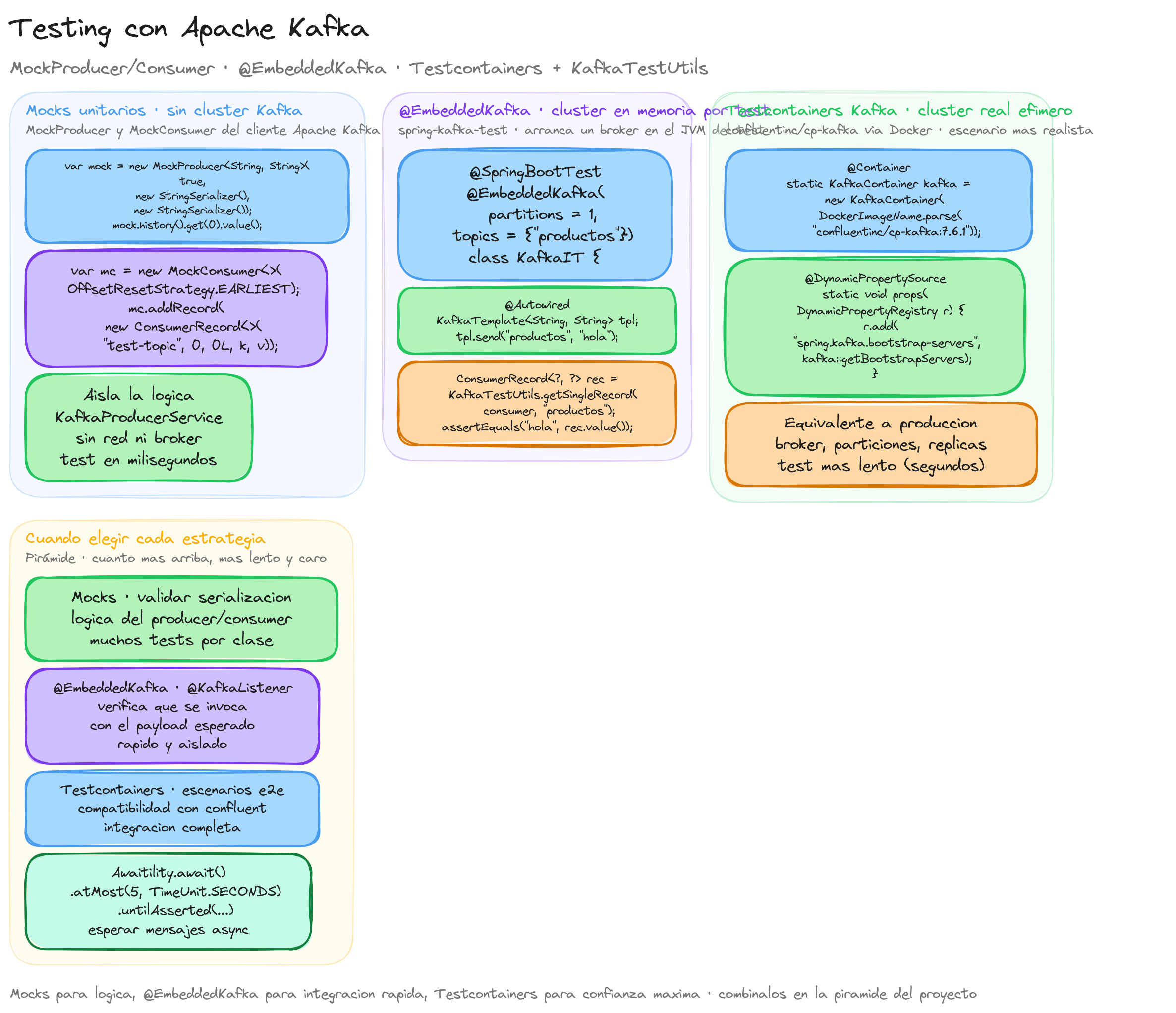
Uso de MockProducer y MockConsumer
En el desarrollo de aplicaciones con Spring Boot 4 y Apache Kafka, es esencial realizar pruebas unitarias que garanticen el correcto funcionamiento de los componentes de mensajería. Para ello, podemos utilizar MockProducer y MockConsumer, que nos permiten simular los Producers y Consumers de Kafka sin necesidad de conectarnos a un clúster real.
El uso de MockProducer facilita la validación de la lógica de envío de mensajes a Kafka, mientras que MockConsumer nos ayuda a verificar la lógica de consumo y procesamiento de mensajes. A continuación, veremos cómo configurar y utilizar estos mocks en nuestras pruebas unitarias.
Para comenzar, necesitamos crear una instancia de MockProducer en nuestras pruebas. Podemos hacerlo de la siguiente manera:
var mockProducer = new MockProducer<String, String>(
true, // autoComplete
new StringSerializer(),
new StringSerializer()
);
En este ejemplo, hemos creado un MockProducer que utiliza StringSerializer tanto para las claves como para los valores. El parámetro autoComplete está establecido en true para que los envíos se completen automáticamente, lo cual es útil para simplificar las pruebas unitarias.
