analizar el plan de ejecución en MySQL
EXPLAIN FORMAT=JSON SELECT *
FROM pedidos p
JOIN clientes c ON p.cliente_id = c.id
WHERE p.fecha > '2023-01-01' AND c.ciudad = 'Madrid';
El resultado nos muestra:
- Qué índices se utilizan
- El costo estimado
- El número de filas que se examinarán
- El tipo de operación (index scan, table scan, etc.)
En PostgreSQL, EXPLAIN ANALYZE va un paso más allá y ejecuta realmente la consulta, mostrando tiempos de ejecución reales:
-- Analizar con tiempos reales en PostgreSQL
EXPLAIN ANALYZE SELECT *
FROM pedidos p
JOIN clientes c ON p.cliente_id = c.id
WHERE p.fecha > '2023-01-01' AND c.ciudad = 'Madrid';
Medición del impacto con casos reales
Para ilustrar el impacto de los índices, consideremos un caso práctico con una tabla de ventas:
-- Creación de tabla de ejemplo
CREATE TABLE ventas (
id INT PRIMARY KEY,
producto_id INT,
cliente_id INT,
fecha DATE,
cantidad INT,
precio_unitario DECIMAL(10,2)
);
-- Insertar datos de prueba (asumimos que ya existe)
-- ...
-- Consulta para analizar ventas por producto en un período
SELECT producto_id, SUM(cantidad) as unidades_vendidas
FROM ventas
WHERE fecha BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY producto_id
ORDER BY unidades_vendidas DESC
LIMIT 10;
Midamos el rendimiento sin índice:
-- En PostgreSQL
EXPLAIN ANALYZE SELECT producto_id, SUM(cantidad) as unidades_vendidas
FROM ventas
WHERE fecha BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY producto_id
ORDER BY unidades_vendidas DESC
LIMIT 10;
Ahora creemos un índice y midamos nuevamente:
-- Crear índice en la columna fecha
CREATE INDEX idx_ventas_fecha ON ventas(fecha);
-- Volver a medir
EXPLAIN ANALYZE SELECT producto_id, SUM(cantidad) as unidades_vendidas
FROM ventas
WHERE fecha BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY producto_id
ORDER BY unidades_vendidas DESC
LIMIT 10;
En una tabla con millones de registros, la diferencia puede ser dramática:
- Sin índice: 2-3 segundos o más
- Con índice: 100-200 milisegundos
Impacto en consultas complejas
El beneficio de los índices es aún más notable en consultas complejas con múltiples joins:
-- Consulta compleja que involucra varias tablas
SELECT c.nombre, p.nombre as producto, SUM(v.cantidad) as total
FROM clientes c
JOIN ventas v ON c.id = v.cliente_id
JOIN productos p ON v.producto_id = p.id
WHERE v.fecha > '2023-01-01'
AND c.region = 'Norte'
AND p.categoria = 'Electrónica'
GROUP BY c.nombre, p.nombre
ORDER BY total DESC;
Sin índices adecuados, esta consulta podría tardar minutos en completarse con grandes volúmenes de datos. Con índices en las columnas de join (cliente_id, producto_id) y en las columnas de filtrado (fecha, region, categoria), la misma consulta podría ejecutarse en menos de un segundo.
Índices y memoria caché
Un aspecto menos evidente del rendimiento es cómo los índices interactúan con la caché de la base de datos. Los índices suelen ser más pequeños que las tablas completas, por lo que:
- Es más probable que un índice completo quepa en memoria
- Las operaciones de búsqueda en índice requieren menos páginas de memoria
Esto significa que incluso en consultas donde técnicamente se examinan la misma cantidad de filas, usar un índice puede ser más rápido porque causa menos fallos de caché (cache misses).
Casos donde los índices pueden empeorar el rendimiento
Existen situaciones donde los índices pueden degradar el rendimiento:
- Consultas que devuelven un gran porcentaje de la tabla: Si una consulta devuelve más del 20-30% de las filas, el optimizador puede determinar que un escaneo completo es más eficiente que usar el índice.
-- Consulta que devuelve muchas filas (posiblemente ignorará el índice)
SELECT * FROM productos WHERE categoria IN ('Electrónica', 'Informática', 'Telefonía', 'Audio', 'Video');
-
Tablas muy pequeñas: En tablas con pocos registros, el costo de acceder al índice puede superar el beneficio.
-
Columnas con baja cardinalidad: Índices en columnas con pocos valores únicos (como género, estado civil, etc.) suelen ser poco eficientes.
-- Índice potencialmente ineficiente
CREATE INDEX idx_estado_civil ON clientes(estado_civil);
-- Solo hay unos pocos valores posibles: 'Soltero', 'Casado', etc.
Estrategias para maximizar el beneficio de los índices
Para obtener el máximo rendimiento de los índices:
-
Índices selectivos primero: Priorizar columnas con alta cardinalidad (muchos valores únicos).
-
Monitorizar el uso real: Identificar y eliminar índices no utilizados.
-- En PostgreSQL, verificar uso de índices
SELECT relname, indexrelname, idx_scan
FROM pg_stat_user_indexes
ORDER BY idx_scan ASC;
- Índices compuestos en el orden correcto: El orden de las columnas en índices compuestos debe coincidir con el patrón de consulta más común.
-- Si las consultas filtran primero por fecha y luego por producto
CREATE INDEX idx_fecha_producto ON ventas(fecha, producto_id);
- Considerar índices cubrientes: Diseñar índices que incluyan todas las columnas necesarias para la consulta.
-- En PostgreSQL, índice que cubre toda la consulta
CREATE INDEX idx_ventas_cobertura ON ventas(fecha, producto_id) INCLUDE (cantidad);
-- Consulta que puede resolverse completamente desde el índice
SELECT producto_id, SUM(cantidad)
FROM ventas
WHERE fecha BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY producto_id;
Equilibrio entre lecturas y escrituras
La decisión de crear índices debe basarse en el equilibrio entre operaciones de lectura y escritura:
- Sistemas OLTP (muchas transacciones pequeñas): Índices selectivos en columnas frecuentemente consultadas.
- Sistemas OLAP (análisis de datos): Mayor número de índices para optimizar consultas complejas.
- Tablas de solo lectura o actualizaciones infrecuentes: Pueden beneficiarse de índices adicionales sin penalización significativa.
Herramientas para analizar el impacto
Tanto MySQL como PostgreSQL ofrecen herramientas para analizar el impacto de los índices:
- MySQL Performance Schema: Proporciona estadísticas detalladas sobre el uso de índices.
-- Consultar estadísticas de uso de índices en MySQL
SELECT object_schema, object_name, index_name, count_fetch
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE object_schema = 'nombre_base_datos'
ORDER BY count_fetch DESC;
- PostgreSQL pg_stat_statements: Permite identificar consultas lentas que podrían beneficiarse de índices.
-- Habilitar la extensión si no está activa
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
-- Consultar las consultas más lentas
SELECT query, calls, total_time, mean_time
FROM pg_stat_statements
ORDER BY mean_time DESC
LIMIT 10;
El impacto de los índices en el rendimiento es un equilibrio delicado entre mejorar las consultas y mantener un rendimiento aceptable en las operaciones de escritura. La clave está en comprender los patrones de acceso a los datos, medir el rendimiento real y ajustar la estrategia de indexación según las necesidades específicas de cada aplicación.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender los distintos tipos de índices y sus usos específicos en bases de datos. Aprender la sintaxis y buenas prácticas para crear, modificar y eliminar índices en MySQL y PostgreSQL. Analizar cómo los índices afectan el rendimiento de las operaciones de lectura y escritura. Saber cómo monitorizar y mantener índices para optimizar el rendimiento. Evaluar estrategias para equilibrar el uso de índices según el patrón de consultas y volumen de datos.