Qué es Kafka Streams
Kafka Streams es una biblioteca de cliente para procesamiento de flujos (streams) y análisis de datos en tiempo real, construida sobre Apache Kafka. Permite a los desarrolladores crear aplicaciones y microservicios que transforman, agregan y enriquecen datos transmitidos a través de tópicos de Kafka, todo ello dentro de una arquitectura distribuida y tolerante a fallos.
A diferencia de spring-kafka, que es un proyecto de Spring para facilitar la integración con Apache Kafka y manejar la producción y consumo de mensajes de forma más sencilla dentro del ecosistema Spring, Kafka Streams se enfoca en el procesamiento y transformación de datos en flujo continuo. Mientras que spring-kafka se utiliza principalmente para aplicaciones que envían y reciben mensajes, Kafka Streams proporciona una API de alto nivel para realizar operaciones complejas como map, filter, join y aggregate sobre los datos en movimiento.
En primer lugar, es necesario asegurarse de que el proyecto tenga las dependencias adecuadas en el archivo pom.xml o build.gradle. Para incluir Kafka Streams en un proyecto Maven, se debe agregar la siguiente dependencia:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-streams</artifactId>
</dependency>
Con las dependencias configuradas, podemos proceder a implementar un Stream que actúe como productor y consumidor. En Kafka Streams, las aplicaciones a menudo consumen datos de uno o más tópicos, los procesan y producen resultados en otros tópicos.
Por tanto, antes de avanzar conviene tener claras las diferencias entre spring-kafka y spring-kafka-streams:
**spring-kafka**:
- Propósito: Proporciona las funcionalidades básicas para interactuar con Apache Kafka, como productores y consumidores estándar, manejo de listeners con anotaciones como
@KafkaListener, y configuraciones básicas de Kafka. - Uso principal: Ideal para aplicaciones que requieren operaciones básicas de producción y consumo de mensajes sin procesamiento avanzado de flujos.
**spring-kafka-streams**:
- Propósito: Extiende las capacidades de
**spring-kafka**integrando Kafka Streams, lo que permite realizar procesamiento de flujos de datos avanzado, como transformaciones, agregaciones, y joins utilizando KStreams y KTables. - Uso principal: Adecuado para aplicaciones que necesitan procesamiento de flujos en tiempo real, análisis continuo de datos, y operaciones de estado.
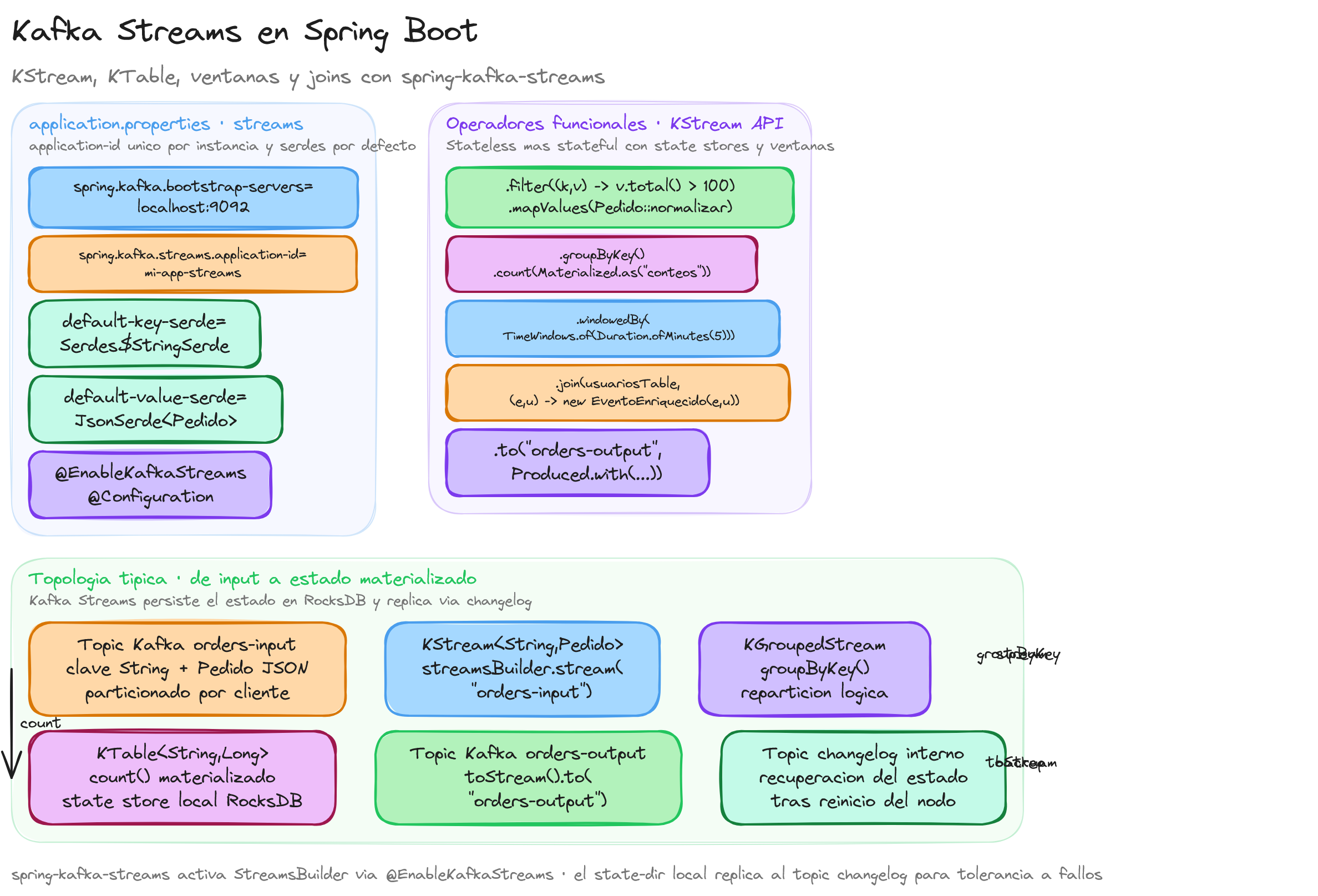
