Concepto ventana y sintaxis OVER y PARTITION BY
flowchart TB
Tabla["Tabla origen: filas individuales"] --> Over[Cláusula OVER]
Over --> Partition["PARTITION BY: divide en subconjuntos"]
Partition --> Order["ORDER BY: ordena dentro de la partición"]
Order --> Frame["Frame: ROWS o RANGE BETWEEN"]
Frame --> Funcion{Tipo de función ventana}
Funcion -- ranking --> Rank["ROW_NUMBER, RANK, DENSE_RANK, NTILE"]
Funcion -- offset --> Offset["LAG, LEAD, FIRST_VALUE, LAST_VALUE"]
Funcion -- agregación --> Agg["SUM, AVG, COUNT sobre frame"]
Rank --> Salida["Filas conservadas: agrega valor por fila"]
Offset --> Salida
Agg --> Salida
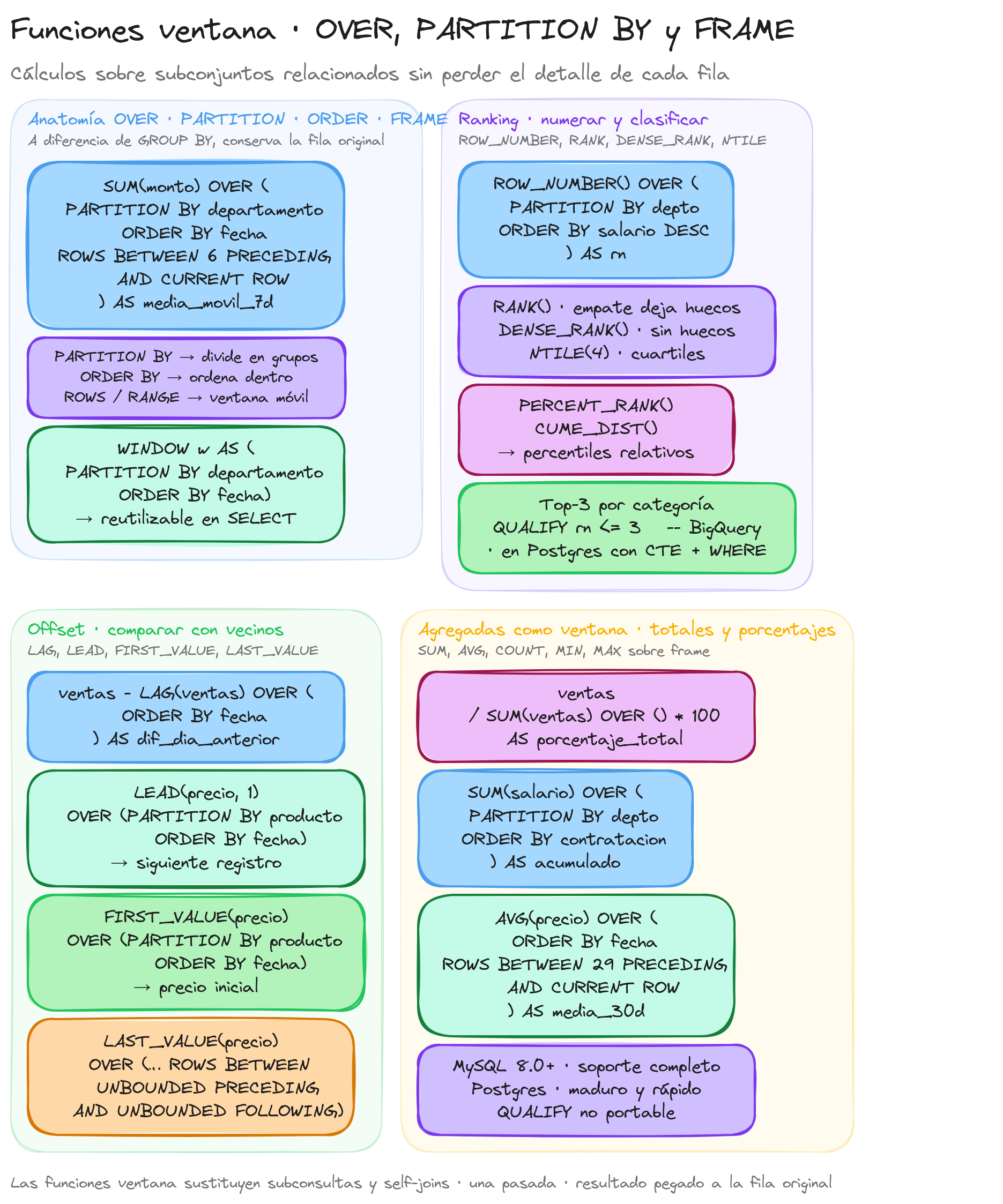
Las funciones ventana (window functions) representan una característica avanzada de SQL que permite realizar cálculos a través de un conjunto de filas relacionadas con la fila actual, sin necesidad de agrupar los resultados como ocurre con las funciones de agregación tradicionales. Estas funciones nos permiten mantener el detalle de cada fila mientras realizamos operaciones sobre conjuntos de datos.
