Qué es el optimizer
El optimizer (o planner) es el componente del motor SQL que decide cómo ejecutar una consulta. Ante una misma query, hay muchas formas posibles:
- ¿Escanea la tabla entera o usa un índice?
- Si hay JOIN de 3 tablas, ¿en qué orden las une?
- ¿Usa hash join, merge join o nested loop?
- ¿Ordena por clave o con un sort externo?
El optimizer genera múltiples planes, les asigna un coste estimado y elige el más barato. EXPLAIN muestra ese plan; EXPLAIN ANALYZE lo ejecuta y muestra además tiempos y filas reales.
Sintaxis básica
-- Solo plan estimado, no ejecuta
EXPLAIN SELECT * FROM pedidos WHERE fecha > '2026-01-01';
-- Plan + ejecucion real con tiempos
EXPLAIN ANALYZE SELECT * FROM pedidos WHERE fecha > '2026-01-01';
-- Con mas detalle (PostgreSQL)
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, FORMAT TEXT)
SELECT * FROM pedidos WHERE fecha > '2026-01-01';
En MySQL:
EXPLAIN SELECT * FROM pedidos WHERE fecha > '2026-01-01';
EXPLAIN ANALYZE SELECT * FROM pedidos WHERE fecha > '2026-01-01'; -- MySQL 8.0.18+
EXPLAIN FORMAT=JSON SELECT ...; -- salida JSON estructurada
Leyendo un plan simple
EXPLAIN ANALYZE SELECT * FROM pedidos WHERE cliente_id = 42;
Salida típica:
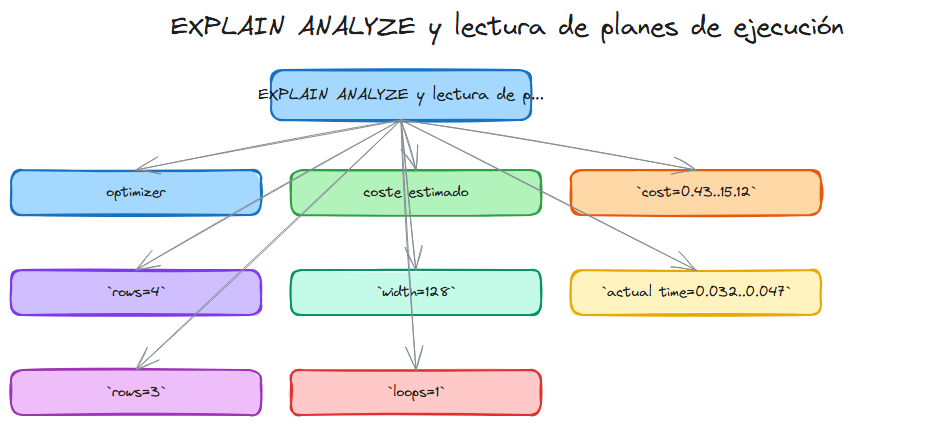
Index Scan using idx_pedidos_cliente on pedidos
(cost=0.43..15.12 rows=4 width=128)
(actual time=0.032..0.047 rows=3 loops=1)
Index Cond: (cliente_id = 42)
Planning Time: 0.087 ms
Execution Time: 0.067 ms
Qué significa cada valor
cost=0.43..15.12: el coste estimado. El primero es el coste hasta devolver la primera fila; el segundo, el coste total. Son unidades arbitrarias del optimizer.rows=4: filas estimadas que devolverá el nodo.width=128: tamaño medio estimado por fila en bytes.actual time=0.032..0.047: tiempo real en milisegundos hasta la primera fila y hasta la última.rows=3: filas reales (no estimadas).loops=1: cuántas veces se ejecutó este nodo. En nested loops puede ser alto.
Regla crítica: si estimated rows y actual rows difieren mucho (órdenes de magnitud), el optimizer tomó decisiones con estadísticas obsoletas. Solución: ANALYZE tabla; o VACUUM ANALYZE tabla;.
Nodos más habituales
Seq Scan (Sequential Scan)
Lee la tabla completa fila por fila. Apropiado cuando:
- No hay índice aplicable.
- La query va a devolver la mayoría de filas (>~20%).
- La tabla es pequeña (el optimizer decide que es más barato leer todo que usar el índice).
Seq Scan on productos (cost=0.00..157.00 rows=1000 width=64)
Si esperabas que usara un índice y ves Seq Scan, verifica:
- Si el índice existe (
\d nombre_tablaen psql). - Si el WHERE usa funciones que anulan el índice (
WHERE UPPER(col) = ?no usa índice encol; usaWHERE col = UPPER(?)o índice funcional). - Si las estadísticas están al día (
ANALYZE).
Index Scan
Usa un índice para localizar filas específicas. Rápido cuando devuelve pocas filas.
Index Scan using idx_productos_precio on productos
(cost=0.29..8.31 rows=1 width=64)
Index Cond: (precio < 100)
Bitmap Heap Scan + Bitmap Index Scan
Construye un bitmap de páginas que pueden contener filas, luego las lee en orden físico. Es eficiente cuando:
- Usa varios índices (combinados con OR/AND).
- Devuelve filas dispersas pero numerosas.
Bitmap Heap Scan on pedidos (cost=...)
Recheck Cond: ...
-> Bitmap Index Scan on idx_pedidos_fecha (cost=...)
Index Only Scan
Especialmente rápido: el índice contiene todas las columnas que la query necesita, no hace falta acceder a la tabla. Requiere covering index:
Index Only Scan using idx_productos_precio_incl on productos
(cost=0.29..4.31 rows=1 width=32)
Heap Fetches: 0 <- excelente: no accedio a la tabla
Nested Loop
Para cada fila de una tabla, busca las filas coincidentes en otra. Eficiente cuando la tabla externa es pequeña y la interna tiene un índice útil.