Supongamos que tenemos un servicio que envía mensajes a Kafka:
@Service
public class KafkaProducerService {
private final KafkaTemplate<String, String> kafkaTemplate;
public KafkaProducerService(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}
En nuestra prueba unitaria, queremos inyectar el MockProducer en lugar del Producer real. Para ello, podemos configurar un ProducerFactory que utilice nuestro mock:
@Test
void testSendMessage() {
var mockProducer = new MockProducer<String, String>(
true,
new StringSerializer(),
new StringSerializer()
);
ProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(
Collections.emptyMap(),
new StringSerializer(),
new StringSerializer()
) {
@Override
public Producer<String, String> createProducer() {
return mockProducer;
}
};
var kafkaTemplate = new KafkaTemplate<>(producerFactory);
var producerService = new KafkaProducerService(kafkaTemplate);
producerService.sendMessage("test-topic", "Hola, Kafka!");
assertTrue(mockProducer.history().size() == 1);
var record = mockProducer.history().get(0);
assertEquals("Hola, Kafka!", record.value());
}
En este test, hemos creado un ProducerFactory personalizado que devuelve nuestro MockProducer. De esta forma, cuando el servicio utiliza el KafkaTemplate para enviar un mensaje, internamente se utiliza el mock, permitiéndonos verificar los mensajes enviados. Es crucial destacar que el uso de MockProducer nos permite aislar el código bajo prueba.
De manera similar, podemos utilizar MockConsumer para probar nuestras clases que consumen mensajes de Kafka. Primero, creamos una instancia del MockConsumer:
var mockConsumer = new MockConsumer<String, String>(OffsetResetStrategy.EARLIEST);
Imaginemos un listener que procesa mensajes de Kafka:
@Service
public class KafkaConsumerService {
@KafkaListener(topics = "test-topic", groupId = "test-group")
public void listen(String message) {
// Procesar el mensaje
}
}
Para probar este listener con el MockConsumer, necesitamos un enfoque diferente, ya que @KafkaListener trabaja con hilos propios gestionados por Spring. Una alternativa es probar la lógica de procesamiento de forma aislada o utilizar el KafkaMessageListenerContainer con el mock.
Podemos configurar un KafkaMessageListenerContainer que utilice el MockConsumer:
@Test
void testConsumeMessage() {
var mockConsumer = new MockConsumer<String, String>(OffsetResetStrategy.EARLIEST);
ConsumerFactory<String, String> consumerFactory = new ConsumerFactory<>() {
@Override
public Consumer<String, String> createConsumer() {
return mockConsumer;
}
// Otros métodos implementados según sea necesario
};
var containerProperties = new ContainerProperties("test-topic");
var container = new KafkaMessageListenerContainer<>(consumerFactory, containerProperties);
var messages = new ArrayList<String>();
container.setupMessageListener((MessageListener<String, String>) record -> {
messages.add(record.value());
});
container.start();
mockConsumer.schedulePollTask(() -> {
mockConsumer.rebalance(Collections.singletonList(new TopicPartition("test-topic", 0)));
mockConsumer.addRecord(new ConsumerRecord<>("test-topic", 0, 0L, null, "Hola, Kafka!"));
});
// Esperar un breve tiempo para que se procese el mensaje
Thread.sleep(100);
assertEquals(1, messages.size());
assertEquals("Hola, Kafka!", messages.get(0));
container.stop();
}
En este ejemplo, hemos creado un ConsumerFactory personalizado que devuelve nuestro MockConsumer. Luego, configuramos un KafkaMessageListenerContainer y definimos un MessageListener que añade los mensajes recibidos a una lista. Simulamos la llegada de mensajes utilizando schedulePollTask del MockConsumer. Esta técnica nos permite validar la lógica de consumo sin depender de un entorno Kafka real, lo cual es fundamental para pruebas unitarias eficientes.
Es importante resaltar que el uso de MockProducer y MockConsumer es adecuado para pruebas unitarias, donde queremos aislar la lógica de nuestra aplicación sin depender de un clúster de Kafka real. Al utilizar mocks, podemos controlar completamente el entorno de pruebas y simular escenarios específicos, como excepciones o mensajes malformados.
Para pruebas de integración, es recomendable utilizar herramientas como @EmbeddedKafka o TestContainers, que proporcionan instancias de Kafka reales en entornos controlados. Esto permite verificar la interacción con Kafka en situaciones más cercanas a producción, pero para validar la lógica interna de nuestros servicios, los mocks son más apropiados.
Las principales ventajas de usar MockProducer y MockConsumer son:
- Rapidez en las pruebas: Al no depender de un servidor Kafka real, las pruebas son más rápidas y consumen menos recursos.
- Mayor control: Podemos simular condiciones específicas y predecibles, incluyendo errores y situaciones límite.
- Aislamiento: Las pruebas se centran en la lógica de nuestra aplicación, sin interferencias externas ni dependencias de infraestructura.
- Facilita el TDD: Permite desarrollar pruebas unitarias antes de implementar la funcionalidad, fomentando un enfoque de desarrollo dirigido por pruebas.
Al implementar estas prácticas, mejoramos la confiabilidad y mantenibilidad de nuestro código, asegurándonos de que nuestros Producers y Consumers funcionen correctamente en diferentes escenarios. Además, al detectar posibles errores en etapas tempranas del desarrollo, reducimos costos y evitamos problemas en producción.
Uso de @EmbeddedKafka para pruebas de integración de Producers y Consumers
Al desarrollar aplicaciones con Spring Boot 4 y Apache Kafka, es fundamental realizar pruebas de integración que validen la interacción real entre Producers y Consumers. Para ello, podemos utilizar la anotación @EmbeddedKafka, que nos permite ejecutar una instancia de Kafka embebida durante nuestras pruebas, sin necesidad de un clúster externo.
La anotación @EmbeddedKafka proporciona un entorno de Kafka en memoria, facilitando la ejecución de pruebas integrales que incluyen la serialización, deserialización y el procesamiento real de mensajes. A continuación, exploraremos cómo configurar y utilizar esta herramienta en nuestras pruebas.
Para empezar, es necesario agregar la dependencia de Embedded Kafka en nuestro archivo build.gradle o pom.xml. Si utilizamos Gradle, añadimos:
testImplementation 'org.springframework.kafka:spring-kafka-test'
Esta biblioteca nos ofrece clases y utilidades específicas para pruebas con Kafka, incluyendo @EmbeddedKafka.
En nuestras pruebas, anotamos la clase de test con @EmbeddedKafka, indicando las propiedades necesarias:
@EmbeddedKafka(partitions = 1, topics = { "test-topic" })
@SpringBootTest
public class KafkaIntegrationTest {
// ...
}
Aquí, partitions define el número de particiones para los topics especificados, y topics es un array con los nombres de los topics que utilizaremos en las pruebas. La anotación @SpringBootTest carga el contexto completo de Spring, lo cual es esencial para pruebas de integración.
Supongamos que tenemos un Producer que envía mensajes a Kafka:
@Service
public class KafkaProducerService {
private final KafkaTemplate<String, String> kafkaTemplate;
public KafkaProducerService(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage(String message) {
kafkaTemplate.send("test-topic", message);
}
}
Y un Consumer que recibe esos mensajes:
@Component
public class KafkaConsumerService {
@KafkaListener(topics = "test-topic", groupId = "test-group")
public void listen(String message) {
// Procesamiento del mensaje
System.out.println("Mensaje recibido: " + message);
}
}
En nuestras pruebas, queremos verificar que el Producer envía correctamente los mensajes y que el Consumer los recibe y procesa adecuadamente. Para ello, implementamos un test de integración utilizando @EmbeddedKafka:
@EmbeddedKafka(partitions = 1, topics = { "test-topic" })
@SpringBootTest
public class KafkaIntegrationTest {
@Autowired
private KafkaProducerService producerService;
@Autowired
private EmbeddedKafkaBroker embeddedKafkaBroker;
private Consumer<String, String> consumer;
@BeforeEach
void setUp() {
Map<String, Object> consumerProps = KafkaTestUtils.consumerProps(
"test-group", "true", embeddedKafkaBroker);
consumerProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
var consumerFactory = new DefaultKafkaConsumerFactory<String, String>(
consumerProps, new StringDeserializer(), new StringDeserializer());
consumer = consumerFactory.createConsumer();
embeddedKafkaBroker.consumeFromAnEmbeddedTopic(consumer, "test-topic");
}
@AfterEach
void tearDown() {
consumer.close();
}
@Test
void testKafkaProducerAndConsumer() {
var message = "Hola, Kafka!";
producerService.sendMessage(message);
var records = KafkaTestUtils.getRecords(consumer);
assertThat(records.count()).isGreaterThan(0);
var record = records.iterator().next();
assertThat(record.value()).isEqualTo(message);
}
}
En este ejemplo, utilizamos KafkaTestUtils para configurar el Consumer y consumir mensajes del topic embebido. La clave está en:
- Configuración del Consumer: Creamos un
Consumerreal que se conecta alEmbeddedKafkaBrokerutilizando las propiedades adecuadas. - Consumo de mensajes: Utilizamos
KafkaTestUtils.getRecords(consumer)para obtener los registros que han sido publicados en el topic. - Verificaciones: Utilizamos las aserciones de AssertJ para comprobar que el mensaje enviado es igual al recibido.
Es importante destacar que, dado que estamos trabajando con un entorno real de Kafka, las pruebas de integración pueden detectar problemas que las pruebas unitarias con mocks no revelarían, como errores de configuración o problemas de serialización.
Si necesitamos personalizar las propiedades de Kafka durante las pruebas, podemos utilizar la anotación @TestPropertySource o definir un archivo application-test.properties. Por ejemplo:
@TestPropertySource(properties = {
"spring.kafka.consumer.auto-offset-reset=earliest",
"spring.kafka.consumer.group-id=test-group",
"spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer",
"spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer"
})
Esto nos permite ajustar el comportamiento del Producer y Consumer según nuestras necesidades durante las pruebas.
