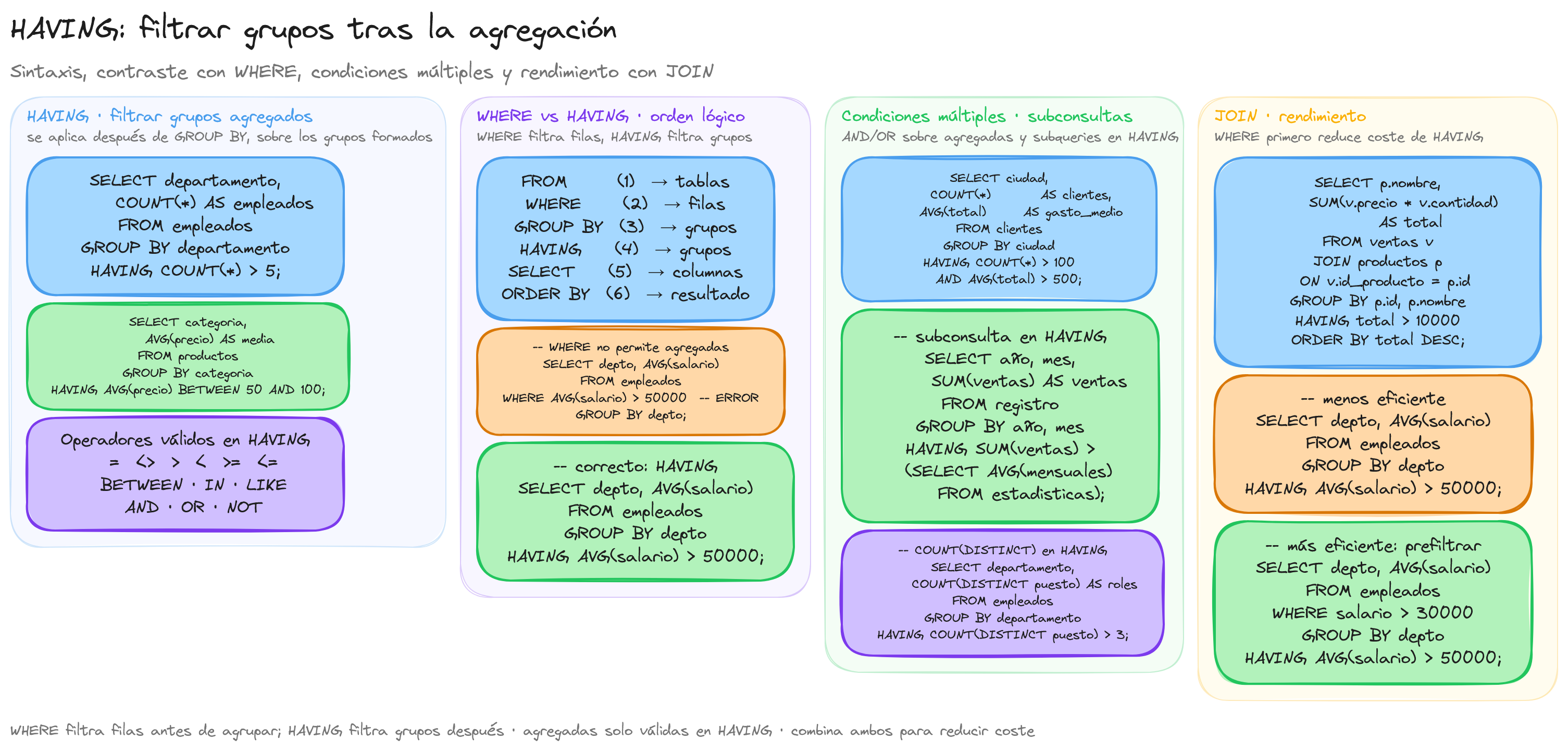
Filtrado de grupos
Cuando trabajamos con datos agrupados en SQL, a menudo necesitamos aplicar condiciones específicas a estos grupos para obtener resultados más precisos. La cláusula HAVING nos permite filtrar grupos de resultados después de que han sido creados mediante GROUP BY, algo que no podemos lograr con WHERE.
