Por qué un pool de conexiones importa
Abrir una conexión TCP a PostgreSQL, autenticarse, negociar SSL y ejecutar la primera consulta cuesta entre 30 y 200 milisegundos. Hacer esto en cada petición HTTP destruye la latencia y satura tanto al servidor de aplicación como al de base de datos. Un pool reutiliza conexiones ya abiertas: cada petición pide una al pool, la usa unos milisegundos y la devuelve.
HikariCP es el pool por defecto en Spring Boot 4 desde hace años. Es el más rápido del ecosistema Java según los benchmarks oficiales (cinco a diez veces más throughput que c3p0 o DBCP2 en operaciones de borrowing/returning) y el código fuente es radicalmente simple comparado con sus alternativas. La regla en proyectos nuevos es: usar HikariCP, configurarlo bien, no buscar otro.
graph LR
A[Petición HTTP] --> B[Servlet Thread]
B --> C{Pool: borrow}
C -->|conexión idle disponible| D[Devuelve conexión]
C -->|pool lleno y todas en uso| E[Espera hasta connection-timeout]
E -->|timeout| F[SQLException: timeout]
E -->|libera una| D
D --> G[Usa conexión]
G --> H{Pool: return}
H --> I[Conexión vuelve a idle]
HikariCP por defecto en Spring Boot 4
Sin configuración explícita, Spring Boot 4 aplica estos valores:
maximum-pool-size: 10minimum-idle: 10 (igual al máximo, pool de tamaño fijo)connection-timeout: 30000 msidle-timeout: 600000 ms (10 minutos)max-lifetime: 1800000 ms (30 minutos)keepalive-time: 0 (desactivado)leak-detection-threshold: 0 (desactivado)auto-commit: truepool-name: HikariPool-1
Estos valores funcionan en desarrollo, pero no son adecuados para producción. El primero a revisar siempre es el tamaño del pool.
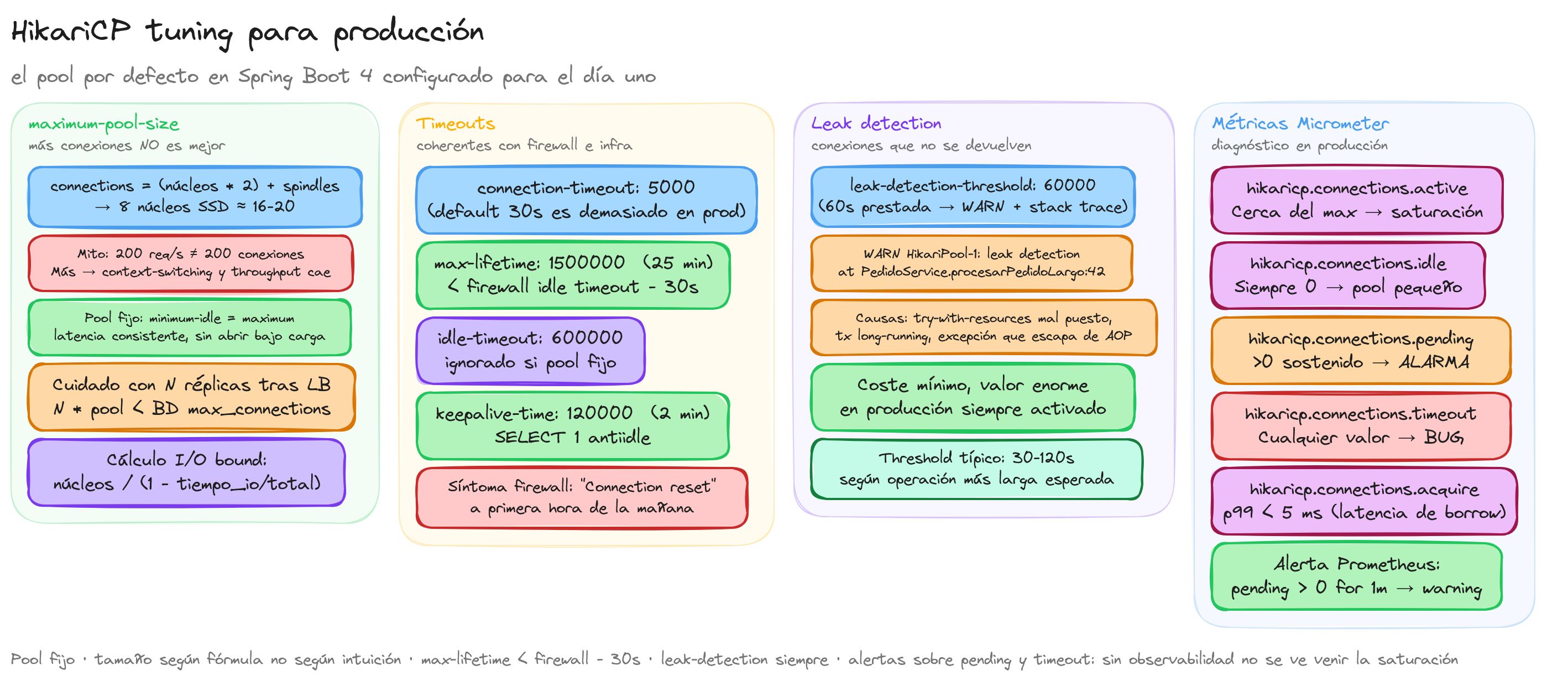
Cálculo de maximum-pool-size
El error más extendido sobre pools es asumir que más conexiones es mejor. La intuición dice "si tengo 200 peticiones por segundo, necesito 200 conexiones". Es falso. La regla empírica que usa el equipo de HikariCP, derivada de papers de Oracle y PostgreSQL, es:
connections = (núcleos_efectivos * 2) + spindles
Donde spindles es el número de discos físicos del servidor de base de datos. En un servidor moderno con 8 núcleos y SSD (1 spindle equivalente), el pool ideal está entre 16 y 20 conexiones. Más allá, el throughput baja porque la base de datos pierde tiempo en context-switching entre tantos hilos compitiendo por los mismos núcleos.
