Configurar binding de consumer y group
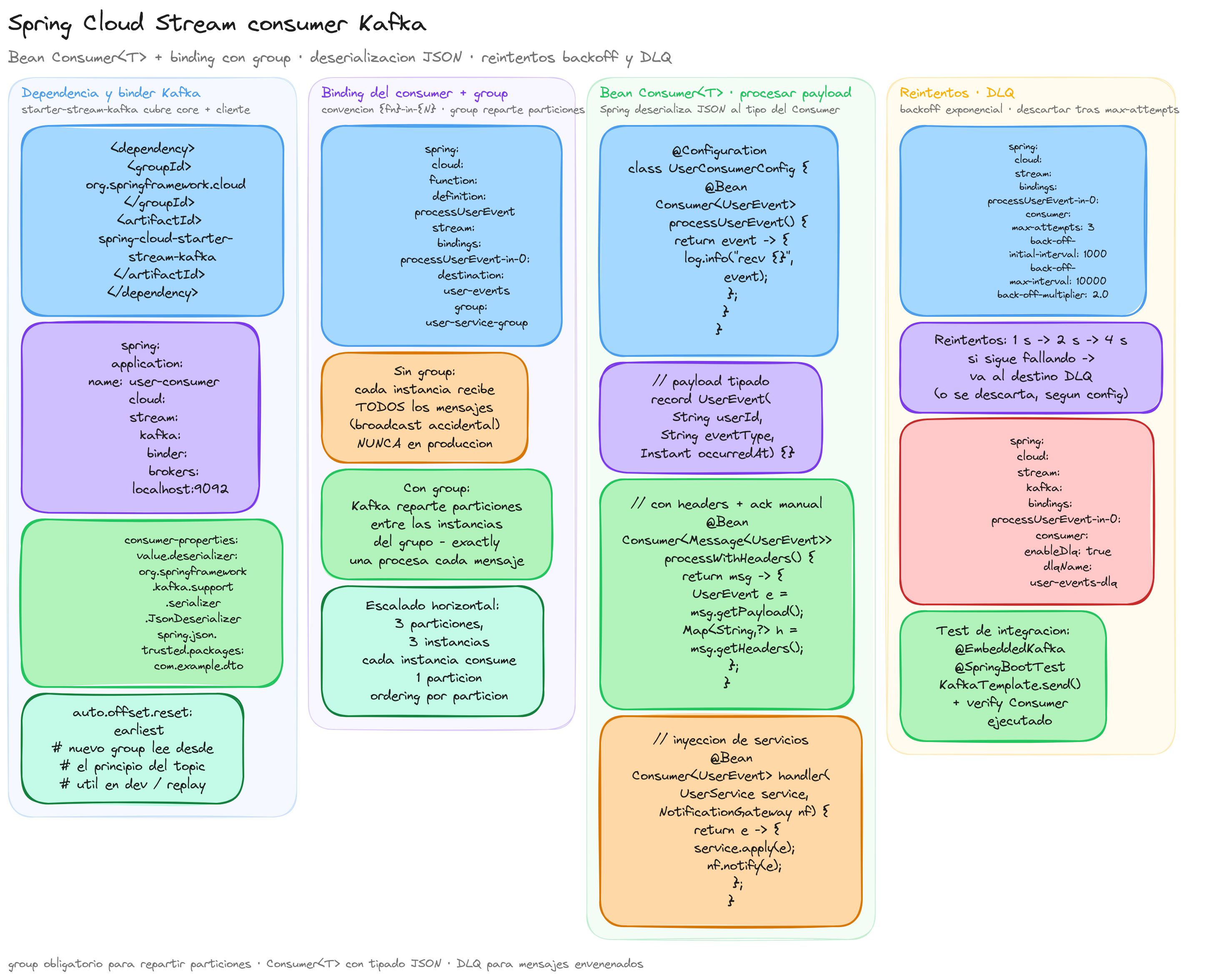
Un consumer en Spring Cloud Stream requiere una configuración específica para establecer la conexión con Kafka y definir el comportamiento del grupo de consumidores. La configuración se centra en dos aspectos fundamentales: los bindings que definen dónde y cómo consumir mensajes, y los consumer groups que permiten el procesamiento distribuido.
Dependencias del proyecto
Para implementar un consumer necesitamos las mismas dependencias que utilizamos en el producer, añadiendo el binder de Kafka:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
Esta dependencia incluye automáticamente Spring Cloud Stream y el conector específico para Kafka, permitiendo que nuestra aplicación actúe como consumidora de mensajes.
Configuración básica del consumer
La configuración del consumer se establece en el archivo application.yml utilizando la estructura de bindings de Spring Cloud Stream. Un binding define la conexión entre nuestra función Java y el topic de Kafka:
spring:
cloud:
stream:
bindings:
processMessage-in-0:
destination: user-events
group: user-service-group
kafka:
binder:
brokers: localhost:9092
El nombre del binding sigue la convención {functionName}-in-{index}, donde processMessage sería el nombre de nuestra función consumer, in indica que es un binding de entrada, y 0 es el índice del parámetro.
