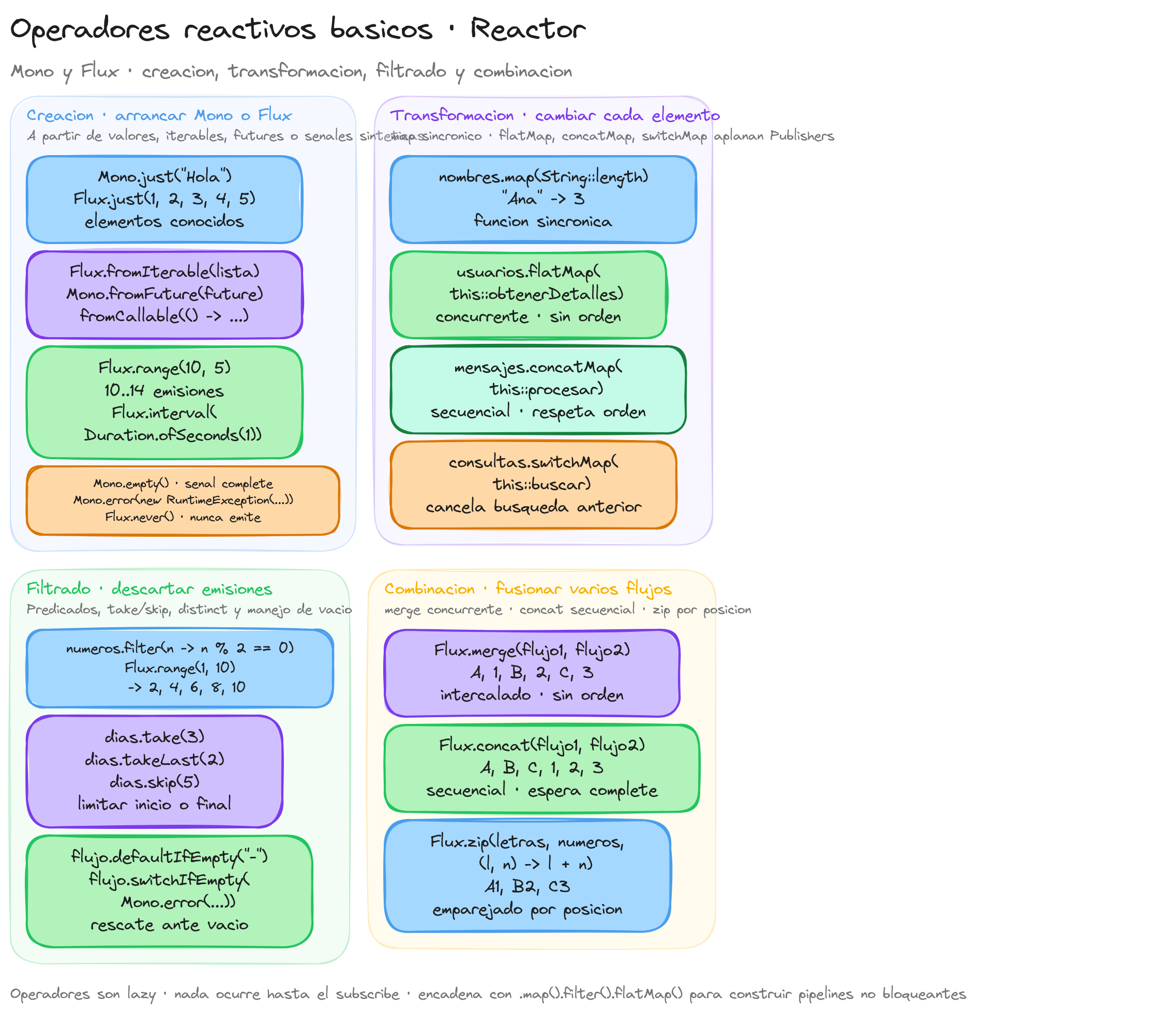
Operadores de creación
Los operadores de creación en Reactor son fundamentales para iniciar flujos reactivos a partir de diferentes fuentes de datos. Estos operadores permiten generar secuencias Mono o Flux según las necesidades específicas de la aplicación.
Operador just
El operador just crea un Mono o Flux a partir de uno o varios elementos proporcionados. Es una forma sencilla de iniciar un flujo con valores conocidos.
Mono<String> monoJust = Mono.just("Hola Mundo");
Flux<Integer> fluxJust = Flux.just(1, 2, 3, 4, 5);
En el ejemplo anterior, monoJust emitirá el mensaje "Hola Mundo" y completará, mientras que fluxJust emitirá una secuencia de números del 1 al 5.
Operador empty
El operador empty genera un Mono o Flux que completa sin emitir ningún elemento. Es útil cuando se desea representar una ausencia de datos sin errores.
