Agrupación básica
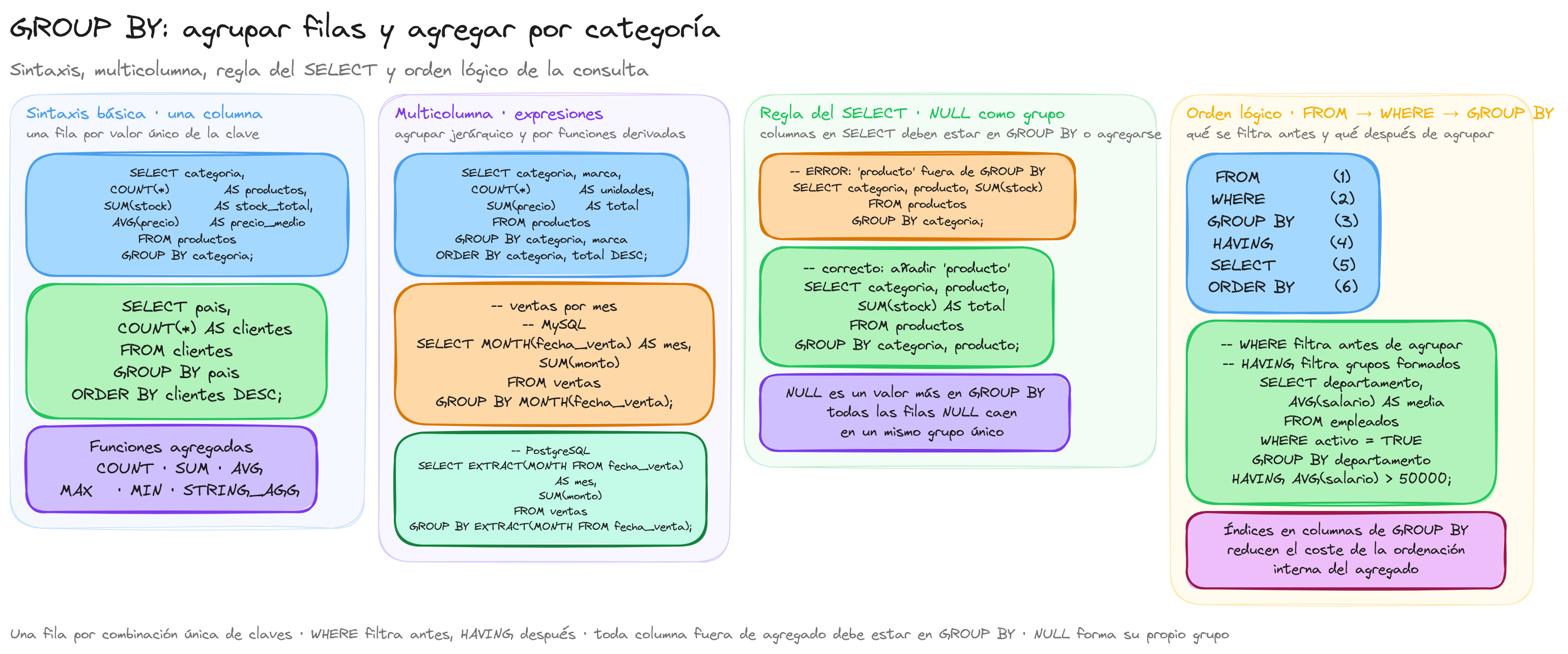
La cláusula GROUP BY es una de las herramientas más útiles en SQL cuando necesitamos analizar datos agrupados por categorías. En lugar de ver registros individuales, esta cláusula nos permite agrupar filas que comparten un mismo valor en una o más columnas, permitiéndonos realizar cálculos sobre cada grupo.
Cuando trabajamos con bases de datos, frecuentemente necesitamos obtener información resumida en lugar de datos detallados. Por ejemplo, podríamos querer conocer el total de ventas por categoría de producto, el promedio de salarios por departamento, o el número de clientes por país.
Sintaxis básica
La estructura básica de una consulta con GROUP BY es:
SELECT columna_agrupacion, funcion_agregada(columna)
FROM tabla
GROUP BY columna_agrupacion;
Donde:
columna_agrupaciónes la columna por la que queremos agrupar los resultadosfuncion_agregadaes una función como COUNT(), SUM(), AVG(), MAX() o MIN()
Ejemplo práctico
Imaginemos una tabla ventas con información sobre transacciones:
CREATE TABLE ventas (
id INT PRIMARY KEY,
producto VARCHAR(50),
categoria VARCHAR(50),
cantidad INT,
precio DECIMAL(10,2),
fecha_venta DATE
);
Si queremos contar cuántas ventas hay por cada categoría de producto, usaríamos:
SELECT categoria, COUNT(*) AS total_ventas
FROM ventas
GROUP BY categoria;
Este query nos devolverá una fila por cada categoría única, junto con el número total de ventas en esa categoría.
Agrupación con funciones agregadas
La verdadera potencia de GROUP BY se manifiesta cuando lo combinamos con funciones agregadas. Estas funciones realizan cálculos sobre los grupos de filas:
- COUNT(): Cuenta el número de filas en cada grupo
- SUM(): Suma los valores de una columna para cada grupo
- AVG(): Calcula el promedio de una columna para cada grupo
- MAX(): Encuentra el valor máximo de una columna en cada grupo
- MIN(): Encuentra el valor mínimo de una columna en cada grupo
Por ejemplo, para calcular el total de ingresos por categoría:
SELECT categoria, SUM(cantidad * precio) AS ingresos_totales
FROM ventas
GROUP BY categoria;
Ordenando resultados agrupados
Podemos combinar GROUP BY con ORDER BY para ordenar los resultados según nuestras necesidades:
SELECT categoria, SUM(cantidad * precio) AS ingresos_totales
FROM ventas
GROUP BY categoria
ORDER BY ingresos_totales DESC;
Este query mostrará las categorías ordenadas de mayor a menor según sus ingresos totales.
Agrupación por expresiones
También podemos agrupar por expresiones, no solo por columnas directas. Por ejemplo, si queremos agrupar ventas por mes:
-- En MySQL:
SELECT MONTH(fecha_venta) AS mes, SUM(cantidad * precio) AS ingresos
FROM ventas
GROUP BY MONTH(fecha_venta);
-- En PostgreSQL:
SELECT EXTRACT(MONTH FROM fecha_venta) AS mes, SUM(cantidad * precio) AS ingresos
FROM ventas
GROUP BY EXTRACT(MONTH FROM fecha_venta);
Consideraciones importantes
Al trabajar con GROUP BY, hay algunas reglas fundamentales que debemos recordar:
-
Todas las columnas en la cláusula SELECT que no estén dentro de funciones agregadas deben aparecer en la cláusula GROUP BY.
-
No podemos usar alias de columna definidos en el SELECT dentro del GROUP BY (aunque MySQL lo permite, no es estándar SQL).
-
GROUP BY se ejecuta después de WHERE pero antes de ORDER BY en el procesamiento de la consulta.
Veamos un ejemplo de error común:
-- Esto generará un error en la mayoría de sistemas SQL
SELECT categoria, producto, SUM(cantidad)
FROM ventas
GROUP BY categoria;
Este query fallará porque producto no está en la cláusula GROUP BY. La forma correcta sería:
SELECT categoria, producto, SUM(cantidad) AS total_cantidad
FROM ventas
GROUP BY categoria, producto;
Ejemplo con datos reales
Supongamos que tenemos datos de ventas y queremos analizar el rendimiento por día de la semana:
-- En MySQL:
SELECT
DAYNAME(fecha_venta) AS dia_semana,
COUNT(*) AS numero_ventas,
ROUND(AVG(cantidad * precio), 2) AS venta_promedio
FROM ventas
GROUP BY DAYNAME(fecha_venta)
ORDER BY FIELD(dia_semana, 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday');
-- En PostgreSQL:
SELECT
TO_CHAR(fecha_venta, 'Day') AS dia_semana,
COUNT(*) AS numero_ventas,
ROUND(AVG(cantidad * precio)::numeric, 2) AS venta_promedio
FROM ventas
GROUP BY TO_CHAR(fecha_venta, 'Day'), TO_CHAR(fecha_venta, 'D')
ORDER BY TO_CHAR(fecha_venta, 'D');
Este análisis nos permitiría identificar qué días de la semana generan más ventas y cuál es el valor promedio de las transacciones.
Agrupación con valores NULL
Es importante entender cómo SQL maneja los valores NULL en agrupaciones. En GROUP BY, todos los valores NULL se consideran iguales y se agrupan juntos:
SELECT categoria, COUNT(*) AS total
FROM ventas
GROUP BY categoria;
Si algunos productos no tienen categoría asignada (NULL), aparecerán como un grupo separado en los resultados.
Casos de uso comunes
La agrupación básica es especialmente útil para:
- Análisis de ventas: Total de ventas por región, producto o período
- Estadísticas de usuarios: Número de usuarios por país, grupo de edad o plataforma
- Métricas financieras: Promedio de gastos por departamento o categoría
- Análisis de inventario: Cantidad de productos por categoría o ubicación
- Reportes de rendimiento: Número de transacciones por hora o día
Agrupación multicolumna
Cuando analizamos datos en SQL, a menudo necesitamos crear agrupaciones más específicas que las que se pueden lograr con una sola columna. La agrupación multicolumna nos permite segmentar nuestros datos con mayor precisión, creando grupos basados en combinaciones únicas de valores en múltiples columnas.
Sintaxis para agrupar por múltiples columnas
Para agrupar por más de una columna, simplemente añadimos las columnas adicionales en la cláusula GROUP BY, separándolas por comas:
SELECT columna1, columna2, ..., funcion_agregada(columna)
FROM tabla
GROUP BY columna1, columna2, ...;
Cada combinación única de valores en las columnas especificadas formará un grupo separado en los resultados.
Jerarquía de agrupación
Cuando agrupamos por múltiples columnas, SQL crea una jerarquía de agrupación. El orden de las columnas en la cláusula GROUP BY determina esta jerarquía, aunque no afecta a los resultados finales. Conceptualmente, podemos visualizarlo como:
- Primero se agrupan los datos por la primera columna
- Dentro de cada grupo de la primera columna, se subagrupan por la segunda columna
- Y así sucesivamente para cada columna adicional
Por ejemplo, si agrupamos ventas por país y luego por ciudad:
SELECT pais, ciudad, SUM(monto) AS total_ventas
FROM ventas
GROUP BY pais, ciudad;
Obtendremos una fila para cada combinación única de país y ciudad, con el total de ventas para esa combinación específica.
Ejemplo práctico con datos de ventas
Consideremos una tabla de ventas con información detallada:
CREATE TABLE ventas_detalladas (
id INT PRIMARY KEY,
fecha DATE,
producto VARCHAR(100),
categoria VARCHAR(50),
subcategoria VARCHAR(50),
region VARCHAR(50),
vendedor VARCHAR(100),
cantidad INT,
precio_unitario DECIMAL(10,2)
);
Si queremos analizar las ventas por categoría y subcategoría de producto:
SELECT
categoria,
subcategoria,
COUNT(*) AS num_transacciones,
SUM(cantidad) AS unidades_vendidas,
ROUND(SUM(cantidad * precio_unitario), 2) AS ingresos_totales
FROM ventas_detalladas
GROUP BY categoria, subcategoria
ORDER BY categoria, ingresos_totales DESC;
Este query nos dará una visión jerárquica de nuestras ventas, mostrando el rendimiento de cada subcategoría dentro de cada categoría principal.
Análisis temporal multinivel
La agrupación multicolumna es especialmente útil para análisis temporales en diferentes niveles. Por ejemplo, podemos analizar ventas por año y mes:
-- En MySQL:
SELECT
YEAR(fecha) AS anio,
MONTH(fecha) AS mes,
SUM(cantidad * precio_unitario) AS ventas_totales
FROM ventas_detalladas
GROUP BY YEAR(fecha), MONTH(fecha)
ORDER BY anio, mes;
-- En PostgreSQL:
SELECT
EXTRACT(YEAR FROM fecha) AS anio,
EXTRACT(MONTH FROM fecha) AS mes,
SUM(cantidad * precio_unitario) AS ventas_totales
FROM ventas_detalladas
GROUP BY EXTRACT(YEAR FROM fecha), EXTRACT(MONTH FROM fecha)
ORDER BY anio, mes;
Este tipo de consulta nos permite identificar tendencias estacionales y comparar el rendimiento mes a mes a lo largo de diferentes años.
Agrupación por dimensiones de negocio
En análisis de datos empresariales, frecuentemente necesitamos examinar métricas a través de múltiples dimensiones de negocio. Por ejemplo, podríamos querer analizar ventas por región y vendedor:
SELECT
region,
vendedor,
COUNT(*) AS transacciones,
SUM(cantidad * precio_unitario) AS ventas_totales,
ROUND(AVG(cantidad * precio_unitario), 2) AS ticket_promedio
FROM ventas_detalladas
GROUP BY region, vendedor
ORDER BY region, ventas_totales DESC;
Esta consulta nos ayudaría a identificar a los vendedores estrella en cada región y comparar su rendimiento.
Combinando expresiones en agrupaciones multicolumna
Podemos combinar columnas directas con expresiones en nuestras agrupaciones:
-- En MySQL:
SELECT
categoria,
YEAR(fecha) AS anio,
QUARTER(fecha) AS trimestre,
SUM(cantidad * precio_unitario) AS ingresos
FROM ventas_detalladas
GROUP BY categoria, YEAR(fecha), QUARTER(fecha)
ORDER BY categoria, anio, trimestre;
-- En PostgreSQL:
SELECT
categoria,
EXTRACT(YEAR FROM fecha) AS anio,
EXTRACT(QUARTER FROM fecha) AS trimestre,
SUM(cantidad * precio_unitario) AS ingresos
FROM ventas_detalladas
GROUP BY categoria, EXTRACT(YEAR FROM fecha), EXTRACT(QUARTER FROM fecha)
ORDER BY categoria, anio, trimestre;
Esta consulta nos permite analizar el rendimiento trimestral de cada categoría de producto a lo largo del tiempo.
Agrupación con cálculos derivados
También podemos agrupar por cálculos derivados, lo que nos permite crear segmentaciones personalizadas:
SELECT
CASE
WHEN precio_unitario < 50 THEN 'Económico'
WHEN precio_unitario BETWEEN 50 AND 200 THEN 'Estándar'
ELSE 'Premium'
END AS segmento_precio,
categoria,
COUNT(*) AS num_ventas,
SUM(cantidad) AS unidades_vendidas
FROM ventas_detalladas
GROUP BY
CASE
WHEN precio_unitario < 50 THEN 'Económico'
WHEN precio_unitario BETWEEN 50 AND 200 THEN 'Estándar'
ELSE 'Premium'
END,
categoria
ORDER BY segmento_precio, categoria;
Esta técnica nos permite crear segmentaciones dinámicas basadas en rangos de valores u otras condiciones lógicas.
Limitaciones y consideraciones
Al trabajar con agrupaciones multicolumna, debemos tener en cuenta algunas consideraciones:
- Rendimiento: Agrupar por muchas columnas puede afectar el rendimiento, especialmente en tablas grandes.
- Cardinalidad: Si las columnas tienen muchos valores únicos, podríamos terminar con demasiados grupos pequeños.
- Regla de columnas: Todas las columnas no agregadas en el SELECT deben aparecer en el GROUP BY.
Por ejemplo, esta consulta generará un error en la mayoría de sistemas SQL:
-- Consulta incorrecta
SELECT categoria, subcategoria, region, SUM(cantidad)
FROM ventas_detalladas
GROUP BY categoria, subcategoria;
La forma correcta sería incluir todas las columnas no agregadas en el GROUP BY:
-- Consulta correcta
SELECT categoria, subcategoria, region, SUM(cantidad) AS total_cantidad
FROM ventas_detalladas
GROUP BY categoria, subcategoria, region;
Ejemplo de análisis de rentabilidad
Un caso de uso avanzado sería analizar la rentabilidad por múltiples dimensiones:
SELECT
region,
categoria,
EXTRACT(YEAR FROM fecha) AS anio,
SUM(cantidad * precio_unitario) AS ingresos,
COUNT(DISTINCT vendedor) AS num_vendedores,
ROUND(SUM(cantidad * precio_unitario) / COUNT(DISTINCT vendedor), 2) AS ingreso_por_vendedor
FROM ventas_detalladas
GROUP BY region, categoria, EXTRACT(YEAR FROM fecha)
ORDER BY region, ingreso_por_vendedor DESC;
Este análisis nos permite identificar qué combinaciones de región y categoría generan mayor ingreso por vendedor, ayudándonos a optimizar la asignación de recursos.