Consumer groups y distribución de carga
Los consumer groups son fundamentales para el procesamiento distribuido en Kafka. Cuando varios consumidores pertenecen al mismo grupo, Kafka distribuye automáticamente las particiones entre ellos, asegurando que cada mensaje se procese exactamente una vez:
spring:
cloud:
stream:
bindings:
processMessage-in-0:
destination: user-events
group: user-service-group
consumer:
max-attempts: 3
back-off-initial-interval: 1000
La propiedad group es obligatoria para evitar que cada instancia de la aplicación procese todos los mensajes. Sin ella, cada consumer recibiría una copia de todos los mensajes del topic.
Configuración específica de Kafka
Para el correcto funcionamiento del consumer, especialmente cuando trabajamos con mensajes JSON, necesitamos configurar el deserializador:
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
consumer-properties:
value.deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
spring.json.trusted.packages: com.example.dto
La configuración spring.json.trusted.packages es una medida de seguridad que específica qué paquetes pueden ser deserializados, evitando problemas de seguridad con clases no confiables.
Configuración de reintentos y manejo de errores
Spring Cloud Stream proporciona mecanismos de reintento integrados que podemos configurar a nivel de binding:
spring:
cloud:
stream:
bindings:
processMessage-in-0:
destination: user-events
group: user-service-group
consumer:
max-attempts: 3
back-off-initial-interval: 1000
back-off-max-interval: 10000
back-off-multiplier: 2.0
Esta configuración establece un patrón de backoff exponencial: si el procesamiento falla, Spring Cloud Stream reintentará con intervalos crecientes (1s, 2s, 4s) hasta un máximo de 3 intentos.
Configuración completa de ejemplo
Un ejemplo completo de configuración para un consumer quedaría así:
spring:
application:
name: user-consumer-service
cloud:
stream:
bindings:
processUserEvent-in-0:
destination: user-events
group: user-processing-service
consumer:
max-attempts: 3
back-off-initial-interval: 1000
kafka:
binder:
brokers: localhost:9092
consumer-properties:
value.deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
spring.json.trusted.packages: com.example.model
auto.offset.reset: earliest
logging:
level:
org.springframework.cloud.stream: DEBUG
La configuración auto.offset.reset: earliest asegura que cuando un nuevo consumer group se conecte, comenzará leyendo desde el inicio del topic, útil durante el desarrollo y testing.
Esta configuración establece los cimientos para que nuestro consumer pueda recibir y procesar mensajes de forma confiable, con manejo automático de errores y distribución de carga entre múltiples instancias del servicio.
Consumer: Consumer y procesamiento básico
La implementación de un consumer en Spring Cloud Stream se basa en el patrón funcional, utilizando la interfaz Consumer<T> para definir cómo procesar los mensajes entrantes. Este enfoque proporciona una forma declarativa y elegante de manejar el procesamiento asíncrono de mensajes.
Implementación básica del Consumer
Un consumer se implementa como un bean funcional que Spring Cloud Stream detecta automáticamente y vincula con el binding correspondiente:
@Configuration
public class MessageConsumerConfig {
private static final Logger logger = LoggerFactory.getLogger(MessageConsumerConfig.class);
@Bean
public Consumer<UserEvent> processUserEvent() {
return userEvent -> {
logger.info("Procesando evento de usuario: {}", userEvent);
// Lógica de negocio
processUser(userEvent);
logger.info("Evento procesado correctamente para usuario: {}", userEvent.getUserId());
};
}
private void processUser(UserEvent event) {
// Implementación de la lógica de negocio
switch (event.getEventType()) {
case "USER_CREATED" -> handleUserCreated(event);
case "USER_UPDATED" -> handleUserUpdated(event);
case "USER_DELETED" -> handleUserDeleted(event);
default -> logger.warn("Tipo de evento desconocido: {}", event.getEventType());
}
}
}
El nombre del método processUserEvent debe coincidir con la primera parte del binding definido en la configuración (processUserEvent-in-0). Spring Cloud Stream establece automáticamente la conexión entre el bean funcional y el topic de Kafka.
Deserialización automática de JSON
Cuando configuramos correctamente el JsonDeserializer, Spring Cloud Stream deserializa automáticamente los mensajes JSON a nuestros objetos Java. El DTO debe coincidir con la estructura del mensaje:
public class UserEvent {
private String userId;
private String eventType;
private String email;
private LocalDateTime timestamp;
// Constructors, getters, setters
public UserEvent() {}
public UserEvent(String userId, String eventType, String email) {
this.userId = userId;
this.eventType = eventType;
this.email = email;
this.timestamp = LocalDateTime.now();
}
// Getters y setters...