Entendiendo el concepto de ventana
Una ventana en SQL se refiere a un conjunto de filas sobre las que se realiza una operación. A diferencia de las funciones de agregación con GROUP BY (que reducen múltiples filas a una sola), las funciones ventana preservan todas las filas originales en el resultado.
Imagina que tienes una tabla con las ventas de una tienda y quieres calcular el total de ventas por departamento, pero manteniendo el detalle de cada venta individual. Con una función ventana, puedes obtener ambas cosas a la vez.
La cláusula OVER
La cláusula OVER es el componente fundamental que convierte una función normal en una función ventana. Esta cláusula define el conjunto de filas (la ventana) sobre el que se aplicará la función.
La sintaxis básica es:
función_ventana() OVER ([partition_by_clause] [order_by_clause])
Por ejemplo, para calcular la suma de ventas por departamento:
SELECT
id_venta,
departamento,
monto,
SUM(monto) OVER (PARTITION BY departamento) AS total_departamento
FROM ventas;
Este ejemplo muestra cada venta individual junto con el total de ventas de su departamento.
PARTITION BY: Dividiendo los datos en subconjuntos
La cláusula PARTITION BY divide el conjunto de resultados en particiones a las que se aplica la función ventana por separado. Es similar conceptualmente a GROUP BY, pero con una diferencia crucial: no reduce el número de filas en el resultado.
Veamos un ejemplo práctico con una tabla de empleados:
SELECT
nombre,
departamento,
salario,
AVG(salario) OVER (PARTITION BY departamento) AS salario_promedio_depto
FROM empleados;
Este ejemplo muestra cada empleado con su salario individual y el salario promedio de su departamento. La función ventana calcula el promedio para cada departamento, pero mantiene todas las filas originales.
Ventanas sin particiones
Si omitimos la cláusula PARTITION BY, la ventana incluirá todas las filas del conjunto de resultados:
SELECT
nombre,
salario,
AVG(salario) OVER () AS salario_promedio_general
FROM empleados;
En este caso, cada fila mostrará el salario promedio de todos los empleados.
Ordenación dentro de las ventanas con ORDER BY
Dentro de la cláusula OVER, también podemos incluir ORDER BY para definir el orden de las filas dentro de cada partición:
SELECT
nombre,
departamento,
fecha_contratacion,
salario,
SUM(salario) OVER (
PARTITION BY departamento
ORDER BY fecha_contratacion
) AS salario_acumulado
FROM empleados;
Este ejemplo calcula la suma acumulada de salarios dentro de cada departamento, ordenados por fecha de contratación. Para cada empleado, muestra la suma de su salario más los salarios de todos los empleados contratados antes que él en el mismo departamento.
Diferencias entre MySQL y PostgreSQL
Ambos sistemas de gestión de bases de datos soportan funciones ventana, pero con algunas diferencias:
- MySQL: Introdujo soporte completo para funciones ventana a partir de la versión 8.0.
- PostgreSQL: Tiene un soporte más maduro y completo para funciones ventana desde versiones anteriores.
