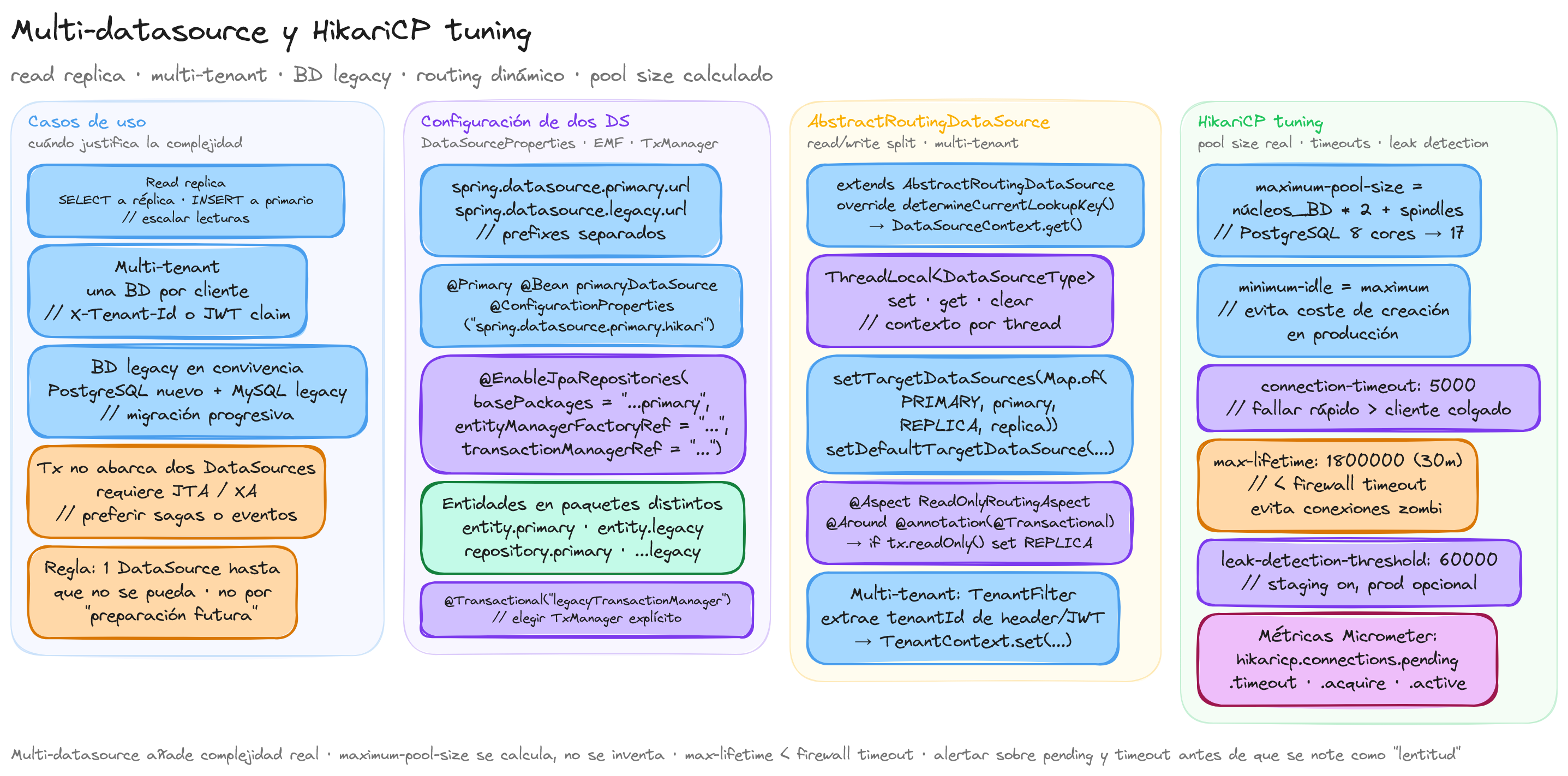
Cuándo necesitas más de un DataSource
Spring Boot ofrece autoconfiguración de un único DataSource por defecto, lo que cubre el 90% de los proyectos. Para el 10% restante hay tres escenarios habituales:
- 1. Read replica: separar lecturas de escrituras a réplicas dedicadas para escalar lecturas. Las consultas de reporting van a réplica; las escrituras al primario.
- 2. Multi-tenant: cada tenant tiene su BD propia. La aplicación selecciona dinámicamente el DataSource según el contexto del usuario.
- 3. BD heredadas en convivencia: la aplicación nueva usa PostgreSQL, pero también consulta una BD legacy en MySQL u Oracle. Cada una con sus entidades.
