Atomicidad
flowchart TB
Tx["Transacción: BEGIN"] --> Pilares{Garantías ACID}
Pilares --> Atom["Atomicidad: todo o nada con COMMIT o ROLLBACK"]
Pilares --> Cons["Consistencia: respeta restricciones e integridad"]
Pilares --> Iso["Aislamiento: niveles según concurrencia"]
Pilares --> Dur["Durabilidad: WAL en disco tras COMMIT"]
Iso --> RU["READ UNCOMMITTED: lecturas sucias"]
Iso --> RC["READ COMMITTED: por defecto en PostgreSQL 17"]
Iso --> RR["REPEATABLE READ: por defecto en MySQL"]
Iso --> Ser["SERIALIZABLE: máxima coherencia"]
RU --> Anom["Anomalías: dirty, non-repeatable, phantom"]
RC --> Anom
RR --> Anom
Ser --> Sin[Sin anomalías observables]
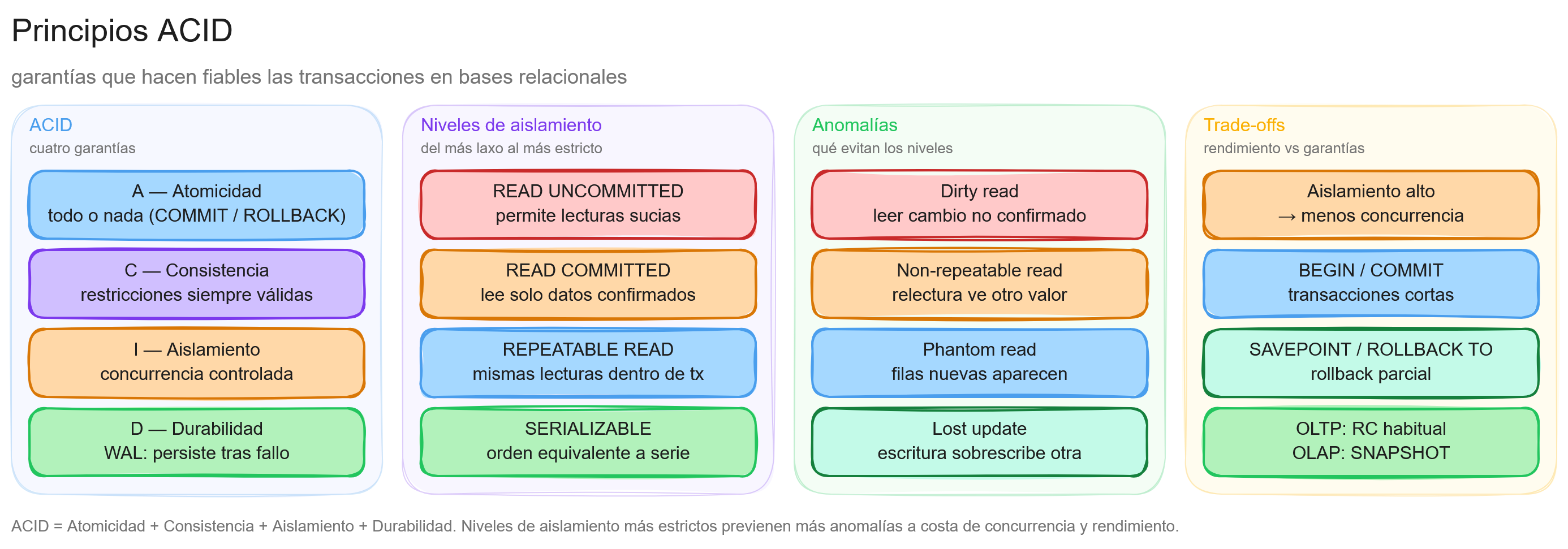
La atomicidad constituye el primer pilar de las propiedades ACID en sistemas de bases de datos relacionales. Este concepto fundamental garantiza que las operaciones en una base de datos se ejecuten como una unidad indivisible, asegurando la integridad de los datos incluso ante fallos del sistema.
En esencia, la atomicidad establece que una transacción debe tratarse como una unidad atómica de trabajo. Esto significa que todas las operaciones dentro de una transacción deben completarse con éxito, o ninguna de ellas debe tener efecto sobre la base de datos. No existen estados intermedios o parciales: la transacción se ejecuta por completo o no se ejecuta en absoluto.