En MySQL, un ejemplo básico sería:
SELECT
id_producto,
categoria,
precio,
AVG(precio) OVER (PARTITION BY categoria) AS precio_promedio
FROM productos;
En PostgreSQL, podemos usar la misma sintaxis:
SELECT
id_producto,
categoria,
precio,
AVG(precio) OVER (PARTITION BY categoria) AS precio_promedio
FROM productos;
Casos de uso prácticos
Las funciones ventana son especialmente útiles en varios escenarios:
- Análisis de tendencias: Calcular promedios móviles o sumas acumulativas.
SELECT
fecha,
ventas_diarias,
AVG(ventas_diarias) OVER (
ORDER BY fecha
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS promedio_semanal
FROM ventas_por_dia;
- Comparaciones con períodos anteriores: Comparar valores actuales con valores previos.
SELECT
fecha,
ventas,
ventas - LAG(ventas) OVER (ORDER BY fecha) AS diferencia_con_dia_anterior
FROM ventas_por_dia;
- Cálculos de porcentajes del total: Determinar qué porcentaje representa cada valor respecto al total.
SELECT
producto,
ventas,
ventas / SUM(ventas) OVER () * 100 AS porcentaje_del_total
FROM ventas_por_producto;
Ventajas de las funciones ventana
Las funciones ventana ofrecen varias ventajas significativas:
- Eficiencia: Evitan múltiples subconsultas o joins para obtener valores agregados junto con detalles.
- Legibilidad: Hacen que las consultas sean más claras y concisas.
- Rendimiento: Generalmente son más eficientes que soluciones alternativas.
Por ejemplo, sin funciones ventana, para obtener cada venta junto con el total por departamento, necesitaríamos:
SELECT
v.id_venta,
v.departamento,
v.monto,
t.total_departamento
FROM ventas v
JOIN (
SELECT
departamento,
SUM(monto) AS total_departamento
FROM ventas
GROUP BY departamento
) t ON v.departamento = t.departamento;
Con funciones ventana, es mucho más simple:
SELECT
id_venta,
departamento,
monto,
SUM(monto) OVER (PARTITION BY departamento) AS total_departamento
FROM ventas;
Las funciones ventana son una herramienta poderosa que permite realizar análisis complejos de datos de manera eficiente. Dominando la sintaxis OVER y PARTITION BY, podrás realizar cálculos sofisticados manteniendo el nivel de detalle que necesitas en tus consultas SQL.
Funciones de ranking
Las funciones de ranking son un subconjunto especializado de las funciones ventana que permiten asignar un número de posición (rango) a cada fila dentro de una partición según un criterio de ordenación específico. Estas funciones son extremadamente útiles cuando necesitamos clasificar registros, identificar los N primeros o últimos elementos, o encontrar posiciones relativas dentro de un conjunto de datos.
SQL ofrece varias funciones de ranking que, aunque similares, tienen comportamientos específicos que las hacen adecuadas para diferentes situaciones. Veamos las principales:
ROW_NUMBER()
La función ROW_NUMBER() asigna un número único y secuencial a cada fila dentro de una partición, comenzando desde 1 y siguiendo el orden especificado. No hay empates en esta función; cada fila recibe un valor único incluso si tienen valores idénticos en la columna de ordenación.
SELECT
nombre,
departamento,
salario,
ROW_NUMBER() OVER (PARTITION BY departamento ORDER BY salario DESC) AS posicion
FROM empleados;
Este ejemplo asigna una posición a cada empleado dentro de su departamento, ordenados por salario de mayor a menor. El empleado con el salario más alto en cada departamento tendrá la posición 1.
RANK()
La función RANK() también asigna posiciones, pero maneja los empates de manera diferente. Cuando dos o más filas tienen el mismo valor en la columna de ordenación, reciben el mismo rango. Sin embargo, esto crea "huecos" en la secuencia de numeración.
SELECT
producto,
categoria,
precio,
RANK() OVER (PARTITION BY categoria ORDER BY precio DESC) AS ranking
FROM productos;
Si dos productos en la misma categoría tienen exactamente el mismo precio, ambos recibirán el mismo ranking. El siguiente producto recibirá un ranking que salta el número correspondiente a los empates. Por ejemplo, si dos productos comparten el ranking 2, el siguiente producto tendrá el ranking 4.