Mono<String> monoEmpty = Mono.empty();
Flux<String> fluxEmpty = Flux.empty();
Tanto monoEmpty como fluxEmpty completarán inmediatamente sin emitir valores. Este comportamiento es útil en casos donde un flujo podría o no tener datos, y la ausencia de ellos es un resultado válido.
Operador never
El operador never crea un flujo que no emite elementos ni completa. Se mantiene en ejecución indefinidamente, lo cual puede ser útil en pruebas o situaciones específicas donde se requiere un flujo inactivo.
Mono<String> monoNever = Mono.never();
Flux<String> fluxNever = Flux.never();
Estos flujos no emitirán valores ni señales de finalización, manteniendo al suscriptor en espera de eventos que nunca ocurrirán.
Operador error
El operador error genera un flujo que inmediatamente emite una señal de error. Es útil para representar condiciones de fallo desde el inicio del flujo.
Mono<String> monoError = Mono.error(new RuntimeException("Error ocurrido"));
Flux<String> fluxError = Flux.error(new RuntimeException("Error en el flujo"));
Al suscribirse a estos flujos, se recibirá la señal de error con la excepción proporcionada, permitiendo su manejo mediante operadores de control de errores.
Operador from
El operador from permite crear flujos a partir de distintos tipos de fuentes, como CompletableFuture, Stream, Iterable o incluso otros Publisher.
CompletableFuture<String> future = CompletableFuture.completedFuture("Dato asíncrono");
Mono<String> monoFromFuture = Mono.fromFuture(future);
List<String> lista = Arrays.asList("A", "B", "C");
Flux<String> fluxFromIterable = Flux.fromIterable(lista);
En este ejemplo, monoFromFuture emitirá el resultado del CompletableFuture, mientras que fluxFromIterable emitirá los elementos de la lista proporcionada.
Operador range
El operador range crea un Flux que emite una secuencia de números enteros en un rango específico.
Flux<Integer> fluxRange = Flux.range(10, 5);
El flujo fluxRange emitirá los números enteros desde 10 hasta 14. Este operador es útil para generar secuencias numéricas de forma concisa.
Operador interval
El operador interval genera un Flux que emite secuencias de números largos (Long) a intervalos de tiempo regulares.
Flux<Long> fluxInterval = Flux.interval(Duration.ofSeconds(1));
En este caso, fluxInterval emitirá un número cada segundo, empezando desde cero y aumentando en uno con cada emisión. Este operador es especialmente útil para tareas programadas o temporizadores.
Estos operadores proporcionan diversas formas de iniciar flujos reactivos en Reactor, adaptándose a diferentes escenarios y fuentes de datos. Al combinarlos con otros operadores, es posible construir pipelines de procesamiento de datos complejos y eficientes.
Operadores de transformación
Los operadores de transformación en Reactor son esenciales para modificar los elementos emitidos por flujos reactivos, permitiendo adaptarlos a las necesidades específicas de procesamiento.
El operador map transforma cada elemento emitido por un flujo aplicando una función de manera sincrónica. Es útil para operaciones directas y rápidas sobre los datos.
Flux<String> nombres = Flux.just("Ana", "Luis", "Marta");
Flux<Integer> longitudes = nombres.map(String::length);
En este ejemplo, el Flux longitudes emitirá los valores 3, 4 y 5, correspondientes a la longitud de cada nombre.
Cuando la transformación de cada elemento implica una operación que devuelve un Publisher, como otra fuente de datos reactiva, se utiliza el operador flatMap. Este operador aplanará los flujos resultantes en un único flujo, permitiendo el manejo de operaciones asíncronas.
Flux<String> usuarios = Flux.just("usuario1", "usuario2", "usuario3");
Flux<String> detalles = usuarios.flatMap(this::obtenerDetallesUsuario);
Aquí, obtenerDetallesUsuario es un método que devuelve un Mono<String> con los detalles de cada usuario. El flatMap combinará todos los Mono en un solo Flux detalles.
Si es importante mantener el orden de emisión de los elementos transformados, se debe emplear el operador concatMap. A diferencia de flatMap, concatMap garantiza que las suscripciones a los flujos internos ocurren de forma secuencial.
Flux<String> mensajes = Flux.just("Primero", "Segundo", "Tercero");
Flux<String> procesados = mensajes.concatMap(this::procesarMensaje);
En este caso, procesarMensaje devuelve un Flux<String> por cada mensaje. El uso de concatMap asegura que los mensajes se procesen uno tras otro, respetando el orden original.
El operador switchMap también transforma cada elemento en un Publisher, pero siempre suscribe al flujo más reciente, cancelando los anteriores. Es especialmente útil en situaciones donde solo interesa el último resultado disponible, como en búsquedas en tiempo real.
