Introducción al service discovery con Eureka
En arquitecturas de microservicios, los servicios necesitan comunicarse entre sí constantemente para proporcionar funcionalidad completa a los usuarios finales. Sin embargo, gestionar estas comunicaciones se convierte rápidamente en un desafío complejo cuando los servicios se ejecutan en diferentes servidores, puertos y pueden cambiar dinámicamente su ubicación debido a escalado, fallos o redeployments.
El service discovery (descubrimiento de servicios) surge como una solución fundamental que permite a los microservicios encontrar y comunicarse con otros servicios de forma dinámica, sin necesidad de configuraciones estáticas hardcodeadas que se vuelven inmanejables en entornos de producción.
¿Por qué necesitamos service discovery?
En una arquitectura monolítica tradicional, las diferentes partes de la aplicación se comunican mediante llamadas a métodos locales o conexiones a bases de datos con URLs fijas. Sin embargo, en microservicios, cada servicio es una aplicación independiente que puede:
- Ejecutarse en múltiples instancias para manejar mayor carga
- Cambiar de ubicación cuando se redespliega o se mueve a otro servidor
- Fallar y recuperarse en diferentes direcciones IP o puertos
- Escalarse automáticamente creando y destruyendo instancias según la demanda
Imagina un escenario donde el servicio de usuarios necesita comunicarse con el servicio de pedidos. Si hardcodeamos la URL http://servidor1:8080/pedidos, ¿qué sucede cuando:
- El servicio de pedidos se mueve al
servidor2:8081? - Se crean tres instancias del servicio de pedidos para balancear carga?
- Una instancia falla y necesitamos redirigir el tráfico?
Sin service discovery, tendríamos que actualizar manualmente las configuraciones cada vez que ocurra algún cambio, lo cual es impracticable en entornos dinámicos.
Componentes del service discovery
El patrón de service discovery se basa en dos componentes principales que trabajan de forma coordinada:

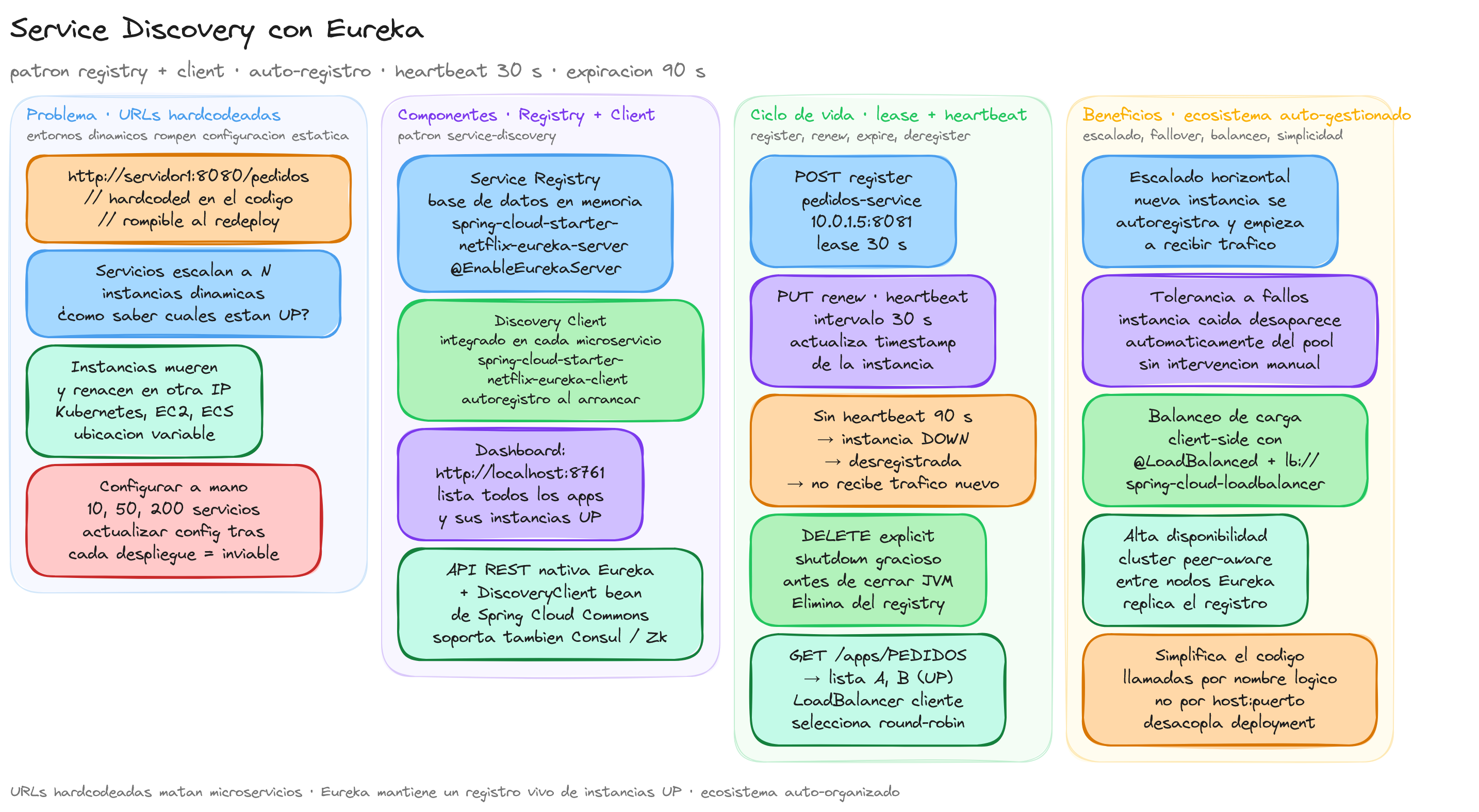
- Service Registry (Registro de servicios): Un componente centralizado que mantiene una base de datos de todos los servicios disponibles, sus ubicaciones (IP y puerto), estado de salud y metadatos adicionales.