En estos casos hay que renunciar a la autoconfiguración por defecto y declarar manualmente los DataSource.
Configuración de dos DataSource
spring:
datasource:
primary:
url: jdbc:postgresql://primary:5432/empleados
username: ${DB_PRIMARY_USER}
password: ${DB_PRIMARY_PASSWORD}
hikari:
maximum-pool-size: 20
minimum-idle: 5
pool-name: HikariPrimary
legacy:
url: jdbc:mysql://legacy:3306/empleados_legacy
username: ${DB_LEGACY_USER}
password: ${DB_LEGACY_PASSWORD}
hikari:
maximum-pool-size: 10
minimum-idle: 2
pool-name: HikariLegacy
@Configuration
@EnableJpaRepositories(
basePackages = "com.empresa.empleados.repository.primary",
entityManagerFactoryRef = "primaryEntityManagerFactory",
transactionManagerRef = "primaryTransactionManager"
)
public class PrimaryDataSourceConfig {
@Primary
@Bean(name = "primaryDataSource")
@ConfigurationProperties("spring.datasource.primary.hikari")
public DataSource primaryDataSource(
@Qualifier("primaryProperties") DataSourceProperties props) {
return props.initializeDataSourceBuilder().type(HikariDataSource.class).build();
}
@Primary
@Bean(name = "primaryProperties")
@ConfigurationProperties("spring.datasource.primary")
public DataSourceProperties primaryProperties() {
return new DataSourceProperties();
}
@Primary
@Bean(name = "primaryEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean primaryEntityManagerFactory(
EntityManagerFactoryBuilder builder,
@Qualifier("primaryDataSource") DataSource ds) {
return builder
.dataSource(ds)
.packages("com.empresa.empleados.entity.primary")
.persistenceUnit("primary")
.build();
}
@Primary
@Bean(name = "primaryTransactionManager")
public PlatformTransactionManager primaryTransactionManager(
@Qualifier("primaryEntityManagerFactory") EntityManagerFactory emf) {
return new JpaTransactionManager(emf);
}
}
@Configuration
@EnableJpaRepositories(
basePackages = "com.empresa.empleados.repository.legacy",
entityManagerFactoryRef = "legacyEntityManagerFactory",
transactionManagerRef = "legacyTransactionManager"
)
public class LegacyDataSourceConfig {
@Bean(name = "legacyDataSource")
public DataSource legacyDataSource(
@Qualifier("legacyProperties") DataSourceProperties props) {
return props.initializeDataSourceBuilder().type(HikariDataSource.class).build();
}
@Bean(name = "legacyProperties")
@ConfigurationProperties("spring.datasource.legacy")
public DataSourceProperties legacyProperties() {
return new DataSourceProperties();
}
@Bean(name = "legacyEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean legacyEntityManagerFactory(
EntityManagerFactoryBuilder builder,
@Qualifier("legacyDataSource") DataSource ds) {
return builder
.dataSource(ds)
.packages("com.empresa.empleados.entity.legacy")
.persistenceUnit("legacy")
.build();
}
@Bean(name = "legacyTransactionManager")
public PlatformTransactionManager legacyTransactionManager(
@Qualifier("legacyEntityManagerFactory") EntityManagerFactory emf) {
return new JpaTransactionManager(emf);
}
}
Las entidades se separan en paquetes distintos:
com.empresa.empleados.entity.primary
- Empleado.java <- mapeada a primary
- Departamento.java
com.empresa.empleados.entity.legacy
- EmpleadoLegacy.java <- mapeada a legacy
Y los repositorios respectivamente:
com.empresa.empleados.repository.primary
- EmpleadoRepository.java
com.empresa.empleados.repository.legacy
- EmpleadoLegacyRepository.java
Cada repository se inyecta normalmente; Spring sabe a qué DataSource pertenece por el @EnableJpaRepositories.basePackages.
@Primary y @Transactional
@Primary marca el DataSource por defecto. Si haces @Autowired DataSource ds, te entregan el primario. Si haces @Transactional sin especificar, abre transacción contra el primario.
Para usar el legacy explícitamente:
@Service
@RequiredArgsConstructor
public class MigrationService {
private final EmpleadoLegacyRepository legacyRepo;
private final EmpleadoRepository primaryRepo;
@Transactional("legacyTransactionManager")
public List<EmpleadoLegacyDto> leerLegacy() {
return legacyRepo.findAll();
}
@Transactional // implicit "primaryTransactionManager"
public void migrar(EmpleadoLegacyDto legacy) {
primaryRepo.save(toEmpleado(legacy));
}
}
Importante:
@Transactionalno es transaccional a través de DataSources. Una transacción solo abarca un DataSource. Si necesitas atomicidad cross-datasource, hace falta JTA (XA transactions), que añade complejidad significativa. Lo idiomático es evitar este caso con eventos eventually-consistent o sagas.
Read/write split con AbstractRoutingDataSource
Patrón clásico: enviar SELECT a réplica, INSERT/UPDATE/DELETE al primario. Spring trae AbstractRoutingDataSource que selecciona el DataSource en cada llamada según un contexto:
public class RoutingDataSource extends AbstractRoutingDataSource {
public enum DataSourceType { PRIMARY, REPLICA }
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContext.get();
}
}
public class DataSourceContext {
private static final ThreadLocal<DataSourceType> CONTEXT = new ThreadLocal<>();
public static void set(DataSourceType type) { CONTEXT.set(type); }
public static DataSourceType get() { return CONTEXT.get(); }
public static void clear() { CONTEXT.remove(); }
}
Configuración:
@Bean
public DataSource routingDataSource(
@Qualifier("primaryDataSource") DataSource primary,
@Qualifier("replicaDataSource") DataSource replica) {
var routing = new RoutingDataSource();
routing.setTargetDataSources(Map.of(
DataSourceType.PRIMARY, primary,
DataSourceType.REPLICA, replica
));
routing.setDefaultTargetDataSource(primary);
return routing;
}
Aspecto que selecciona automáticamente:
@Aspect
@Component
public class ReadOnlyRoutingAspect {
@Around("@annotation(org.springframework.transaction.annotation.Transactional)")
public Object route(ProceedingJoinPoint pjp) throws Throwable {
var method = ((MethodSignature) pjp.getSignature()).getMethod();
var tx = method.getAnnotation(Transactional.class);
if (tx != null && tx.readOnly()) {
DataSourceContext.set(DataSourceType.REPLICA);
} else {
DataSourceContext.set(DataSourceType.PRIMARY);
}
try {
return pjp.proceed();
} finally {
DataSourceContext.clear();
}
}
}
Con esto, los métodos anotados con @Transactional(readOnly = true) van a la réplica; los demás al primario:
@Service
public class EmpleadoQueryService {
@Transactional(readOnly = true)
public List<EmpleadoDto> listar() {
// Va a réplica
}
}
@Service
public class EmpleadoCommandService {
@Transactional
public EmpleadoDto crear(EmpleadoCrearDto dto) {
// Va a primario
}
}
Hay que configurar la réplica con transaction-isolation: TRANSACTION_REPEATABLE_READ o READ_COMMITTED y permitir solo SELECT (a nivel de usuario de BD) para evitar escrituras accidentales.
Multi-tenant: un DataSource por tenant
Para multi-tenancy con BD por tenant, el patrón es similar pero el contexto se establece desde la petición (header, JWT claim):
@Component
public class TenantFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain chain) throws ServletException, IOException {
var tenantId = extractTenant(request); // de header X-Tenant-Id o JWT
TenantContext.set(tenantId);
try {
chain.doFilter(request, response);
} finally {
TenantContext.clear();
}
}
}
public class TenantRoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return TenantContext.get();
}
}
Spring Boot 4 + Hibernate también soporta multi-tenancy nativamente con hibernate.multiTenancy = SCHEMA o DATABASE, pero requiere configuración más compleja del MultiTenantConnectionProvider y CurrentTenantIdentifierResolver.
HikariCP tuning para producción
HikariCP es el connection pool por defecto en Spring Boot. Las propiedades que importan:
maximum-pool-size
Tamaño máximo del pool. Cálculo recomendado:
pool_size = ((núcleos_BD * 2) + número_spindles)
Para PostgreSQL en SSD con 8 núcleos: 82 + 1 = 17. Para MySQL en cluster con 16 núcleos: 162 + 1 = 33.
No más alto: pools grandes degradan el rendimiento por contención de locks en la BD. Es un mito que "más conexiones = más rendimiento". A partir de cierto punto, más conexiones causan menor throughput.
spring:
datasource:
hikari:
maximum-pool-size: 20
minimum-idle
Conexiones mínimas siempre abiertas. Por defecto = maximum-pool-size (recomendado en producción para evitar coste de creación).
spring:
datasource:
hikari:
minimum-idle: 20 # mismo que maximum
En desarrollo se puede bajar a 1-2 para no consumir recursos.
connection-timeout
Tiempo máximo que una petición espera a obtener conexión del pool antes de fallar. Por defecto 30 segundos.
spring:
datasource:
hikari:
connection-timeout: 5000 # 5 segundos
5 segundos es razonable: si no hay conexión en 5s, mejor fallar y devolver 503 que dejar al cliente colgado.
idle-timeout y max-lifetime
idle-timeout: tiempo tras el cual una conexión idle se cierra. Default 10 minutos.max-lifetime: tiempo máximo de vida de una conexión. Default 30 minutos.
max-lifetime debe ser menor que el timeout del firewall y del servidor de BD para evitar conexiones zombi:
spring:
datasource:
hikari:
idle-timeout: 600000 # 10 min
max-lifetime: 1800000 # 30 min
keepalive-time: 300000 # 5 min, ping al servidor
leak-detection-threshold
Detecta conexiones abiertas que no se cierran. Si una conexión está fuera del pool más tiempo que este threshold, HikariCP escribe un stacktrace en logs:
spring:
datasource:
hikari:
leak-detection-threshold: 60000 # 60 segundos
Útil en desarrollo y staging. En producción se desactiva (o pone alto, 5 minutos) para evitar overhead.
Métricas con Micrometer
Spring Boot expone métricas de HikariCP automáticamente:
hikaricp.connections{pool="HikariPrimary"} # total
hikaricp.connections.active{pool="HikariPrimary"} # en uso
hikaricp.connections.idle{pool="HikariPrimary"} # idle
hikaricp.connections.pending{pool="HikariPrimary"} # esperando
hikaricp.connections.acquire{pool="HikariPrimary"} # tiempo medio adquirir
hikaricp.connections.usage{pool="HikariPrimary"} # tiempo medio uso
hikaricp.connections.timeout{pool="HikariPrimary"} # timeouts contador
Métricas críticas en producción:
pendingconstantemente > 0: pool saturado, aumentarmaximum-pool-sizeo investigar consultas lentas.timeout> 0: conexiones rechazadas. Cliente recibe 503. Crítico.acquirep99 alto: contención. Mismo diagnóstico que pending.activesiempre cerca del máximo: pool al límite.
Dashboard de Grafana típico muestra estas cuatro métricas a la vez.
Anti-patrones
Pool grande "por si acaso"
maximum-pool-size: 200 en una BD con 8 núcleos colapsa la BD. La BD pasa más tiempo cambiando contextos que ejecutando queries.
Conexiones que no se cierran
Código que usa DataSource.getConnection() directamente y olvida cerrar genera leaks que el pool no detecta inmediatamente. Usar siempre try-with-resources:
try (var conn = dataSource.getConnection();
var stmt = conn.prepareStatement(sql);
var rs = stmt.executeQuery()) {
// ...
}
Con Spring JdbcTemplate o JPA esto se gestiona automáticamente.
TX larga sosteniendo la conexión
Una transacción que dura 10 segundos mantiene una conexión ocupada todo ese tiempo. Si el pool tiene 20 conexiones y hay 30 peticiones simultáneas, las 10 últimas fallan con timeout.
Optimizar transacciones cortas:
- Mover lógica que no necesita BD fuera del
@Transactional. - Usar
@Transactional(readOnly = true)cuando aplique. - Dividir flujos largos en transacciones pequeñas.
Misma maximum-pool-size en réplica que en primario
La réplica suele recibir más SELECT (informes, dashboards). Puede necesitar pool mayor que el primario:
spring:
datasource:
primary:
hikari:
maximum-pool-size: 20
replica:
hikari:
maximum-pool-size: 40
Buenas prácticas
- Multi-datasource solo cuando es necesario: read replica con tráfico significativo, multi-tenant real, BD heredada que conviene mantener separada. No por "preparación futura".
maximum-pool-sizecalculado, no fijado por costumbre. La fórmula es real.max-lifetime< firewall timeout. Evita reconexiones forzadas que generan errores transitorios.leak-detection-thresholdactivo en staging. Detecta leaks antes de producción.- Métricas Micrometer + alertas sobre
pendingytimeout. Sin estas alertas, una saturación de pool aparece como "lentitud" sin causa aparente. - Documentación clara del routing: si hay read/write split o multi-tenant, todo el equipo debe saber qué métodos van a qué DataSource.
- Nunca confiar en routing automático sin tests: añadir tests que verifican que
@Transactional(readOnly = true)realmente va a réplica.
Multi-datasource es una herramienta potente que añade complejidad significativa. La regla es: resolver el problema de hoy con un solo DataSource hasta que no se pueda. Cuando se cruza el umbral, hacerlo con cuidado, métricas y tests.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Configurar múltiples DataSource con sus propios EntityManagerFactory y TransactionManager. Distinguir el datasource primario del secundario con @Primary. Implementar routing dinámico (read/write split, multi-tenant) con AbstractRoutingDataSource. Tunear HikariCP con criterio (pool size, timeouts, leak detection). Monitorizar el pool con Micrometer.