Flux<String> consultas = obtenerConsultasUsuario();
Flux<List<Resultado>> resultados = consultas.switchMap(this::buscarResultados);
Si el usuario realiza varias consultas rápidamente, switchMap cancelará las búsquedas anteriores y solo procesará la más reciente, evitando cargas innecesarias en el sistema.
Entender cuándo utilizar cada operador es crucial para el desarrollo de aplicaciones reactivas eficientes. Mientras map es adecuado para transformaciones simples, flatMap, concatMap y switchMap ofrecen control sobre operaciones más complejas y asíncronas, permitiendo manejar flujos internos y controlar el comportamiento en cuanto a concurrencia y orden de emisión.
Operadores de filtrado
Los operadores de filtrado en Reactor permiten controlar y limitar las emisiones de flujos reactivos, facilitando la manipulación eficiente de los datos. Estos operadores son esenciales para seleccionar elementos específicos de un Flux o un Mono según distintas condiciones.
Operador filter
El operador filter emite únicamente los elementos que cumplen con una condición determinada. Recibe una función predicado que evalúa cada elemento y decide si debe ser emitido.
Flux<Integer> numeros = Flux.range(1, 10);
Flux<Integer> pares = numeros.filter(n -> n % 2 == 0);
pares.subscribe(System.out::println);
// Salida: 2, 4, 6, 8, 10
En este ejemplo, el Flux pares emitirá solo los números pares del 1 al 10. El operador filter es útil para descartar elementos no deseados basándose en criterios lógicos.
Operador take
El operador take limita el número de emisiones a las primeras N emitidas por el flujo original. Es especialmente útil cuando solo se necesitan los primeros elementos de una secuencia.
Flux<String> dias = Flux.just("Lunes", "Martes", "Miércoles", "Jueves", "Viernes");
Flux<String> primerosTresDias = dias.take(3);
primerosTresDias.subscribe(System.out::println);
// Salida: Lunes, Martes, Miércoles
Aquí, se toman los primeros tres días de la semana laboral. El operador take es una forma sencilla de acotar flujos a una cantidad específica de elementos desde el inicio.
Operador takeLast
El operador takeLast emite los últimos N elementos de un flujo. A diferencia de take, este operador espera a que el flujo original complete para emitir los elementos finales.
Flux<String> letras = Flux.just("A", "B", "C", "D", "E");
Flux<String> ultimasDosLetras = letras.takeLast(2);
ultimasDosLetras.subscribe(System.out::println);
// Salida: D, E
En este caso, el Flux ultimasDosLetras emitirá las últimas dos letras de la secuencia. El operador takeLast es útil cuando se requiere obtener elementos finales después de procesar o recibir todo el flujo.
Operador skip
El operador skip omite las primeras N emisiones del flujo original y emite el resto. Es útil para ignorar elementos iniciales que no son relevantes para el procesamiento posterior.
Flux<Integer> numeros = Flux.range(1, 10);
Flux<Integer> sinPrimerosCinco = numeros.skip(5);
sinPrimerosCinco.subscribe(System.out::println);
// Salida: 6, 7, 8, 9, 10
Aquí, se omiten los primeros cinco números, y el Flux sinPrimerosCinco emite del 6 al 10. El operador skip permite focalizarse en una porción específica del flujo, eliminando emisiones iniciales innecesarias.
Operador skipLast
El operador skipLast descarta las últimas N emisiones de un flujo. Como takeLast, necesita esperar a que el flujo original complete para determinar cuáles elementos omitir al final.
Flux<String> palabras = Flux.just("uno", "dos", "tres", "cuatro", "cinco");
Flux<String> sinUltimasDos = palabras.skipLast(2);
sinUltimasDos.subscribe(System.out::println);
// Salida: uno, dos, tres
En este ejemplo, el Flux sinUltimasDos emite todas las palabras excepto las dos últimas. El operador skipLast es útil cuando se desean excluir elementos finales de un flujo una vez completado.
Combinación de operadores de filtrado
Los operadores de filtrado pueden combinarse para lograr un control más granular sobre las emisiones. Por ejemplo:
Flux<Integer> numeros = Flux.range(1, 100);
Flux<Integer> resultado = numeros
.filter(n -> n % 2 == 0)
.skip(10)
.take(5);
resultado.subscribe(System.out::println);
// Emite los números pares del 22 al 30
En este caso, se filtran los números pares, se omiten los primeros diez y se toman los siguientes cinco. La capacidad de encadenar operadores permite construir flujos reactivos altamente personalizados y eficientes.
Consideraciones sobre la asincronía:
Es importante tener en cuenta que operadores como takeLast y skipLast requieren conocer el tamaño total del flujo, por lo que pueden introducir comportamientos asíncronos que afecten al rendimiento. En flujos infinitos o muy grandes, su uso debe evaluarse cuidadosamente.
Uso de operadores en contexto
En aplicaciones reactivas con Spring WebFlux, estos operadores permiten procesar y transformar datos de manera no bloqueante. Por ejemplo, al manejar peticiones HTTP que devuelven listas filtradas:
@GetMapping("/usuarios/activos")
public Flux<Usuario> obtenerUsuariosActivos() {
return usuarioRepository.findAll()
.filter(Usuario::esActivo)
.take(50);
}
En este controlador, se obtienen todos los usuarios desde el repositorio reactivo y se filtran aquellos que están activos, limitando la respuesta a los primeros 50 usuarios. El uso de operadores de filtrado garantiza respuestas rápidas y eficientes, optimizando el consumo de recursos.
Los operadores de filtrado como filter, take, takeLast, skip y skipLast son herramientas esenciales en la programación reactiva con Reactor. Permiten manipular y controlar la emisión de datos de forma declarativa y eficiente, adaptándose a las necesidades específicas de cada aplicación.
Operadores de combinación
Los operadores de combinación en Reactor permiten fusionar y coordinar múltiples flujos reactivos, facilitando el manejo concurrente de secuencias de datos. Estos operadores son fundamentales para construir flujos complejos y sincronizar emisiones de diferentes fuentes.
Operador merge
El operador merge combina las emisiones de varios flujos Flux en uno solo, emitiendo los elementos tan pronto como estén disponibles. Este operador es adecuado cuando se desea mezclar flujos que pueden emitir datos de forma asíncrona.
Flux<String> flujo1 = Flux.just("A", "B", "C");
Flux<String> flujo2 = Flux.just("1", "2", "3");
Flux<String> flujoCombinado = Flux.merge(flujo1, flujo2);
flujoCombinado.subscribe(System.out::println);
// Posible salida: A, 1, B, 2, C, 3
En este ejemplo, flujoCombinado emitirá los elementos de flujo1 y flujo2 intercalados según la disponibilidad, sin garantizar ningún orden específico. El operador merge es útil cuando el orden de las emisiones no es crítico y se busca maximizar el rendimiento mediante la concurrencia.
Operador concat
El operador concat también combina múltiples flujos Flux, pero a diferencia de merge, asegura que las emisiones ocurren en secuencia, uno tras otro. No iniciará la emisión del siguiente flujo hasta que el anterior haya completado.
Flux<String> flujo1 = Flux.just("A", "B", "C");
Flux<String> flujo2 = Flux.just("1", "2", "3");
Flux<String> flujoConcatenado = Flux.concat(flujo1, flujo2);
flujoConcatenado.subscribe(System.out::println);
// Salida: A, B, C, 1, 2, 3
Aquí, flujoConcatenado emitirá primero todos los elementos de flujo1 y luego los de flujo2, manteniendo el orden de los flujos originales. El operador concat es apropiado cuando es importante preservar la secuencia de los datos.
Operador zip
El operador zip combina varios flujos Flux coordinando sus emisiones en función de la posición. Emite un nuevo elemento cuando todos los flujos fuente han emitido un elemento, combinándolos mediante una función especificada.
Flux<String> letras = Flux.just("A", "B", "C");
Flux<Integer> numeros = Flux.just(1, 2, 3);
Flux<String> flujoEmparejado = Flux.zip(letras, numeros, (letra, numero) -> letra + numero);
flujoEmparejado.subscribe(System.out::println);
// Salida: A1, B2, C3
En este ejemplo, flujoEmparejado emitirá combinaciones de los elementos de letras y números en función de su posición respectiva. El operador zip es útil cuando se requiere sincronizar flujos y crear pares o tuplas de datos correlacionados.
Es importante destacar que si los flujos tienen longitud diferente, zip completará cuando el flujo más corto haya emitido todos sus elementos, ya que no habrá más elementos para combinar.
Operador startWith
El operador startWith permite prefijar elementos o flujos al inicio de un flujo existente. Es decir, las emisiones especificadas en startWith se producirán antes que las del flujo original.
Flux<String> flujoOriginal = Flux.just("X", "Y", "Z");
Flux<String> flujoConPrefijo = flujoOriginal.startWith("A", "B", "C");
flujoConPrefijo.subscribe(System.out::println);
// Salida: A, B, C, X, Y, Z
En este caso, flujoConPrefijo emitirá primero los elementos "A", "B", "C", y luego continuará con las emisiones de flujoOriginal. El operador startWith es útil para agregar valores iniciales o mensajes de encabezado antes de un flujo de datos.
Además, startWith puede recibir otro flujo Flux o un Mono como prefijo:
Flux<String> prefijo = Flux.just("Inicio1", "Inicio2");
Flux<String> flujoConPrefijoFlux = flujoOriginal.startWith(prefijo);
flujoConPrefijoFlux.subscribe(System.out::println);
// Salida: Inicio1, Inicio2, X, Y, Z
Combinación de operadores
Los operadores de combinación pueden encadenarse para construir flujos más elaborados. Por ejemplo, combinar múltiples flujos con prefijos y mantener el orden:
Flux<String> flujo1 = Flux.just("Datos1", "Datos2");
Flux<String> flujo2 = Flux.just("MásDatos1", "MásDatos2");
Flux<String> prefijo = Flux.just("Inicio");
Flux<String> flujoFinal = Flux.concat(prefijo, flujo1, flujo2);
flujoFinal.subscribe(System.out::println);
// Salida: Inicio, Datos1, Datos2, MásDatos1, MásDatos2
En este ejemplo, se utiliza concat para asegurar que las emisiones ocurran en el orden especificado, iniciando con el prefijo y continuando con los datos de flujo1 y flujo2.
Consideraciones sobre la concurrencia y el rendimiento
El operador merge ejecuta los flujos fuente de manera concurrente, lo que puede mejorar el rendimiento en contextos donde los flujos producen emisiones de forma asíncrona o a diferentes ritmos. Sin embargo, es importante manejar adecuadamente la concurrencia y estar atento a posibles condiciones de carrera.
Por otro lado, concat ejecuta los flujos secuencialmente, esperando a que cada flujo complete antes de iniciar el siguiente. Esto garantiza un uso más predecible de los recursos, pero puede ser menos eficiente en términos de tiempo total si los flujos tienen demoras intrínsecas.
Uso de los operadores en contextos prácticos
Estos operadores son especialmente útiles en aplicaciones reactivas que requieren combinar datos de múltiples fuentes, como llamadas a servicios externos, acceso a bases de datos o procesamiento de eventos.
Por ejemplo, supongamos que tenemos dos repositorios reactivos y deseamos obtener y combinar datos de ambos:
Flux<Producto> productosNacionales = productoRepository.findProductosNacionales();
Flux<Producto> productosImportados = productoRepository.findProductosImportados();
Flux<Producto> todosLosProductos = Flux.merge(productosNacionales, productosImportados);
En este caso, todosLosProductos emitirá productos tanto nacionales como importados conforme estén disponibles, aprovechando la asíncronía para mejorar la eficiencia.
Si es necesario procesar los productos en un orden específico, podríamos utilizar concat:
Flux<Producto> todosLosProductosOrdenados = Flux.concat(productosNacionales, productosImportados);
Así, primero se procesarán los productos nacionales y, una vez completados, se iniciará con los importados.
Sincronización de flujos con zip
Para situaciones en las que es necesario sincronizar datos relacionados, zip es la herramienta adecuada. Por ejemplo, combinar información de usuarios y sus direcciones:
Flux<Usuario> usuarios = usuarioRepository.findAll();
Flux<Direccion> direcciones = direccionRepository.findAll();
Flux<UsuarioConDireccion> usuariosConDirecciones = Flux.zip(usuarios, direcciones)
.map(tuple -> new UsuarioConDireccion(tuple.getT1(), tuple.getT2()));
Aquí, se asume que los flujos usuarios y direcciones están alineados de manera que el primer usuario corresponde a la primera dirección, y así sucesivamente. El operador zip coordina las emisiones para que esto sea posible.
Agregando elementos iniciales con startWith
Para situaciones donde se desea iniciar un flujo con valores predeterminados o mensajes de inicio, startWith es la elección adecuada. Por ejemplo, en una aplicación de chat reactiva:
Flux<Mensaje> mensajes = obtenerMensajesChat();
Flux<Mensaje> bienvenida = Flux.just(new Mensaje("Sistema", "Bienvenido al chat"));
Flux<Mensaje> flujoChat = mensajes.startWith(bienvenida);
Así, cuando un usuario se conecta, recibirá primero el mensaje de bienvenida, seguido de los mensajes del chat en tiempo real.
Estos operadores de combinación amplían las capacidades de flujo en Reactor, permitiendo manejar y coordinar múltiples secuencias de datos de manera eficiente y flexible. Su comprensión y uso adecuado son cruciales para desarrollar aplicaciones reactivas robustas con Spring Boot 4.
Operadores de errores
En la programación reactiva con Reactor, el manejo de errores es esencial para garantizar la resiliencia y confiabilidad de las aplicaciones. Los operadores de error permiten gestionar excepciones y eventos inesperados de manera fluida dentro de los flujos reactivos.
Operador onErrorReturn
El operador onErrorReturn ofrece una forma sencilla de proporcionar un valor alternativo en caso de que ocurra un error en el flujo. Al interceptar la señal de error, emite un valor predeterminado y completa el flujo de manera normal.
Flux<String> flujoConError = Flux.just("1", "2", "a", "4")
.map(dato -> {
// Intento de conversión que puede fallar
return Integer.parseInt(dato);
})
.map(numero -> "Número: " + numero)
.onErrorReturn("Valor por defecto en caso de error");
flujoConError.subscribe(System.out::println);
En este ejemplo, al intentar convertir la cadena "a" a entero, se produce una excepción. Gracias a onErrorReturn, el flujo emite "Valor por defecto en caso de error" y completa sin propagar el error al suscriptor.
Operador onErrorResume
El operador onErrorResume permite recuperar de un error cambiando a un flujo alternativo. A diferencia de onErrorReturn, que emite un solo valor, onErrorResume puede continuar la emisión con otro Publisher.
Flux<String> flujoRecuperado = Flux.just("5", "6", "b", "8")
.map(dato -> Integer.parseInt(dato))
.map(numero -> "Número: " + numero)
.onErrorResume(error -> {
// Logica de recuperación con un nuevo flujo
return Flux.just("Error recuperado, continuando con nuevos datos", "9", "10")
.map(nuevoDato -> "Número: " + nuevoDato);
});
flujoRecuperado.subscribe(System.out::println);
En este caso, al ocurrir un error, onErrorResume cambia el flujo original por uno nuevo, permitiendo que la aplicación siga procesando otros datos sin interrumpirse.
Operador doOnNext
El operador doOnNext se utiliza para ejecutar acciones secundarias en cada elemento emitido sin alterar el flujo. Es útil para registrar información, auditar eventos o realizar operaciones auxiliares.
Flux<String> flujoAuditado = Flux.just("X", "Y", "Z")
.doOnNext(elemento -> {
// Acción secundaria, como un registro
System.out.println("Elemento procesado: " + elemento);
})
.map(elemento -> "Procesado: " + elemento);
flujoAuditado.subscribe(System.out::println);
Aquí, doOnNext imprime cada elemento antes de que sea transformado por el operador map. Esto permite monitorear el flujo sin interferir en la secuencia de datos.
Operador doOnError
El operador doOnError permite ejecutar una acción cuando ocurre un error, sin manejarlo ni prevenir su propagación. Es útil para registrar errores o realizar operaciones de limpieza.
Flux<String> flujoConRegistroDeError = Flux.just("10", "20", "c", "40")
.map(dato -> Integer.parseInt(dato))
.doOnError(error -> {
// Registro del error
System.err.println("Error detectado: " + error.getMessage());
})
.map(numero -> "Número: " + numero);
flujoConRegistroDeError.subscribe(
System.out::println,
error -> System.err.println("Suscriptor recibe el error: " + error.getMessage())
);
Aunque doOnError registra el error, no lo maneja. El error sigue propagándose al suscriptor, quien debe decidir cómo reaccionar ante la situación.
Operador doOnComplete
El operador doOnComplete se activa cuando el flujo completa exitosamente, permitiendo ejecutar acciones finales. Es útil para operaciones de notificación, liberación de recursos o actualización de estado.
Flux<String> flujoConFinalizacion = Flux.just("A", "B", "C")
.map(String::toLowerCase)
.doOnComplete(() -> {
// Acción al completar el flujo
System.out.println("Flujo completado exitosamente");
});
flujoConFinalizacion.subscribe(System.out::println);
En este ejemplo, al terminar de procesar todos los elementos, doOnComplete imprime un mensaje indicando la finalización exitosa del flujo.
Combinación de operadores para manejo robusto de errores
Es común combinar varios operadores de error para construir flujos más robustos. Por ejemplo, se puede usar doOnError para registrar el error y luego onErrorResume para recuperarse:
Flux<String> flujoRobusto = Flux.just("100", "200", "d", "400")
.map(dato -> Integer.parseInt(dato))
.doOnError(error -> {
System.err.println("Error registrado: " + error.getMessage());
})
.onErrorResume(error -> {
return Flux.just(300, 400, 500).map(numero -> "Número recuperado: " + numero);
});
flujoRobusto.subscribe(System.out::println);
Aquí, el flujo registra el error y se recupera con nuevos datos, manteniendo la aplicación operativa y evitando interrupciones inesperadas.
Manejo de errores en operaciones asíncronas
En operaciones que involucran llamadas asíncronas, el manejo de errores adquiere mayor relevancia. Por ejemplo, al realizar peticiones a servicios externos:
Mono<String> llamadaExterna = realizarLlamadaExterna()
.doOnError(error -> {
// Registro del error en la llamada externa
System.err.println("Fallo en llamada externa: " + error.getMessage());
})
.onErrorReturn("Respuesta predeterminada");
llamadaExterna.subscribe(System.out::println);
Al tratarse de una operación asíncrona, es fundamental gestionar adecuadamente los errores para proporcionar respuestas consistentes y evitar bloqueos en el flujo principal.
Importancia del manejo de errores en aplicaciones reactivas
El uso adecuado de estos operadores es crítico para mantener la integridad y confiabilidad de las aplicaciones reactivas. Un manejo de errores bien implementado mejora la experiencia del usuario y facilita el mantenimiento del sistema.
Al diseñar flujos con Reactor, es esencial anticipar posibles fallos y decidir cómo gestionarlos. Los operadores onErrorReturn y onErrorResume ofrecen estrategias para continuar operando ante errores, mientras que doOnError y doOnComplete permiten agregar lógica adicional sin alterar la secuencia principal.
Ejemplo práctico en un contexto web
Imagine que se desarrolla un servicio web que procesa solicitudes de usuarios y puede fallar al consultar una base de datos:
@GetMapping("/datos/{id}")
public Mono<ResponseEntity<String>> obtenerDatos(@PathVariable String id) {
return servicioDatos.obtenerDatoPorId(id)
.doOnError(error -> {
// Registro del error
System.err.println("Error al obtener datos: " + error.getMessage());
})
.onErrorReturn("Información no disponible")
.map(dato -> ResponseEntity.ok(dato));
}
En este caso, si ocurre un error al obtener los datos, el servicio responde con un mensaje alternativo, manteniendo la disponibilidad del endpoint y proporcionando al cliente una respuesta coherente.
El manejo de errores mediante operadores como onErrorReturn, onErrorResume, doOnNext, doOnError y doOnComplete es fundamental en la programación reactiva con Reactor. Estos operadores proporcionan las herramientas necesarias para construir flujos resilientes y garantizar que las aplicaciones respondan de manera apropiada ante situaciones inesperadas, mejorando así la robustez y confiabilidad del sistema.
Operadores de acumulación y estadística
En la programación reactiva con Reactor, existen operadores que permiten acumular y realizar operaciones estadísticas sobre los elementos emitidos por un flujo. Los operadores reduce y count son fundamentales para resumir secuencias de datos de manera eficiente.
El operador reduce realiza una operación de acumulación sobre los elementos de un flujo, produciendo un único resultado. Funciona aplicando una función binaria de manera iterativa sobre cada elemento emitido y el acumulador anterior. Este operador es útil para calcular sumas, productos o concatenaciones de elementos.
Por ejemplo, para sumar todos los números emitidos por un Flux:
Flux<Integer> numeros = Flux.range(1, 5); // Emite números del 1 al 5
Mono<Integer> suma = numeros.reduce((acumulador, siguiente) -> acumulador + siguiente);
suma.subscribe(resultado -> System.out.println("La suma es: " + resultado));
// Salida: La suma es: 15
En este caso, reduce acumula los valores sumándolos, y el resultado final es emitido por un Mono. Es importante destacar que el operador retorna un Mono, ya que el resultado es un único valor.
Si se desea proporcionar un valor inicial al acumulador, se puede utilizar la versión sobrecargada de reduce que acepta un valor de identidad:
Mono<Integer> sumaConIdentidad = numeros.reduce(10, (acumulador, siguiente) -> acumulador + siguiente);
sumaConIdentidad.subscribe(resultado -> System.out.println("La suma con identidad es: " + resultado));
// Salida: La suma con identidad es: 25
Aquí, el valor inicial del acumulador es 10, por lo que la suma total será 25. El uso de un valor de identidad puede ser útil en escenarios donde se requiere un punto de partida específico para la acumulación.
El operador count calcula el número total de elementos emitidos por un flujo. Devuelve un Mono con la cantidad de emisiones, lo cual es especialmente útil para estadísticas y métricas.
Por ejemplo, para contar el número de elementos en un flujo de cadenas:
Flux<String> palabras = Flux.just("reactivo", "programación", "asíncrono", "backpressure");
Mono<Long> totalPalabras = palabras.count();
totalPalabras.subscribe(cantidad -> System.out.println("Número de palabras: " + cantidad));
// Salida: Número de palabras: 4
El operador count se encarga de contar las emisiones y proporcionar el total una vez que el flujo completa. Es importante tener en cuenta el tipo de retorno Mono, ya que la cantidad puede ser un número grande y se utiliza Long para representarlo.
Además de estos operadores, es común combinarlos con otros para realizar cálculos más complejos. Por ejemplo, calcular la longitud total de todas las palabras en un flujo:
Mono<Integer> longitudTotal = palabras
.map(String::length)
.reduce(0, (acumulador, longitud) -> acumulador + longitud);
longitudTotal.subscribe(total -> System.out.println("Longitud total de todas las palabras: " + total));
// Salida: Longitud total de todas las palabras: 36
En este ejemplo, primero se mapea cada palabra a su longitud utilizando map, y luego se acumulan las longitudes con reduce, iniciando desde cero. El resultado es la suma de las longitudes de todas las palabras emitidas.
