¿Qué es la programación reactiva en Spring?
La programación reactiva en Spring es un enfoque de desarrollo que permite construir aplicaciones eficientes y escalables mediante la gestión asíncrona y no bloqueante de datos y eventos. A diferencia del modelo tradicional, donde las operaciones pueden bloquear hilos mientras esperan respuestas, la programación reactiva maneja flujos de datos de forma asíncrona, optimizando el uso de recursos y mejorando el rendimiento.
En este paradigma, las aplicaciones se diseñan para reaccionar a los eventos a medida que suceden. Esto se logra mediante flujos de datos que emiten elementos a lo largo del tiempo, y suscriptores que responden a estos elementos. Spring adopta este enfoque a través de su módulo Spring WebFlux, que proporciona soporte nativo para construir aplicaciones web reactivas.
Una de las claves de la programación reactiva en Spring es el uso de Reactive Streams, un estándar que define interacciones no bloqueantes y asíncronas entre componentes que procesan flujos de datos. Este estándar garantiza:
- Backpressure: Control de flujo que permite al suscriptor gestionar la velocidad a la que recibe datos, evitando sobrecargas.
- Composición: Capacidad para combinar y transformar flujos de datos fácilmente.
- Asincronía: Manejo de operaciones sin bloquear hilos, liberando recursos para otras tareas.
Spring implementa estos conceptos mediante las clases Mono y Flux, que representan flujos de 0..1 y 0..N elementos respectivamente. Por ejemplo, un Mono puede emitir un único String o ninguno, mientras que un Flux puede emitir múltiples Integer a lo largo del tiempo.
Un ejemplo sencillo de un Flux podría ser:
Flux<String> colores = Flux.just("Rojo", "Verde", "Azul");
colores.subscribe(System.out::println);
Este código crea un flujo que emite tres cadenas y las imprime en la consola. La llamada a subscribe inicia la secuencia y establece cómo se manejará cada elemento emitido.
La programación reactiva en Spring es especialmente útil en aplicaciones que requieren alta concurrencia y escalabilidad, como servicios web que manejan numerosas solicitudes simultáneamente. Al eliminar bloqueos innecesarios y aprovechar mejor los recursos del sistema, es posible mejorar significativamente el rendimiento de la aplicación.
Además, Spring ofrece herramientas como WebClient, un cliente reactivo para hacer peticiones HTTP de forma no bloqueante, y soporte para controladores reactivos basados en anotaciones o funciones. Esto facilita la creación de servicios web que se benefician plenamente del modelo reactivo.
La adopción de la programación reactiva requiere un cambio de mentalidad respecto al desarrollo imperativo tradicional. Es importante comprender conceptos como la inmutabilidad, el manejo asíncrono de errores y la composición de flujos. Sin embargo, una vez dominados, ofrecen un poderoso modelo para construir aplicaciones modernas y eficientes.
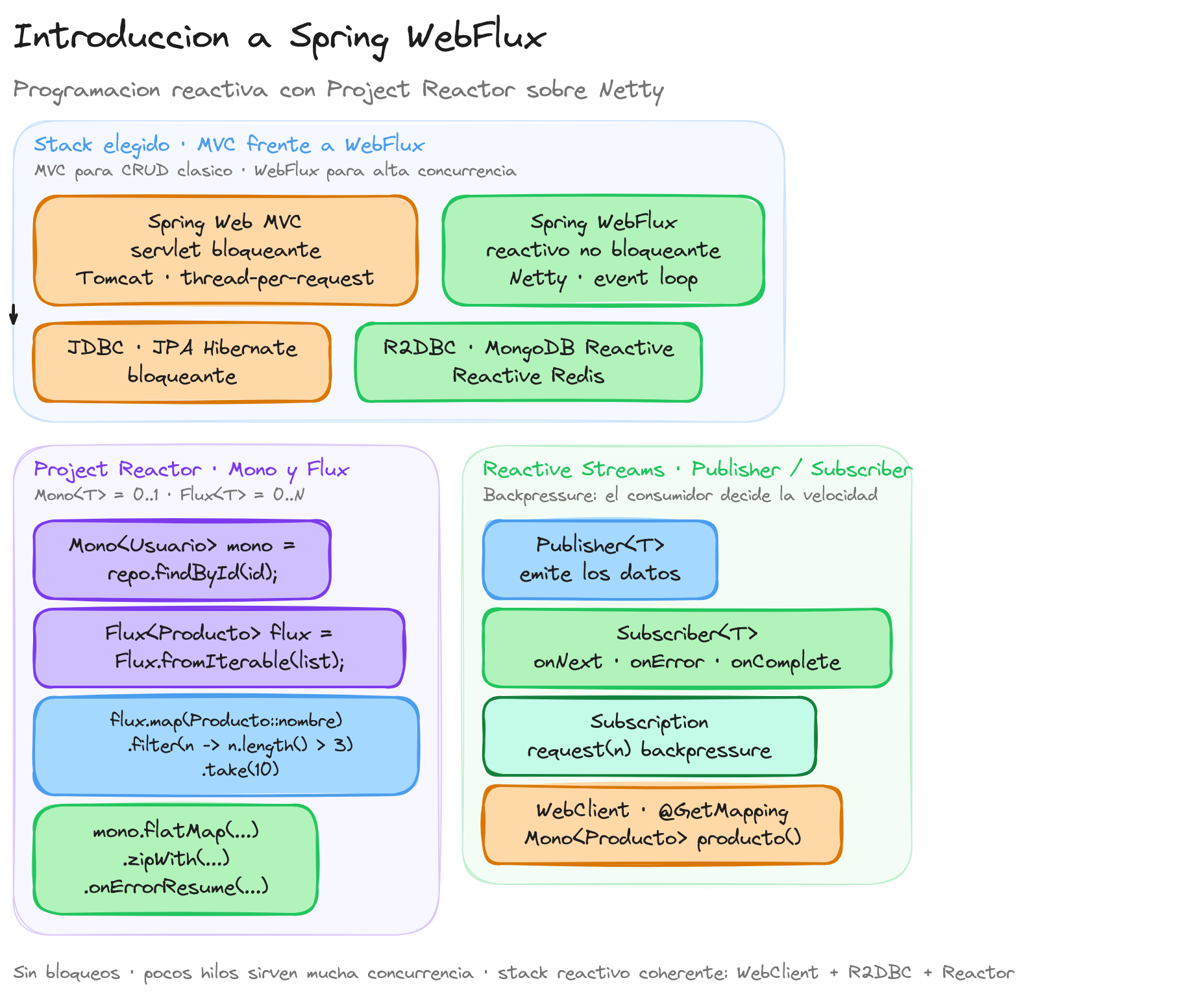
Diferencia entre Spring Web y Spring WebFlux
Spring Framework proporciona dos enfoques distintos para desarrollar aplicaciones web: Spring Web y Spring WebFlux. Aunque ambos permiten construir aplicaciones robustas en Java, difieren en su arquitectura y en cómo manejan las solicitudes y respuestas.
Spring Web, también conocido como Spring MVC, se basa en un modelo de programación imperativo y utiliza un enfoque síncrono y bloqueante. Cada solicitud entrante es atendida por un hilo del servidor, que permanece ocupado hasta que se completa el procesamiento de la solicitud. Esto implica que, para manejar múltiples solicitudes concurrentes, el servidor necesita una cantidad proporcional de hilos, lo que puede limitar la escalabilidad en sistemas con alta carga.
En contraste, Spring WebFlux adopta un modelo de programación reactivo, empleando un enfoque asíncrono y no bloqueante. En este paradigma, las operaciones de entrada y salida (I/O) no bloquean los hilos, permitiendo que un número reducido de hilos maneje un gran volumen de solicitudes concurrentes. Esto es posible gracias a los Reactive Streams, que facilitan el procesamiento de flujos de datos de manera reactiva y eficiente.
Una diferencia fundamental radica en el modelo de concurrencia. En Spring Web, la concurrencia se gestiona a través del modelo de hilos tradicionales, mientras que en Spring WebFlux se utiliza un modelo basado en eventos y callback, eliminando la necesidad de asignar un hilo por solicitud. Esto reduce el consumo de recursos y mejora el rendimiento en aplicaciones con alta concurrencia.
En términos de servidores, Spring Web se ejecuta sobre contenedores de servlets como Apache Tomcat o Jetty, que siguen el estándar Servlet API. Por su parte, Spring WebFlux puede operar sobre contenedores de servlets adaptados para soportar I/O no bloqueante o sobre servidores totalmente no bloqueantes como Netty, ofreciendo mayor flexibilidad en la elección del entorno de ejecución.
La manera de programar controladores también presenta diferencias. Aunque ambos frameworks permiten el uso de anotaciones como @Controller y @RequestMapping, Spring WebFlux introduce la posibilidad de definir rutas de forma funcional utilizando la clase RouterFunction. Por ejemplo:
RouterFunction<ServerResponse> route = RouterFunctions.route(
GET("/hello"),
request -> ServerResponse.ok().body(BodyInserters.fromValue("Hola Mundo"))
);
En este ejemplo, se define una ruta que responde a una petición GET en /hello de manera funcional, característica propia de Spring WebFlux.
Además, el manejo de tipos de retorno en los controladores es distinto. En Spring Web, los métodos suelen devolver objetos como ModelAndView o entidades directamente. En cambio, en Spring WebFlux, los métodos retornan tipos reactivos como Mono<T> o Flux<T>, permitiendo representar flujos asíncronos de uno o múltiples elementos.
El uso de tipos reactivos conlleva un cambio en cómo se gestionan las operaciones de E/S y el flujo de datos. Por ejemplo, un controlador en Spring WebFlux podría ser:
@GetMapping("/numeros")
public Flux<Integer> numeros() {
return Flux.range(1, 10);
}
Este método devuelve un Flux que emite una secuencia de números del 1 al 10, aprovechando la naturaleza reactiva para manejar los datos de manera asíncrona.
Otra diferencia notable es la forma en que se maneja el backpressure. Spring WebFlux incorpora mecanismos para controlar la velocidad a la que se emiten y consumen los datos, evitando la sobrecarga del sistema. Esto es esencial en aplicaciones reactivas donde el productor de datos puede generar elementos más rápido de lo que el consumidor puede procesar.
En cuanto a las dependencias, Spring WebFlux requiere incluir librerías adicionales como Reactor Core, que proporciona las clases Mono y Flux, mientras que Spring Web funciona principalmente con las bibliotecas estándar de Spring MVC.
Finalmente, es importante tener en cuenta que la adopción de Spring WebFlux implica familiarizarse con la programación reactiva y los conceptos asociados, como la composición de flujos, el manejo asíncrono de errores y la gestión de suscripciones. Esto representa un cambio significativo respecto al modelo tradicional de Spring Web, pero ofrece beneficios en términos de rendimiento y escalabilidad en aplicaciones modernas.
Estándar Reactive Streams y Project Reactor
El estándar Reactive Streams es una especificación que define un conjunto de interfaces y reglas para procesar flujos de datos asíncronos y no bloqueantes con contrapresión (backpressure). Este estándar proporciona un marco común que garantiza interoperabilidad entre diferentes bibliotecas y frameworks, permitiendo manejar flujos de datos de manera eficiente y coordinada.
La contrapresión es fundamental en la programación reactiva, ya que permite al consumidor controlar la velocidad a la que recibe datos del productor. De esta manera, se evita la sobrecarga del sistema cuando el productor emite datos más rápido de lo que el consumidor puede procesar. El estándar Reactive Streams establece cómo deben comportarse los componentes para manejar adecuadamente esta contrapresión.
Project Reactor es una librería basada en Reactive Streams que ofrece una implementación potente y flexible para construir aplicaciones reactivas en Java. Desarrollado por el equipo de Spring, Project Reactor es el núcleo de Spring WebFlux y proporciona las clases principales para trabajar con flujos de datos reactivos: Mono y Flux.