- Service Discovery Client: Un mecanismo que permite a los servicios registrarse en el registry y consultar la ubicación de otros servicios cuando necesitan comunicarse con ellos.
Este patrón facilita un ecosistema auto-organizado donde los servicios pueden aparecer y desaparecer dinámicamente, y el resto del sistema se adapta automáticamente a estos cambios.
Netflix Eureka como solución
Netflix Eureka es una implementación madura y probada del patrón service discovery que se integra perfectamente con Spring Cloud. Desarrollada originalmente por Netflix para gestionar sus arquitecturas de microservicios a gran escala, Eureka proporciona:
- Alta disponibilidad: Puede ejecutarse en múltiples instancias para evitar puntos únicos de fallo
- Tolerancia a particiones de red: Continúa funcionando aunque pierda conectividad con otras instancias
- Integración transparente: Se integra automáticamente con Spring Boot mediante anotaciones simples
- Dashboard visual: Proporciona una interfaz web para monitorizar el estado de los servicios registrados
La arquitectura de Eureka sigue un modelo cliente-servidor donde:
- Los servicios actúan como clientes Eureka que se registran automáticamente al iniciarse
- El servidor Eureka mantiene el registro centralizado y proporciona APIs para consultas
- Los servicios pueden consultar el registro para descubrir otros servicios y sus instancias disponibles
Beneficios del service discovery con Eureka
La implementación de service discovery con Eureka aporta múltiples beneficios a arquitecturas de microservicios:
- Eliminación de configuraciones estáticas: Los servicios no necesitan conocer las ubicaciones exactas de otros servicios, sino que las descubren dinámicamente.
- Escalabilidad automática: Nuevas instancias de servicios se registran automáticamente y están disponibles inmediatamente para recibir tráfico.
- Recuperación ante fallos: Servicios que fallan se eliminan automáticamente del registro, evitando que reciban nuevas peticiones.
- Balanceado de carga: Al conocer todas las instancias disponibles de un servicio, es posible distribuir el tráfico de forma equilibrada.
- Simplificación del desarrollo: Los desarrolladores se centran en la lógica de negocio sin preocuparse por la gestión de ubicaciones de servicios.
En las siguientes lecciones veremos cómo implementar tanto el Eureka Server como los clientes Eureka para crear un ecosistema de microservicios que se auto-gestiona y adapta dinámicamente a los cambios del entorno.
Eureka Server y Eureka Discovery Client
La arquitectura de service discovery con Eureka se fundamenta en dos componentes principales que colaboran para proporcionar un sistema de registro y descubrimiento distribuido y resiliente. Cada componente tiene responsabilidades específicas que, al trabajar en conjunto, crean un ecosistema donde los microservicios pueden auto-gestionarse dinámicamente.
Eureka Server: El registro centralizado
El Eureka Server actúa como el corazón del sistema de service discovery, funcionando como un registro centralizado donde todos los microservicios publican su información de ubicación y estado. Su arquitectura está diseñada para ser altamente disponible y tolerar fallos de red, características esenciales en entornos de producción.
Responsabilidades principales del Eureka Server:
- Gestión del registro de servicios: Mantiene una base de datos en memoria con información detallada de todas las instancias de servicios registradas, incluyendo direcciones IP, puertos, metadatos y estado de salud.
- Recepción de heartbeats: Los servicios cliente envían señales de vida periódicas (heartbeats) cada 30 segundos por defecto. El servidor utiliza estas señales para determinar qué instancias están operativas.