Para configurar Kafka Streams en una aplicación Spring Boot 4, es esencial ajustar el archivo application.properties con las propiedades específicas necesarias. A continuación se muestran las configuraciones básicas:
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.streams.application-id=mi-aplicacion-streams
spring.kafka.streams.auto-startup=true
La propiedad **spring.kafka.bootstrap-servers** define los servidores donde Kafka está corriendo y a los que la aplicación se conectará. El **application-id** es un identificador único para la instancia de la aplicación de streams; es crucial ya que Kafka Streams utiliza este ID para mantener el estado y coordinar el procesamiento en caso de múltiples instancias. La propiedad **auto-startup** determina si el procesamiento de streams debe iniciar automáticamente al arrancar la aplicación.
Además de las configuraciones básicas, es posible especificar propiedades adicionales para ajustar el comportamiento de la aplicación. Por ejemplo, para definir las serdes (serializadores/deserializadores) predeterminados:
spring.kafka.streams.default-key-serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.kafka.streams.default-value-serde=org.apache.kafka.common.serialization.Serdes$LongSerde
Estas propiedades establecen las clases de serde que Kafka Streams utilizará para las claves y valores de los mensajes, garantizando una correcta serialización y deserialización de los datos.
También es fundamental comprender cómo Kafka Streams gestiona el estado interno de las aplicaciones. Si se emplean operaciones de estado, como agregaciones o joins, Kafka Streams almacenará este estado localmente e incluso puede compartirlo a través de tópicos de cambio de registro (changelogs). Para configurar la ubicación de estado y otros parámetros relevantes:
spring.kafka.streams.state-dir=/opt/kafka-streams/state-store
La propiedad **state-dir** indica el directorio donde se almacenará el estado local de la aplicación. Es importante asegurarse de que este directorio tenga suficiente espacio y sea persistente para evitar pérdida de datos en caso de reinicios.
