Definición de BBDD relacionales
Las bases de datos relacionales constituyen uno de los modelos más utilizados y robustos para el almacenamiento estructurado de información. Este modelo, fundamentado en la teoría matemática de relaciones, organiza los datos en estructuras tabulares que permiten establecer conexiones lógicas entre ellas.
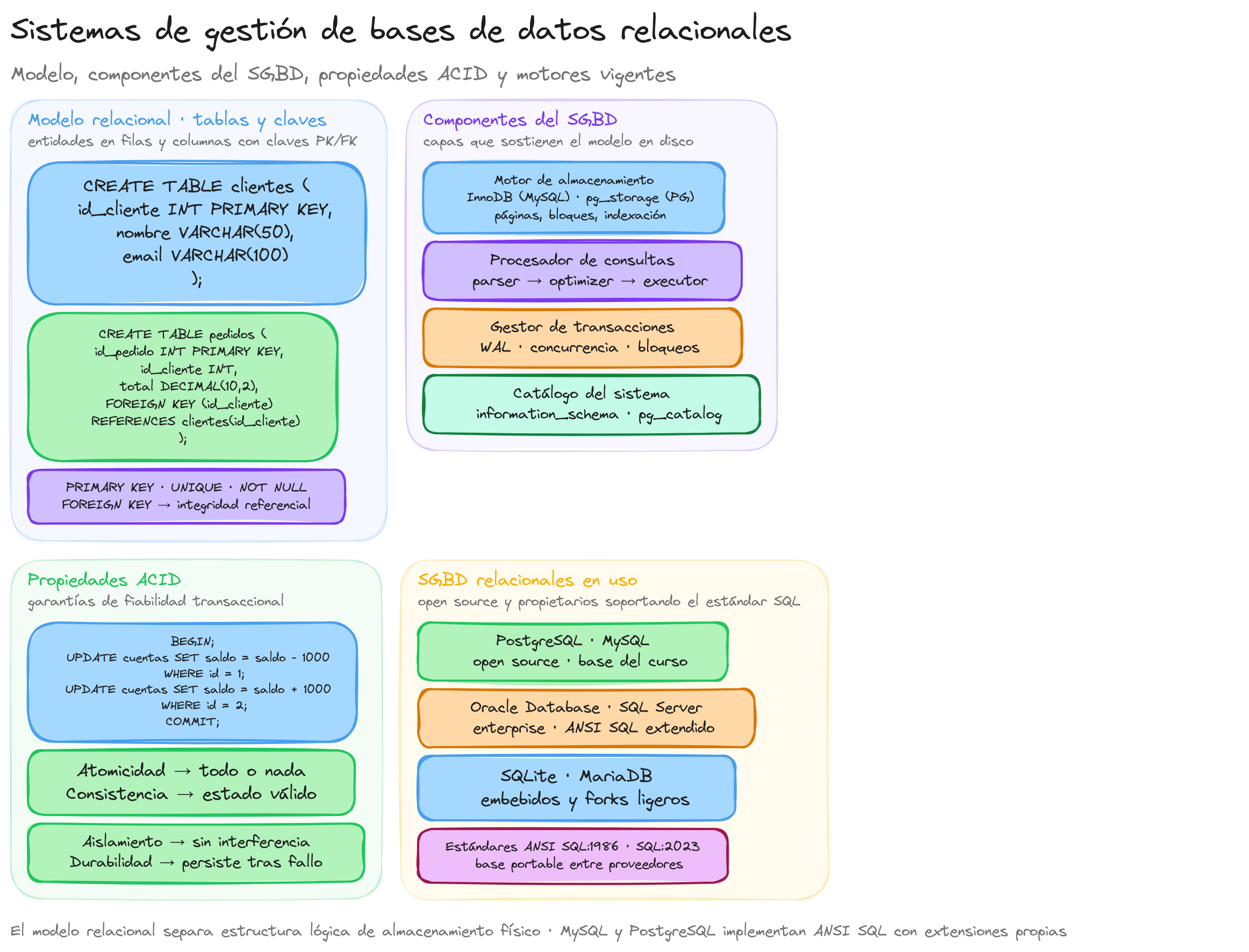
Una base de datos relacional almacena y organiza los datos en tablas bidimensionales compuestas por filas y columnas. Cada tabla representa una entidad específica del mundo real, como clientes, productos o pedidos. La estructura fundamental de estas tablas se caracteriza por:
-
Tablas (o relaciones): Estructuras rectangulares compuestas por filas y columnas donde se almacenan los datos. Por ejemplo, una tabla "Clientes" podría contener información sobre todas las personas que han realizado compras en una tienda.