Otro aspecto relevante es la necesidad de esperar a que el Consumer procese los mensajes, ya que el procesamiento es asíncrono. Podemos utilizar herramientas como CountDownLatch para sincronizar nuestras pruebas:
@Component
public class KafkaConsumerService {
private final CountDownLatch latch = new CountDownLatch(1);
private String payload;
@KafkaListener(topics = "test-topic", groupId = "test-group")
public void listen(String message) {
payload = message;
latch.countDown();
}
public CountDownLatch getLatch() {
return latch;
}
public String getPayload() {
return payload;
}
}
En el test, inyectamos el KafkaConsumerService y esperamos a que el latch llegue a cero:
@Autowired
private KafkaConsumerService consumerService;
@Test
void testKafkaProducerAndConsumer() throws InterruptedException {
var message = "Hola, Kafka!";
producerService.sendMessage(message);
var latchCompleted = consumerService.getLatch().await(10, TimeUnit.SECONDS);
assertThat(latchCompleted).isTrue();
assertThat(consumerService.getPayload()).isEqualTo(message);
}
De esta manera, garantizamos que el mensaje ha sido consumido y podemos verificar su contenido. El uso de CountDownLatch es una práctica común para sincronizar hilos en pruebas que involucran procesamiento asíncrono.
Además, es posible configurar múltiples topics y grupos de consumidores en @EmbeddedKafka si nuestras pruebas lo requieren:
@EmbeddedKafka(
partitions = 3,
topics = { "topic1", "topic2" },
brokerProperties = { "listeners=PLAINTEXT://localhost:9092", "port=9092" }
)
La propiedad brokerProperties nos permite especificar configuraciones adicionales del broker embebido, como el puerto y los listeners.
Para manejar mensajes con tipos de datos personalizados, es necesario configurar los Serializers y Deserializers adecuados. Por ejemplo, si trabajamos con objetos JSON, podemos usar JsonSerializer y JsonDeserializer de Spring Kafka:
@Bean
public ProducerFactory<String, MyCustomObject> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, embeddedKafkaBroker.getBrokersAsString());
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public ConsumerFactory<String, MyCustomObject> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, embeddedKafkaBroker.getBrokersAsString());
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props, new StringDeserializer(), new JsonDeserializer<>(MyCustomObject.class));
}
Con esta configuración, podemos enviar y recibir objetos de tipo MyCustomObject durante nuestras pruebas, asegurándonos de que la serialización y deserialización funcionan correctamente.
Es crucial mencionar que el uso de @EmbeddedKafka no está limitado a pruebas de Producers y Consumers básicos. También es posible realizar pruebas más complejas, como transacciones, procesamiento de streams y manejo de errores.
Por ejemplo, para probar transacciones en Kafka, debemos asegurarnos de configurar las propiedades transaccionales y validar que los mensajes se envían y consumen dentro de una transacción:
producerFactory.setTransactionIdPrefix("tx-");
kafkaTemplate.executeInTransaction(operations -> {
operations.send("test-topic", "Mensaje transaccional");
return true;
});
En las pruebas, verificamos que el mensaje se haya procesado únicamente si la transacción se completó exitosamente.
Otra ventaja de @EmbeddedKafka es la posibilidad de simular escenarios de fallo, como la caída del broker o la desconexión de un Consumer. Al controlar el entorno de Kafka embebido, podemos ajustar las condiciones para probar la robustez y resiliencia de nuestra aplicación.
Finalmente, es aconsejable separar las pruebas unitarias de las pruebas de integración en diferentes suites, ya que las pruebas con @EmbeddedKafka pueden ser más lentas debido al inicio del broker embebido. Organizar adecuadamente nuestras pruebas garantiza una ejecución eficiente y facilita el mantenimiento del proyecto.
Al implementar @EmbeddedKafka en nuestras pruebas de integración, mejoramos la calidad y confiabilidad de las aplicaciones que utilizan Apache Kafka, asegurando una comunicación efectiva entre Producers y Consumers en un entorno controlado y reproducible.
Testing de Producers y Consumers utilizando TestContainers
En el desarrollo de aplicaciones con Spring Boot 4 y Apache Kafka, es vital realizar pruebas de integración que permitan verificar la interacción real con un clúster de Kafka. Una forma eficaz y moderna de lograrlo es utilizando TestContainers, una biblioteca que facilita la creación y gestión de contenedores de Docker en tests automatizados.
TestContainers nos permite levantar un entorno real de Kafka en contenedores, asegurando que nuestras pruebas se ejecuten en un entorno aislado y reproducible. A continuación, exploraremos cómo configurar y utilizar TestContainers para probar Producers y Consumers en aplicaciones Spring Boot 4.
Para comenzar, es necesario añadir las dependencias de TestContainers en nuestro archivo build.gradle o pom.xml. Si utilizamos Gradle, agregamos:
testImplementation 'org.testcontainers:junit-jupiter:1.19.0'
testImplementation 'org.testcontainers:kafka:1.19.0'
Estas dependencias incluyen el módulo de TestContainers para Kafka y la integración con JUnit 5. Es importante que las versiones sean compatibles con Java y Spring Boot 4 para garantizar la correcta ejecución de las pruebas.