El filtrado de grupos es una técnica fundamental cuando analizamos datos agregados. Mientras que WHERE filtra filas individuales antes de cualquier agrupación, HAVING se aplica después de que los datos han sido agrupados y las funciones de agregación calculadas.
Sintaxis básica
La sintaxis para filtrar grupos con HAVING es:
SELECT columna1, función_agregación(columna2)
FROM tabla
GROUP BY columna1
HAVING condición_sobre_grupos;
La condición en HAVING normalmente involucra el resultado de una función de agregación como COUNT, SUM, AVG, MAX o MIN.
Ejemplos prácticos
Veamos algunos ejemplos para entender mejor cómo funciona el filtrado de grupos:
Ejemplo 1: Encontrar departamentos con más de 5 empleados
SELECT departamento, COUNT(*) AS num_empleados
FROM empleados
GROUP BY departamento
HAVING COUNT(*) > 5;
Este ejemplo agrupa a los empleados por departamento y luego filtra solo aquellos departamentos que tienen más de 5 empleados.
Ejemplo 2: Identificar productos con ventas totales superiores a $10,000
SELECT id_producto, nombre_producto, SUM(precio * cantidad) AS ventas_totales
FROM ventas
JOIN productos ON ventas.id_producto = productos.id
GROUP BY id_producto, nombre_producto
HAVING SUM(precio * cantidad) > 10000
ORDER BY ventas_totales DESC;
Aquí estamos filtrando grupos de productos cuyas ventas totales superan los $10,000.
Operadores de comparación en HAVING
Podemos utilizar todos los operadores de comparación estándar en la cláusula HAVING:
- Igualdad:
= - Desigualdad:
<>o!= - Mayor que:
> - Menor que:
< - Mayor o igual que:
>= - Menor o igual que:
<=
Ejemplo: Encontrar categorías de productos con un precio promedio entre $50 y $100
SELECT categoria, AVG(precio) AS precio_promedio
FROM productos
GROUP BY categoria
HAVING AVG(precio) BETWEEN 50 AND 100;
Condiciones múltiples
También podemos combinar múltiples condiciones en HAVING usando operadores lógicos como AND y OR:
SELECT ciudad, COUNT(*) AS num_clientes, AVG(total_compras) AS promedio_compras
FROM clientes
GROUP BY ciudad
HAVING COUNT(*) > 100 AND AVG(total_compras) > 500;
Este ejemplo muestra ciudades que tienen más de 100 clientes y donde el promedio de compras por cliente supera los $500.
Filtrado con expresiones calculadas
HAVING permite filtrar basándose en expresiones calculadas que involucran funciones de agregación:
SELECT año, mes, SUM(ventas) AS ventas_totales
FROM registro_ventas
GROUP BY año, mes
HAVING SUM(ventas) > (SELECT AVG(ventas_mensuales) FROM estadisticas_anuales);
Este ejemplo filtra para mostrar solo los meses cuyas ventas totales superan el promedio mensual de ventas registrado en otra tabla.
Uso con DISTINCT
Podemos combinar HAVING con DISTINCT para filtrar grupos basados en valores únicos:
SELECT departamento, COUNT(DISTINCT puesto) AS puestos_diferentes
FROM empleados
GROUP BY departamento
HAVING COUNT(DISTINCT puesto) > 3;
Este ejemplo muestra departamentos que tienen más de 3 puestos de trabajo diferentes.
Consideraciones de rendimiento
Al filtrar grupos, es importante considerar el rendimiento de nuestras consultas:
- HAVING procesa datos después de la agrupación, lo que puede ser costoso en términos de recursos si los grupos son numerosos.