Funcionamiento de la atomicidad
Cuando trabajamos con transacciones en MySQL o PostgreSQL, la atomicidad se implementa mediante un sistema de confirmación y reversión. Este mecanismo funciona de la siguiente manera:
- Al iniciar una transacción, la base de datos crea un punto de guardado (savepoint)
- Todas las operaciones se ejecutan de manera provisional
- Si todas las operaciones tienen éxito, se realiza un COMMIT que confirma los cambios
- Si alguna operación falla, se ejecuta un ROLLBACK que revierte todos los cambios
Veamos un ejemplo práctico en MySQL:
START TRANSACTION;
UPDATE cuentas SET saldo = saldo - 1000 WHERE id_cuenta = 123;
UPDATE cuentas SET saldo = saldo + 1000 WHERE id_cuenta = 456;
COMMIT;
En este ejemplo, estamos transfiriendo 1000 unidades de la cuenta 123 a la cuenta 456. La atomicidad garantiza que ambas operaciones se ejecuten juntas o ninguna se ejecute. Si ocurriera un fallo después de la primera actualización pero antes del COMMIT, el sistema realizaría automáticamente un ROLLBACK, dejando la base de datos en su estado original.
Atomicidad en situaciones de error
La atomicidad es especialmente importante cuando ocurren errores inesperados. Consideremos un escenario donde una transacción falla:
START TRANSACTION;
UPDATE inventario SET cantidad = cantidad - 5 WHERE id_producto = 10;
-- Supongamos que aquí ocurre un error (por ejemplo, una restricción de clave foránea)
INSERT INTO pedidos (id_producto, cantidad) VALUES (10, 5);
ROLLBACK; -- Se ejecuta automáticamente si hay un error
En este caso, si la inserción en la tabla pedidos falla por alguna razón, la atomicidad garantiza que la actualización previa en la tabla inventario también se revierta. Esto evita inconsistencias como la reducción del inventario sin el correspondiente registro del pedido.
Implementación en MySQL y PostgreSQL
Tanto MySQL como PostgreSQL implementan la atomicidad de manera similar, aunque con algunas diferencias técnicas:
-
MySQL (InnoDB): Utiliza un registro de deshacer (undo log) que almacena la información necesaria para revertir operaciones. Cuando se inicia una transacción, InnoDB registra el estado original de los datos antes de modificarlos.
-
PostgreSQL: Implementa la atomicidad mediante un sistema de control de concurrencia multiversión (MVCC) que mantiene múltiples versiones de los datos. Esto permite que las transacciones trabajen con una "instantánea" coherente de la base de datos.
Veamos cómo se configura el comportamiento de las transacciones en PostgreSQL:
-- Verificar el nivel de aislamiento actual
SHOW transaction_isolation;
-- Iniciar una transacción explícita
BEGIN;
-- Realizar operaciones
INSERT INTO clientes (nombre, email) VALUES ('Ana García', 'ana@ejemplo.com');
UPDATE clientes SET tipo = 'Premium' WHERE email = 'ana@ejemplo.com';
-- Confirmar cambios
COMMIT;
Atomicidad y control de errores
Para manejar adecuadamente la atomicidad en aplicaciones reales, es importante implementar un control de errores apropiado. En MySQL, podemos utilizar transacciones con manejo de excepciones:
START TRANSACTION;
-- Guardar un punto de restauración
SAVEPOINT antes_operaciones;
-- Intentar realizar operaciones
UPDATE productos SET stock = stock - 1 WHERE id = 101;
INSERT INTO ventas (producto_id, cantidad) VALUES (101, 1);
-- Si todo va bien, confirmar
COMMIT;
-- En caso de error (en un procedimiento almacenado o aplicación)
-- ROLLBACK TO antes_operaciones;
-- ROLLBACK;
El uso de SAVEPOINT permite crear puntos de restauración intermedios dentro de una transacción, ofreciendo un control más granular sobre qué operaciones revertir en caso de error.
Limitaciones de la atomicidad
Es importante entender que la atomicidad tiene ciertas limitaciones:
- No garantiza que las transacciones concurrentes no interfieran entre sí (eso lo maneja el aislamiento)
- No asegura que los datos cumplan con las reglas de negocio (eso corresponde a la consistencia)
- No garantiza que los cambios sobrevivan a fallos del sistema (eso lo proporciona la durabilidad)
La atomicidad simplemente asegura que cada transacción se ejecute completamente o no tenga ningún efecto.