DENSE_RANK()
Similar a RANK(), la función DENSE_RANK() asigna el mismo valor a filas con valores idénticos en la columna de ordenación. La diferencia es que no deja huecos en la secuencia de numeración.
SELECT
estudiante,
asignatura,
calificacion,
DENSE_RANK() OVER (PARTITION BY asignatura ORDER BY calificacion DESC) AS posicion
FROM calificaciones;
En este caso, si dos estudiantes tienen la misma calificación en una asignatura, ambos recibirán la misma posición, y el siguiente estudiante recibirá la posición inmediatamente siguiente. Por ejemplo, si dos estudiantes comparten la posición 2, el siguiente tendrá la posición 3.
NTILE(n)
La función NTILE(n) divide las filas de una partición en un número específico de grupos (aproximadamente) iguales y asigna a cada fila el número del grupo al que pertenece.
SELECT
nombre,
ventas_anuales,
NTILE(4) OVER (ORDER BY ventas_anuales DESC) AS cuartil
FROM vendedores;
Este ejemplo divide a los vendedores en cuatro grupos (cuartiles) según sus ventas anuales. Los vendedores con mayores ventas estarán en el cuartil 1, y los de menores ventas en el cuartil 4.
PERCENT_RANK()
La función PERCENT_RANK() calcula la posición relativa de una fila dentro de su partición, devolviendo un valor entre 0 y 1. La fórmula es (rank - 1) / (total_rows - 1).
SELECT
producto,
precio,
PERCENT_RANK() OVER (ORDER BY precio) AS posicion_percentil
FROM productos;
Los productos con precios más bajos tendrán valores cercanos a 0, mientras que los más caros tendrán valores cercanos a 1. Esta función es útil para análisis estadísticos y para identificar outliers.
CUME_DIST()
La función CUME_DIST() (distribución acumulativa) calcula la proporción de filas con valores menores o iguales al valor actual, devolviendo un número entre 0 y 1.
SELECT
empleado,
salario,
CUME_DIST() OVER (ORDER BY salario) AS distribucion_acumulada
FROM empleados;
Un valor de 0.7 significa que el 70% de los empleados tienen un salario menor o igual al del empleado actual.
Ejemplos prácticos de aplicación
Identificar los 3 productos más vendidos por categoría
WITH RankedProducts AS (
SELECT
producto,
categoria,
unidades_vendidas,
RANK() OVER (PARTITION BY categoria ORDER BY unidades_vendidas DESC) AS ranking
FROM ventas_productos
)
SELECT
producto,
categoria,
unidades_vendidas
FROM RankedProducts
WHERE ranking <= 3;
Este ejemplo utiliza una Common Table Expressión (CTE) para primero asignar un ranking a cada producto dentro de su categoría, y luego filtrar solo los tres productos más vendidos de cada categoría.
Calcular cuartiles salariales por departamento
SELECT
nombre,
departamento,
salario,
CASE
WHEN cuartil = 1 THEN 'Top 25%'
WHEN cuartil = 2 THEN '26-50%'
WHEN cuartil = 3 THEN '51-75%'
WHEN cuartil = 4 THEN 'Bottom 25%'
END AS grupo_salarial
FROM (
SELECT
nombre,
departamento,
salario,
NTILE(4) OVER (PARTITION BY departamento ORDER BY salario DESC) AS cuartil
FROM empleados
) AS ranked_employees;
Este ejemplo divide a los empleados de cada departamento en cuatro grupos salariales, facilitando la identificación de disparidades salariales dentro de los departamentos.
Identificar valores atípicos con PERCENT_RANK
SELECT
producto,
precio,
CASE
WHEN percentil >= 0.95 THEN 'Precio premium'
WHEN percentil <= 0.05 THEN 'Precio económico'
ELSE 'Precio estándar'
END AS categoria_precio
FROM (
SELECT
producto,
precio,
PERCENT_RANK() OVER (ORDER BY precio) AS percentil
FROM productos
) AS ranked_products;
Esta consulta identifica productos con precios atípicamente altos o bajos, categorizándolos como "premium" o "económicos" si están en el 5% superior o inferior respectivamente.