Otro aspecto clave es la gestión de errores y la configuración de la política de retención de registros. Por ejemplo, para aplicar una política de manejo de excepciones durante el procesamiento:
spring.kafka.streams.deserialization-exception-handler=org.apache.kafka.streams.errors.LogAndFailExceptionHandler
Con esta configuración, cualquier error de deserialización hará que la aplicación registre el error y detenga el procesamiento, lo cual puede ser útil para entornos donde la integridad de los datos es crítica.
Finalmente, para optimizar el rendimiento y ajustar parámetros avanzados de Kafka Streams, se pueden incluir propiedades como:
spring.kafka.streams.num-stream-threads=3
spring.kafka.streams.buffered-records-per-partition=1000
La propiedad **num-stream-threads** define el número de hilos de procesamiento que la aplicación utilizará, permitiendo aprovechar mejor los recursos disponibles. **buffered-records-per-partition** controla cuántos registros se almacenarán en el buffer por partición antes de ser procesados, afectando la latencia y el rendimiento.
En resumen, Kafka Streams proporciona una potente herramienta para construir aplicaciones de procesamiento de datos en tiempo real dentro del ecosistema de Spring Boot 4. La correcta configuración del archivo application.properties es esencial para aprovechar al máximo sus capacidades y asegurar un funcionamiento eficiente y fiable.
Implementación de Producers y Consumers con Kafka Streams
Para implementar producers y consumers utilizando Kafka Streams en una aplicación Spring Boot 4, es fundamental comprender cómo integrar las APIs proporcionadas por Kafka Streams dentro del contexto de Spring. A diferencia de la producción y consumo tradicionales con spring-kafka, Kafka Streams ofrece una manera más directa y funcional de procesar flujos de datos.
A continuación, se muestra un ejemplo de cómo definir un bean que configura el procesamiento de un flujo utilizando la anotación @Bean en una clase de configuración. Este bean representará nuestra topología de Kafka Streams.
@Configuration
public class KafkaStreamsConfig {
@Bean
public KStream<String, String> kStream(StreamsBuilder streamsBuilder) {
KStream<String, String> stream = streamsBuilder.stream("input-topic");
stream.mapValues(value -> {
// Procesamiento del valor
return value.toUpperCase();
})
.to("output-topic");
return stream;
}
}
En este ejemplo, se construye un KStream que consume mensajes del tópico **input-topic**. Cada mensaje es transformado a mayúsculas y luego enviado al tópico **output-topic**. La operación **mapValues** es una transformación típica en Kafka Streams que permite manipular los valores de los mensajes.
Es importante destacar que el StreamsBuilder es inyectado automáticamente por Spring Boot gracias a la configuración previa. La integración entre Kafka Streams y Spring Boot facilita la configuración y el arranque del procesamiento.
Además, para manejar la serialización y deserialización (serdes) de las claves y valores, es posible configurar serdes específicos si los datos no son simples cadenas. Por ejemplo, si los mensajes son objetos JSON, se pueden utilizar serdes para JSON o definir serdes personalizados.
Otro aspecto clave es el manejo de producers y consumers en Kafka Streams. Aunque la API de Kafka Streams abstrae gran parte de la complejidad, es esencial entender que bajo el capó se están produciendo y consumiendo mensajes a los tópicos especificados. Por ello, si se requiere un control más fino, es posible interactuar directamente con los tópicos utilizando los métodos proporcionados por la API.
Para crear un producer personalizado, se puede utilizar el objeto **KafkaTemplate** de Spring Kafka. Sin embargo, al trabajar con Kafka Streams, es más común definir el flujo dentro de la topología. A continuación, un ejemplo de cómo emitir mensajes puntuales desde un producer externo:
@Service
public class MessageProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public MessageProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage(String message) {
kafkaTemplate.send("input-topic", message);
}
}
Este servicio permite enviar mensajes al tópico **input-topic**, que luego serán procesados por el KStream definido previamente.