-
Filas (o tuplas): Cada fila representa un registro individual dentro de la tabla. En una tabla de clientes, cada fila contendría la información completa de un cliente específico.
-
Columnas (o atributos): Definen las propiedades o características de la entidad que representa la tabla. En la tabla de clientes, las columnas podrían ser: ID, nombre, apellido, dirección y teléfono.
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nombre VARCHAR(50),
apellido VARCHAR(50),
email VARCHAR(100),
fecha_registro DATE
);
El modelo relacional se distingue por su capacidad para establecer relaciones entre tablas mediante claves. Existen dos tipos principales de claves:
-
Clave primaria (Primary Key): Identifica de manera única cada registro dentro de una tabla. No puede contener valores duplicados ni nulos. En el ejemplo anterior, "id_cliente" sería la clave primaria.
-
Clave foránea (Foreign Key): Establece una relación entre dos tablas al referenciar la clave primaria de otra tabla. Permite mantener la integridad referencial entre tablas relacionadas.
CREATE TABLE pedidos (
id_pedido INT PRIMARY KEY,
id_cliente INT,
fecha_pedido DATE,
total DECIMAL(10,2),
FOREIGN KEY (id_cliente) REFERENCES clientes(id_cliente)
);
En este ejemplo, la tabla "pedidos" tiene una clave foránea "id_cliente" que hace referencia a la clave primaria de la tabla "clientes", estableciendo así una relación entre ambas tablas.
Las bases de datos relacionales se rigen por un conjunto de propiedades ACID que garantizan la fiabilidad de las transacciones:
- Atomicidad: Las transacciones se ejecutan completamente o no se ejecutan en absoluto.
- Consistencia: Las transacciones mantienen la base de datos en un estado válido.
- Aislamiento: Las transacciones se ejecutan de forma aislada, sin interferir entre sí.
- Durabilidad: Una vez completada una transacción, sus cambios persisten incluso ante fallos del sistema.
El lenguaje SQL (Structured Query Language) es el estándar utilizado para interactuar con bases de datos relacionales. Permite realizar operaciones como:
- Consultar datos (SELECT)
- Insertar registros (INSERT)
- Actualizar información (UPDATE)
- Eliminar datos (DELETE)
- Definir estructuras (CREATE, ALTER, DROP)
-- Consulta básica que relaciona datos de dos tablas
SELECT c.nombre, c.apellido, p.fecha_pedido, p.total
FROM clientes c
JOIN pedidos p ON c.id_cliente = p.id_cliente
WHERE p.total > 100
ORDER BY p.fecha_pedido DESC;
Las bases de datos relacionales implementan el concepto de normalización, un proceso que organiza los datos para reducir la redundancia y mejorar la integridad. Este proceso se divide en varias formas normales (1NF, 2NF, 3NF, etc.) que establecen reglas progresivamente más estrictas sobre la estructura de las tablas.
Entre los sistemas de gestión de bases de datos relacionales más utilizados se encuentran MySQL y PostgreSQL (que utilizaremos en este curso), además de otros como Oracle Database, Microsoft SQL Server y SQLite. Cada uno tiene características específicas, pero todos implementan los principios fundamentales del modelo relacional.