Visualización de datos agrupados
Las agrupaciones multicolumna son ideales para crear tablas dinámicas o visualizaciones jerárquicas. Por ejemplo, podríamos generar datos para un mapa de calor que muestre ventas por día de la semana y hora del día:
-- En PostgreSQL:
SELECT
TO_CHAR(fecha, 'Day') AS dia_semana,
EXTRACT(HOUR FROM fecha_hora) AS hora_dia,
COUNT(*) AS num_transacciones
FROM ventas_detalladas
GROUP BY TO_CHAR(fecha, 'Day'), EXTRACT(HOUR FROM fecha_hora), TO_CHAR(fecha, 'D')
ORDER BY TO_CHAR(fecha, 'D'), hora_dia;
Esta consulta nos permitiría identificar los patrones temporales en nuestras ventas, mostrando cuándo ocurre la mayor actividad comercial.
GROUP BY con agregación
La combinación de GROUP BY con funciones de agregación constituye una de las herramientas más potentes de SQL para el análisis de datos. Mientras que GROUP BY por sí solo organiza los registros en grupos, son las funciones de agregación las que nos permiten realizar cálculos significativos sobre estos grupos.
Funciones de agregación en grupos
Las funciones de agregación procesan múltiples filas para producir un único valor resumido. Cuando se combinan con GROUP BY, estas funciones se aplican independientemente a cada grupo formado. Las funciones de agregación más comunes son:
- COUNT(): Cuenta el número de filas o valores no nulos
- SUM(): Calcula la suma de los valores numéricos
- AVG(): Calcula el promedio de los valores numéricos
- MAX(): Encuentra el valor máximo
- MIN(): Encuentra el valor mínimo
Veamos un ejemplo con una tabla de pedidos:
CREATE TABLE pedidos (
id INT PRIMARY KEY,
cliente_id INT,
producto_id INT,
cantidad INT,
precio_unitario DECIMAL(10,2),
fecha_pedido DATE
);
Para calcular estadísticas de ventas por producto:
SELECT
producto_id,
COUNT(*) AS numero_pedidos,
SUM(cantidad) AS unidades_vendidas,
ROUND(AVG(precio_unitario), 2) AS precio_promedio,
MIN(precio_unitario) AS precio_minimo,
MAX(precio_unitario) AS precio_maximo,
SUM(cantidad * precio_unitario) AS ingresos_totales
FROM pedidos
GROUP BY producto_id;
Esta consulta proporciona un análisis completo de cada producto, mostrando desde cuántas veces se ha pedido hasta los ingresos totales generados.
Funciones de agregación condicionales
Podemos hacer que las funciones de agregación actúen de manera condicional utilizando CASE WHEN dentro de ellas:
SELECT
EXTRACT(YEAR FROM fecha_pedido) AS año,
SUM(CASE WHEN cantidad >= 10 THEN 1 ELSE 0 END) AS pedidos_grandes,
SUM(CASE WHEN cantidad < 10 THEN 1 ELSE 0 END) AS pedidos_pequeños,
COUNT(*) AS total_pedidos
FROM pedidos
GROUP BY EXTRACT(YEAR FROM fecha_pedido);
Esta técnica nos permite crear métricas personalizadas basadas en condiciones específicas dentro de cada grupo.