Nested Loop (cost=..., rows=10, ...)
-> Seq Scan on clientes (rows=10)
-> Index Scan on pedidos (loops=10)
Index Cond: (cliente_id = clientes.id)
Si loops es muy grande (miles) y la interna no tiene índice, el coste es O(n²). Suele indicar que hace falta un índice o un tipo de JOIN distinto.
Hash Join
Construye una tabla hash con una relación, y escanea la otra buscando coincidencias. Eficiente con tablas medianas que caben en memoria.
Hash Join (cost=..., rows=100, ...)
Hash Cond: (pedidos.cliente_id = clientes.id)
-> Seq Scan on pedidos (rows=1000)
-> Hash (rows=100)
-> Seq Scan on clientes (rows=100)
Si la hash table excede work_mem, el motor usa disco y el rendimiento cae. Ajusta work_mem (solo dentro de una sesión si hace falta):
SET work_mem = '64MB'; -- para esta sesion
Merge Join
Une dos relaciones pre-ordenadas por la clave del JOIN, avanzando ambas en paralelo. Muy eficiente cuando ambos lados ya están ordenados (por un índice B-tree o un ORDER BY previo).
Merge Join (cost=..., rows=1000, ...)
Merge Cond: (pedidos.id = lineas.pedido_id)
-> Index Scan using idx_pedidos_id on pedidos
-> Sort on lineas <- puede ser costoso
Errores comunes: estimaciones mal
Cuando actual rows difiere enormemente de estimated rows:
Seq Scan on pedidos
(cost=0.00..100.00 rows=100 width=64)
(actual time=0.032..5000.567 rows=1000000 loops=1)
El optimizer creía 100 filas, ejecutó con 1 millón. Probablemente tomó un plan de nested loop que con 1M de filas es lentísimo.
Soluciones:
- Actualizar estadísticas:
ANALYZE pedidos; - Aumentar
default_statistics_target(más buckets en el histograma):ALTER TABLE pedidos ALTER COLUMN estado SET STATISTICS 1000; ANALYZE pedidos; - Estadísticas multivariantes (correlaciones entre columnas):
CREATE STATISTICS stats_pedidos_estado_fecha (dependencies) ON estado, fecha FROM pedidos; ANALYZE pedidos;
Formato JSON y visualización
Para análisis automáticos o herramientas:
EXPLAIN (FORMAT JSON, ANALYZE, BUFFERS)
SELECT * FROM pedidos WHERE cliente_id = 42;
Herramientas útiles para leer planes:
- explain.depesz.com: pega la salida de EXPLAIN y resalta los nodos más costosos.
- pev2 (interactivo): visualiza el árbol con colores según coste.
- pgAdmin: muestra el plan gráficamente.
BUFFERS: cache hits vs lectura de disco
EXPLAIN (ANALYZE, BUFFERS) muestra cuántas páginas vienen de la caché y cuántas del disco:
Seq Scan on pedidos
...
Buffers: shared hit=100 read=500
hit: páginas leídas de la caché de PostgreSQL (rápido).read: páginas leídas del disco (lento, pero luego pasan a cache).
Si repites la query y sigue viendo muchos read, la tabla no cabe en cache. Soluciones: aumentar shared_buffers, o usar índices más selectivos.
EXPLAIN en producción sin impacto
EXPLAIN sin ANALYZE no ejecuta la query. Seguro en producción.
EXPLAIN ANALYZE sí ejecuta la query completa (incluso UPDATE/DELETE reales). Para ver el plan de un UPDATE sin modificar datos, envuelve en transacción y rollback:
BEGIN;
EXPLAIN (ANALYZE, BUFFERS) UPDATE pedidos SET estado = 'pagado' WHERE id = 123;
ROLLBACK;
Flujo de trabajo para optimizar una query lenta
- Reproducir el problema:
EXPLAIN ANALYZEcon los parámetros reales. - Identificar el nodo más caro: mirar
actual timeyrows. - Verificar estadísticas:
actual rowsvsestimated rows. Si difieren,ANALYZE. - Revisar índices: ¿hay un índice apropiado? ¿lo está usando?
- Verificar JOIN order: si hay varias tablas, asegúrate de que el plan une las más pequeñas primero.
- Ajustar
work_memsi vesexternal sortoDisk: ...kB. - Considerar reescribir la query si el plan estructural es malo (
EXISTSen lugar deIN, CTE materializada, etc.).
Resumen de comandos útiles
-- PostgreSQL
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, FORMAT TEXT) <query>;
ANALYZE tabla; -- refrescar estadisticas
VACUUM ANALYZE tabla; -- reclamar espacio + analyze
ALTER TABLE tabla ALTER COLUMN col SET STATISTICS 1000; -- mas precision
CREATE STATISTICS <nombre> ON col1, col2 FROM tabla; -- multivariantes
-- MySQL
EXPLAIN <query>;
EXPLAIN ANALYZE <query>; -- MySQL 8.0.18+
EXPLAIN FORMAT=JSON <query>;
ANALYZE TABLE tabla;

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Interpretar la salida de EXPLAIN (plan) y EXPLAIN ANALYZE (plan + ejecucion real). Identificar cuando un Seq Scan es apropiado y cuando hay que forzar un Index Scan. Distinguir Nested Loop, Hash Join y Merge Join segun el tamano de las tablas. Detectar estimaciones incorrectas (actual rows muy distinto de estimated) y su correcion con ANALYZE. Usar BUFFERS para ver cache hits/misses y TIMING para medir tiempos por nodo.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje