Introducción teórica a Spring Data
Spring Data es un proyecto paraguas dentro del ecosistema Spring que simplifica significativamente el acceso a datos en aplicaciones Java. Su objetivo principal es reducir la cantidad de código repetitivo que tradicionalmente se requiere para implementar capas de acceso a datos, proporcionando una abstracción consistente sobre diferentes tecnologías de persistencia.
Capas de persistencia con Spring Data JPA
graph TD
App[Aplicación Spring Boot] --> Service[Service con lógica de negocio]
Service --> Repo[Repository interface Spring Data JPA]
Repo --> JPA[JPA especificación]
JPA --> Hib[Hibernate implementación]
Hib --> JDBC[JDBC driver]
JDBC --> DB["(Base de datos relacional)"]
¿Qué problema resuelve Spring Data?
En el desarrollo tradicional de aplicaciones, los desarrolladores deben escribir una gran cantidad de código para realizar operaciones básicas de CRUD (Create, Read, Update, Delete) contra bases de datos. Este código suele ser repetitivo y propenso a errores, especialmente cuando se trabaja con múltiples entidades o diferentes sistemas de almacenamiento.
Spring Data elimina esta complejidad mediante la generación automática de implementaciones de repositorios basándose únicamente en interfaces que definimos. Esto significa que podemos declarar métodos de acceso a datos sin necesidad de implementar su lógica, ya que Spring Data se encarga de generar automáticamente el código necesario.
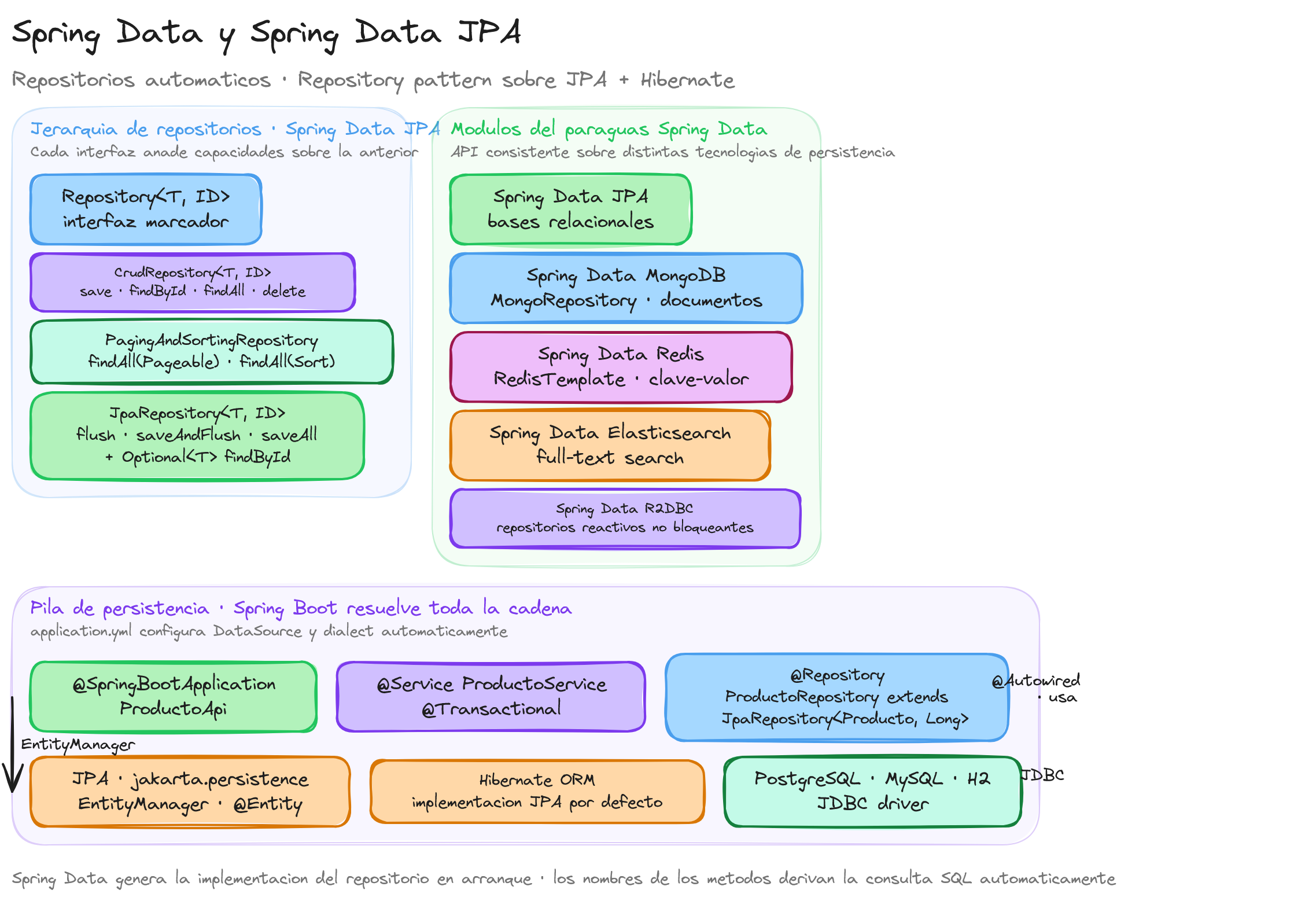
Arquitectura modular de Spring Data
Spring Data está organizado como un conjunto de módulos especializados, cada uno diseñado para trabajar con tecnologías específicas de persistencia:
- Spring Data JPA: Para bases de datos relacionales usando JPA/Hibernate
- Spring Data MongoDB: Para bases de datos de documentos MongoDB
- Spring Data Redis: Para almacenes clave-valor Redis
- Spring Data Elasticsearch: Para motores de búsqueda Elasticsearch
- Spring Data Cassandra: Para bases de datos NoSQL Cassandra
Esta arquitectura modular permite que los desarrolladores utilicen una API consistente independientemente del sistema de almacenamiento subyacente, facilitando el cambio entre diferentes tecnologías de persistencia sin modificar significativamente el código de la aplicación.
Conceptos fundamentales
El núcleo de Spring Data se basa en varios conceptos clave que proporcionan su funcionalidad:
Repositorios automáticos: Spring Data genera automáticamente implementaciones de interfaces de repositorio, eliminando la necesidad de escribir código de acceso a datos básico. Simplemente definimos una interfaz que extienda de las interfaces base proporcionadas por Spring Data.
Consultas derivadas: Permite crear consultas automáticamente basándose en los nombres de los métodos. Por ejemplo, un método llamado findByNombreAndEdad generará automáticamente una consulta que busque por nombre y edad.
Consultas personalizadas: Para casos más complejos, Spring Data permite definir consultas personalizadas usando anotaciones o archivos de configuración, manteniendo la flexibilidad cuando se necesita un control más granular.
Paginación y ordenación: Proporciona soporte integrado para paginación y ordenación de resultados, características esenciales en aplicaciones que manejan grandes volúmenes de datos.
Ventajas de usar Spring Data
La adopción de Spring Data aporta múltiples beneficios al desarrollo de aplicaciones:
- Reducción significativa de código: Elimina la necesidad de escribir implementaciones repetitivas de operaciones CRUD
- Consistencia entre proyectos: Proporciona una API uniforme independientemente de la tecnología de persistencia utilizada
- Mantenibilidad mejorada: Al reducir el código personalizado, se minimizan los puntos de fallo y se facilita el mantenimiento
- Integración nativa con Spring: Se integra perfectamente con el contenedor de inversión de control de Spring y sus características de inyección de dependencias
- Flexibilidad: Permite tanto generación automática como personalización manual cuando se requiere funcionalidad específica
Spring Data representa un cambio de paradigma en cómo abordamos el acceso a datos en aplicaciones Spring, transformando una tarea tradicionalmente compleja y propensa a errores en una experiencia más declarativa y productiva.
Introducción teórica a Spring Data JPA
Spring Data JPA es el módulo más utilizado del ecosistema Spring Data, específicamente diseñado para simplificar el trabajo con bases de datos relacionales. Este módulo actúa como una capa de abstracción sobre JPA (Java Persistence API), proporcionando funcionalidades adicionales que hacen que el desarrollo con bases de datos relacionales sea más eficiente y menos propenso a errores.
¿Qué es JPA y por qué Spring Data JPA?
JPA (Java Persistence API) es una especificación estándar de Java que define cómo mapear objetos Java a tablas de bases de datos relacionales. Sin embargo, trabajar directamente con JPA requiere escribir una cantidad considerable de código repetitivo para operaciones básicas como guardar, buscar, actualizar y eliminar entidades.
Spring Data JPA se construye sobre esta especificación añadiendo automatización inteligente y convenciones sobre configuración. Mientras que JPA nos proporciona las herramientas básicas para el mapeo objeto-relacional, Spring Data JPA nos ofrece repositorios que generan automáticamente las implementaciones de nuestras operaciones de acceso a datos.
Características principales de Spring Data JPA
Repositorios automáticos: Spring Data JPA puede generar automáticamente implementaciones completas de repositorios basándose únicamente en interfaces. Esto significa que podemos definir métodos de acceso a datos sin escribir ni una sola línea de implementación.
Consultas por convención de nombres: Una de las características más destacadas es la capacidad de crear consultas automáticamente basándose en los nombres de los métodos. El framework analiza el nombre del método y genera la consulta SQL correspondiente.
Soporte para consultas JPQL y SQL nativo: Cuando necesitamos consultas más complejas, Spring Data JPA permite definir consultas personalizadas usando JPQL (Java Persistence Query Language) o SQL nativo directamente en las interfaces de repositorio.
Gestión automática de transacciones: Se integra perfectamente con el sistema de gestión de transacciones de Spring, proporcionando control transaccional automático para nuestras operaciones de base de datos.
Jerarquía de interfaces de repositorio
Spring Data JPA proporciona una jerarquía bien estructurada de interfaces que podemos extender según nuestras necesidades:
Repository: La interfaz base que actúa como marcador. No proporciona métodos, pero identifica nuestras interfaces como repositorios de Spring Data.
CrudRepository: Extiende Repository y proporciona métodos básicos de CRUD como save(), findById(), findAll(), deleteById(), etc.
PagingAndSortingRepository: Añade capacidades de paginación y ordenación a las operaciones básicas de CRUD, esencial para manejar grandes conjuntos de datos.
JpaRepository: La interfaz más completa que combina todas las anteriores y añade funcionalidades específicas de JPA como flush(), saveAndFlush(), y operaciones por lotes.
Consultas derivadas: el corazón de Spring Data JPA
Una de las funcionalidades más innovadoras de Spring Data JPA es su capacidad para derivar consultas automáticamente a partir de los nombres de los métodos. El framework analiza el nombre del método y construye la consulta SQL correspondiente.
Esta funcionalidad sigue patrones específicos donde las palabras clave como findBy, countBy, deleteBy indican el tipo de operación, seguidas por los nombres de las propiedades de la entidad y operadores lógicos como And, Or, Between, LessThan, etc.
El sistema es lo suficientemente inteligente como para manejar relaciones entre entidades, permitiendo navegar por asociaciones usando la notación de punto en los nombres de los métodos.
Integración con el ecosistema Spring Boot
En el contexto de Spring Boot, Spring Data JPA se integra de manera transparente gracias a la configuración automática. Spring Boot detecta automáticamente las dependencias de JPA en el classpath y configura todos los componentes necesarios como el EntityManager, el DataSource y los repositorios.
Esta integración incluye la configuración automática de Hibernate como implementación JPA por defecto, la creación automática del esquema de base de datos basándose en las entidades, y la configuración de pools de conexiones optimizados.
Ventajas específicas de Spring Data JPA
Productividad mejorada: Elimina la necesidad de escribir implementaciones de DAO (Data Access Object) tradicionales, reduciendo significativamente el tiempo de desarrollo.
Menos errores: Al generar automáticamente las implementaciones, se reducen los errores humanos típicos en el código de acceso a datos.
Mantenibilidad: El código resultante es más limpio y fácil de mantener, ya que la lógica de acceso a datos se concentra en interfaces declarativas.
Flexibilidad: Permite tanto generación automática como personalización manual, adaptándose a diferentes niveles de complejidad en los requisitos de acceso a datos.
Optimización automática: Spring Data JPA incluye optimizaciones automáticas como lazy loading, caching de consultas y batch processing que mejoran el rendimiento sin intervención manual.
Spring Data JPA representa la evolución natural del acceso a datos en aplicaciones Java, combinando la robustez de JPA con la simplicidad y elegancia que caracteriza al ecosistema Spring.
Introducción teórica al patrón Repository
El patrón Repository es un patrón de diseño arquitectónico que actúa como una capa de abstracción entre la lógica de negocio de una aplicación y la capa de acceso a datos. Su propósito fundamental es encapsular la lógica necesaria para acceder a las fuentes de datos, centralizando las consultas y proporcionando una interfaz más orientada a objetos para acceder a la capa de datos.
Origen y propósito del patrón
Este patrón fue popularizado por Eric Evans en su libro "Domain-Driven Design" y Martin Fowler en "Patterns of Enterprise Application Architecture". Su objetivo principal es crear una separación clara entre la lógica de dominio y la lógica de acceso a datos, permitiendo que el código de negocio se mantenga independiente de los detalles específicos de cómo se almacenan y recuperan los datos.
El patrón Repository simula una colección de objetos en memoria, proporcionando métodos para agregar, eliminar y consultar objetos como si estuviéramos trabajando con una colección estándar de Java, pero con la persistencia manejada de forma transparente en segundo plano.
Estructura conceptual del patrón
Interfaz Repository: Define el contrato que específica qué operaciones están disponibles para trabajar con una entidad específica. Esta interfaz actúa como un punto de acceso unificado para todas las operaciones relacionadas con esa entidad.
Implementación concreta: Contiene la lógica específica para interactuar con el mecanismo de persistencia elegido, ya sea una base de datos relacional, un almacén NoSQL, o incluso archivos. Esta implementación traduce las operaciones del dominio en operaciones específicas del sistema de almacenamiento.
Entidad de dominio: Representa los objetos del negocio que necesitan ser persistidos. El Repository se encarga de convertir estos objetos de dominio en representaciones adecuadas para el almacenamiento y viceversa.
Beneficios arquitectónicos
Desacoplamiento: El patrón Repository desacopla la lógica de negocio de los detalles de implementación del acceso a datos. Esto significa que podemos cambiar el sistema de almacenamiento sin afectar la lógica de negocio de la aplicación.
Testabilidad mejorada: Al trabajar con interfaces, podemos crear fácilmente implementaciones mock para las pruebas unitarias, permitiendo probar la lógica de negocio sin depender de una base de datos real.
Centralización de consultas: Todas las consultas relacionadas con una entidad específica se concentran en un solo lugar, facilitando el mantenimiento y evitando la duplicación de lógica de acceso a datos a lo largo de la aplicación.
Flexibilidad en el almacenamiento: El patrón permite cambiar entre diferentes tecnologías de persistencia (SQL, NoSQL, archivos, servicios web) sin modificar el código que utiliza el Repository.
Tipos de operaciones en un Repository
Los Repositories típicamente proporcionan varios tipos de operaciones organizadas por su propósito:
Operaciones de consulta: Métodos para recuperar entidades basándose en diferentes criterios. Estas operaciones no modifican el estado de los datos y suelen incluir búsquedas por identificador, por propiedades específicas, o consultas más complejas con múltiples criterios.
Operaciones de comando: Métodos que modifican el estado de los datos, incluyendo la creación de nuevas entidades, actualización de entidades existentes, y eliminación de entidades del almacén de datos.
Operaciones de agregación: Métodos que realizan cálculos sobre conjuntos de datos, como contar elementos que cumplen ciertos criterios, calcular sumas o promedios, o determinar valores máximos y mínimos.
Repository vs DAO: diferencias conceptuales
Aunque el patrón Repository y el patrón DAO (Data Access Object) pueden parecer similares, existen diferencias conceptuales importantes:
El patrón DAO se centra en proporcionar una interfaz para acceder a una fuente de datos específica, típicamente mapeando directamente a las operaciones de la base de datos. Su enfoque es más técnico y orientado a la persistencia.
El patrón Repository, por el contrario, se centra en el dominio del negocio y simula una colección de objetos en memoria. Su interfaz está diseñada desde la perspectiva del dominio, no desde la perspectiva de la base de datos.
Implementación conceptual básica
Un Repository típico define métodos que reflejan el lenguaje del dominio de la aplicación. En lugar de pensar en términos de tablas y consultas SQL, pensamos en términos de colecciones de objetos de negocio.
La implementación interna del Repository se encarga de traducir estas operaciones orientadas al dominio en las operaciones específicas del sistema de persistencia elegido, manteniendo esta complejidad oculta para los consumidores del Repository.
Ventajas en el contexto de aplicaciones empresariales
Mantenibilidad: Al centralizar la lógica de acceso a datos, los cambios en los requisitos de persistencia se pueden implementar en un solo lugar, reduciendo el impacto de los cambios en toda la aplicación.
Reutilización: Los métodos del Repository pueden ser reutilizados por diferentes partes de la aplicación, evitando la duplicación de lógica de acceso a datos.
Consistencia: El patrón garantiza que todas las operaciones relacionadas con una entidad sigan las mismas convenciones y estándares, mejorando la consistencia del código.
Evolución gradual: Permite evolucionar la estrategia de persistencia de forma gradual, ya que los cambios se encapsulan dentro de la implementación del Repository sin afectar a sus consumidores.
El patrón Repository representa una abstracción fundamental en el diseño de aplicaciones modernas, proporcionando una base sólida para construir capas de acceso a datos mantenibles, testables y flexibles.
Diferencia entre Spring Data JPA, JPA y Hibernate
Para comprender completamente el ecosistema de persistencia en aplicaciones Java modernas, es fundamental entender las diferencias y relaciones entre tres tecnologías que frecuentemente se mencionan juntas: JPA, Hibernate y Spring Data JPA. Aunque están estrechamente relacionadas, cada una cumple un papel específico en la arquitectura de acceso a datos.
JPA: La especificación estándar
JPA (Java Persistence API) es una especificación oficial de Java que define un conjunto de interfaces y anotaciones para el mapeo objeto-relacional. Es importante entender que JPA no es una implementación, sino un estándar que describe cómo debe funcionar la persistencia de objetos Java en bases de datos relacionales.
JPA establece las reglas sobre cómo anotar entidades, cómo definir relaciones entre objetos, cómo realizar consultas usando JPQL, y cómo gestionar el ciclo de vida de las entidades. Sin embargo, por sí sola, JPA no puede ejecutar ninguna operación de base de datos, ya que necesita una implementación concreta que traduzca estas especificaciones en código funcional.
Las anotaciones como @Entity, @Id, @OneToMany, y @ManyToOne pertenecen a la especificación JPA, lo que significa que son portables entre diferentes implementaciones. Esto garantiza que el código que escribimos usando estas anotaciones funcionará independientemente de qué proveedor JPA utilicemos.
Hibernate: La implementación líder
Hibernate es la implementación más popular y madura de la especificación JPA. Desarrollado originalmente antes de que existiera JPA, Hibernate influyó significativamente en el diseño de esta especificación y posteriormente se adaptó para cumplir completamente con el estándar JPA.
Como implementación JPA, Hibernate proporciona toda la funcionalidad real que hace posible la persistencia: genera las consultas SQL, gestiona las conexiones a la base de datos, implementa el cache de primer y segundo nivel, y maneja las transacciones. Además, Hibernate incluye características adicionales que van más allá de la especificación JPA, como tipos de datos personalizados, consultas SQL nativas avanzadas, y optimizaciones específicas de rendimiento.
Hibernate actúa como el motor de persistencia que Spring Data JPA utiliza por defecto en Spring Boot. Cuando definimos entidades con anotaciones JPA, es Hibernate quien se encarga de crear las tablas correspondientes, generar las consultas SQL, y mapear los resultados de vuelta a objetos Java.