Diferencias entre MySQL y PostgreSQL
Ambos sistemas de gestión de bases de datos soportan las funciones de ranking, pero con algunas diferencias:
- MySQL: Soporta todas las funciones de ranking mencionadas a partir de la versión 8.0.
- PostgreSQL: Tiene un soporte más maduro y completo para estas funciones desde versiones anteriores.
En MySQL, un ejemplo básico sería:
SELECT
nombre,
departamento,
salario,
RANK() OVER (PARTITION BY departamento ORDER BY salario DESC) AS ranking
FROM empleados;
En PostgreSQL, la sintaxis es idéntica:
SELECT
nombre,
departamento,
salario,
RANK() OVER (PARTITION BY departamento ORDER BY salario DESC) AS ranking
FROM empleados;
Consideraciones de rendimiento
Las funciones de ranking pueden ser intensivas en recursos, especialmente con grandes conjuntos de datos. Algunas recomendaciones:
- Limitar el conjunto de datos: Aplicar filtros antes de usar funciones de ranking.
- Índices adecuados: Asegurarse de que las columnas utilizadas en PARTITION BY y ORDER BY estén indexadas.
- Materializar resultados intermedios: Usar CTEs o tablas temporales para cálculos complejos.
-- Enfoque más eficiente con conjuntos grandes
WITH FilteredData AS (
SELECT * FROM ventas
WHERE fecha >= '2023-01-01'
)
SELECT
producto,
ventas,
ROW_NUMBER() OVER (ORDER BY ventas DESC) AS ranking
FROM FilteredData;
Combinando funciones de ranking
Es posible utilizar múltiples funciones de ranking en la misma consulta para obtener diferentes perspectivas sobre los datos:
SELECT
producto,
categoria,
ventas,
ROW_NUMBER() OVER (PARTITION BY categoria ORDER BY ventas DESC) AS row_num,
RANK() OVER (PARTITION BY categoria ORDER BY ventas DESC) AS rank,
DENSE_RANK() OVER (PARTITION BY categoria ORDER BY ventas DESC) AS dense_rank
FROM productos_ventas;
Esta consulta permite comparar cómo las diferentes funciones de ranking manejan los empates y asignan posiciones dentro de cada categoría de productos.
Las funciones de ranking son herramientas poderosas que permiten realizar análisis sofisticados de datos, identificar patrones y tendencias, y presentar información de manera significativa y accionable. Dominando estas funciones, podrás extraer insights valiosos de tus datos de manera eficiente y elegante.
Agregación por ventanas
Las funciones de agregación por ventanas representan una extensión poderosa de las funciones ventana que nos permiten realizar cálculos agregados (como sumas, promedios o conteos) sobre un conjunto específico de filas relacionadas con la fila actual. A diferencia de las funciones de agregación tradicionales con GROUP BY, las agregaciones por ventanas mantienen todas las filas originales en el resultado mientras realizan cálculos sobre subconjuntos de datos.
Funciones de agregación en contexto de ventanas
Las funciones de agregación más comunes que podemos utilizar con la sintaxis de ventanas incluyen:
- SUM(): Calcula la suma de valores
- AVG(): Calcula el promedio de valores
- COUNT(): Cuenta el número de filas
- MIN(): Encuentra el valor mínimo
- MAX(): Encuentra el valor máximo
La sintaxis básica para usar estas funciones en un contexto de ventana es:
función_agregación() OVER ([partition_by_clause] [order_by_clause] [frame_clause])
Por ejemplo, para calcular el promedio de ventas por región:
SELECT
fecha,
region,
ventas,
AVG(ventas) OVER (PARTITION BY region) AS promedio_region
FROM ventas_mensuales;
Marcos de ventana (Window Frames)
Un marco de ventana define con precisión el conjunto de filas incluidas en cada cálculo de la función de agregación. Esta característica permite un control detallado sobre qué filas se consideran para cada operación de agregación.
La sintaxis para definir un marco de ventana es:
función_agregación() OVER (
[PARTITION BY columna1, columna2, ...]
[ORDER BY columna3, columna4, ...]