En cuanto al consumer, al estar utilizando Kafka Streams, no es necesario implementar un consumer tradicional. El procesamiento se define en la topología del stream, y cualquier lógica de consumo y transformación se realiza allí. Sin embargo, si se desea consumir los mensajes resultantes del tópico de salida, se puede definir otro KStream o utilizar un consumer tradicional.
Por ejemplo, para consumir y procesar los mensajes del tópico **output-topic**, se podría extender la topología actual:
@Bean
public KStream<String, String> processedStream(StreamsBuilder streamsBuilder) {
KStream<String, String> stream = streamsBuilder.stream("output-topic");
stream.foreach((key, value) -> {
// Lógica personalizada para cada mensaje
System.out.println("Clave: " + key + ", Valor: " + value);
});
return stream;
}
Con este bean, se está consumiendo del tópico **output-topic** y aplicando una operación por cada par clave-valor recibido, en este caso, simplemente imprimiéndolos en la consola.
Es esencial comprender que en Kafka Streams, las aplicaciones suelen ser pipelines de procesamiento, donde los streams pueden encadenarse y aplicarse múltiples transformaciones. La topología resultante define cómo fluye y se transforma la información a través de los distintos tópicos.
Para manejar casos más complejos, como procesar mensajes de diferentes tipos o aplicar condiciones específicas, se pueden utilizar operaciones como **filter**, **branch** y combinar múltiples streams. Por ejemplo, para filtrar mensajes que cumplen cierta condición:
KStream<String, String> filteredStream = stream.filter((key, value) -> value.contains("importante"));
filteredStream.to("filtered-topic");
Este fragmento filtra los mensajes cuyo valor contiene la palabra "importante" y luego los envía al tópico **filtered-topic**.
Además, Kafka Streams permite definir procesadores personalizados a través de la API Processor API, lo que ofrece un mayor control sobre el procesamiento. Aunque es una funcionalidad avanzada, puede ser útil en situaciones donde las operaciones predefinidas no son suficientes.
Es crucial destacar la importancia de manejar adecuadamente los serdes y la configuración de la aplicación para asegurar que los datos se serialicen y deserialicen correctamente, evitando errores de ejecución.
Concepto y uso de KStreams y KTables
En Kafka Streams, los KStreams y las KTables son los componentes fundamentales para el procesamiento de datos en flujo. Comprender su concepto y cómo utilizarlos es esencial para desarrollar aplicaciones escalables y eficientes.
- Un KStream es una abstracción que representa un flujo continuo e inmutable de registros clave-valor. Cada registro en un KStream es un evento independiente que se procesa secuencialmente. Los KStreams son ideales para modelar flujos de datos donde cada evento es significativo por sí mismo, como transacciones financieras o registros de actividad.
- Por otro lado, una KTable es una vista materializada y actualizable de los datos, representando el estado más reciente para cada clave. Las KTables manejan los datos como un conjunto donde cada nueva entrada actualiza o elimina el valor anterior asociado a una clave específica. Son útiles en escenarios que requieren mantener un estado acumulado o consultar el valor más reciente de una entidad, como perfiles de usuario o inventarios.
La principal diferencia entre KStream y KTable reside en cómo tratan las actualizaciones de datos. Mientras que el KStream interpreta cada registro como un evento independiente, la KTable mantiene y refleja el estado actual de los datos, permitiendo operaciones de agregación y consultas de estado.
Para utilizar KStreams y KTables en una aplicación Spring Boot 4, se debe configurar adecuadamente el StreamsBuilder e incorporar las transformaciones necesarias. A continuación, se muestra un ejemplo de cómo definir un KStream para procesar datos de un tópico de entrada:
@Configuration
public class StreamsConfiguration {
@Bean
public KStream<String, String> kStream(StreamsBuilder streamsBuilder) {
KStream<String, String> stream = streamsBuilder.stream("topico-entrada", Consumed.with(Serdes.String(), Serdes.String()));
stream.mapValues(valor -> procesarEvento(valor))
.to("topico-salida", Produced.with(Serdes.String(), Serdes.String()));
return stream;
}
private String procesarEvento(String evento) {
// Lógica de procesamiento
return evento.toUpperCase();
}
}
En este ejemplo, se crea un KStream que consume mensajes del tópico-entrada, aplica una transformación al valor de cada mensaje y envía el resultado al tópico-salida. La función **procesarEvento** representa la lógica de negocio aplicada a cada registro.
Para trabajar con una KTable, se utiliza el método **table** del StreamsBuilder. A continuación se presenta un ejemplo de cómo definir una KTable y realizar una agregación:
@Bean
public KTable<String, Long> kTable(StreamsBuilder streamsBuilder) {
KTable<String, String> table = streamsBuilder.table("topico-tabla", Consumed.with(Serdes.String(), Serdes.String()));
KTable<String, Long> agregados = table.groupBy((clave, valor) -> KeyValue.pair(valor, 1L), Grouped.with(Serdes.String(), Serdes.Long()))
.count(Materialized.as("conteo-valores"));
agregados.toStream().to("topico-agregado", Produced.with(Serdes.String(), Serdes.Long()));
return agregados;
}
En este caso, se crea una KTable a partir del tópico-tabla, se agrupan los registros por valor y se cuenta la cantidad de ocurrencias por cada uno. El resultado se envía al tópico-agregado. La utilización de **Materialized.as** permite almacenar el resultado de la agregación en un almacén de estado local, facilitando consultas posteriores.
Es importante considerar el uso de serdes (serializadores y deserializadores) adecuados para las claves y valores, especialmente cuando se trabaja con tipos de datos personalizados. En Spring Boot 4, se pueden configurar los serdes de la siguiente manera:
spring.kafka.streams.default-key-serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.kafka.streams.default-value-serde=org.apache.kafka.common.serialization.Serdes$StringSerde
Al combinar KStreams y KTables, es posible realizar operaciones más complejas como joins. Por ejemplo, para enriquecer un flujo de eventos con información adicional almacenada en una KTable:
@Bean
public KStream<String, EventoEnriquecido> kStreamEnriquecido(StreamsBuilder streamsBuilder) {
KStream<String, Evento> eventosStream = streamsBuilder.stream("topico-eventos", Consumed.with(Serdes.String(), eventoSerde));
KTable<String, Usuario> usuariosTable = streamsBuilder.table("topico-usuarios", Consumed.with(Serdes.String(), usuarioSerde));
KStream<String, EventoEnriquecido> eventosEnriquecidos = eventosStream.join(
usuariosTable,
(evento, usuario) -> new EventoEnriquecido(evento, usuario),
Joined.with(Serdes.String(), eventoSerde, usuarioSerde)
);
eventosEnriquecidos.to("topico-eventos-enriquecidos", Produced.with(Serdes.String(), eventoEnriquecidoSerde));
return eventosEnriquecidos;
}
En este ejemplo, se realiza un join entre un KStream de eventos y una KTable de usuarios para crear un flujo de eventos enriquecidos con información del usuario. La operación **join** asocia cada evento con el estado actual de la KTable correspondiente a la clave.
Es fundamental manejar correctamente los serdes para los tipos **Evento**, **Usuario** y **EventoEnriquecido**, asegurando una serialización y deserialización coherente de los objetos. Además, considerar el manejo de ventanas de tiempo es crucial cuando se trabaja con datos que requieren agregaciones o uniones basadas en intervalos temporales.
Las ventanas de tiempo permiten segmentar los datos en intervalos definidos, facilitando operaciones como conteos o promedios en periodos específicos. Por ejemplo, para contar el número de eventos por minuto:
KTable<Windowed<String>, Long> eventosPorMinuto = eventosStream
.groupByKey(Grouped.with(Serdes.String(), eventoSerde))
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(1)))
.count(Materialized.as("eventos-por-minuto"));
eventosPorMinuto.toStream().to("topico-eventos-por-minuto", Produced.with(windowedSerde, Serdes.Long()));
Esta configuración crea una KTable que mantiene el conteo de eventos en ventanas de un minuto, sin periodo de gracia. El uso de **Windowed<String>** como clave permite identificar cada ventana temporal de forma única.