Impacto en el rendimiento
Implementar la atomicidad tiene un costo en rendimiento, ya que requiere:
- Mantener registros adicionales (logs de transacciones)
- Realizar operaciones de escritura adicionales
- Gestionar bloqueos o versiones múltiples de datos
Sin embargo, este costo es generalmente aceptable considerando los beneficios en términos de integridad de datos. En sistemas de alto rendimiento, es posible ajustar la configuración para equilibrar la seguridad de las transacciones con el rendimiento:
-- En MySQL, configurar transacciones autocommit (menos seguro pero más rápido)
SET autocommit = 1;
-- En PostgreSQL, usar transacciones de solo lectura cuando sea posible
BEGIN READ ONLY;
SELECT * FROM productos WHERE categoria = 'Electrónica';
COMMIT;
La atomicidad es solo el primer componente de las propiedades ACID, pero establece la base fundamental para garantizar que las operaciones en la base de datos mantengan la integridad de los datos incluso en situaciones adversas.
Consistencia
La consistencia representa el segundo pilar fundamental de las propiedades ACID en sistemas de bases de datos relacionales. Este principio garantiza que una transacción solo pueda llevar la base de datos de un estado válido a otro igualmente válido, preservando la integridad de los datos según las reglas definidas.
A diferencia de la atomicidad (que se centra en la indivisibilidad de las operaciones), la consistencia se enfoca en mantener la correctitud lógica de los datos. Esto significa que todas las restricciones, reglas de negocio y relaciones entre datos deben respetarse antes y después de cada transacción.
Mecanismos de consistencia
La consistencia se implementa mediante varios mecanismos que trabajan en conjunto:
- Restricciones de integridad: Reglas que definen qué datos son válidos
- Disparadores (triggers): Código que se ejecuta automáticamente ante ciertos eventos
- Transacciones: Unidades de trabajo que mantienen la base de datos consistente
En MySQL y PostgreSQL, podemos definir diferentes tipos de restricciones para mantener la consistencia:
CREATE TABLE pedidos (
id_pedido INT PRIMARY KEY,
id_cliente INT NOT NULL,
total DECIMAL(10,2) CHECK (total > 0),
fecha_pedido DATE NOT NULL,
FOREIGN KEY (id_cliente) REFERENCES clientes(id_cliente)
);
En este ejemplo, hemos definido varias restricciones:
- La clave primaria
id_pedidogarantiza que cada pedido tenga un identificador único - La restricción
NOT NULLasegura que ciertos campos siempre tengan un valor - La restricción
CHECKverifica que el total del pedido sea siempre positivo - La clave foránea
FOREIGN KEYasegura que cada pedido esté asociado a un cliente existente
Consistencia en transacciones
Cuando ejecutamos una transacción, el sistema de gestión de bases de datos (SGBD) verifica que todas las restricciones se cumplan antes de confirmar los cambios. Veamos un ejemplo:
START TRANSACTION;
-- Insertar un nuevo pedido
INSERT INTO pedidos (id_pedido, id_cliente, total, fecha_pedido)
VALUES (1001, 500, 1250.75, '2023-11-15');
-- Actualizar el inventario
UPDATE inventario SET stock = stock - 5 WHERE id_producto = 101;
COMMIT;
Si el cliente con id_cliente = 500 no existe, o si el stock resultante fuera negativo (suponiendo que exista una restricción CHECK (stock >= 0)), la transacción fallaría y se realizaría un rollback automático, manteniendo así la consistencia de la base de datos.
Diferencias entre MySQL y PostgreSQL
Aunque ambos sistemas implementan la consistencia, existen algunas diferencias importantes:
-
PostgreSQL tiene un enfoque más estricto hacia la consistencia y ofrece un conjunto más amplio de tipos de restricciones, incluyendo restricciones de exclusión y restricciones diferidas.
-
MySQL (con InnoDB) implementa la mayoría de las restricciones, pero históricamente ha sido más flexible en ciertos aspectos. Por ejemplo, en versiones anteriores, las restricciones CHECK se analizaban pero no se aplicaban.
Veamos un ejemplo de una restricción más avanzada en PostgreSQL:
-- Restricción única que permite solo una reserva por sala y franja horaria
CREATE TABLE reservas (
id_reserva SERIAL PRIMARY KEY,
id_sala INT NOT NULL,
fecha DATE NOT NULL,
hora_inicio TIME NOT NULL,
hora_fin TIME NOT NULL,
CONSTRAINT horarios_no_solapados EXCLUDE USING gist
(id_sala WITH =,
tsrange(fecha + hora_inicio, fecha + hora_fin) WITH &&)
);
Esta restricción EXCLUDE, disponible en PostgreSQL, garantiza que no haya reservas solapadas para la misma sala.
