Spring Cloud Stream: conceptos y binders
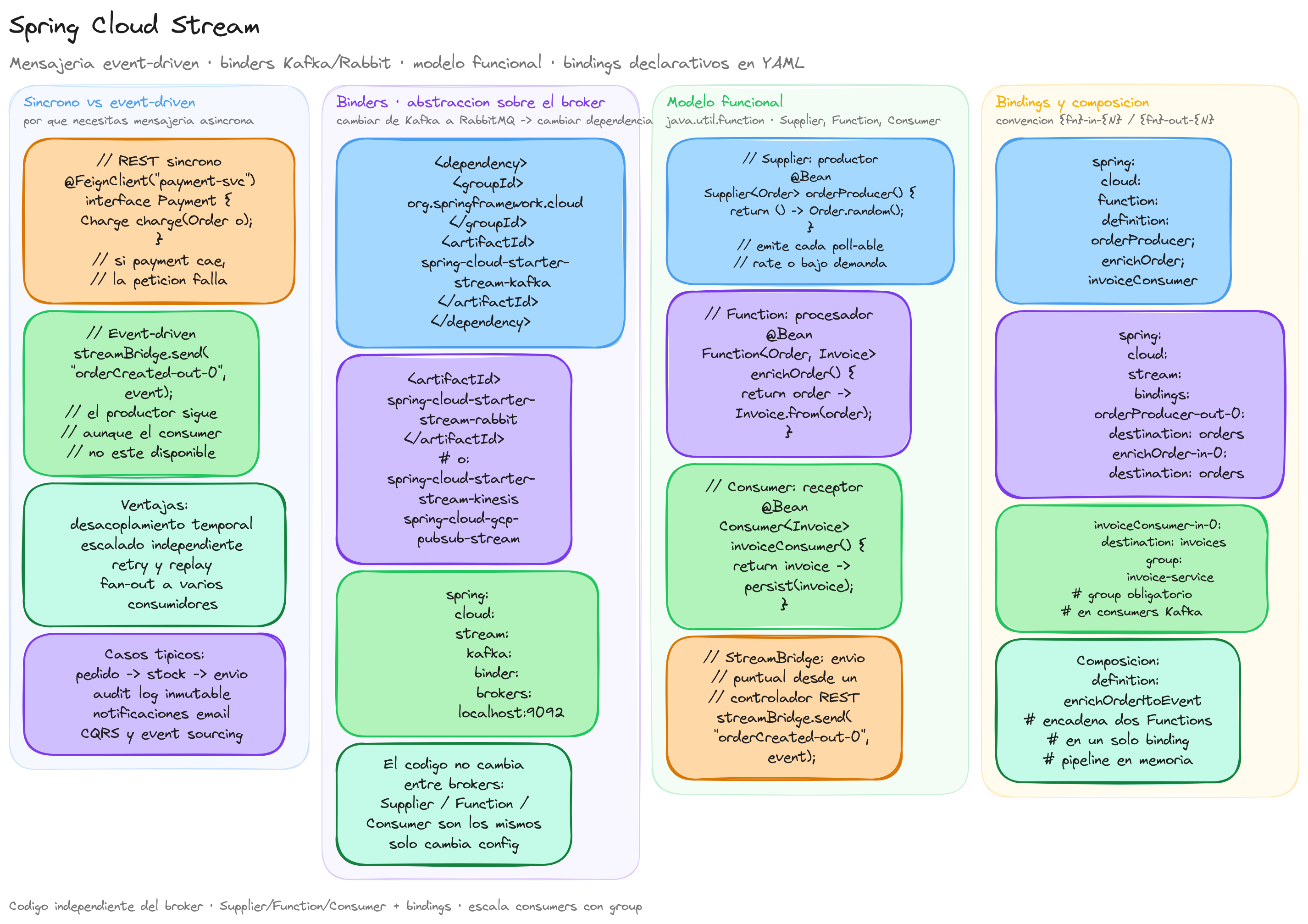
Spring Cloud Stream es un framework que simplifica la construcción de aplicaciones basadas en mensajería para arquitecturas de microservicios. Su principal ventaja radica en proporcionar una abstracción sobre los sistemas de mensajería subyacentes, permitiendo que el código de negocio se mantenga independiente de la implementación específica del broker de mensajes.