Las interfaces clave definidas por el estándar Reactive Streams y implementadas por Project Reactor son:
- Publisher: Interfaz que representa una fuente de elementos de tipo
T. Es el encargado de emitir datos a los suscriptores. - Subscriber: Define al consumidor que recibe los elementos del publisher. Implementa métodos como
onNext,onErroryonCompletepara manejar el flujo entrante. - Subscription: Gestiona la relación entre el publisher y el subscriber, permitiendo controlar el número de elementos que se solicitan mediante el método
request(long n).
En Project Reactor, las clases Mono y Flux implementan la interfaz Publisher<T>. Mono representa un flujo asíncrono que puede emitir cero o un elemento, mientras que Flux puede emitir cero o múltiples elementos.
Un ejemplo sencillo de uso de Mono es:
Mono<String> mensaje = Mono.just("Hola Mundo");
mensaje.subscribe(System.out::println);
En este caso, se crea un Mono que emite la cadena "Hola Mundo" y se suscribe para imprimir el mensaje en la consola.
Por su parte, Flux permite trabajar con secuencias de múltiples elementos:
Flux<Integer> numeros = Flux.range(1, 5);
numeros.subscribe(n -> System.out.println("Número: " + n));
Este código genera un flujo de números del 1 al 5 y los imprime uno a uno en la consola.
La contrapresión se gestiona a través de la interfaz Subscription. Al suscribirse a un Publisher, se puede controlar la demanda de elementos:
Flux<String> datos = Flux.just("A", "B", "C", "D").log();
datos.subscribe(new Subscriber<String>() {
private Subscription subscription;
private int recibidos = 0;
@Override
public void onSubscribe(Subscription s) {
this.subscription = s;
subscription.request(2); // Solicita los primeros dos elementos
}
@Override
public void onNext(String s) {
System.out.println("Elemento: " + s);
recibidos++;
if (recibidos == 2) {
subscription.cancel(); // Cancela la suscripción después de recibir dos elementos
}
}
@Override
public void onError(Throwable t) {
System.err.println("Error: " + t);
}
@Override
public void onComplete() {
System.out.println("Flujo completado");
}
});
Este ejemplo muestra cómo un suscriptor puede solicitar un número específico de elementos y controlar la suscripción según sus necesidades, evitando procesar más datos de los que puede manejar.
Project Reactor ofrece una amplia gama de operadores para transformar y combinar flujos de datos, facilitando la manipulación de secuencias de forma declarativa. Algunos operadores comunes son:
- map: Transforma cada elemento del flujo aplicando una función.
- filter: Filtra elementos según una condición.
- flatMap: Transforma cada elemento en un flujo y los aplana en un único flujo.
Por ejemplo, utilizando operadores:
Flux<Integer> numerosPares = Flux.range(1, 10)
.filter(n -> n % 2 == 0)
.map(n -> n * n);
numerosPares.subscribe(n -> System.out.println("Cuadrado par: " + n));
Este código filtra los números pares del 1 al 10, calcula su cuadrado y los imprime, demostrando la composición funcional de operaciones.
En el contexto de Spring WebFlux, Project Reactor permite que los controladores retornen directamente tipos Mono y Flux, integrándose de manera natural con el manejo de solicitudes HTTP de forma no bloqueante.
Un ejemplo de controlador que utiliza Flux:
@RestController
@RequestMapping("/api")
public class UsuarioController {
private final UsuarioService usuarioService;
public UsuarioController(UsuarioService usuarioService) {
this.usuarioService = usuarioService;
}
@GetMapping("/usuarios")
public Flux<Usuario> obtenerUsuarios() {
return usuarioService.listarUsuarios();
}
}
En este caso, el método obtenerUsuarios retorna un Flux<Usuario>, y Spring WebFlux se encarga de gestionar la respuesta HTTP de manera reactiva, enviando cada usuario conforme está disponible.
La interoperabilidad es otra ventaja clave de seguir el estándar Reactive Streams. Al adherirse a una especificación común, es posible combinar diferentes librerías y módulos que también implementan estas interfaces, facilitando la integración y reduciendo la complejidad.
