Del SQL operacional al SQL de producción
Casi todo profesional que trabaja con bases de datos ha pasado por una primera fase del lenguaje: escribir SELECT, INSERT, UPDATE y DELETE con WHERE, combinar tablas con JOIN, agrupar con GROUP BY y obtener un resultado correcto en pruebas locales. A esto lo llamamos SQL operacional: cubre el flujo CRUD habitual de cualquier aplicación con un volumen moderado de datos y poca concurrencia.
El SQL de producción empieza cuando esos mismos patrones dejan de bastar. Aparece, entre otras, cuando se da alguna de estas situaciones reales:
- 1. Escala de datos: tablas con decenas o cientos de millones de filas donde un
SELECTsin índice tarda minutos en lugar de milisegundos. - 2. Concurrencia: cientos de transacciones por segundo escribiendo sobre las mismas filas, con riesgo de bloqueos mutuos y resultados inconsistentes según el nivel de aislamiento.
- 3. Análisis sobre los mismos datos transaccionales: directivos que piden informes con subtotales jerárquicos, comparativas año contra año, percentiles o medias móviles sin cargar los datos en una herramienta externa.
- 4. Tipos no tabulares: documentos
JSONcon esquema variable, búsquedas textuales, datos geoespaciales, vectores semánticos paraRAGo series temporales con miles de medidas por minuto. - 5. Disponibilidad y recuperación: requisitos contractuales de
99,99 %de uptime, tolerancia a fallos del nodo primario, recuperación a un punto exacto del tiempo tras un incidente. - 6. Aislamiento entre clientes: aplicaciones multi-tenant donde una consulta no debe nunca filtrar datos del tenant equivocado.
Resolver estas situaciones con SQL es lo que distingue a un perfil avanzado. Cada una toca una capa diferente: la capa de consulta, la capa de concurrencia, la capa física y la capa de operación. Este curso recorre las cuatro.
Definición operativa: SQL avanzado no es escribir consultas más largas; es conocer las herramientas adecuadas para cada problema y leer el motor lo suficiente como para elegir.
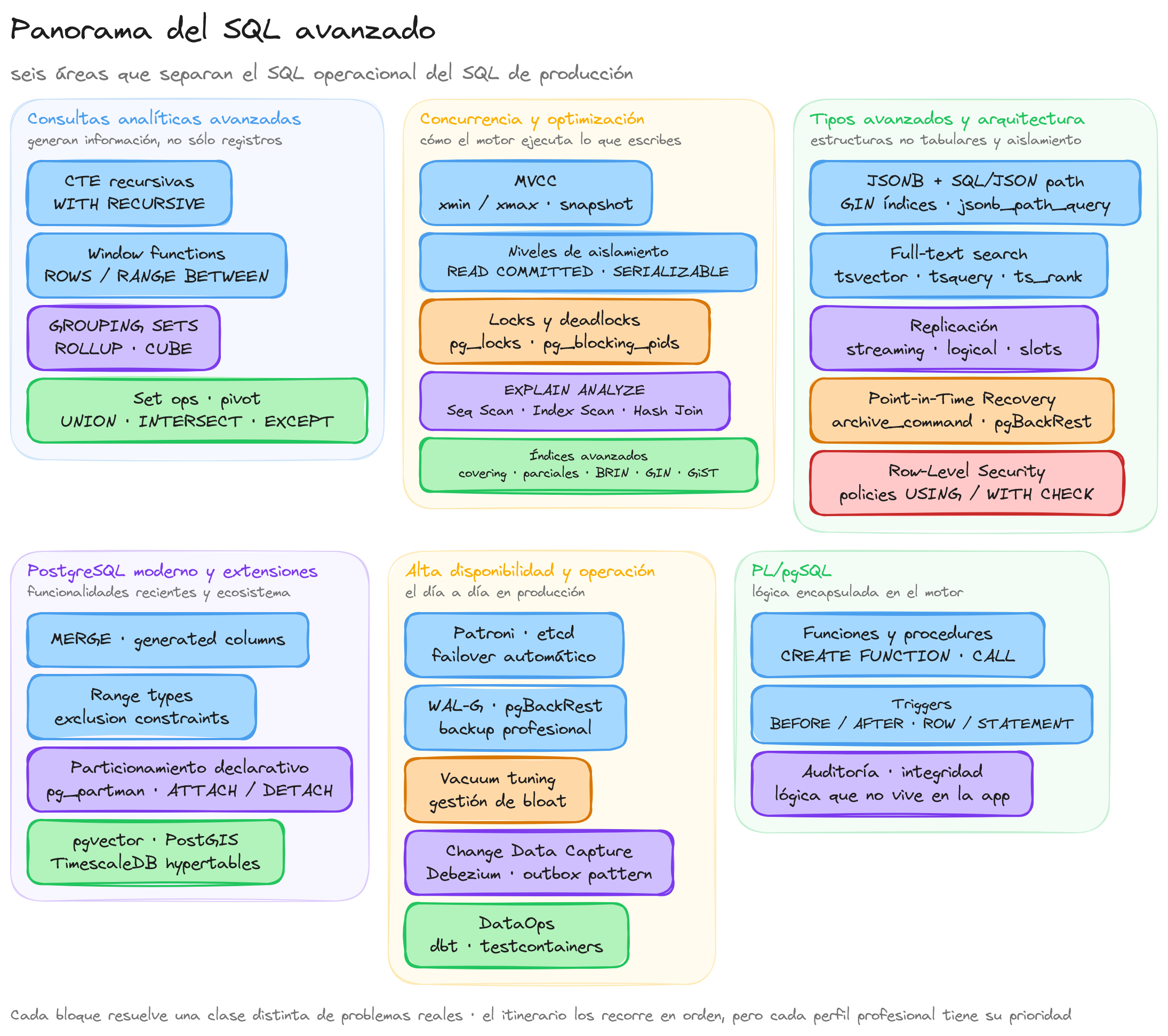
Las seis áreas del itinerario
El curso se organiza en seis áreas. Cada una resuelve una clase de problemas distinta y exige un tipo de conocimiento diferente.
graph LR
A[SQL avanzado] --> B[Consultas analíticas]
A --> C[Concurrencia y optimización]
A --> D[Tipos avanzados y arquitectura]
A --> E[PostgreSQL moderno]
A --> F[Alta disponibilidad y CDC]
A --> G[PL/pgSQL]
Consultas analíticas avanzadas
El primer bloque va sobre consultas que producen información, no sólo registros. Aquí entran las CTE recursivas para resolver jerarquías (organigramas, árboles de categorías, listas de materiales), las funciones de ventana con frames explícitos para medias móviles, totales acumulados y rankings, y las extensiones de agregación GROUPING SETS, ROLLUP y CUBE para informes con subtotales jerárquicos.
También entran las operaciones de conjunto (UNION, INTERSECT, EXCEPT) y el pivotado de filas a columnas. Un equipo de reporting que domina este bloque puede entregar informes ejecutivos directamente desde la base de datos sin pasar por una herramienta intermedia.
Concurrencia y optimización
El segundo bloque baja un nivel: cómo se comportan las consultas cuando muchas se ejecutan a la vez. Aborda MVCC (Multi-Version Concurrency Control) por dentro, los niveles de aislamiento del estándar ISO con los fenómenos que evita cada uno, los tipos de lock y la prevención de deadlocks.
La parte de optimización enseña a leer planes de ejecución con EXPLAIN ANALYZE, distinguir un Seq Scan de un Index Scan o un Bitmap Heap Scan, y elegir entre tipos de índice más allá del B-tree: covering, parciales, funcionales, BRIN para series temporales, GIN para JSONB y full-text, GiST para datos geoespaciales y rangos.
Tipos avanzados y arquitectura enterprise
El tercer bloque trata las estructuras de datos no tabulares y sus implicaciones de arquitectura. JSONB en PostgreSQL con su propio lenguaje de path (SQL/JSON), full-text search nativo con ranking por relevancia, replicación streaming y lógica, Point-in-Time Recovery con archivado de WAL, y Row-Level Security como mecanismo de aislamiento multi-tenant a nivel de motor.
Quien diseña una plataforma
SaaSB2B de cierta complejidad usará al menos cuatro de estas técnicas. Saber cuándo aplicar cada una es trabajo de arquitecto.
PostgreSQL moderno y extensiones
El cuarto bloque es específico de PostgreSQL reciente. Cubre la sentencia MERGE del estándar SQL:2003, las columnas generadas, los range types con exclusion constraints (reservas sin solapamientos), el particionamiento declarativo y un repaso de extensiones esenciales: pgvector para búsqueda semántica con LLMs, PostGIS para datos geoespaciales y TimescaleDB para series temporales con hypertables.
Alta disponibilidad, CDC y operación en producción
El quinto bloque es de operación pura: failover automático con Patroni, backups profesionales con WAL-G y pgBackRest, vacuum tuning y gestión de bloat, Change Data Capture con Debezium y el outbox pattern, migraciones de esquema sin downtime con la técnica expand-contract y herramientas de DataOps como dbt y testcontainers-postgres para el ciclo CI/CD.
Programación con PL/pgSQL
El sexto bloque cierra el curso con funciones, procedures y triggers en PL/pgSQL. Es la capa que permite encapsular lógica de negocio dentro de la base de datos cuando la aplicación no es el lugar correcto: auditoría automática, cálculos derivados, integridad referencial avanzada o tareas batch que se ejecutan dentro del motor.
Dónde se aplica cada bloque en el día a día
El curso se completa en su totalidad: las seis áreas son competencias profesionales esperables de un perfil senior, y todas se evalúan en el proyecto integrador final. La distribución por perfil que viene a continuación no es un mapa de "qué estudiar y qué saltar", es una orientación de dónde aparecerá con más frecuencia cada bloque en el trabajo cotidiano del alumno una vez termine el curso.
| Bloque | Aparece en el día a día de... |
|--------|-------------------------------|
| Consultas analíticas avanzadas | Backend senior que escribe informes y queries de producto. Data engineer que construye dashboards y modelos analíticos. |
| Concurrencia y optimización | Backend senior que diagnostica consultas lentas. DBA que mantiene el motor sano y lee planes de ejecución todos los días. |
| Tipos avanzados y arquitectura | Arquitecto que diseña una plataforma SaaS multi-tenant. Data engineer que indexa JSONB o configura full-text. DBA que opera replicación y PITR. |
| PostgreSQL moderno | Equipo que adopta MERGE, range types o extensiones específicas (pgvector, PostGIS, TimescaleDB) en proyectos nuevos. |
| Alta disponibilidad y operación | DBA y SRE responsables del uptime, backups y CDC. Data engineer que mantiene pipelines con Debezium o dbt. |
| PL/pgSQL | Cualquier equipo que decida encapsular auditoría, integridad o lógica batch dentro del motor en lugar de en la aplicación. |
Un backend senior se cruzará con
EXPLAIN ANALYZEcien veces por una conPatroni, pero conviene haber visto las dos para entender el mapa completo del motor. La fortaleza profesional viene de conocer las seis áreas: el énfasis luego lo marca cada proyecto.
La lección siguiente comprueba que los prerequisitos del nivel intermedio están en su sitio antes de entrar en el material avanzado.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Identificar las seis áreas del SQL avanzado y los problemas de producción que resuelve cada una. Distinguir el SQL operacional del SQL de producción. Conocer en qué tipo de proyectos profesionales se aplica cada área.