[ROWS|RANGE] frame_start [TO|AND] frame_end
)
Donde frame_start y frame_end pueden ser:
- UNBOUNDED PRECEDING: Desde el inicio de la partición
- UNBOUNDED FOLLOWING: Hasta el final de la partición
- CURRENT ROW: La fila actual
- n PRECEDING: n filas antes de la fila actual
- n FOLLOWING: n filas después de la fila actual
Ejemplos de marcos de ventana
1. Suma acumulativa de ventas por mes:
SELECT
fecha,
ventas,
SUM(ventas) OVER (
ORDER BY fecha
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS ventas_acumuladas
FROM ventas_mensuales;
Este ejemplo calcula la suma acumulativa de ventas para cada mes, considerando todos los meses anteriores hasta el actual.
2. Promedio móvil de 3 meses:
SELECT
fecha,
ventas,
AVG(ventas) OVER (
ORDER BY fecha
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS promedio_movil_3meses
FROM ventas_mensuales;
Esta consulta calcula el promedio de ventas considerando el mes actual y los dos meses anteriores, creando un promedio móvil de 3 meses.
3. Comparación con valores anteriores y posteriores:
SELECT
fecha,
producto,
precio,
AVG(precio) OVER (
PARTITION BY producto
ORDER BY fecha
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS precio_promedio_cercano
FROM historico_precios;
Este ejemplo calcula el precio promedio considerando la fecha actual, la anterior y la siguiente para cada producto.
Diferencia entre ROWS y RANGE
SQL ofrece dos formas de definir marcos de ventana:
- ROWS: Define el marco en términos de filas físicas (número de filas)
- RANGE: Define el marco en términos de valores lógicos (rango de valores)
-- Usando ROWS (basado en posición física)
SELECT
fecha,
ventas,
AVG(ventas) OVER (
ORDER BY fecha
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS promedio_3dias_rows
FROM ventas_diarias;
-- Usando RANGE (basado en valores lógicos)
SELECT
fecha,
ventas,
AVG(ventas) OVER (
ORDER BY fecha
RANGE BETWEEN INTERVAL '1' DAY PRECEDING AND INTERVAL '1' DAY FOLLOWING
) AS promedio_3dias_range
FROM ventas_diarias;
La diferencia es sutil pero importante: con ROWS, se consideran exactamente las filas especificadas independientemente de sus valores. Con RANGE, se consideran todas las filas cuyos valores están dentro del rango especificado, lo que puede incluir más filas si hay valores duplicados.
Casos de uso prácticos
Análisis de tendencias y detección de anomalías
SELECT
fecha,
ventas,
AVG(ventas) OVER (
ORDER BY fecha
ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING
) AS tendencia,
ventas - AVG(ventas) OVER (
ORDER BY fecha
ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING
) AS desviacion
FROM ventas_diarias;
Esta consulta calcula una línea de tendencia suavizada (promedio móvil de 7 días) y la desviación de cada día respecto a esa tendencia, lo que ayuda a identificar anomalías.
Cálculo de porcentajes del total
SELECT
departamento,
empleado,
salario,
salario / SUM(salario) OVER (PARTITION BY departamento) * 100 AS porcentaje_depto,
salario / SUM(salario) OVER () * 100 AS porcentaje_empresa
FROM empleados;
Este ejemplo muestra qué porcentaje del presupuesto salarial representa cada empleado, tanto a nivel de departamento como de toda la empresa.
Análisis de crecimiento
SELECT
año,
trimestre,
ventas,
ventas - LAG(ventas) OVER (ORDER BY año, trimestre) AS crecimiento_absoluto,
(ventas - LAG(ventas) OVER (ORDER BY año, trimestre)) /
LAG(ventas) OVER (ORDER BY año, trimestre) * 100 AS crecimiento_porcentual
FROM ventas_trimestrales;
Esta consulta calcula el crecimiento absoluto y porcentual de las ventas respecto al trimestre anterior.