- Para conjuntos de datos grandes, es recomendable usar WHERE para filtrar filas innecesarias antes de agruparlas.
- Los índices en las columnas utilizadas en GROUP BY pueden mejorar significativamente el rendimiento.
-- Menos eficiente
SELECT departamento, AVG(salario) AS salario_promedio
FROM empleados
GROUP BY departamento
HAVING AVG(salario) > 50000;
-- Más eficiente si muchos salarios son menores a 30000
SELECT departamento, AVG(salario) AS salario_promedio
FROM empleados
WHERE salario > 30000 -- Filtro previo para reducir filas
GROUP BY departamento
HAVING AVG(salario) > 50000;
En el segundo ejemplo, filtramos primero con WHERE para eliminar salarios bajos que probablemente no contribuirían a grupos que cumplan la condición HAVING, mejorando así el rendimiento.
Casos de uso comunes
El filtrado de grupos es especialmente útil en varios escenarios analíticos:
- Análisis de ventas: Identificar productos, regiones o períodos con ventas por encima o debajo de ciertos umbrales.
- Gestión de recursos humanos: Encontrar departamentos con alta rotación de personal o salarios atípicos.
- Control de calidad: Detectar lotes de producción con tasas de defectos superiores al promedio.
- Análisis de comportamiento de usuarios: Identificar segmentos de usuarios con patrones de uso específicos.
-- Encontrar categorías de productos con alta variabilidad de precios
SELECT categoria,
COUNT(*) AS num_productos,
MAX(precio) - MIN(precio) AS rango_precio
FROM productos
GROUP BY categoria
HAVING (MAX(precio) - MIN(precio)) > 1000 AND COUNT(*) > 5;
Este ejemplo identifica categorías de productos que tienen una amplia variación de precios (más de $1,000 entre el producto más caro y el más barato) y que contienen más de 5 productos.
WHERE vs HAVING
Cuando trabajamos con consultas SQL, es fundamental entender la diferencia entre las cláusulas WHERE y HAVING, ya que ambas permiten filtrar datos pero operan en momentos diferentes del procesamiento de la consulta y sobre distintos tipos de datos.
La principal diferencia radica en que WHERE filtra filas individuales antes de cualquier agrupación, mientras que HAVING filtra grupos de filas después de que se ha aplicado la agrupación. Esta distinción es crucial para construir consultas eficientes y obtener los resultados esperados.
Momento de ejecución en el procesamiento de consultas
El orden de ejecución de una consulta SQL típica es:
- FROM: Selección de tablas
- WHERE: Filtrado de filas
- GROUP BY: Agrupación de filas
- HAVING: Filtrado de grupos
- SELECT: Selección de columnas
- ORDER BY: Ordenamiento de resultados
Este orden explica por qué WHERE no puede utilizar funciones de agregación en sus condiciones, mientras que HAVING sí puede hacerlo.
Comparación de sintaxis
-- Filtrado con WHERE
SELECT columna1, columna2
FROM tabla
WHERE condición_sobre_filas;
-- Filtrado con HAVING
SELECT columna1, función_agregación(columna2)
FROM tabla
GROUP BY columna1
HAVING condición_sobre_grupos;
Diferencias clave
- Posición en la consulta: WHERE va antes de GROUP BY, mientras que HAVING va después.
- Tipo de filtrado: WHERE filtra filas individuales; HAVING filtra grupos.
- Uso de funciones de agregación: WHERE no puede usar funciones como COUNT, SUM o AVG en sus condiciones; HAVING sí puede.
- Rendimiento: WHERE generalmente es más eficiente porque reduce el conjunto de datos antes de realizar operaciones de agrupación.