La utilización de Schedulers en Project Reactor permite controlar cómo y dónde se ejecutan las operaciones reactivas. Por defecto, las operaciones se ejecutan en el hilo en el que se suscriben, pero se pueden cambiar los contextos de ejecución:
Flux<Integer> flujoParalelo = Flux.range(1, 10)
.publishOn(Schedulers.parallel())
.map(n -> n * 2);
flujoParalelo.subscribe(n -> System.out.println("Valor procesado: " + n));
Aquí, publishOn(Schedulers.parallel()) indica que las operaciones posteriores se ejecutarán en un pool de hilos paralelo, mejorando el rendimiento en tareas intensivas.
Es importante destacar que para aprovechar al máximo las ventajas de la programación reactiva con Project Reactor, todas las partes de la aplicación deben ser no bloqueantes. Esto incluye el acceso a bases de datos, llamadas a servicios externos y cualquier operación de I/O. Tecnologías como R2DBC para bases de datos relacionales o controladores no bloqueantes para bases de datos NoSQL son esenciales en este enfoque.
Adicionalmente, Project Reactor proporciona herramientas para manejar errores de manera eficaz mediante operadores como onErrorResume, onErrorContinue y retry. Estos permiten definir estrategias de recuperación y garantizar la resiliencia de la aplicación.
En conclusión, el estándar Reactive Streams y Project Reactor forman la base de la programación reactiva en Spring Boot 4. Al comprender y aplicar estos conceptos, es posible construir aplicaciones más escalables, eficientes y capaces de manejar de forma elegante la concurrencia y el flujo asíncrono de datos.
Principales clases reactivas en Spring WebFlux: Mono, Flux, WebClient
En Spring WebFlux, las clases reactivas principales son Mono, Flux y WebClient. Estas clases forman la base para desarrollar aplicaciones reactivas y asíncronas, facilitando el manejo de flujos de datos de manera eficiente.
Mono y Flux son tipos reactivos proporcionados por Project Reactor, que implementan el estándar Reactive Streams. Estas clases permiten representar y manipular secuencias de datos de forma declarativa y funcional.
Mono
Un Mono representa una secuencia asíncrona que puede emitir cero o un único elemento de tipo T. Es útil cuando se espera una respuesta única, como el resultado de una consulta a una base de datos o el retorno de una operación remota.
Ejemplo de creación de un Mono:
Mono<String> saludo = Mono.just("Hola, mundo");
En este caso, se crea un Mono que emitirá la cadena "Hola, mundo". Para suscribirse y procesar el valor emitido, se utiliza el método subscribe:
saludo.subscribe(s -> System.out.println("Mensaje: " + s));
Es posible crear un Mono vacío utilizando Mono.empty() o a partir de una operación que podría no devolver resultado:
Mono<Usuario> usuario = buscarUsuarioPorId(id);
Si el usuario no existe, el Mono no emitirá ningún valor y completará sin datos.
Flux
Un Flux representa una secuencia asíncrona que puede emitir cero o n elementos de tipo T. Se emplea cuando se trabaja con colecciones o flujos de datos que pueden contener múltiples elementos, como listas de objetos o streams de datos en tiempo real.
Ejemplo de creación de un Flux:
Flux<String> colores = Flux.just("Rojo", "Verde", "Azul");
Este Flux emitirá las cadenas "Rojo", "Verde" y "Azul". Para procesar cada elemento, se realiza una suscripción:
colores.subscribe(color -> System.out.println("Color: " + color));
También es posible generar flujos a partir de rangos numéricos:
Flux<Integer> numeros = Flux.range(1, 5);
Este Flux emitirá los números del 1 al 5 de manera secuencial.
Operadores en Mono y Flux
Mono y Flux proporcionan una variedad de operadores para transformar, filtrar y combinar flujos de datos de forma funcional. Algunos operadores comunes incluyen:
- map: Transforma cada elemento aplicando una función.
Flux<Integer> cuadrados = numeros.map(n -> n * n);
Genera un Flux con los cuadrados de los números originales.
- filter: Filtra los elementos según una condición.
Flux<Integer> pares = numeros.filter(n -> n % 2 == 0);
Emite únicamente los números pares.
- flatMap: Transforma cada elemento en un flujo y aplana los resultados en un único flujo.