El modelo relacional ofrece varias ventajas significativas:
- Estructura clara y predecible que facilita el diseño y mantenimiento
- Integridad de datos garantizada mediante restricciones y relaciones
- Flexibilidad en consultas gracias al lenguaje SQL
- Independencia de datos que separa la estructura lógica de la física
- Seguridad robusta con sistemas de permisos y control de acceso
Las bases de datos relacionales son especialmente adecuadas para aplicaciones donde la estructura de datos es conocida y estable, y donde la integridad de los datos es crítica, como sistemas bancarios, inventarios, gestión de recursos humanos o comercio electrónico.
Componentes de un SGBD
Un Sistema de Gestión de Bases de Datos (SGBD) es un conjunto de programas que permiten crear, mantener y utilizar bases de datos de manera eficiente. Estos sistemas actúan como intermediarios entre los usuarios y los datos almacenados, proporcionando herramientas para su manipulación y garantizando su integridad y seguridad.
Los SGBD modernos como MySQL y PostgreSQL están compuestos por varios componentes fundamentales que trabajan en conjunto para proporcionar un entorno completo de gestión de datos. Estos componentes se pueden clasificar en diferentes capas funcionales:
Motor de almacenamiento
El motor de almacenamiento es el componente responsable de gestionar cómo se guardan, recuperan y actualizan los datos en el disco físico. Este componente:
- Organiza los datos en estructuras físicas como archivos, páginas y bloques
- Implementa algoritmos de indexación para acelerar las búsquedas
- Gestiona el almacenamiento en caché para optimizar el rendimiento
MySQL, por ejemplo, ofrece varios motores de almacenamiento intercambiables como InnoDB (predeterminado), MyISAM, Memory y Archive, cada uno con características específicas:
CREATE TABLE productos (
id INT PRIMARY KEY,
nombre VARCHAR(100),
precio DECIMAL(10,2)
) ENGINE=InnoDB;
PostgreSQL, por su parte, utiliza un único motor de almacenamiento extensible que puede personalizarse mediante extensiones.
Procesador de consultas
El procesador de consultas es el cerebro del SGBD, encargado de interpretar, optimizar y ejecutar las instrucciones SQL. Este componente incluye:
- Analizador sintáctico: Verifica que las consultas SQL estén correctamente formuladas
- Optimizador de consultas: Determina la estrategia más eficiente para ejecutar cada consulta
- Evaluador de consultas: Ejecuta el plan generado y recupera los resultados
Cuando ejecutamos una consulta como:
SELECT p.nombre, c.nombre_categoria
FROM productos p
JOIN categorias c ON p.id_categoria = c.id
WHERE p.precio > 100;
El procesador analiza la consulta, determina el mejor plan de ejecución (qué tabla leer primero, qué índices utilizar, etc.) y finalmente ejecuta la operación.
Gestor de transacciones
El gestor de transacciones garantiza que las operaciones que modifican la base de datos se ejecuten de manera confiable, manteniendo las propiedades ACID. Sus componentes incluyen:
- Gestor de concurrencia: Controla el acceso simultáneo a los datos mediante bloqueos o control de versiones
- Gestor de recuperación: Mantiene registros de las operaciones (logs) para poder recuperar la base de datos tras fallos
- Gestor de bloqueos: Evita conflictos cuando múltiples usuarios intentan modificar los mismos datos
BEGIN;
UPDATE cuentas SET saldo = saldo - 1000 WHERE id = 1;
UPDATE cuentas SET saldo = saldo + 1000 WHERE id = 2;
COMMIT;
En este ejemplo, el gestor de transacciones garantiza que ambas actualizaciones se completen correctamente o ninguna se aplique, manteniendo la consistencia de los saldos.
Catálogo del sistema
El catálogo del sistema (también llamado diccionario de datos) almacena metadatos sobre la estructura de la base de datos:
- Definiciones de tablas, columnas y tipos de datos
- Información sobre índices y restricciones
- Estadísticas sobre los datos almacenados
- Permisos y roles de usuarios
En MySQL, esta información se almacena en la base de datos information_schema, mientras que PostgreSQL utiliza el esquema pg_catalog. Podemos consultar estos metadatos:
-- Consultar información sobre tablas en MySQL
SELECT table_name, engine, table_rows
FROM information_schema.tables
WHERE table_schema = 'mi_base_datos';
Gestor de seguridad
El gestor de seguridad controla el acceso a la base de datos mediante:
- Autenticación: Verifica la identidad de los usuarios
- Autorización: Determina qué operaciones puede realizar cada usuario
- Auditoría: Registra las acciones realizadas para su posterior revisión
-- Crear un usuario y asignar permisos en MySQL
CREATE USER 'aplicacion'@'localhost' IDENTIFIED BY 'contraseña';
GRANT SELECT, INSERT ON tienda.productos TO 'aplicacion'@'localhost';
Gestor de buffers
El gestor de buffers (o caché) mantiene en memoria las partes de la base de datos que se utilizan con frecuencia para minimizar las operaciones de lectura/escritura en disco, que son relativamente lentas. Este componente:
- Decide qué datos mantener en memoria y cuáles descartar
- Implementa algoritmos como LRU (Least Recently Used) para gestionar el espacio limitado
- Sincroniza los datos en memoria con el almacenamiento persistente
Tanto MySQL como PostgreSQL permiten configurar el tamaño de estos buffers:
-- Configurar el tamaño del buffer pool en MySQL
SET GLOBAL innodb_buffer_pool_size = 4294967296; -- 4GB
Interfaces de usuario
Los SGBD proporcionan diversas interfaces para interactuar con la base de datos:
- Interfaces de línea de comandos (CLI): Como
mysqlopsql - Interfaces gráficas (GUI): Como MySQL Workbench o pgAdmin
- APIs de programación: Conectores para lenguajes como PHP, Python, Java, etc.
# Conexión a MySQL desde línea de comandos
mysql -u usuario -p nombre_base_datos
# Conexión a PostgreSQL desde línea de comandos
psql -U usuario -d nombre_base_datos
Herramientas de administración
Los SGBD incluyen herramientas de administración para:
- Monitorización del rendimiento: Identificar cuellos de botella y optimizar consultas
- Copias de seguridad y restauración: Proteger los datos contra pérdidas
- Importación y exportación: Transferir datos entre sistemas
- Replicación y alta disponibilidad: Mantener copias sincronizadas de los datos
-- Ejemplo de backup en MySQL
mysqldump -u root -p mi_base_datos > backup.sql
-- Ejemplo de backup en PostgreSQL
pg_dump -U postgres mi_base_datos > backup.sql
Componentes de comunicación
Los componentes de comunicación permiten el acceso remoto a la base de datos a través de redes:
- Protocolos de comunicación cliente-servidor
- Gestión de conexiones y sesiones
- Compresión y cifrado de datos en tránsito
# Conexión remota a MySQL
mysql -h servidor.ejemplo.com -u usuario -p nombre_base_datos
# Conexión remota a PostgreSQL
psql -h servidor.ejemplo.com -U usuario -d nombre_base_datos
La arquitectura modular de los SGBD permite que estos componentes trabajen juntos de manera coordinada, proporcionando un sistema completo para la gestión de datos que combina rendimiento, seguridad y facilidad de uso. Tanto MySQL como PostgreSQL implementan estos componentes con enfoques ligeramente diferentes, pero ambos ofrecen todas las funcionalidades esenciales de un SGBD moderno.
Evolución histórica
La historia de las bases de datos y sus sistemas de gestión refleja la evolución tecnológica de la computación y las necesidades cambiantes de almacenamiento y procesamiento de información a lo largo de más de seis décadas. Este recorrido histórico nos permite entender mejor los fundamentos y el desarrollo de las tecnologías que utilizamos actualmente.
Los primeros sistemas de archivos (1950s-1960s)
En los albores de la informática, el almacenamiento de datos se realizaba mediante simples sistemas de archivos. Estos primeros sistemas presentaban importantes limitaciones:
- Datos almacenados en archivos planos sin estructura relacional
- Alta redundancia de información
- Dependencia entre los programas y la estructura física de los datos
- Acceso secuencial que dificultaba las búsquedas complejas
Durante esta época, las organizaciones desarrollaban sistemas de archivos a medida para cada aplicación, lo que generaba islas de información difíciles de integrar y mantener.
Primeros SGBD: modelos jerárquicos y de red (1960s-1970s)
La década de 1960 vio el nacimiento de los primeros verdaderos sistemas de gestión de bases de datos, basados principalmente en dos modelos:
-
Modelo jerárquico: Organizaba los datos en estructuras de árbol con relaciones padre-hijo. El ejemplo más representativo fue IMS (Information Management System) desarrollado por IBM en 1966 para el programa espacial Apollo. Este modelo:
-
Permitía relaciones uno-a-muchos
-
Facilitaba operaciones en registros relacionados
-
Limitaba la flexibilidad al imponer una estructura rígida
-
Modelo de red: Evolucionó para superar algunas limitaciones del modelo jerárquico. El estándar CODASYL (Conference on Data Systems Languages) de 1969 definió este modelo que:
-
Soportaba relaciones muchos-a-muchos
-
Utilizaba conjuntos para establecer asociaciones entre registros
-
Requería que los programadores conocieran la estructura física de los datos
Estos primeros sistemas representaron un avance significativo, pero aún requerían que los programadores navegaran manualmente por las estructuras de datos, lo que resultaba complejo y poco flexible.
La revolución relacional (1970s-1980s)
El verdadero punto de inflexión llegó en 1970 cuando Edgar F. Codd, investigador de IBM, publicó su histórico artículo "A Relational Model of Data for Large Shared Data Banks". Este trabajo sentó las bases teóricas del modelo relacional, que revolucionaría la industria con conceptos fundamentales:
- Organización de datos en tablas (relaciones) bidimensionales
- Independencia entre la estructura lógica y física de los datos
- Uso de álgebra relacional como fundamento matemático
- Introducción del concepto de normalización
Los primeros prototipos de SGBD relacionales aparecieron poco después:
- System R de IBM (1974-1979): Primer sistema que implementó SQL
- Ingres de la Universidad de Berkeley (1974-1977): Base para posteriores sistemas comerciales
La década de 1980 vio la comercialización y adopción generalizada de los SGBD relacionales:
- Oracle lanzó su primera versión comercial en 1979
- DB2 de IBM se introdujo en 1983
- SQL Server apareció inicialmente en 1989 (desarrollado por Sybase y Microsoft)
-- Ejemplo de consulta SQL básica (circa 1980s)
SELECT EMPLEADO.NOMBRE, DEPARTAMENTO.NOMBRE
FROM EMPLEADO, DEPARTAMENTO
WHERE EMPLEADO.DEPT_ID = DEPARTAMENTO.ID;
Esta época también vio la estandarización del lenguaje SQL (inicialmente llamado SEQUEL), que se convertiría en el estándar universal para interactuar con bases de datos relacionales. El primer estándar SQL (SQL-86) fue adoptado por ANSI en 1986 y por ISO en 1987.
Madurez y diversificación (1990s-2000s)
Durante los años 90 y principios de los 2000, los SGBD relacionales maduraron y se diversificaron:
- MySQL fue lanzado en 1995, enfocándose en rendimiento y facilidad de uso
- PostgreSQL evolucionó a partir de Postgres en 1996, destacando por su conformidad con estándares
- Aparecieron sistemas de código abierto que democratizaron el acceso a esta tecnología
Esta época trajo importantes avances técnicos:
- Mejoras en optimización de consultas
- Soporte para procedimientos almacenados y triggers
- Capacidades de replicación y alta disponibilidad
- Integración de tipos de datos complejos (XML, JSON, espaciales)
-- Procedimiento almacenado (característica de los 90s)
CREATE PROCEDURE actualizar_salario(emp_id INT, incremento DECIMAL)
BEGIN
UPDATE empleados
SET salario = salario + incremento
WHERE id = emp_id;
END;
También fue la época de los data warehouses y sistemas OLAP (Online Analytical Processing), que extendieron las capacidades analíticas de las bases de datos relacionales para el soporte a la toma de decisiones.
La era NoSQL y NewSQL (2000s-2010s)
El crecimiento exponencial de Internet y las aplicaciones web generó nuevos desafíos que impulsaron la aparición de alternativas al modelo relacional:
-
Bases de datos NoSQL: Surgieron para abordar limitaciones de escalabilidad y flexibilidad:
-
Bases de datos de documentos (MongoDB, 2009)
-
Almacenes clave-valor (Redis, 2009)
-
Bases de datos columnares (Cassandra, 2008)
-
Bases de datos de grafos (Neo4j, 2007)
-
Sistemas NewSQL: Intentaron combinar la escalabilidad de NoSQL con las garantías ACID de los sistemas relacionales:
-
Google Spanner
-
CockroachDB
-
VoltDB
Durante este período, los SGBD relacionales tradicionales no permanecieron estáticos, sino que evolucionaron para incorporar características inspiradas en NoSQL:
- MySQL añadió el motor InnoDB como predeterminado (2010)
- PostgreSQL incorporó soporte para datos JSON (2012) y búsqueda de texto completo
-- PostgreSQL con soporte JSON (2010s)
CREATE TABLE productos (
id SERIAL PRIMARY KEY,
datos JSONB
);
INSERT INTO productos (datos)
VALUES ('{"nombre": "Laptop", "precio": 999.99, "tags": ["electrónica", "portátil"]}');
La era de la nube y los datos masivos (2010s-presente)
La última década ha estado marcada por la computación en la nube y el manejo de grandes volúmenes de datos:
- Bases de datos como servicio (DBaaS): Amazon RDS, Azure SQL Database, Google Cloud SQL
- Sistemas diseñados para big data: Hadoop, Spark, Snowflake
- Bases de datos distribuidas con replicación global
- Integración de capacidades de machine learning y análisis en tiempo real
Los SGBD relacionales tradicionales han seguido evolucionando:
- MySQL 8.0 (2018) añadió características como roles, transacciones atómicas y mejoras en JSON
- PostgreSQL ha incorporado particionamiento declarativo, paralelismo de consultas y mejoras en replicación
-- Particionamiento en PostgreSQL moderno
CREATE TABLE mediciones (
id SERIAL,
fecha_hora TIMESTAMP,
valor DECIMAL
) PARTITION BY RANGE (fecha_hora);
CREATE TABLE mediciones_2023 PARTITION OF mediciones
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
Tendencias actuales y futuro
El panorama actual de los SGBD muestra varias tendencias claras:
- Convergencia entre paradigmas relacionales y NoSQL
- Énfasis en escalabilidad horizontal y arquitecturas distribuidas
- Integración con tecnologías de IA y aprendizaje automático
- Optimización para entornos cloud-native y contenedores
- Mayor atención a la seguridad y privacidad de datos
MySQL y PostgreSQL, los sistemas que utilizaremos en este curso, han demostrado una notable capacidad de adaptación a lo largo de esta evolución histórica. Ambos han incorporado características modernas mientras mantienen la solidez del modelo relacional, lo que explica su continua relevancia y popularidad.
Esta evolución histórica nos muestra que, aunque han surgido numerosas alternativas, los principios fundamentales del modelo relacional siguen siendo válidos y valiosos. Al mismo tiempo, los SGBD modernos han sabido adaptarse e incorporar nuevas capacidades para responder a las cambiantes necesidades de almacenamiento y procesamiento de datos.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la estructura y principios fundamentales de las bases de datos relacionales. Identificar los componentes esenciales de un sistema de gestión de bases de datos (SGBD). Conocer el lenguaje SQL y su uso básico para manipular datos y estructuras. Analizar la evolución histórica de las bases de datos y su impacto en la tecnología actual. Reconocer las ventajas y aplicaciones del modelo relacional en entornos reales.