Agregaciones por ventanas en MySQL y PostgreSQL
Tanto MySQL como PostgreSQL soportan agregaciones por ventanas, pero con algunas diferencias en la implementación:
MySQL (versión 8.0+):
SELECT
producto,
mes,
ventas,
SUM(ventas) OVER (
PARTITION BY producto
ORDER BY mes
ROWS UNBOUNDED PRECEDING
) AS ventas_acumuladas
FROM ventas_mensuales;
PostgreSQL:
SELECT
producto,
mes,
ventas,
SUM(ventas) OVER (
PARTITION BY producto
ORDER BY mes
ROWS UNBOUNDED PRECEDING
) AS ventas_acumuladas
FROM ventas_mensuales;
La sintaxis es similar, pero PostgreSQL ofrece algunas funcionalidades adicionales y un soporte más maduro para marcos de ventana complejos.
Optimización de consultas con agregaciones por ventanas
Las agregaciones por ventanas pueden ser operaciones intensivas en recursos, especialmente con grandes conjuntos de datos. Algunas recomendaciones para optimizar su rendimiento:
- Limitar el tamaño de las particiones: Usar filtros WHERE antes de aplicar funciones ventana.
- Considerar el tamaño del marco: Marcos más pequeños (como ROWS BETWEEN 5 PRECEDING AND 5 FOLLOWING) son más eficientes que marcos ilimitados (UNBOUNDED).
- Índices adecuados: Asegurarse de que las columnas usadas en PARTITION BY y ORDER BY estén indexadas.
-- Más eficiente con grandes conjuntos de datos
SELECT
fecha,
producto,
ventas,
AVG(ventas) OVER (
PARTITION BY producto
ORDER BY fecha
ROWS BETWEEN 30 PRECEDING AND CURRENT ROW
) AS promedio_movil_30dias
FROM ventas_diarias
WHERE fecha >= DATE_SUB(CURRENT_DATE, INTERVAL 90 DAY);
Combinando agregaciones con otras funciones ventana
Es posible combinar agregaciones por ventanas con funciones de ranking u otras funciones ventana para análisis más complejos:
SELECT
region,
producto,
ventas,
RANK() OVER (PARTITION BY region ORDER BY ventas DESC) AS ranking,
ventas / SUM(ventas) OVER (PARTITION BY region) * 100 AS porcentaje_region,
AVG(ventas) OVER (
PARTITION BY region, producto
ORDER BY año, mes
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS promedio_trimestral
FROM ventas_mensuales;
Esta consulta proporciona múltiples perspectivas sobre los datos de ventas: ranking de productos por región, porcentaje de contribución a las ventas regionales y promedio móvil trimestral.
Ejemplo de aplicación real: Análisis de comportamiento de clientes
SELECT
cliente_id,
fecha_compra,
monto,
COUNT(*) OVER (PARTITION BY cliente_id) AS total_compras,
SUM(monto) OVER (PARTITION BY cliente_id) AS gasto_total,
AVG(monto) OVER (PARTITION BY cliente_id) AS gasto_promedio,
monto / SUM(monto) OVER (PARTITION BY cliente_id) * 100 AS porcentaje_gasto,
DATEDIFF(
fecha_compra,
FIRST_VALUE(fecha_compra) OVER (
PARTITION BY cliente_id
ORDER BY fecha_compra
)
) AS dias_desde_primera_compra
FROM compras;
Esta consulta proporciona un análisis completo del comportamiento de compra de cada cliente, incluyendo frecuencia, montos y patrones temporales, todo en una sola consulta eficiente.
Las agregaciones por ventanas son una herramienta extremadamente versátil que permite realizar análisis complejos de datos manteniendo el nivel de detalle necesario. Dominando esta técnica, podrás transformar consultas complejas que requerirían múltiples subconsultas o joins en expresiones elegantes y eficientes.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Comprender el concepto de ventana y la sintaxis básica de las funciones ventana con OVER y PARTITION BY.
- Diferenciar entre funciones de ranking y funciones de agregación aplicadas como ventanas.
- Aplicar funciones de ranking como ROW_NUMBER, RANK, DENSE_RANK, NTILE, PERCENT_RANK y CUME_DIST para clasificar y analizar datos.
- Utilizar marcos de ventana (window frames) para definir con precisión el rango de filas en cálculos agregados.
- Optimizar consultas y entender diferencias de soporte entre MySQL y PostgreSQL para funciones ventana.