Otro aspecto a considerar es el estado local que mantiene Kafka Streams. Las aplicaciones que utilizan operaciones de estado, como agregaciones o joins, almacenan datos en el State Store, una estructura que permite recuperar y actualizar el estado de manera eficiente. En Spring Boot 4, se puede acceder al estado local para realizar consultas interactivas, proporcionando funcionalidad adicional a las aplicaciones.
Para exponer el estado local y permitir consultas interactivas, se puede utilizar el Interactive Query Service de Kafka Streams. Esto permite a los servicios recuperar información directamente del estado local sin necesidad de acceder a los tópicos de Kafka.
Es recomendable monitorizar y manejar adecuadamente los tópicos de changelog y repartition generados por Kafka Streams, ya que son fundamentales para la replicación y recuperación del estado en caso de fallos. La configuración de las propiedades de retención y compactación de estos tópicos puede optimizar el rendimiento y la eficiencia del sistema.
Transformaciones de datos, uniones y joins, agregaciones y ventanas
En Kafka Streams, las transformaciones de datos son esenciales para procesar y manipular flujos de información en tiempo real. Estas transformaciones permiten aplicar operaciones como map, filter, flatMap, entre otras, sobre los datos que transitan por los KStreams y KTables, adaptándolos a las necesidades específicas de la aplicación.
Una de las transformaciones más comunes es el mapeo de valores. Utilizando el método mapValues, es posible modificar el valor de cada registro en el stream:
KStream<String, String> streamModificado = streamOriginal.mapValues(valor -> valor.toLowerCase());
En este ejemplo, todos los valores del streamOriginal se convierten a minúsculas, generando un nuevo streamModificado.
Para filtrar registros basados en una condición, se utiliza el método filter:
KStream<String, String> streamFiltrado = streamOriginal.filter((clave, valor) -> valor.contains("importante"));
Aquí, streamFiltrado contendrá únicamente aquellos registros cuyo valor incluya la palabra importante.
Las transformaciones también pueden implicar cambios en la estructura del stream. Con flatMap, un registro de entrada puede producir múltiples registros de salida:
KStream<String, String> streamExpandido = streamOriginal.flatMap((clave, valor) -> {
List<KeyValue<String, String>> resultados = new ArrayList<>();
for (String palabra : valor.split(" ")) {
resultados.add(new KeyValue<>(clave, palabra));
}
return resultados;
});
En este caso, cada valor es dividido en palabras, y se emite un nuevo registro por cada palabra, manteniendo la misma clave.
Las uniones y joins permiten combinar flujos y tablas para enriquecer los datos. Existen diferentes tipos de joins en Kafka Streams: inner join, left join y outer join.
El inner join combina registros de dos streams o de un stream y una tabla cuando las claves coinciden:
KStream<String, String> streamUnido = streamA.join(
streamB,
(valorA, valorB) -> valorA + "-" + valorB,
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(5)),
StreamJoined.with(Serdes.String(), Serdes.String(), Serdes.String())
);
Este código realiza un join entre streamA y streamB, donde los valores se concatenan si las claves coinciden en un intervalo de 5 minutos.
El left join incluye todos los registros del stream izquierdo, añadiendo los del derecho cuando hay coincidencia:
KStream<String, String> leftJoinedStream = streamA.leftJoin(
streamB,
(valorA, valorB) -> {
if (valorB != null) {
return valorA + "-" + valorB;
}
return valorA + "-sinValorDerecho";
},
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(5)),
StreamJoined.with(Serdes.String(), Serdes.String(), Serdes.String())
);
Con el left join, se garantiza que todos los registros de streamA estén presentes en el resultado, incluso si no hay coincidencia en streamB.
Las agregaciones permiten resumir y consolidar datos. Usando métodos como groupByKey y count, es posible contar el número de ocurrencias por clave:
KTable<String, Long> conteoPorClave = streamOriginal
.groupByKey(Grouped.with(Serdes.String(), Serdes.String()))
.count(Materialized.as("conteo-por-clave"));
El resultado es una KTable que mantiene el conteo actualizado de registros por cada clave.
Para realizar agregaciones basadas en ventanas de tiempo, se utilizan las ventanas. Las ventanas pueden ser de diferentes tipos: ventanas de tiempo fijo (tumbling windows), ventanas deslizantes (hopping windows) o ventanas de sesión.
Un ejemplo de agregación con ventanas de tiempo fijo:
KTable<Windowed<String>, Long> conteoPorVentana = streamOriginal
.groupByKey(Grouped.with(Serdes.String(), Serdes.String()))
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(1)))
.count(Materialized.as("conteo-por-ventana"));
Aquí, conteoPorVentana mantiene el conteo de registros por clave en intervalos de un minuto.
Las ventanas deslizantes permiten superponer ventanas temporales:
KTable<Windowed<String>, Double> promedioDeslizante = streamOriginal
.groupByKey(Grouped.with(Serdes.String(), Serdes.Double()))
.windowedBy(TimeWindows.ofSizeAndGrace(Duration.ofMinutes(5), Duration.ofSeconds(30)))
.aggregate(
() -> 0.0,
(clave, nuevoValor, acumulado) -> (acumulado + nuevoValor) / 2,
Materialized.with(Serdes.String(), Serdes.Double())
);
Este ejemplo calcula un promedio deslizante de los valores numéricos por clave en ventanas de 5 minutos.
Las ventanas de sesión se utilizan para agrupar eventos que ocurren en periodos de actividad separados por inactividad:
KTable<Windowed<String>, Long> conteoSesion = streamOriginal
.groupByKey(Grouped.with(Serdes.String(), Serdes.String()))
.windowedBy(SessionWindows.with(Duration.ofMinutes(5)))
.count(Materialized.as("conteo-sesion"));
Este código cuenta los eventos por clave en sesiones delimitadas por 5 minutos de inactividad.
Para facilitar el manejo de timestamps y asignar marcas de tiempo personalizadas, es posible implementar una TimestampExtractor:
public class CustomTimestampExtractor implements TimestampExtractor {
@Override
public long extract(ConsumerRecord<Object, Object> registro, long timestampAnterior) {
// Extraer timestamp personalizado del registro
return obtenerTimestampDelRegistro(registro);
}
}
Al configurar el stream, se puede especificar el extractor personalizado:
KStream<String, String> streamConTimestamp = streamsBuilder.stream(
"topico-entrada",
Consumed.with(Serdes.String(), Serdes.String())
.withTimestampExtractor(new CustomTimestampExtractor())
);
Esto asegura que las operaciones de ventana utilicen los timestamps correctos.
Es esencial manejar adecuadamente las grace periods en las ventanas para considerar eventos retrasados:
TimeWindows ventanasConGrace = TimeWindows
.ofSizeWithNoGrace(Duration.ofMinutes(1))
.grace(Duration.ofSeconds(10));
Con un grace period de 10 segundos, se aceptan eventos tardíos dentro de ese intervalo.
Al combinar transformaciones, uniones, agregaciones y ventanas, se pueden crear flujos de procesamiento complejos y eficientes. Por ejemplo, para detectar tendencias en tiempo real:
KStream<String, Long> tendencias = streamOriginal
.filter((clave, valor) -> valor.contains("eventoInteresante"))
.groupBy((clave, valor) -> extraerCategoria(valor), Grouped.with(Serdes.String(), Serdes.String()))
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(5)))
.count()
.toStream()
.map((windowedClave, conteo) -> new KeyValue<>(windowedClave.key(), conteo));
En este flujo, se filtran eventos de interés, se agrupan por categoría, se cuentan en ventanas de 5 minutos y se preparan para su análisis o visualización.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Añadir la dependencia de Kafka Streams. Conocer la diferencia entre Spring Kafka y Spring for Kafka Streams. Implementar procesadores que consumen y producen información. Envío y recepción de datos desde Apache Kafka a Spring.