Otra aplicación práctica es concatenar todas las cadenas de un flujo en una sola cadena:
Mono<String> fraseCompleta = palabras.reduce((acumulador, siguiente) -> acumulador + " " + siguiente);
fraseCompleta.subscribe(frase -> System.out.println("Frase completa: " + frase));
// Salida: Frase completa: reactivo programación asíncrono backpressure
El operador reduce permite combinar las palabras en una única frase. Este patrón es útil para generar resultados agregados a partir de emisiones individuales.
Es relevante mencionar que si se utiliza reduce en un flujo vacío, el resultado será un Mono vacío, ya que no hay elementos para acumular. Para manejar este caso, se puede proporcionar un valor de identidad o utilizar el operador defaultIfEmpty:
Flux<Integer> flujoVacio = Flux.empty();
Mono<Integer> sumaVacia = flujoVacio.reduce((a, b) -> a + b)
.defaultIfEmpty(0); // Proporciona un valor por defecto si el Mono está vacío
sumaVacia.subscribe(resultado -> System.out.println("Resultado en flujo vacío: " + resultado));
// Salida: Resultado en flujo vacío: 0
El operador defaultIfEmpty emite un valor predeterminado en caso de que el Mono generado por reduce no emita ningún elemento debido a un flujo vacío.
En cuanto al operador count, también puede ser útil en combinación con otros operadores para realizar validaciones o controlar el flujo de la aplicación. Por ejemplo, verificar si un flujo contiene un número específico de elementos:
Mono<Boolean> tieneTresElementos = palabras.count()
.map(cantidad -> cantidad == 3);
tieneTresElementos.subscribe(esTres -> System.out.println("¿El flujo tiene tres elementos? " + esTres));
// Salida: ¿El flujo tiene tres elementos? false
En este caso, se cuenta el número de palabras y luego se verifica si la cantidad es igual a tres, emitiendo un valor booleano.
Para flujos grandes, es importante considerar el impacto en el rendimiento al utilizar estos operadores, ya que reduce y count requieren procesar todos los elementos antes de emitir el resultado final. En situaciones donde el flujo es infinito o muy extenso, puede ser necesario aplicar operadores como take para limitar el número de emisiones:
Flux<Long> flujoInfinito = Flux.interval(Duration.ofMillis(100));
Mono<Long> conteoLimitado = flujoInfinito
.take(50) // Toma solo los primeros 50 elementos
.count();
conteoLimitado.subscribe(cantidad -> System.out.println("Cantidad de elementos tomados: " + cantidad));
// Salida: Cantidad de elementos tomados: 50
Aquí, el operador take limita el flujo a las primeras 50 emisiones, permitiendo que count pueda calcular el total sin esperar indefinidamente.
Es relevante aprovechar los operadores de acumulación y estadística para extraer información valiosa de los flujos reactivos. Por ejemplo, calcular el promedio de una serie de números:
Flux<Integer> valores = Flux.just(10, 20, 30, 40, 50);
Mono<Double> promedio = valores
.collectList() // Recopila los elementos en una lista
.flatMap(lista -> {
int suma = lista.stream().mapToInt(Integer::intValue).sum();
double promedioCalculado = (double) suma / lista.size();
return Mono.just(promedioCalculado);
});
promedio.subscribe(valor -> System.out.println("Promedio: " + valor));
// Salida: Promedio: 30.0
En este ejemplo, se utiliza collectList para recopilar todos los elementos emitidos en una lista, y luego se calcula el promedio. Aunque no existe un operador específico average en Reactor, se puede lograr este resultado combinando operadores y aplicando lógica personalizada.
Otro caso de uso es encontrar el valor máximo o mínimo en un flujo:
Mono<Integer> maximo = valores.reduce(Integer::max);
maximo.subscribe(valor -> System.out.println("Valor máximo: " + valor));
// Salida: Valor máximo: 50
Utilizando reduce con Integer::max, se obtiene el valor máximo de los elementos emitidos. De manera similar, se puede utilizar Integer::min para obtener el valor mínimo.
Es fundamental entender que los operadores reduce y count procesan el flujo completo antes de emitir un resultado. Esto significa que se debe tener cautela al utilizarlos en flujos muy largos o potencialmente infinitos, ya que pueden causar consumo excesivo de memoria o bloquear la emisión indefinidamente.
En aplicaciones donde se requiere un procesamiento más eficiente de grandes volúmenes de datos, es recomendable explorar operadores como reduce con reducción parcial o técnicas de ventana (windowing), aunque estas caen fuera del alcance de esta sección.
Finalmente, es importante mencionar que los operadores de acumulación y estadística son esenciales para analizar y resumir datos en aplicaciones reactivas. Su uso adecuado permite extraer insights y realizar cálculos agregados de manera declarativa, aprovechando el modelo reactivo para procesar secuencias de datos de forma eficiente y no bloqueante.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Operadores de creación. Operadores de transformación. Operadores de filtrado. Operadores de combinación. Operadores de errores. Operadores de acumulación y estadística.