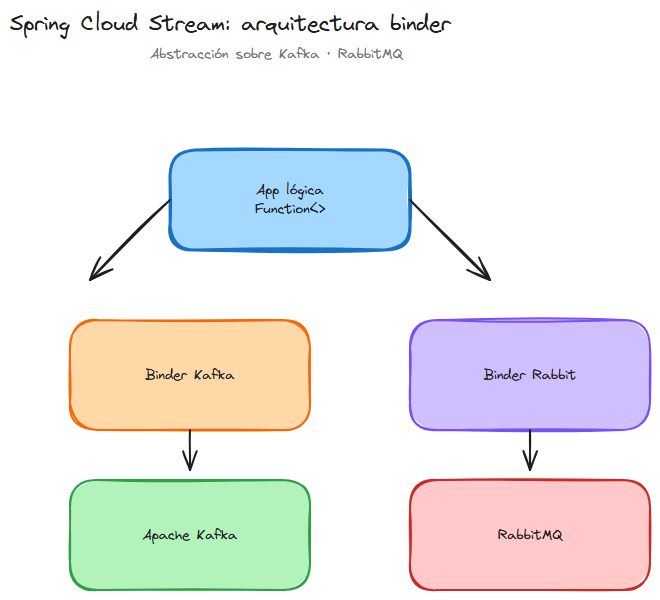
El siguiente diagrama resume visualmente los conceptos clave introducidos en esta seccion:
Paradigma event-driven vs comunicación síncrona
En las lecciones anteriores hemos trabajado con comunicación síncrona entre microservicios utilizando OpenFeign, donde un servicio llama directamente a otro y espera una respuesta inmediata. Este patrón RPC (Remote Procedure Call) funciona bien para operaciones que requieren respuesta inmediata, pero presenta limitaciones en términos de acoplamiento y disponibilidad.
La comunicación asíncrona basada en eventos ofrece ventajas significativas:
- Desacoplamiento temporal: Los servicios no necesitan estar disponibles simultáneamente
- Escalabilidad mejorada: Los mensajes pueden procesarse a ritmos diferentes
- Tolerancia a fallos: Los mensajes persisten aunque un servicio esté temporalmente indisponible
- Flexibilidad arquitectónica: Nuevos consumidores pueden añadirse sin modificar el productor
Arquitectura de Spring Cloud Stream
Spring Cloud Stream organiza la comunicación por mensajes en tres componentes principales:
- Source (Productor): Genera y envía mensajes
- Processor: Recibe, transforma y reenvía mensajes
- Sink (Consumidor): Recibe y procesa mensajes finales
El flujo típico de un mensaje sigue este patrón:
Aplicación → Spring Cloud Stream → Binder → Message Broker → Binder → Spring Cloud Stream → Aplicación
Concepto de Binder
El binder es el componente central que abstrae la comunicación con el sistema de mensajería. Actúa como un adaptador entre la aplicación Spring Boot y el broker de mensajes específico, proporcionando una interfaz unificada independientemente del sistema subyacente.