Ejemplos comparativos
Veamos algunos ejemplos que ilustran claramente las diferencias:
Ejemplo 1: Filtrado de filas vs. filtrado de grupos
-- Con WHERE: Empleados con salario mayor a 50000
SELECT nombre, departamento, salario
FROM empleados
WHERE salario > 50000;
-- Con HAVING: Departamentos con salario promedio mayor a 50000
SELECT departamento, AVG(salario) AS salario_promedio
FROM empleados
GROUP BY departamento
HAVING AVG(salario) > 50000;
En el primer caso, filtramos empleados individuales con salarios altos. En el segundo, filtramos departamentos con promedios salariales altos.
Ejemplo 2: Combinando WHERE y HAVING
-- Departamentos con salario promedio mayor a 50000, considerando solo empleados a tiempo completo
SELECT departamento, AVG(salario) AS salario_promedio
FROM empleados
WHERE tipo_contrato = 'Tiempo completo'
GROUP BY departamento
HAVING AVG(salario) > 50000;
Aquí, WHERE filtra primero para incluir solo empleados a tiempo completo, y luego HAVING filtra los grupos resultantes para mostrar solo departamentos con salario promedio superior a 50000.
Cuándo usar cada uno
-
Usa WHERE cuando:
-
Necesites filtrar filas individuales basándote en valores de columnas.
-
Quieras mejorar el rendimiento filtrando datos antes de agruparlos.
-
No necesites usar funciones de agregación en tus condiciones de filtrado.
-
Usa HAVING cuando:
-
Necesites filtrar grupos basándote en resultados de funciones de agregación.
-
Quieras aplicar condiciones después de que los datos han sido agrupados.
-
Necesites referirte a alias de columnas creados en la cláusula SELECT.
Errores comunes
Un error frecuente es intentar usar funciones de agregación en la cláusula WHERE:
-- Incorrecto: ERROR - no se puede usar agregación en WHERE
SELECT departamento, COUNT(*) AS num_empleados
FROM empleados
WHERE COUNT(*) > 5
GROUP BY departamento;
-- Correcto: Usar HAVING para condiciones con funciones de agregación
SELECT departamento, COUNT(*) AS num_empleados
FROM empleados
GROUP BY departamento
HAVING COUNT(*) > 5;
Otro error común es intentar filtrar por un alias de columna usando WHERE:
-- Incorrecto: ERROR - no se puede usar alias en WHERE
SELECT nombre, salario, salario * 1.1 AS salario_con_aumento
FROM empleados
WHERE salario_con_aumento > 55000;
-- Correcto: Repetir la expresión en WHERE
SELECT nombre, salario, salario * 1.1 AS salario_con_aumento
FROM empleados
WHERE salario * 1.1 > 55000;
-- Alternativa: Usar subconsulta o CTE
WITH empleados_con_aumento AS (
SELECT nombre, salario, salario * 1.1 AS salario_con_aumento
FROM empleados
)
SELECT *
FROM empleados_con_aumento
WHERE salario_con_aumento > 55000;
Optimización de consultas
Para optimizar el rendimiento de tus consultas, considera estas recomendaciones:
- Usa WHERE siempre que sea posible para reducir el volumen de datos antes de agrupar.
- Combina WHERE y HAVING cuando necesites filtrar tanto filas individuales como grupos.
- Aprovecha los índices en las columnas utilizadas en WHERE para mejorar la velocidad.
-- Menos eficiente
SELECT categoria, COUNT(*) AS total_productos
FROM productos
GROUP BY categoria
HAVING COUNT(*) > 10 AND categoria LIKE 'Electr%';
-- Más eficiente
SELECT categoria, COUNT(*) AS total_productos
FROM productos
WHERE categoria LIKE 'Electr%' -- Filtra primero para reducir filas
GROUP BY categoria
HAVING COUNT(*) > 10;
Compatibilidad entre bases de datos
La mayoría de los sistemas de gestión de bases de datos relacionales (MySQL, PostgreSQL, SQL Server, Oracle) implementan WHERE y HAVING de manera similar, siguiendo el estándar SQL. Sin embargo, pueden existir pequeñas diferencias en cuanto a optimización y comportamiento específico.