Consistencia y reglas de negocio
La consistencia va más allá de las restricciones básicas y abarca también las reglas de negocio complejas. Estas reglas pueden implementarse mediante triggers:
CREATE TRIGGER verificar_limite_credito
BEFORE INSERT OR UPDATE ON pedidos
FOR EACH ROW
BEGIN
DECLARE credito_disponible DECIMAL(10,2);
SELECT limite_credito - SUM(total) INTO credito_disponible
FROM clientes c
LEFT JOIN pedidos p ON c.id_cliente = p.id_cliente
WHERE c.id_cliente = NEW.id_cliente
GROUP BY c.limite_credito;
IF NEW.total > credito_disponible THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'El pedido excede el límite de crédito del cliente';
END IF;
END;
Este trigger en MySQL verifica que un nuevo pedido no exceda el límite de crédito disponible del cliente, manteniendo así la consistencia según las reglas de negocio establecidas.
Consistencia eventual vs. consistencia inmediata
En sistemas de bases de datos distribuidos, existen diferentes modelos de consistencia:
- Consistencia inmediata: Garantiza que todos los nodos ven los mismos datos al mismo tiempo
- Consistencia eventual: Permite temporalmente inconsistencias, pero garantiza que eventualmente todos los nodos convergerán al mismo estado
MySQL y PostgreSQL, como bases de datos relacionales tradicionales, implementan por defecto la consistencia inmediata dentro de una única instancia. Sin embargo, en configuraciones de replicación, pueden presentar características de consistencia eventual:
-- En MySQL, configurar replicación con consistencia relajada
SET GLOBAL binlog_format = 'ROW';
SET GLOBAL sync_binlog = 0;
-- En PostgreSQL, configurar replicación asíncrona
-- (en postgresql.conf)
-- synchronous_commit = off
Impacto de la consistencia en el diseño de aplicaciones
Mantener la consistencia tiene implicaciones importantes en el diseño de aplicaciones:
- Es preferible implementar restricciones a nivel de base de datos en lugar de solo en la aplicación
- Las transacciones deben diseñarse cuidadosamente para mantener la consistencia
- En sistemas distribuidos, puede ser necesario elegir entre consistencia y disponibilidad
-- Ejemplo de transacción que mantiene la consistencia en una transferencia bancaria
START TRANSACTION;
-- Verificar que hay fondos suficientes
SELECT @saldo := saldo FROM cuentas WHERE id_cuenta = 123;
IF @saldo < 1000 THEN
ROLLBACK;
SELECT 'Fondos insuficientes' AS mensaje;
ELSE
-- Realizar la transferencia
UPDATE cuentas SET saldo = saldo - 1000 WHERE id_cuenta = 123;
UPDATE cuentas SET saldo = saldo + 1000 WHERE id_cuenta = 456;
COMMIT;
SELECT 'Transferencia exitosa' AS mensaje;
END IF;
La consistencia es un componente crucial que trabaja en conjunto con la atomicidad para garantizar la integridad de los datos. Mientras que la atomicidad asegura que las operaciones se completen o se reviertan en su totalidad, la consistencia garantiza que esas operaciones mantengan la base de datos en un estado válido según todas las reglas definidas.
Aislamiento y durabilidad
Las propiedades de aislamiento y durabilidad completan el acrónimo ACID, proporcionando garantías fundamentales sobre cómo las transacciones interactúan entre sí y cómo persisten los datos en el tiempo. Mientras que la atomicidad y consistencia se centran en la integridad de una transacción individual, el aislamiento y la durabilidad abordan aspectos críticos de concurrencia y persistencia.
Aislamiento (Isolation)
El aislamiento garantiza que las transacciones concurrentes se ejecuten de manera independiente, como si cada una fuera la única operación en el sistema. Esta propiedad evita que las transacciones interfieran entre sí, incluso cuando se ejecutan simultáneamente.
En un entorno multiusuario como una base de datos, múltiples transacciones pueden ejecutarse al mismo tiempo. Sin un adecuado nivel de aislamiento, podrían surgir varios problemas:
- Lecturas sucias: Una transacción lee datos que otra transacción ha modificado pero aún no ha confirmado
- Lecturas no repetibles: Una transacción relee datos y encuentra que han sido modificados por otra transacción
- Lecturas fantasma: Una transacción ejecuta una consulta que devuelve un conjunto de filas, pero una consulta posterior devuelve filas adicionales debido a cambios realizados por otra transacción
MySQL y PostgreSQL implementan diferentes niveles de aislamiento para equilibrar la concurrencia con la consistencia:
-- Establecer el nivel de aislamiento en MySQL
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- Establecer el nivel de aislamiento en PostgreSQL
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Los niveles de aislamiento estándar, de menor a mayor restricción, son:
- READ UNCOMMITTED: Permite lecturas sucias, no repetibles y fantasma
- READ COMMITTED: Evita lecturas sucias, pero permite lecturas no repetibles y fantasma
- REPEATABLE READ: Evita lecturas sucias y no repetibles, pero permite lecturas fantasma
- SERIALIZABLE: Evita todos los problemas de concurrencia, proporcionando el máximo aislamiento
Veamos un ejemplo práctico de cómo el nivel de aislamiento afecta a las transacciones concurrentes:
-- Transacción 1 (en una sesión)
START TRANSACTION;
UPDATE productos SET precio = precio * 1.10 WHERE categoria = 'Electrónica';
-- (No se ha ejecutado COMMIT todavía)
-- Transacción 2 (en otra sesión simultánea)
START TRANSACTION;
SELECT AVG(precio) FROM productos WHERE categoria = 'Electrónica';
COMMIT;
Con nivel READ UNCOMMITTED, la Transacción 2 vería los precios actualizados aunque la Transacción 1 no haya hecho COMMIT. Con READ COMMITTED o superior, la Transacción 2 vería los precios originales.
Control de concurrencia en MySQL y PostgreSQL
Ambos sistemas utilizan diferentes mecanismos para implementar el aislamiento:
-
MySQL (InnoDB) utiliza principalmente un sistema de bloqueo de filas combinado con un control de concurrencia multiversión (MVCC) para niveles superiores a READ UNCOMMITTED.
-
PostgreSQL implementa un sistema de MVCC puro, donde cada transacción ve una "instantánea" de la base de datos en el momento que comenzó, independientemente de los cambios no confirmados realizados por otras transacciones.
-- Ejemplo de bloqueo explícito en MySQL
START TRANSACTION;
SELECT * FROM inventario WHERE id_producto = 101 FOR UPDATE;
-- Esto bloquea la fila para otras transacciones hasta que esta termine
UPDATE inventario SET stock = stock - 1 WHERE id_producto = 101;
COMMIT;
El bloqueo FOR UPDATE es útil cuando necesitamos garantizar que nadie más modifique los datos mientras procesamos una transacción crítica.
Durabilidad (Durability)
La durabilidad garantiza que una vez que una transacción ha sido confirmada (COMMIT), sus cambios permanecerán en la base de datos incluso ante fallos del sistema como cortes de energía o bloqueos. Esta propiedad asegura que los datos no se pierdan una vez confirmados.
La durabilidad se implementa principalmente mediante:
- Registros de transacciones (logs): Archivos que registran todas las operaciones antes de aplicarlas a los datos
- Técnicas de almacenamiento persistente: Mecanismos para escribir datos en medios no volátiles
- Procedimientos de recuperación: Métodos para restaurar la base de datos a un estado consistente después de un fallo
Tanto MySQL como PostgreSQL implementan la durabilidad, aunque con algunas diferencias técnicas:
-- Configuración de durabilidad en MySQL
SET GLOBAL innodb_flush_log_at_trx_commit = 1; -- Máxima durabilidad
SET GLOBAL sync_binlog = 1; -- Sincronización del binlog
-- Configuración de durabilidad en PostgreSQL (en postgresql.conf)
-- fsync = on
-- synchronous_commit = on
Con estas configuraciones, ambos sistemas garantizan que los datos confirmados sobrevivirán a fallos del sistema, aunque con un impacto en el rendimiento.
Compromiso entre rendimiento y durabilidad
La durabilidad completa tiene un costo en rendimiento, ya que requiere operaciones de E/S sincrónicas. Tanto MySQL como PostgreSQL permiten ajustar este equilibrio:
-- MySQL: Reducir durabilidad para mejorar rendimiento
SET GLOBAL innodb_flush_log_at_trx_commit = 2; -- Flush cada segundo
-- PostgreSQL: Reducir durabilidad para mejorar rendimiento
-- synchronous_commit = off -- En postgresql.conf
Con estas configuraciones menos estrictas, existe una pequeña ventana de tiempo (generalmente segundos) durante la cual una transacción confirmada podría perderse en caso de fallo catastrófico. Esta configuración puede ser aceptable para datos no críticos donde el rendimiento es prioritario.