Ventajas del patrón binder:
- Portabilidad: Cambiar de Apache Kafka a RabbitMQ requiere únicamente modificar dependencias y configuración
- Configuración declarativa: La configuración se realiza mediante propiedades YAML/Properties
- Gestión automática: Maneja conexiones, serialización/deserialización y gestión de errores
Binders disponibles oficialmente:
- Apache Kafka: Para sistemas de alta throughput y persistencia de logs
- RabbitMQ: Para patrones de mensajería tradicionales y routing complejo
- Amazon Kinesis: Para streaming en AWS
- Google Pub/Sub: Para entornos Google Cloud
Configuración básica con Kafka
Para utilizar Apache Kafka como backend, necesitamos la siguiente dependencia en nuestro pom.xml:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
La configuración mínima en application.yml incluye:
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
bindings:
# Los bindings específicos se configurarán en las lecciones prácticas
Configuración con RabbitMQ como alternativa
La flexibilidad de Spring Cloud Stream se demuestra en la facilidad para cambiar de broker. Para RabbitMQ, simplemente sustituimos la dependencia:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
Y ajustamos la configuración:
spring:
cloud:
stream:
rabbit:
binder:
connection-name: my-connection
bindings:
# Los bindings permanecen idénticos
Entorno de desarrollo con Docker
Para las lecciones prácticas siguientes, necesitaremos un entorno Kafka local. El docker-compose.yml mínimo incluye:
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
Bindings y canales
Los bindings conectan las funciones de negocio con los canales de mensajería externos. Spring Cloud Stream gestiona automáticamente la serialización/deserialización de objetos Java a formato JSON, y el enrutamiento de mensajes según la configuración.
Cada binding se configura mediante propiedades que especifican:
- Destination: Nombre del topic/queue/exchange de destino
- Content-type: Formato del mensaje (application/json por defecto)
- Group: Grupo de consumidores para balanceo de carga
- Partitioning: Estrategia de distribución en particiones
Preparación para las lecciones prácticas
En las próximas dos lecciones implementaremos:
- Productor Kafka: Servicio que envía eventos utilizando el modelo funcional
Supplier - Consumidor Kafka: Servicio que procesa eventos mediante funciones
Consumer
Ambas implementaciones utilizarán la misma infraestructura de binders y la configuración Docker presentada en esta sección, demostrando la consistencia y simplicidad del modelo de Spring Cloud Stream.
Modelo funcional: Supplier / Function / Consumer
Spring Cloud Stream ha evolucionado hacia un modelo funcional que simplifica significativamente la definición de productores y consumidores de mensajes. Este enfoque aprovecha las interfaces funcionales de Java 8+ y la programación reactiva para crear aplicaciones más legibles y mantenibles.
Interfaces funcionales principales
El modelo funcional se basa en tres interfaces estándar de Java:
Supplier<T>: Representa un productor que genera mensajes sin recibir entradaFunction<T,R>: Actúa como un procesador que transforma mensajes de entrada en mensajes de salidaConsumer<T>: Define un consumidor que procesa mensajes sin producir salida
Esta aproximación reemplaza las anotaciones @Input, @Output y @StreamListener del modelo anterior, ofreciendo mayor simplicidad y claridad.
Supplier: Producción de mensajes
Un Supplier genera mensajes de forma periódica o bajo demanda. Spring Cloud Stream invoca automáticamente el método get() del supplier según la configuración establecida:
@Configuration
public class MessageProducer {
@Bean
public Supplier<String> messageSupplier() {
return () -> "Mensaje generado a las " + LocalDateTime.now();
}
}
Configuración del binding para el supplier:
spring:
cloud:
stream:
bindings:
messageSupplier-out-0:
destination: messages-topic
content-type: application/json
function:
definition: messageSupplier
Consumer: Procesamiento de mensajes
Un Consumer procesa mensajes entrantes de forma reactiva. El framework invoca automáticamente el método accept() cuando llegan nuevos mensajes:
@Configuration
public class MessageConsumer {
private static final Logger logger = LoggerFactory.getLogger(MessageConsumer.class);
@Bean
public Consumer<String> messageProcessor() {
return message -> {
logger.info("Procesando mensaje: {}", message);
// Lógica de negocio aquí
};
}
}
Configuración del binding para el consumer:
spring:
cloud:
stream:
bindings:
messageProcessor-in-0:
destination: messages-topic
group: message-processing-group
content-type: application/json
function:
definition: messageProcessor
Function: Transformación de mensajes
Una Function actúa como middleware que recibe un mensaje, lo transforma y produce un mensaje de salida. Es útil para implementar patrones de transformación y enriquecimiento:
@Configuration
public class MessageTransformer {
@Bean
public Function<String, MessageDto> messageEnricher() {
return input -> MessageDto.builder()
.originalMessage(input)
.processedAt(LocalDateTime.now())
.processedBy("message-transformer-service")
.build();
}
}
Configuración del binding para la function:
spring:
cloud:
stream:
bindings:
messageEnricher-in-0:
destination: raw-messages
messageEnricher-out-0:
destination: enriched-messages
function:
definition: messageEnricher
Nombrado automático de bindings
Spring Cloud Stream utiliza una convención de nombres automática para los bindings:
- Suppliers:
{functionName}-out-{index} - Consumers:
{functionName}-in-{index} - Functions:
{functionName}-in-{index}y{functionName}-out-{index}
El índice permite manejar múltiples entradas o salidas. Para la mayoría de casos de uso, el índice es 0.