En nuestras clases de test, anotamos la clase con @Testcontainers para indicar que utilizaremos contenedores en las pruebas:
@Testcontainers
@SpringBootTest
public class KafkaTestContainersIntegrationTest {
// ...
}
Dentro de la clase, declaramos el contenedor de Kafka utilizando la anotación @Container:
@Container
public static KafkaContainer kafkaContainer = new KafkaContainer("confluentinc/cp-kafka:7.4.0");
En este ejemplo, estamos utilizando una imagen de Kafka compatible con Confluent Platform. El contenedor se iniciará automáticamente antes de las pruebas y se detendrá al finalizar, gracias a la gestión que proporciona TestContainers.
Para que nuestra aplicación Spring Boot se conecte al contenedor de Kafka durante las pruebas, necesitamos ajustar las propiedades de conexión. Podemos hacerlo utilizando DynamicPropertySource:
@DynamicPropertySource
static void configureKafka(DynamicPropertyRegistry registry) {
registry.add("spring.kafka.bootstrap-servers", kafkaContainer::getBootstrapServers);
}
Esta configuración asegura que el KafkaTemplate y otros componentes de Kafka en nuestra aplicación utilicen la dirección del contenedor iniciado por TestContainers.
Supongamos que tenemos un Producer que envía mensajes al topic test-topic:
@Service
public class KafkaProducerService {
private final KafkaTemplate<String, String> kafkaTemplate;
public KafkaProducerService(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage(String message) {
kafkaTemplate.send("test-topic", message);
}
}
Y un Consumer que escucha en el mismo topic:
@Component
public class KafkaConsumerService {
private final List<String> messages = new CopyOnWriteArrayList<>();
@KafkaListener(topics = "test-topic", groupId = "test-group")
public void receiveMessage(String message) {
messages.add(message);
}
public List<String> getMessages() {
return messages;
}
}
En nuestra clase de prueba, podemos verificar que el Producer envía mensajes y que el Consumer los recibe correctamente:
@Testcontainers
@SpringBootTest
public class KafkaTestContainersIntegrationTest {
@Container
public static KafkaContainer kafkaContainer = new KafkaContainer("confluentinc/cp-kafka:7.4.0");
@Autowired
private KafkaProducerService producerService;
@Autowired
private KafkaConsumerService consumerService;
@DynamicPropertySource
static void configureKafka(DynamicPropertyRegistry registry) {
registry.add("spring.kafka.bootstrap-servers", kafkaContainer::getBootstrapServers);
}
@Test
void testSendAndReceive() throws InterruptedException {
var message = "Hola desde TestContainers!";
producerService.sendMessage(message);
await().atMost(Duration.ofSeconds(10))
.untilAsserted(() -> assertTrue(consumerService.getMessages().contains(message)));
assertEquals(1, consumerService.getMessages().size());
}
}
En este test, utilizamos awaitility para esperar hasta que el mensaje sea recibido por el Consumer, evitando así problemas de sincronización. La biblioteca Awaitility facilita la espera asíncrona en pruebas, asegurando que las aserciones se evalúen correctamente.
Es fundamental asegurarse de que las propiedades de Kafka en nuestra aplicación estén configuradas para permitir la serialización y deserialización adecuada de los mensajes. Por ejemplo, en application-test.properties podemos incluir:
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.consumer.group-id=test-group
Estas propiedades garantizan que tanto el Producer como el Consumer manejen los mensajes de tipo String de forma correcta durante las pruebas.
Si trabajamos con tipos de datos personalizados, necesitamos configurar los Serializers y Deserializers apropiados. Por ejemplo, si utilizamos mensajes en formato JSON, podemos emplear JsonSerializer y JsonDeserializer de la siguiente manera:
spring.kafka.producer.value-serializer=org.springframework.kafka.support.serializer.JsonSerializer
spring.kafka.consumer.value-deserializer=org.springframework.kafka.support.serializer.JsonDeserializer
spring.kafka.consumer.properties.spring.json.trusted.packages=*
Además, es recomendable especificar la clase de destino en el deserializador cuando se trabaja con mensajes JSON:
@JsonDeserialize
public class MyCustomMessage {
private String content;
// Getters y setters
}
Y ajustar el Consumer para recibir objetos de tipo MyCustomMessage:
@Component
public class KafkaConsumerService {
private final List<MyCustomMessage> messages = new CopyOnWriteArrayList<>();
@KafkaListener(topics = "test-topic", groupId = "test-group")
public void receiveMessage(MyCustomMessage message) {
messages.add(message);
}
public List<MyCustomMessage> getMessages() {
return messages;
}
}
Al modificar el test, debemos adaptar la comprobación al nuevo tipo de mensaje:
@Test
void testSendAndReceiveCustomMessage() throws InterruptedException {
var message = new MyCustomMessage("Contenido personalizado");
producerService.sendMessage(message);
await().atMost(Duration.ofSeconds(10))
.untilAsserted(() -> assertEquals(1, consumerService.getMessages().size()));
var receivedMessage = consumerService.getMessages().get(0);
assertEquals("Contenido personalizado", receivedMessage.getContent());
}
En este contexto, es esencial usar buenas prácticas como la reutilización de código y la organización estructurada de las pruebas para mantener la claridad y legibilidad.