Interacción entre aislamiento y durabilidad
Estas dos propiedades interactúan de manera importante:
- Un mayor nivel de aislamiento generalmente requiere más recursos y puede reducir el rendimiento
- Una mayor durabilidad implica más operaciones de E/S y también puede afectar al rendimiento
- Ambas propiedades son esenciales para garantizar la integridad de los datos en entornos concurrentes
-- Transacción con alto aislamiento y durabilidad garantizada
START TRANSACTION ISOLATION LEVEL SERIALIZABLE;
INSERT INTO registros_auditoria (accion, usuario, timestamp)
VALUES ('modificación_crítica', 'admin', NOW());
UPDATE cuentas_financieras SET saldo = saldo - 10000 WHERE id = 12345;
COMMIT;
En este ejemplo, el nivel SERIALIZABLE garantiza que ninguna otra transacción interfiera, mientras que el COMMIT asegura que los cambios serán durables incluso ante fallos del sistema.
Implementación práctica en aplicaciones
Al diseñar aplicaciones que trabajan con bases de datos, es importante considerar:
- Seleccionar el nivel de aislamiento adecuado para cada tipo de transacción
- Minimizar la duración de las transacciones para reducir conflictos
- Implementar reintentos para manejar errores de concurrencia
- Configurar la durabilidad según la criticidad de los datos
-- Ejemplo de manejo de errores de concurrencia en PostgreSQL
DO $$
BEGIN
FOR i IN 1..5 LOOP -- Intentar hasta 5 veces
BEGIN
START TRANSACTION ISOLATION LEVEL SERIALIZABLE;
UPDATE inventario SET stock = stock - 1
WHERE id_producto = 101 AND stock > 0;
IF FOUND THEN -- Si se actualizó alguna fila
INSERT INTO ventas (producto_id, fecha) VALUES (101, NOW());
COMMIT;
EXIT; -- Salir del bucle si todo fue bien
ELSE
ROLLBACK;
RAISE EXCEPTION 'Producto agotado';
END IF;
EXCEPTION WHEN serialization_failure THEN
ROLLBACK;
-- Esperar un poco antes de reintentar
PERFORM pg_sleep(random());
END;
END LOOP;
END $$;
Este ejemplo muestra cómo manejar errores de serialización en PostgreSQL, reintentando la transacción automáticamente cuando se producen conflictos de concurrencia.
Consideraciones para bases de datos distribuidas
En entornos distribuidos, el aislamiento y la durabilidad presentan desafíos adicionales:
- La replicación asíncrona puede comprometer temporalmente la durabilidad
- El particionamiento (sharding) puede afectar al aislamiento entre nodos
- Los sistemas distribuidos a menudo deben equilibrar consistencia, disponibilidad y tolerancia a particiones (teorema CAP)
-- Configuración de replicación en MySQL con compromiso de durabilidad
CHANGE MASTER TO
MASTER_HOST='servidor-principal.ejemplo.com',
MASTER_USER='replicacion',
MASTER_PASSWORD='contraseña',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=73;
START SLAVE;
En este escenario de replicación, existe un retraso entre la confirmación en el servidor principal y la aplicación de los cambios en los servidores secundarios, lo que puede afectar temporalmente a la durabilidad global del sistema.
El aislamiento y la durabilidad, junto con la atomicidad y la consistencia, forman un conjunto completo de garantías que permiten a las bases de datos relacionales mantener la integridad de los datos incluso en entornos concurrentes y ante fallos del sistema. Comprender estas propiedades es fundamental para diseñar aplicaciones robustas que gestionen datos críticos.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en SQL
Documentación oficial de SQL
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, SQL es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de SQL
Explora más contenido relacionado con SQL y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el concepto de atomicidad y su implementación en MySQL y PostgreSQL. Entender la importancia de la consistencia y cómo se mantiene mediante restricciones y reglas de negocio. Conocer los niveles de aislamiento y su impacto en la concurrencia de transacciones. Aprender cómo la durabilidad asegura la persistencia de los datos tras fallos del sistema. Analizar el equilibrio entre rendimiento y garantías ACID en sistemas de bases de datos.