Spring Data JPA: La capa de abstracción
Spring Data JPA se sitúa en un nivel superior, proporcionando una capa de abstracción sobre JPA e Hibernate. Su propósito no es reemplazar estas tecnologías, sino simplificar su uso mediante la automatización de tareas repetitivas y la provisión de funcionalidades adicionales.
Spring Data JPA utiliza internamente un proveedor JPA (típicamente Hibernate) para realizar las operaciones reales de base de datos. Sin embargo, añade capacidades como la generación automática de repositorios, consultas derivadas de nombres de métodos, y integración perfecta con el ecosistema Spring.
La relación jerárquica entre estas tecnologías es clara: Spring Data JPA depende de JPA, y JPA necesita una implementación como Hibernate para funcionar. Spring Data JPA actúa como una fachada que simplifica el trabajo con JPA/Hibernate.
Comparación práctica de responsabilidades
Responsabilidades de JPA:
- Definir anotaciones estándar para mapeo objeto-relacional
- Establecer la API para EntityManager y operaciones de persistencia
- Especificar el lenguaje de consultas JPQL
- Definir el modelo de callbacks y listeners de entidades
Responsabilidades de Hibernate:
- Implementar todas las especificaciones de JPA
- Generar y ejecutar consultas SQL optimizadas
- Gestionar el cache de entidades y consultas
- Proporcionar características adicionales como validación automática y tipos personalizados
- Manejar la creación automática de esquemas de base de datos
Responsabilidades de Spring Data JPA:
- Generar automáticamente implementaciones de repositorios
- Crear consultas basándose en nombres de métodos
- Proporcionar soporte integrado para paginación y ordenación
- Integrar con el sistema de transacciones de Spring
- Ofrecer funcionalidades adicionales como auditoría automática
Ventajas de usar las tres tecnologías juntas
La combinación de JPA, Hibernate y Spring Data JPA ofrece beneficios complementarios que hacen que trabajar con bases de datos relacionales sea más eficiente:
Portabilidad: Al usar anotaciones JPA estándar, nuestro código puede funcionar con diferentes implementaciones JPA si fuera necesario, aunque en la práctica Hibernate es la opción predominante.
Robustez: Hibernate proporciona una implementación madura y optimizada que ha sido probada en miles de aplicaciones empresariales durante más de una década.
Productividad: Spring Data JPA elimina la necesidad de escribir código repetitivo de acceso a datos, permitiendo que nos concentremos en la lógica de negocio.
Flexibilidad: Podemos usar características específicas de Hibernate cuando necesitemos funcionalidades avanzadas, mientras mantenemos la simplicidad de Spring Data JPA para operaciones comunes.
Cuándo usar cada nivel de abstracción
Para operaciones básicas de CRUD y consultas simples, Spring Data JPA con sus repositorios automáticos es la opción más productiva. Su capacidad de generar implementaciones automáticamente reduce significativamente el código que necesitamos escribir.
Cuando necesitamos consultas complejas o características específicas de Hibernate como cache de segundo nivel o tipos personalizados, podemos acceder directamente a las APIs de Hibernate mientras mantenemos la estructura general de Spring Data JPA.
Para casos donde necesitamos máximo control sobre las consultas SQL o queremos usar características muy específicas de la base de datos, podemos usar JPA directamente con EntityManager, aunque esto es menos común en aplicaciones Spring Boot modernas.
Esta arquitectura en capas proporciona la flexibilidad de elegir el nivel de abstracción apropiado para cada situación específica, desde la máxima productividad hasta el control granular, todo dentro del mismo proyecto.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en Spring Boot
Documentación oficial de Spring Boot
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es Spring Data y cómo simplifica el acceso a datos en aplicaciones Java. Conocer la arquitectura modular de Spring Data y sus principales módulos. Entender el funcionamiento y características de Spring Data JPA como capa de abstracción sobre JPA. Aprender el patrón Repository y su importancia en la separación de la lógica de negocio y acceso a datos. Diferenciar entre JPA, Hibernate y Spring Data JPA y sus roles en la persistencia de datos.