Otra característica potente de TestContainers es la posibilidad de configurar la red y las dependencias entre contenedores. Si nuestra aplicación depende de otros servicios, como una base de datos, podemos levantar múltiples contenedores y establecer conexiones entre ellos.
Por ejemplo, si necesitamos una instancia de Zookeeper para pruebas más complejas, podemos definir:
@Container
public static Network network = Network.newNetwork();
@Container
public static GenericContainer<?> zookeeper = new GenericContainer<>("confluentinc/cp-zookeeper:7.4.0")
.withNetwork(network)
.withNetworkAliases("zookeeper")
.withEnv("ZOOKEEPER_CLIENT_PORT", "2181");
@Container
public static KafkaContainer kafkaContainer = new KafkaContainer("confluentinc/cp-kafka:7.4.0")
.withNetwork(network)
.withExternalZookeeper("zookeeper:2181");
Esta configuración permite que el contenedor de Kafka utilice el Zookeeper externo definido en otro contenedor, recreando un entorno más cercano a producción.
Es importante destacar que TestContainers descarga automáticamente las imágenes de Docker necesarias si no están presentes en el sistema, lo que facilita la configuración y ejecución de las pruebas. Sin embargo, es conveniente mantener las versiones actualizadas y compatibles con nuestra aplicación.
Además, podemos personalizar las configuraciones del broker de Kafka utilizando withEnv o withCommand:
kafkaContainer.withEnv("KAFKA_AUTO_CREATE_TOPICS_ENABLE", "true");
Esta opción es útil para ajustar parámetros específicos y simular diferentes escenarios en nuestras pruebas.
Cuando trabajamos con Spring Boot 4, es posible aprovechar las funcionalidades de configuración automática y perfiles de Spring para simplificar aún más nuestras pruebas. Por ejemplo, podemos definir un perfil test y utilizar @ActiveProfiles("test") en nuestras clases de prueba para cargar propiedades específicas.
Otra ventaja de utilizar TestContainers es la posibilidad de ejecutar las pruebas en entornos de integración continua sin necesidad de instalar servicios adicionales. Al ser contenedores de Docker, garantizamos que las pruebas sean consistentes en diferentes máquinas y configuraciones.
Para mejorar la eficiencia en las pruebas, podemos considerar el uso de una clase base abstracta que configure los contenedores y proporcione métodos utilitarios. De esta forma, evitamos duplicar código y facilitamos el mantenimiento:
@Testcontainers
@SpringBootTest
public abstract class AbstractKafkaTest {
@Container
public static KafkaContainer kafkaContainer = new KafkaContainer("confluentinc/cp-kafka:7.4.0");
@DynamicPropertySource
static void configureKafka(DynamicPropertyRegistry registry) {
registry.add("spring.kafka.bootstrap-servers", kafkaContainer::getBootstrapServers);
}
}
Luego, nuestras clases de test heredan de esta clase base:
public class KafkaProducerTest extends AbstractKafkaTest {
// Pruebas específicas del Producer
}
public class KafkaConsumerTest extends AbstractKafkaTest {
// Pruebas específicas del Consumer
}
Este enfoque promueve una estructura modular y facilita la expansión de nuestras pruebas a medida que la aplicación crece.
Es relevante mencionar que, al utilizar TestContainers, debemos gestionar adecuadamente los tiempos de inicio y detención de los contenedores para optimizar el rendimiento. Por defecto, los contenedores se crean y destruyen para cada prueba, pero podemos configurar el ciclo de vida para que persistan durante toda la suite de tests:
@Testcontainers
@SpringBootTest
@TestInstance(Lifecycle.PER_CLASS)
public class KafkaTestContainersIntegrationTest {
// ...
}
Al establecer @TestInstance(Lifecycle.PER_CLASS), los contenedores se inician una sola vez antes de todas las pruebas de la clase, reduciendo el tiempo total de ejecución.
En resumen, el uso de TestContainers con @Testcontainers y @Container nos proporciona una herramienta poderosa para realizar pruebas de integración realistas y efectivas en aplicaciones Spring Boot 4 con Apache Kafka. Al aprovechar estas tecnologías, podemos asegurar la calidad y confiabilidad de nuestros Producers y Consumers en entornos que reflejan fielmente el comportamiento en producción.
Testing de Kafka Streams en Spring Boot 4
El testing de aplicaciones que utilizan Kafka Streams en Spring Boot 4 es esencial para garantizar la correcta funcionalidad de las operaciones de procesamiento de datos en tiempo real. Las aplicaciones de Kafka Streams suelen involucrar transformaciones complejas y flujos de datos que requieren una verificación minuciosa. A continuación, exploraremos diferentes estrategias y herramientas para realizar pruebas eficaces de Kafka Streams en un entorno de Spring Boot 4.