}
Para casos más complejos donde necesitamos acceder a metadatos del mensaje, podemos utilizar Message<T>:
@Bean
public Consumer<Message<UserEvent>> processUserEventWithHeaders() {
return message -> {
UserEvent userEvent = message.getPayload();
MessageHeaders headers = message.getHeaders();
logger.info("Procesando mensaje con headers: {}", headers);
logger.info("Timestamp del mensaje: {}", headers.get(MessageHeaders.TIMESTAMP));
// Procesar el evento
handleUserEvent(userEvent);
};
}
Procesamiento con manejo de errores
Un consumer robusto debe manejar las excepciones de forma apropiada para evitar perder mensajes o bloquear el procesamiento:
@Bean
public Consumer<UserEvent> processUserEvent() {
return userEvent -> {
try {
logger.info("Iniciando procesamiento para usuario: {}", userEvent.getUserId());
// Validación básica
if (userEvent.getUserId() == null || userEvent.getUserId().trim().isEmpty()) {
throw new IllegalArgumentException("User ID no puede estar vacío");
}
// Procesamiento de negocio
userService.processUserEvent(userEvent);
// Log de éxito
logger.info("Usuario {} procesado exitosamente", userEvent.getUserId());
} catch (IllegalArgumentException e) {
logger.error("Error de validación procesando usuario {}: {}",
userEvent.getUserId(), e.getMessage());
// No relanzamos la excepción para evitar reintentos innecesarios
} catch (Exception e) {
logger.error("Error procesando usuario {}: {}",
userEvent.getUserId(), e.getMessage(), e);
// Relanzamos para activar el mecanismo de reintentos
throw new RuntimeException("Error procesando evento de usuario", e);
}
};
}
Inyección de dependencias en consumers
Los consumers pueden inyectar servicios y repositorios como cualquier otro bean de Spring, facilitando la separación de responsabilidades:
@Configuration
public class UserEventConsumerConfig {
private final UserService userService;
private final NotificationService notificationService;
public UserEventConsumerConfig(UserService userService,
NotificationService notificationService) {
this.userService = userService;
this.notificationService = notificationService;
}
@Bean
public Consumer<UserEvent> processUserEvent() {
return userEvent -> {
logger.info("Procesando evento: {}", userEvent.getEventType());
switch (userEvent.getEventType()) {
case "USER_CREATED":
userService.createUser(userEvent);
notificationService.sendWelcomeEmail(userEvent.getEmail());
break;
case "USER_UPDATED":
userService.updateUser(userEvent);
break;
default:
logger.warn("Evento no manejado: {}", userEvent.getEventType());
}
};
}
}
Testing del consumer
Para probar nuestro consumer, podemos crear un test de integración que verifique el procesamiento completo:
@SpringBootTest
@TestPropertySource(properties = {
"spring.cloud.stream.bindings.processUserEvent-in-0.destination=test-user-events"
})
class UserEventConsumerTest {
@Autowired
private StreamBridge streamBridge;
@Autowired
private UserService userService;
@Test
void shouldProcessUserCreatedEvent() throws InterruptedException {
// Preparar datos
UserEvent userEvent = new UserEvent("user123", "USER_CREATED", "user@example.com");
// Enviar mensaje al topic
streamBridge.send("test-user-events", userEvent);
// Esperar procesamiento (en test real usaríamos TestContainers)
Thread.sleep(2000);
// Verificar que el usuario fue procesado
verify(userService).createUser(userEvent);
}
}
Verificación del flujo end-to-end
Para verificar que nuestro consumer funciona correctamente con el producer de la lección anterior, podemos seguir estos pasos:
1. Arrancar Kafka con Docker:
docker-compose up -d kafka
2. Iniciar el producer (aplicación de la lección anterior) que envía mensajes al topic user-events.
3. Iniciar nuestro consumer y observar los logs:
2024-01-15 10:30:15.234 INFO processUserEvent : Procesando evento de usuario: UserEvent{userId='user123', eventType='USER_CREATED'}
2024-01-15 10:30:15.245 INFO processUserEvent : Evento procesado correctamente para usuario: user123
4. Verificar el consumo desde línea de comandos:
# Listar topics
docker exec kafka kafka-topics --bootstrap-server localhost:9092 --list
# Inspeccionar mensajes en el topic
docker exec kafka kafka-console-consumer --bootstrap-server localhost:9092 \
--topic user-events --from-beginning
Esta verificación nos permite confirmar que los mensajes fluyen correctamente desde el producer hasta el consumer, completando el ciclo de comunicación asíncrona entre microservicios.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en Spring Boot
Documentación oficial de Spring Boot
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la configuración de bindings y grupos de consumidores en Spring Cloud Stream con Kafka. Implementar un consumer funcional usando la interfaz Consumer