Por ejemplo, en MySQL y PostgreSQL, ambos permiten usar HAVING sin GROUP BY (aunque no es una práctica recomendada), mientras que otros sistemas pueden requerir explícitamente GROUP BY cuando se usa HAVING.
-- Funciona en MySQL y PostgreSQL, pero no recomendado
SELECT COUNT(*) AS total
FROM empleados
HAVING COUNT(*) > 100;
-- Forma estándar y recomendada
SELECT COUNT(*) AS total
FROM empleados
GROUP BY () -- Grupo vacío en PostgreSQL
HAVING COUNT(*) > 100;
Entender las diferencias entre WHERE y HAVING te permitirá escribir consultas SQL más precisas y eficientes, aprovechando al máximo las capacidades de filtrado que ofrece el lenguaje.
HAVING con JOIN
La combinación de HAVING con JOIN es una técnica poderosa para filtrar datos agrupados provenientes de múltiples tablas. Esta combinación nos permite realizar análisis complejos sobre datos relacionados, aplicando condiciones a grupos después de haber unido la información de diferentes tablas.
Cuando trabajamos con bases de datos relacionales, rara vez la información que necesitamos está contenida en una sola tabla. Los JOIN nos permiten combinar datos de múltiples tablas, mientras que HAVING nos ayuda a filtrar los resultados agrupados según criterios específicos.
Estructura básica
La estructura típica de una consulta que combina HAVING con JOIN es:
SELECT t1.columna1, t2.columna2, función_agregación(t1.columna3)
FROM tabla1 t1
JOIN tabla2 t2 ON t1.columna_relación = t2.columna_relación
GROUP BY t1.columna1, t2.columna2
HAVING condición_sobre_grupos;
Es importante notar que en la cláusula GROUP BY debemos incluir todas las columnas no agregadas que aparecen en el SELECT.
Ejemplos prácticos
Veamos algunos ejemplos que ilustran el uso de HAVING con diferentes tipos de JOIN:
Ejemplo 1: Encontrar categorías de productos con ventas totales superiores a $10,000
SELECT c.nombre_categoria, SUM(v.cantidad * p.precio) AS ventas_totales
FROM ventas v
INNER JOIN productos p ON v.id_producto = p.id_producto
INNER JOIN categorias c ON p.id_categoria = c.id_categoria
GROUP BY c.nombre_categoria
HAVING SUM(v.cantidad * p.precio) > 10000
ORDER BY ventas_totales DESC;
En este ejemplo, unimos tres tablas (ventas, productos y categorías) para calcular las ventas totales por categoría, y luego filtramos para mostrar solo aquellas categorías cuyas ventas superan los $10,000.
Ejemplo 2: Identificar clientes que han realizado más de 5 pedidos en el último año
SELECT c.id_cliente, c.nombre, COUNT(p.id_pedido) AS total_pedidos
FROM clientes c
LEFT JOIN pedidos p ON c.id_cliente = p.id_cliente
WHERE p.fecha_pedido >= DATE_SUB(CURRENT_DATE, INTERVAL 1 YEAR)
GROUP BY c.id_cliente, c.nombre
HAVING COUNT(p.id_pedido) > 5
ORDER BY total_pedidos DESC;
Aquí utilizamos un LEFT JOIN para incluir a todos los clientes (incluso aquellos sin pedidos), filtramos con WHERE para considerar solo pedidos del último año, y finalmente aplicamos HAVING para mostrar únicamente los clientes con más de 5 pedidos.
Uso con diferentes tipos de JOIN
La cláusula HAVING funciona con todos los tipos de JOIN, cada uno con sus propias implicaciones:
- INNER JOIN con HAVING: Filtra grupos formados solo por filas que coinciden en ambas tablas.
SELECT d.nombre_departamento, AVG(e.salario) AS salario_promedio
FROM empleados e
INNER JOIN departamentos d ON e.id_departamento = d.id_departamento
GROUP BY d.nombre_departamento
HAVING AVG(e.salario) > 50000;
- LEFT JOIN con HAVING: Permite filtrar grupos que incluyen filas de la tabla izquierda sin correspondencia en la derecha.