Uno de los enfoques más efectivos para realizar pruebas unitarias de la lógica de Kafka Streams es utilizar la clase TopologyTestDriver. Esta clase, proporcionada por la librería de Kafka Streams, permite ejecutar y probar la topología de stream en memoria, sin necesidad de un clúster Kafka real. Esto facilita la validación de la lógica de procesamiento de stream de manera rápida y aislada.
Para comenzar, supongamos que tenemos una aplicación de Kafka Streams que procesa mensajes de un topic de entrada, realiza una transformación y envía los resultados a un topic de salida:
@Configuration
public class KafkaStreamsConfig {
@Bean
public KStream<String, String> kStream(StreamsBuilder builder) {
KStream<String, String> stream = builder.stream("input-topic");
KStream<String, String> transformedStream = stream.mapValues(value -> value.toUpperCase());
transformedStream.to("output-topic");
return stream;
}
}
En este ejemplo, los mensajes recibidos en input-topic son transformados a mayúsculas y enviados a output-topic. Para probar esta lógica, utilizaremos TopologyTestDriver en nuestros tests unitarios.
Primero, necesitamos configurar las propiedades de Kafka Streams para el test:
private Properties getStreamsConfig() {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "test-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "dummy:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
return props;
}
Es importante definir BOOTSTRAP_SERVERS_CONFIG con un valor dummy, ya que no se conectará a un broker real en las pruebas unitarias.
Ahora, en el test, creamos una instancia de TopologyTestDriver y utilizamos TestInputTopic y TestOutputTopic para simular la entrada y verificar la salida:
@Test
void testKafkaStreamsTransformation() {
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> stream = new KafkaStreamsConfig().kStream(builder);
Topology topology = builder.build();
try (TopologyTestDriver testDriver = new TopologyTestDriver(topology, getStreamsConfig())) {
TestInputTopic<String, String> inputTopic = testDriver.createInputTopic(
"input-topic",
new StringSerializer(),
new StringSerializer()
);
TestOutputTopic<String, String> outputTopic = testDriver.createOutputTopic(
"output-topic",
new StringDeserializer(),
new StringDeserializer()
);
inputTopic.pipeInput("key1", "mensaje en minúsculas");
List<KeyValue<String, String>> results = outputTopic.readKeyValuesToList();
assertEquals(1, results.size());
assertEquals("MENSAJE EN MINÚSCULAS", results.get(0).value);
}
}
En este test, enviamos un mensaje al input-topic y verificamos que el mensaje transformado recibido en output-topic es el esperado. El uso de TopologyTestDriver permite probar la lógica de transformación de forma eficiente y controlada.
Además de las pruebas unitarias, es recomendable realizar pruebas de integración para confirmar que los componentes interactúan correctamente en un entorno real de Kafka. Para ello, podemos utilizar @EmbeddedKafka, que levanta un broker Kafka embebido durante las pruebas.
Primero, anotamos nuestra clase de test con @EmbeddedKafka y @SpringBootTest:
@EmbeddedKafka(partitions = 1, topics = { "input-topic", "output-topic" })
@SpringBootTest
public class KafkaStreamsIntegrationTest {
@Autowired
private EmbeddedKafkaBroker embeddedKafkaBroker;
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Test
void testKafkaStreamsIntegration() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(1);
List<String> receivedMessages = new ArrayList<>();
Map<String, Object> consumerProps = new HashMap<>(KafkaTestUtils.consumerProps(
"test-group", "true", embeddedKafkaBroker
));
consumerProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
DefaultKafkaConsumerFactory<String, String> consumerFactory = new DefaultKafkaConsumerFactory<>(
consumerProps, new StringDeserializer(), new StringDeserializer()
);
Consumer<String, String> consumer = consumerFactory.createConsumer();
embeddedKafkaBroker.consumeFromAnEmbeddedTopic(consumer, "output-topic");
Executors.newSingleThreadExecutor().submit(() -> {
ConsumerRecords<String, String> records = KafkaTestUtils.getRecords(consumer);
records.forEach(record -> {
receivedMessages.add(record.value());
latch.countDown();
});
});
kafkaTemplate.send("input-topic", "mensaje de integración");
assertTrue(latch.await(10, TimeUnit.SECONDS));
assertEquals(1, receivedMessages.size());
assertEquals("MENSAJE DE INTEGRACIÓN", receivedMessages.get(0));
}
}
En este test de integración, enviamos un mensaje al input-topic utilizando KafkaTemplate y consumimos el resultado del output-topic con un consumidor real. Utilizamos un CountDownLatch para esperar hasta que el mensaje sea procesado y verificamos que el mensaje recibido es el esperado.
Otra alternativa moderna para realizar pruebas de integración es utilizar TestContainers para levantar contenedores de Kafka durante las pruebas. Este enfoque ofrece mayor flexibilidad y se integra bien con entornos de integración continua.