- Limpieza automática: Elimina automáticamente del registro aquellas instancias que no han enviado heartbeats durante un período determinado (90 segundos por defecto), evitando que el tráfico se dirija a servicios no disponibles.
- API REST para consultas: Expone endpoints REST que permiten a los clientes consultar el registro y obtener información sobre instancias disponibles de servicios específicos.
- Dashboard de administración: Proporciona una interfaz web accesible (por defecto en
http://localhost:8761) donde los administradores pueden visualizar el estado del registro y monitorizar los servicios registrados. - El modelo de datos que mantiene Eureka Server incluye información crítica como el identificador del servicio (service ID), la dirección IP, el puerto, los metadatos personalizados y el timestamp de la última actualización. Esta información se estructura de forma que permita consultas eficientes y actualizaciones frecuentes.
Eureka Discovery Client: La puerta de entrada de los servicios
El Eureka Discovery Client es el componente que se integra en cada microservicio para habilitar tanto el registro automático como la capacidad de descubrir otros servicios. Este cliente se ejecuta como parte de cada aplicación Spring Boot y maneja toda la comunicación con el Eureka Server de forma transparente.
Funcionalidades clave del Discovery Client:
- Registro automático: Al iniciarse, el servicio se registra automáticamente en el Eureka Server, enviando información sobre su ubicación, puerto y metadatos configurados.
- Renovación periódica: Mantiene su registro activo enviando heartbeats regulares al servidor, indicando que la instancia sigue operativa y disponible para recibir tráfico.
- Cache local del registro: Mantiene una copia local del registro de servicios que se actualiza periódicamente (cada 30 segundos), reduciendo la latencia en las consultas de discovery y proporcionando resilencia ante fallos temporales del servidor.
- API de descubrimiento: Expone interfaces programáticas (
DiscoveryClient,EurekaClient) que permiten a los desarrolladores consultar dinámicamente las instancias disponibles de otros servicios. - Integración con balanceadores de carga: Se integra automáticamente con Spring Cloud LoadBalancer para distribuir las peticiones entre múltiples instancias de un mismo servicio.
Flujo de comunicación entre componentes
El flujo operacional entre Eureka Server y los Discovery Clients sigue un patrón bien definido que garantiza la coherencia y disponibilidad del sistema:
1 - Fase de registro inicial:
Cuando un microservicio se inicia, el Discovery Client se conecta automáticamente al Eureka Server y envía una petición de registro con su información de servicio (nombre, IP, puerto, metadatos).
2 - Establecimiento de heartbeats:
Una vez registrado, el cliente inicia un proceso de envío de heartbeats periódicos para mantener su registro activo y señalar que está disponible para recibir tráfico.
3 - Sincronización del registro:
El cliente descarga periódicamente una copia completa del registro de servicios desde el servidor, manteniendo una cache local actualizada para consultas rápidas.
4 - Proceso de discovery:
Cuando un servicio necesita comunicarse con otro, utiliza la API del Discovery Client para consultar las instancias disponibles, obteniendo información actualizada sobre direcciones y puertos.
5 - Gestión de fallos:
Si un servicio falla o se detiene, deja de enviar heartbeats. El Eureka Server detecta esta situación y elimina la instancia del registro después del timeout configurado.
Ventajas de la arquitectura distribuida
La separación de responsabilidades entre servidor y cliente aporta beneficios significativos a la arquitectura:
- Desacoplamiento: Los servicios no necesitan conocer la ubicación exacta de otros servicios, sino que consultan dinámicamente esta información.
- Escalabilidad horizontal: Es posible ejecutar múltiples instancias del mismo servicio, y todas se registran automáticamente sin configuración adicional.
- Tolerancia a fallos: La cache local en cada cliente permite continuar operando aunque el Eureka Server experimente interrupciones temporales.
- Simplicidad de desarrollo: Los desarrolladores solo necesitan añadir una dependencia y una anotación para habilitar todas las funcionalidades de service discovery.
Esta arquitectura establecerá las bases para implementar patrones avanzados como balanceado de carga client-side, circuit breakers y routing inteligente, que veremos en las siguientes lecciones del curso donde pasaremos de la teoría a la implementación práctica de ambos componentes.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en Spring Boot
Documentación oficial de Spring Boot
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la necesidad del service discovery en arquitecturas de microservicios. Identificar los componentes principales del patrón service discovery: Service Registry y Service Discovery Client. Conocer la arquitectura y funcionalidades de Netflix Eureka como solución de service discovery. Entender el funcionamiento del Eureka Server y del Eureka Discovery Client. Reconocer las ventajas y beneficios de implementar service discovery con Eureka en microservicios.