Flux<String> palabras = Flux.just("Hola", "Mundo");
Flux<String> letras = palabras.flatMap(palabra -> Flux.fromArray(palabra.split("")));
Divide cada palabra en letras y emite cada letra individualmente.
Manejo de errores
El manejo de errores es esencial en la programación reactiva. Mono y Flux ofrecen operadores para gestionar excepciones y proporcionar alternativas:
- onErrorResume: Recupera de un error proporcionando un flujo alternativo.
Mono<String> resultado = obtenerDato()
.onErrorResume(e -> Mono.just("Valor por defecto"));
Si ocurre un error en obtenerDato(), se emite "Valor por defecto".
- onErrorReturn: Emite un valor fijo en caso de error.
Flux<Integer> datos = procesarDatos()
.onErrorReturn(-1);
Si ocurre un error, se emite -1.
WebClient
WebClient es el cliente HTTP reactivo de Spring WebFlux, que reemplaza al tradicional RestTemplate en contextos no bloqueantes. Permite realizar peticiones HTTP asíncronas de manera declarativa y fluida, integrándose con los tipos Mono y Flux.
Para crear una instancia de WebClient, se utiliza el método estático create:
WebClient cliente = WebClient.create("https://api.ejemplo.com");
Con WebClient, es posible realizar peticiones GET, POST, PUT, DELETE, entre otras. Ejemplo de una petición GET:
Mono<Respuesta> respuesta = cliente.get()
.uri("/datos/{id}", id)
.retrieve()
.bodyToMono(Respuesta.class);
Este código realiza una petición GET a /datos/{id} y convierte la respuesta en un Mono<Respuesta>.
Para procesar la respuesta:
respuesta.subscribe(r -> System.out.println("Dato recibido: " + r));
En caso de que la respuesta sea una lista de elementos, se puede utilizar bodyToFlux:
Flux<Item> items = cliente.get()
.uri("/items")
.retrieve()
.bodyToFlux(Item.class);
WebClient también permite configurar cabeceras, parámetros y autenticación:
Mono<Void> resultado = cliente.post()
.uri("/enviar")
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.bodyValue(datos)
.retrieve()
.bodyToMono(Void.class);
En este ejemplo, se realiza una petición POST enviando datos en formato JSON.
Integración con Mono y Flux
La integración entre WebClient, Mono y Flux es natural, ya que todas las operaciones son asíncronas y no bloqueantes. Esto permite construir cadenas de procesamiento sincrónicas y manipulables.
Por ejemplo, combinar varias peticiones:
Mono<Usuario> usuario = cliente.get()
.uri("/usuarios/{id}", id)
.retrieve()
.bodyToMono(Usuario.class);
Mono<Perfil> perfil = cliente.get()
.uri("/perfiles/{id}", id)
.retrieve()
.bodyToMono(Perfil.class);
Mono<DetalleUsuario> detalle = Mono.zip(usuario, perfil)
.map(tupla -> new DetalleUsuario(tupla.getT1(), tupla.getT2()));
Aquí, se realizan dos peticiones en paralelo y se combinan sus resultados para crear un objeto DetalleUsuario.
Manejo de contrapresión con WebClient
Al trabajar con flujos de datos grandes, es importante controlar la contrapresión o backpressure. WebClient gestiona automáticamente la demanda de datos, pero es posible ajustar el comportamiento si es necesario.
Ejemplo de control de demanda:
cliente.get()
.uri("/stream")
.retrieve()
.bodyToFlux(Evento.class)
.limitRate(5)
.subscribe(evento -> procesarEvento(evento));
Con limitRate(5), se solicita al servidor que envíe hasta cinco elementos a la vez, permitiendo al consumidor procesarlos sin sobrecarga.
Configuración avanzada de WebClient
WebClient es altamente configurable, permitiendo ajustar aspectos como el tiempo de espera, el manejo de errores y el uso de conexiones seguras.
Configuración de tiempos de espera:
HttpClient httpClient = HttpClient.create()
.responseTimeout(Duration.ofSeconds(5));
WebClient cliente = WebClient.builder()
.baseUrl("https://api.ejemplo.com")
.clientConnector(new ReactorClientHttpConnector(httpClient))
.build();
En este caso, se establece un tiempo máximo de respuesta de 5 segundos.