Composición de funciones
Spring Cloud Stream permite componer múltiples funciones mediante el operador pipe (|):
spring:
cloud:
stream:
function:
definition: messageValidator|messageEnricher|messageNotifier
Esta configuración crea una cadena de procesamiento donde la salida de messageValidator alimenta la entrada de messageEnricher, y así sucesivamente.
Gestión de tipos y serialización
El framework maneja automáticamente la serialización/deserialización basándose en el content-type configurado. Para objetos personalizados, Spring utiliza Jackson para conversiones JSON:
@Bean
public Consumer<OrderEvent> orderProcessor() {
return orderEvent -> {
log.info("Procesando pedido: {} por valor de {}",
orderEvent.getOrderId(), orderEvent.getAmount());
// Procesamiento específico del pedido
};
}
Configuración con tipos personalizados:
spring:
cloud:
stream:
bindings:
orderProcessor-in-0:
destination: order-events
content-type: application/json
kafka:
binder:
consumer-properties:
value.deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
spring.json.value.default.type: com.example.OrderEvent
Configuración múltiple de funciones
Una aplicación puede definir múltiples funciones simultáneamente, cada una con su configuración específica:
spring:
cloud:
stream:
function:
definition: orderSupplier;orderProcessor;inventoryUpdater
bindings:
orderSupplier-out-0:
destination: order-events
orderProcessor-in-0:
destination: order-events
group: order-processing
inventoryUpdater-in-0:
destination: inventory-updates
group: inventory-service
Esta flexibilidad permite que una sola aplicación actúe como productor y consumidor simultáneamente, facilitando la implementación de servicios que participan en múltiples flujos de mensajería.
Integración con el contexto de Spring
Las funciones se registran como beans de Spring, lo que permite la inyección de dependencias y el uso de toda la funcionalidad del framework:
@Configuration
public class OrderProcessingConfiguration {
@Autowired
private OrderService orderService;
@Autowired
private NotificationService notificationService;
@Bean
public Function<OrderEvent, OrderProcessedEvent> orderProcessor() {
return orderEvent -> {
Order processedOrder = orderService.processOrder(orderEvent);
notificationService.sendConfirmation(processedOrder);
return OrderProcessedEvent.builder()
.orderId(processedOrder.getId())
.processedAt(LocalDateTime.now())
.status("PROCESSED")
.build();
};
}
}
Este modelo funcional proporciona una base sólida para implementar patrones de mensajería complejos manteniendo la simplicidad del código y aprovechando las características nativas de Spring Boot.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en Spring Boot
Documentación oficial de Spring Boot
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el paradigma event-driven y sus ventajas frente a la comunicación síncrona. Conocer la arquitectura de Spring Cloud Stream y el papel de los binders. Aprender a configurar Spring Cloud Stream con brokers como Kafka y RabbitMQ. Entender el modelo funcional basado en Supplier, Function y Consumer para la producción, transformación y consumo de mensajes. Saber cómo gestionar bindings, serialización y composición de funciones en Spring Cloud Stream.