SELECT p.nombre_proveedor, COUNT(pr.id_producto) AS num_productos
FROM proveedores p
LEFT JOIN productos pr ON p.id_proveedor = pr.id_proveedor
GROUP BY p.nombre_proveedor
HAVING COUNT(pr.id_producto) = 0;
Este ejemplo muestra proveedores que no tienen productos asociados (COUNT = 0).
-
RIGHT JOIN con HAVING: Similar al LEFT JOIN pero desde la perspectiva de la tabla derecha.
-
FULL JOIN con HAVING: Permite filtrar grupos formados por todas las filas de ambas tablas (disponible en PostgreSQL, pero no en MySQL).
Casos de uso avanzados
Ejemplo 3: Encontrar departamentos donde el salario promedio es mayor que el promedio general de la empresa
SELECT d.nombre_departamento, AVG(e.salario) AS salario_promedio
FROM empleados e
INNER JOIN departamentos d ON e.id_departamento = d.id_departamento
GROUP BY d.nombre_departamento
HAVING AVG(e.salario) > (
SELECT AVG(salario)
FROM empleados
);
Este ejemplo utiliza una subconsulta dentro de HAVING para comparar el salario promedio de cada departamento con el promedio general.
Ejemplo 4: Identificar productos que se venden en más del 50% de las tiendas
SELECT p.nombre_producto, COUNT(DISTINCT v.id_tienda) AS num_tiendas,
(SELECT COUNT(*) FROM tiendas) AS total_tiendas
FROM productos p
JOIN ventas v ON p.id_producto = v.id_producto
GROUP BY p.nombre_producto, total_tiendas
HAVING COUNT(DISTINCT v.id_tienda) > total_tiendas * 0.5
ORDER BY num_tiendas DESC;
Aquí combinamos JOIN, GROUP BY, HAVING y una subconsulta para encontrar productos populares que se venden en la mayoría de las tiendas.
Optimización de consultas con HAVING y JOIN
Cuando combinamos HAVING con JOIN, es especialmente importante considerar el rendimiento:
- Orden de las tablas: Coloca la tabla más pequeña primero en la cláusula FROM para reducir el conjunto de datos inicial.
- Filtrado temprano: Usa WHERE antes de GROUP BY para reducir la cantidad de filas que se procesan.
- Índices adecuados: Asegúrate de tener índices en las columnas utilizadas en las condiciones de JOIN, WHERE y GROUP BY.
-- Menos eficiente
SELECT c.nombre_categoria, COUNT(*) AS total_productos
FROM productos p
JOIN categorias c ON p.id_categoria = c.id_categoria
GROUP BY c.nombre_categoria
HAVING COUNT(*) > 10;
-- Más eficiente (si sabemos que pocas categorías tienen más de 10 productos)
SELECT c.nombre_categoria, COUNT(*) AS total_productos
FROM (
SELECT id_categoria, COUNT(*) AS conteo
FROM productos
GROUP BY id_categoria
HAVING COUNT(*) > 10
) AS subq
JOIN categorias c ON subq.id_categoria = c.id_categoria
GROUP BY c.nombre_categoria;
Errores comunes al usar HAVING con JOIN
- Omitir columnas en GROUP BY: Todas las columnas no agregadas en SELECT deben aparecer en GROUP BY.
-- Incorrecto: falta incluir nombre_categoria en GROUP BY
SELECT c.id_categoria, c.nombre_categoria, COUNT(*) AS total
FROM productos p
JOIN categorias c ON p.id_categoria = c.id_categoria
GROUP BY c.id_categoria
HAVING COUNT(*) > 5;
-- Correcto
SELECT c.id_categoria, c.nombre_categoria, COUNT(*) AS total
FROM productos p
JOIN categorias c ON p.id_categoria = c.id_categoria
GROUP BY c.id_categoria, c.nombre_categoria
HAVING COUNT(*) > 5;
- Confundir el orden de ejecución: Recuerda que JOIN y WHERE se ejecutan antes que GROUP BY y HAVING.