Manejo de errores personalizado:
Mono<Resultado> resultado = cliente.get()
.uri("/recurso")
.retrieve()
.onStatus(HttpStatus::is4xxClientError, respuesta -> Mono.error(new ClienteException()))
.onStatus(HttpStatus::is5xxServerError, respuesta -> Mono.error(new ServidorException()))
.bodyToMono(Resultado.class);
Se configuran manejadores para diferentes códigos de estado HTTP, permitiendo lanzar excepciones específicas según el tipo de error.
Uso de Scheduler y paralelismo
En situaciones que requieren procesamiento intensivo, es posible ajustar el Scheduler para ejecutar operaciones en hilos específicos:
Flux<ItemProcesado> itemsProcesados = items
.parallel()
.runOn(Schedulers.boundedElastic())
.map(item -> procesarItem(item))
.sequential();
Este código procesa los items en paralelo utilizando un scheduler de tipo boundedElastic, adecuado para tareas bloqueantes o de larga duración.
Diferencias con RxJava
RxJava y Project Reactor son librerías que proporcionan herramientas para la programación reactiva en Java, implementando el estándar Reactive Streams. Aunque comparten objetivos similares, existen diferencias clave en sus arquitecturas, APIs y enfoques que afectan cómo se integran con Spring WebFlux.
Una de las diferencias principales radica en los tipos principales que ofrecen. RxJava utiliza tipos como Observable, Single, Maybe, Completable y Flowable, mientras que Project Reactor se centra en Mono y Flux. En Project Reactor, Mono representa un flujo que emite cero o un elemento, y Flux representa un flujo que puede emitir cero o muchos elementos. Esta simplificación facilita la comprensión y uso de los tipos reactivos en Spring WebFlux.
En contraste, RxJava ofrece una variedad más amplia de tipos para cubrir diferentes escenarios:
- Observable: Puede emitir cero o múltiples elementos, pero carece de contrapresión.
- Flowable: Similar a
Observable, pero con soporte para contrapresión. - Single: Emite exactamente un elemento o un error.
- Maybe: Puede emitir cero o un elemento o un error.
- Completable: No emite ningún elemento, solo notifica la finalización o un error.
La contrapresión es un aspecto crítico en aplicaciones reactivas para evitar la sobrecarga del consumidor. Project Reactor integra la contrapresión de forma nativa en sus tipos Mono y Flux, siguiendo estrictamente el estándar Reactive Streams. En RxJava, sin embargo, solo Flowable soporta contrapresión, mientras que Observable no la maneja, lo que puede generar complicaciones al trabajar con flujos intensivos.
Otra diferencia significativa es el modelo de programación y la API de operadores. Aunque ambos proyectos comparten operadores comunes como map, flatMap y filter, existen diferencias en la nomenclatura y el comportamiento de algunos operadores. Por ejemplo, en RxJava se utiliza subscribeOn y observeOn para controlar los hilos de ejecución, mientras que en Project Reactor se emplea subscribeOn y publishOn. Esta diferencia en los métodos puede generar confusiones al migrar código entre ambas librerías.
En cuanto al manejo de errores, ambos proyectos ofrecen mecanismos para gestionar excepciones y errores en el flujo de datos. Sin embargo, Project Reactor proporciona operadores adicionales y estrategias más refinadas para el control de errores, alineándose con las necesidades de Spring WebFlux. Operadores como onErrorResume, onErrorContinue y retryWhen permiten una gestión más flexible y robusta de situaciones excepcionales.
La integración con Spring WebFlux es otro punto donde se evidencian diferencias. Spring WebFlux está construido sobre Project Reactor, lo que garantiza una integración nativa y optimizada. Los tipos Mono y Flux están soportados de forma predeterminada en los controladores, repositorios y otros componentes de Spring. Esto simplifica el desarrollo y reduce la necesidad de adaptadores o convertidores adicionales.