Primero, incluimos las dependencias necesarias en nuestro archivo de build:
testImplementation 'org.testcontainers:junit-jupiter:1.19.0'
testImplementation 'org.testcontainers:kafka:1.19.0'
Luego, configuramos el contenedor de Kafka en nuestra clase de test:
@Testcontainers
@SpringBootTest
public class KafkaStreamsTestContainersTest {
@Container
public static KafkaContainer kafkaContainer = new KafkaContainer("confluentinc/cp-kafka:7.4.0")
.withExposedPorts(9092);
@DynamicPropertySource
static void kafkaProperties(DynamicPropertyRegistry registry) {
registry.add("spring.kafka.bootstrap-servers", kafkaContainer::getBootstrapServers);
}
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Test
void testKafkaStreamsWithTestContainers() throws InterruptedException {
// Configuración y lógica similar al test anterior
}
}
El uso de TestContainers garantiza que nuestras pruebas se ejecuten en un entorno que refleja fielmente el comportamiento en producción, ya que se utiliza una instancia real de Kafka en un contenedor de Docker.
Es relevante mencionar que, al probar aplicaciones de Kafka Streams, es común necesitar probar operaciones de estado, como agregaciones o joins, que utilizan state stores. En las pruebas unitarias, el uso de TopologyTestDriver simplifica este proceso, ya que gestiona los state stores en memoria.
Por ejemplo, si nuestra topología incluye una operación de conteo:
@Bean
public KStream<String, String> wordCountStream(StreamsBuilder builder) {
KStream<String, String> stream = builder.stream("input-topic");
KTable<String, Long> wordCounts = stream
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.as("counts-store"));
wordCounts.toStream().to("output-topic", Produced.with(Serdes.String(), Serdes.Long()));
return stream;
}
En el test, podemos acceder al state store y verificar su estado:
@Test
void testWordCount() {
StreamsBuilder builder = new StreamsBuilder();
new KafkaStreamsConfig().wordCountStream(builder);
Topology topology = builder.build();
try (TopologyTestDriver testDriver = new TopologyTestDriver(topology, getStreamsConfig())) {
TestInputTopic<String, String> inputTopic = testDriver.createInputTopic(
"input-topic",
new StringSerializer(),
new StringSerializer()
);
TestOutputTopic<String, Long> outputTopic = testDriver.createOutputTopic(
"output-topic",
new StringDeserializer(),
new LongDeserializer()
);
inputTopic.pipeInput(null, "Kafka Streams Testing");
inputTopic.pipeInput(null, "Kafka and Spring Boot");
List<KeyValue<String, Long>> results = outputTopic.readKeyValuesToList();
assertEquals(5, results.size());
assertEquals(Long.valueOf(1), results.get(0).value);
assertEquals("kafka", results.get(0).key);
// Acceder al state store
ReadOnlyKeyValueStore<String, Long> countsStore = testDriver.getKeyValueStore("counts-store");
assertEquals(Long.valueOf(2), countsStore.get("kafka"));
}
}
En este test, validamos que el state store counts-store contiene los conteos correctos para cada palabra. El uso de getKeyValueStore en TopologyTestDriver permite inspeccionar el estado interno de la topología.
Además, es importante considerar que en Spring Boot 4 podemos utilizar @SpringBootTest junto con TestExecutionListener para inicializar el entorno de Kafka Streams antes de ejecutar los tests. Esto es útil cuando las pruebas dependen de la configuración de Spring y de beans gestionados por el contenedor de inversión de control.
Por ejemplo:
@SpringBootTest
public class KafkaStreamsSpringBootTest {
@Autowired
private StreamsBuilderFactoryBean streamsBuilderFactoryBean;
@Test
void testKafkaStreamsWithSpringContext() throws Exception {
KafkaStreams kafkaStreams = streamsBuilderFactoryBean.getKafkaStreams();
// Realizar pruebas utilizando kafkaStreams
}
}
En este caso, obtenemos una instancia de KafkaStreams directamente desde el contexto de Spring, lo que nos permite interactuar con la topología y realizar operaciones más avanzadas durante las pruebas.
Es crucial asegurarse de que los Serde (Serializers/Deserializers) utilizados en las pruebas sean los mismos que en la aplicación real. Esto garantiza que los datos se serialicen y deserialicen correctamente durante las pruebas. Podemos configurar los Serde en las propiedades de Kafka Streams o directamente en el código de test.
Por último, al probar aplicaciones de Kafka Streams, es recomendable incluir pruebas que cubran escenarios de error y excepciones. Por ejemplo, podemos simular mensajes malformados o excepciones en la lógica de transformación para verificar que nuestra aplicación maneja correctamente estos casos.
El testing de Kafka Streams en Spring Boot 4 implica combinar pruebas unitarias con TopologyTestDriver y pruebas de integración utilizando @EmbeddedKafka o TestContainers. Estas herramientas y enfoques permiten validar la lógica de procesamiento de streams y asegurar que nuestras aplicaciones funcionen correctamente en entornos de producción.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Aprender a probar aplicaciones Spring con Apache Kafka. Aprender a usar @EmbeddedKafka. Aprender a probar Producers. Aprender a probar Consumers. Aprender a integrar Kafka con TestContainers.