Cálculo de porcentajes y proporciones
Una aplicación común de la agregación con GROUP BY es calcular porcentajes dentro de grupos:
SELECT
cliente_id,
COUNT(*) AS total_pedidos,
SUM(cantidad * precio_unitario) AS gasto_total,
ROUND(AVG(cantidad * precio_unitario), 2) AS valor_promedio_pedido,
ROUND(SUM(cantidad * precio_unitario) / COUNT(*), 2) AS gasto_por_pedido
FROM pedidos
GROUP BY cliente_id;
Esta consulta nos permite analizar el comportamiento de compra de cada cliente, calculando métricas como el gasto promedio por pedido.
Agregación con expresiones matemáticas
Podemos aplicar operaciones matemáticas dentro de las funciones de agregación:
SELECT
EXTRACT(MONTH FROM fecha_pedido) AS mes,
SUM(cantidad * precio_unitario) AS ingresos_brutos,
SUM(cantidad * precio_unitario * 0.8) AS ingresos_netos,
SUM(cantidad * precio_unitario * 0.2) AS impuestos
FROM pedidos
GROUP BY EXTRACT(MONTH FROM fecha_pedido)
ORDER BY mes;
Esta consulta calcula los ingresos mensuales desglosados en componentes netos e impuestos, suponiendo una tasa impositiva del 20%.
Agregación con funciones de fecha
Las funciones de fecha combinadas con agregación nos permiten realizar análisis temporales:
-- En MySQL:
SELECT
DATE_FORMAT(fecha_pedido, '%Y-%m') AS mes,
COUNT(*) AS total_pedidos,
ROUND(SUM(cantidad * precio_unitario), 2) AS ingresos_totales,
MAX(cantidad * precio_unitario) AS pedido_mayor_valor
FROM pedidos
GROUP BY DATE_FORMAT(fecha_pedido, '%Y-%m')
ORDER BY mes;
-- En PostgreSQL:
SELECT
TO_CHAR(fecha_pedido, 'YYYY-MM') AS mes,
COUNT(*) AS total_pedidos,
ROUND(SUM(cantidad * precio_unitario)::numeric, 2) AS ingresos_totales,
MAX(cantidad * precio_unitario) AS pedido_mayor_valor
FROM pedidos
GROUP BY TO_CHAR(fecha_pedido, 'YYYY-MM')
ORDER BY mes;
Este tipo de consulta es fundamental para análisis de tendencias y reportes periódicos.
Agregación con funciones de cadena
También podemos utilizar funciones de agregación con cadenas de texto:
-- En MySQL:
SELECT
cliente_id,
COUNT(*) AS total_pedidos,
GROUP_CONCAT(DISTINCT producto_id ORDER BY producto_id) AS productos_comprados
FROM pedidos
GROUP BY cliente_id;
-- En PostgreSQL:
SELECT
cliente_id,
COUNT(*) AS total_pedidos,
STRING_AGG(DISTINCT producto_id::text, ', ' ORDER BY producto_id) AS productos_comprados
FROM pedidos
GROUP BY cliente_id;
Esta consulta nos muestra una lista consolidada de todos los productos únicos que cada cliente ha comprado.
Agregación con funciones estadísticas
Algunos sistemas SQL ofrecen funciones estadísticas avanzadas para análisis más sofisticados:
-- En PostgreSQL:
SELECT
producto_id,
COUNT(*) AS num_pedidos,
AVG(cantidad) AS cantidad_promedio,
STDDEV(cantidad) AS desviacion_estandar,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY cantidad) AS mediana
FROM pedidos
GROUP BY producto_id;
Estas funciones nos permiten realizar análisis estadísticos más profundos sobre nuestros datos agrupados.
Agregación con ventanas temporales
Podemos crear análisis de tendencias utilizando ventanas temporales:
-- Análisis trimestral
SELECT
EXTRACT(YEAR FROM fecha_pedido) AS año,
EXTRACT(QUARTER FROM fecha_pedido) AS trimestre,
COUNT(*) AS num_pedidos,
SUM(cantidad) AS unidades_vendidas,
ROUND(SUM(cantidad * precio_unitario), 2) AS ingresos
FROM pedidos
GROUP BY EXTRACT(YEAR FROM fecha_pedido), EXTRACT(QUARTER FROM fecha_pedido)
ORDER BY año, trimestre;
Este enfoque nos permite identificar patrones estacionales y evaluar el rendimiento a lo largo del tiempo.