Por el contrario, para utilizar RxJava con Spring WebFlux, es necesario integrar sus tipos con los de Project Reactor. Esto implica convertir entre los tipos de RxJava y Reactor, lo que añade complejidad al código y puede afectar al rendimiento. Aunque existen métodos de conversión como Flux.from o Mono.from, esta integración no es tan fluida como trabajar directamente con los tipos nativos de Reactor.
En términos de compatibilidad y soporte, Project Reactor es mantenido por el equipo de Spring, lo que garantiza una alineación completa con las actualizaciones y características de Spring Boot 4. Esto implica que las optimizaciones y mejoras en Reactor se reflejan directamente en Spring WebFlux, ofreciendo una experiencia más cohesionada. Por su parte, RxJava es un proyecto independiente, y aunque es ampliamente utilizado, no mantiene el mismo nivel de sinergia con el ecosistema de Spring.
En el aspecto de la concatenación de flujos y composición funcional, ambos proyectos ofrecen capacidades similares, pero Project Reactor proporciona una integración más estrecha con las características modernas de Java. Con el soporte de Java Streams y la adopción de expresiones lambda, Reactor facilita la construcción de pipelines de procesamiento más legibles y concisos, aprovechando las mejoras del lenguaje.
Un ejemplo de código ilustrando la simplicidad con Project Reactor:
Flux<String> nombres = Flux.just("Ana", "Pedro", "Luis", "Marta")
.filter(nombre -> nombre.startsWith("A"))
.map(String::toUpperCase);
nombres.subscribe(System.out::println);
Esta secuencia filtra los nombres que comienzan con "A" y los convierte a mayúsculas, demostrando una fluidez en la construcción del flujo de datos.
En RxJava, un flujo equivalente podría ser:
Observable<String> nombres = Observable.just("Ana", "Pedro", "Luis", "Marta")
.filter(nombre -> nombre.startsWith("A"))
.map(String::toUpperCase);
nombres.subscribe(System.out::println);
Aunque el código es similar, la necesidad de elegir entre Observable y Flowable según los requisitos de contrapresión añade complejidad al desarrollo con RxJava.
La gestión de hilos y schedulers es otro punto de comparación. En Project Reactor, los operadores subscribeOn y publishOn permiten controlar fácilmente el contexto de ejecución. Además, Reactor proporciona schedulers predefinidos como Schedulers.parallel(), Schedulers.boundedElastic() y Schedulers.single(), optimizados para diferentes tipos de tareas. RxJava también ofrece control de hilos mediante subscribeOn y observeOn, pero las diferencias en la semántica pueden confundir a los desarrolladores acostumbrados a Reactor.
En cuanto a la comunidad y ecosistema, Project Reactor, al estar respaldado por Spring, cuenta con una amplia documentación y recursos específicos para su uso con Spring WebFlux. Esto facilita el aprendizaje y resolución de problemas, apoyándose en una comunidad activa y en constante crecimiento. RxJava cuenta también con una comunidad sólida, pero su uso en conjunto con Spring WebFlux no está tan ampliamente documentado, lo que puede representar un desafío adicional.
Otro aspecto a considerar es la madurez y el ciclo de vida de los proyectos. RxJava 2 introdujo soporte para Reactive Streams, pero con la llegada de RxJava 3, se han realizado cambios significativos que pueden afectar la compatibilidad y mantenimiento del código. Project Reactor, por su parte, mantiene una evolución más estable y centrada en las necesidades de Spring Boot 4, lo que ofrece mayor confianza a largo plazo.
Aunque tanto RxJava como Project Reactor son herramientas poderosas para la programación reactiva en Java, existen diferencias notables que influyen en su uso con Spring WebFlux.
- Project Reactor ofrece una integración más directa, un conjunto de tipos simplificado y un alineamiento completo con el ecosistema de Spring, lo que lo convierte en la opción preferida para desarrollar aplicaciones reactivas con Spring Boot 4.
- Por otro lado, RxJava puede ser apropiado en contextos donde ya se utiliza ampliamente o en proyectos que no estén basados en Spring, pero requiere consideraciones adicionales al integrarlo con Spring WebFlux.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el paradigma reactivo y los componentes Mono, Flux, Reactive Streams y Project Reactor sobre el stack WebFlux de Spring Framework 7.