-- Incorrecto: intenta filtrar por el alias total_ventas en WHERE
SELECT c.nombre_cliente, SUM(v.monto) AS total_ventas
FROM clientes c
JOIN ventas v ON c.id_cliente = v.id_cliente
WHERE total_ventas > 1000 -- Error: total_ventas no existe aún
GROUP BY c.nombre_cliente;
-- Correcto: usar HAVING para filtrar por el resultado de la agregación
SELECT c.nombre_cliente, SUM(v.monto) AS total_ventas
FROM clientes c
JOIN ventas v ON c.id_cliente = v.id_cliente
GROUP BY c.nombre_cliente
HAVING SUM(v.monto) > 1000;
Ejemplos específicos para MySQL y PostgreSQL
MySQL - Encontrar productos con ventas en múltiples regiones:
SELECT p.nombre_producto,
COUNT(DISTINCT r.id_region) AS num_regiones
FROM productos p
JOIN ventas v ON p.id_producto = v.id_producto
JOIN tiendas t ON v.id_tienda = t.id_tienda
JOIN regiones r ON t.id_region = r.id_region
GROUP BY p.nombre_producto
HAVING COUNT(DISTINCT r.id_region) >= 3
ORDER BY num_regiones DESC;
PostgreSQL - Análisis de rendimiento de empleados por departamento:
SELECT d.nombre_departamento,
COUNT(e.id_empleado) AS num_empleados,
ROUND(AVG(e.evaluacion), 2) AS evaluacion_promedio
FROM departamentos d
LEFT JOIN empleados e ON d.id_departamento = e.id_departamento
GROUP BY d.nombre_departamento
HAVING COUNT(e.id_empleado) > 5 AND AVG(e.evaluacion) < 3.5
ORDER BY evaluacion_promedio;
Este ejemplo identifica departamentos con más de 5 empleados y un promedio de evaluación inferior a 3.5, lo que podría indicar problemas de rendimiento que requieren atención.
Combinando múltiples JOIN con HAVING
Para análisis más complejos, podemos combinar múltiples JOIN con HAVING:
SELECT c.nombre_categoria,
p.nombre_proveedor,
COUNT(DISTINCT pr.id_producto) AS num_productos,
SUM(v.cantidad) AS unidades_vendidas
FROM categorias c
JOIN productos pr ON c.id_categoria = pr.id_categoria
JOIN proveedores p ON pr.id_proveedor = p.id_proveedor
JOIN ventas v ON pr.id_producto = v.id_producto
WHERE v.fecha_venta >= '2023-01-01'
GROUP BY c.nombre_categoria, p.nombre_proveedor
HAVING COUNT(DISTINCT pr.id_producto) >= 3
AND SUM(v.cantidad) > 1000
ORDER BY unidades_vendidas DESC;
Esta consulta identifica combinaciones de categorías y proveedores que tienen al menos 3 productos diferentes y han vendido más de 1000 unidades desde el inicio de 2023.
La combinación de HAVING con JOIN es una herramienta esencial para el análisis de datos relacionales, permitiéndonos extraer información valiosa de múltiples tablas y aplicar condiciones sofisticadas a los resultados agrupados.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la función y sintaxis de la cláusula HAVING para filtrar grupos en consultas SQL. Diferenciar entre el uso de WHERE y HAVING y conocer el momento de ejecución de cada uno. Aplicar HAVING en consultas que involucran funciones de agregación y múltiples condiciones. Integrar HAVING con JOIN para filtrar datos agrupados provenientes de varias tablas. Optimizar consultas SQL utilizando HAVING y JOIN considerando el rendimiento y buenas prácticas.