Agregación con múltiples tablas
La agregación con GROUP BY también funciona con consultas que involucran múltiples tablas:
SELECT
c.categoria_nombre,
COUNT(p.id) AS total_pedidos,
SUM(p.cantidad) AS unidades_vendidas,
ROUND(SUM(p.cantidad * p.precio_unitario), 2) AS ingresos_totales
FROM pedidos p
JOIN productos pr ON p.producto_id = pr.id
JOIN categorias c ON pr.categoria_id = c.id
GROUP BY c.categoria_nombre
ORDER BY ingresos_totales DESC;
Esta consulta nos proporciona un análisis por categoría utilizando datos de tres tablas relacionadas.
Agregación con expresiones CASE
Podemos crear agrupaciones dinámicas utilizando expresiones CASE:
SELECT
CASE
WHEN cantidad * precio_unitario < 100 THEN 'Bajo valor'
WHEN cantidad * precio_unitario BETWEEN 100 AND 500 THEN 'Valor medio'
ELSE 'Alto valor'
END AS segmento_valor,
COUNT(*) AS num_pedidos,
ROUND(AVG(cantidad * precio_unitario), 2) AS valor_promedio,
SUM(cantidad * precio_unitario) AS valor_total
FROM pedidos
GROUP BY
CASE
WHEN cantidad * precio_unitario < 100 THEN 'Bajo valor'
WHEN cantidad * precio_unitario BETWEEN 100 AND 500 THEN 'Valor medio'
ELSE 'Alto valor'
END
ORDER BY valor_promedio;
Esta técnica nos permite crear segmentaciones personalizadas basadas en criterios específicos.
Agregación con subconsultas
Podemos utilizar subconsultas para crear métricas de comparación:
SELECT
producto_id,
COUNT(*) AS num_pedidos,
SUM(cantidad) AS unidades_vendidas,
ROUND(SUM(cantidad * precio_unitario), 2) AS ingresos,
ROUND(SUM(cantidad * precio_unitario) /
(SELECT SUM(cantidad * precio_unitario) FROM pedidos) * 100, 2) AS porcentaje_total
FROM pedidos
GROUP BY producto_id
ORDER BY porcentaje_total DESC;
Esta consulta calcula qué porcentaje del total de ingresos representa cada producto.
Optimización de consultas con agregación
Al trabajar con grandes volúmenes de datos, es importante considerar el rendimiento:
- Índices adecuados: Crear índices en las columnas utilizadas en GROUP BY mejora significativamente el rendimiento.
- Filtrado previo: Aplicar filtros con WHERE antes de agrupar reduce la cantidad de datos a procesar.
- Limitar columnas: Seleccionar solo las columnas necesarias reduce el uso de memoria.
Por ejemplo, una consulta optimizada podría ser:
SELECT
producto_id,
SUM(cantidad * precio_unitario) AS ingresos_totales
FROM pedidos
WHERE fecha_pedido >= '2023-01-01'
GROUP BY producto_id
HAVING SUM(cantidad * precio_unitario) > 1000
ORDER BY ingresos_totales DESC
LIMIT 10;
Esta consulta está optimizada para encontrar rápidamente los 10 productos más rentables del año actual.
Casos de uso prácticos
La combinación de GROUP BY con agregación es fundamental para:
- Dashboards de negocio: Crear resúmenes ejecutivos de rendimiento
- Análisis de ventas: Identificar productos más vendidos y tendencias
- Segmentación de clientes: Agrupar clientes por patrones de compra
- Análisis de rendimiento: Evaluar métricas clave por región, período o categoría
- Detección de anomalías: Identificar valores atípicos en grupos de datos
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la sintaxis y uso básico de la cláusula GROUP BY para agrupar resultados. Aplicar funciones agregadas como COUNT, SUM, AVG, MAX y MIN en grupos de datos. Realizar agrupaciones multicolumna para segmentar datos de forma jerárquica. Combinar GROUP BY con expresiones, condiciones y funciones avanzadas para análisis personalizados. Optimizar consultas con GROUP BY para mejorar el rendimiento en bases de datos grandes.