Para casos con queries lentas dominadas por I/O remoto (joins gigantes, full table scans), un cálculo alternativo es:
connections = núcleos / (1 - tiempo_io / tiempo_total)
Si el 80% del tiempo de query es I/O esperando al disco, un servidor de 8 núcleos puede saturar con 8 / (1 - 0.8) = 40 conexiones.
spring:
datasource:
hikari:
maximum-pool-size: 20
minimum-idle: 20
pool-name: PrimaryHikariPool
Si la aplicación tiene varias instancias detrás de un balanceador, el pool se multiplica por instancia. Con 4 réplicas de la app y
maximum-pool-size: 20, el servidor de BD recibe 80 conexiones potenciales. Si la BD tienemax_connections = 100, ya estás cerca del límite y un cuarto worker o un proceso de mantenimiento te dejaría sin conexiones disponibles.
Pool de tamaño fijo vs flexible
Por defecto, HikariCP recomienda pool de tamaño fijo: minimum-idle = maximum-pool-size. Mantiene siempre todas las conexiones abiertas. La ventaja es latencia consistente: nunca hay que abrir una conexión durante una petición.
La razón es que abrir una conexión bajo carga es lento (30-200 ms) y, cuando llega un pico, lo último que quieres es que el pool además esté abriendo conexiones nuevas. Mejor pagarlo todo al arranque.
spring:
datasource:
hikari:
maximum-pool-size: 20
minimum-idle: 20 # mismo valor: pool fijo
Timeouts en producción
connection-timeout
Tiempo máximo que un hilo espera por una conexión libre del pool antes de fallar con SQLException:
spring:
datasource:
hikari:
connection-timeout: 5000 # 5 segundos
El default de 30 segundos es demasiado en producción. Si el pool está saturado y un usuario espera 30 segundos por una conexión, ya ha cerrado la pestaña. Mejor fallar rápido en 5 segundos, devolver un 503 y dejar que el cliente reintente o vea un mensaje de "estamos saturados". Un timeout largo solo retrasa el síntoma de un problema mayor (pool insuficiente o queries lentas que no devuelven la conexión).
idle-timeout y minimum-idle
Si no usas pool fijo y tienes minimum-idle < maximum-pool-size, idle-timeout controla cuánto puede estar una conexión idle antes de cerrarse:
spring:
datasource:
hikari:
minimum-idle: 5
maximum-pool-size: 20
idle-timeout: 300000 # 5 minutos
En pools fijos (recomendado) este valor se ignora.
max-lifetime
Tiempo máximo que una conexión vive antes de ser reciclada, incluso si está en uso al borde:
spring:
datasource:
hikari:
max-lifetime: 1500000 # 25 minutos
Este es el timeout más crítico de toda la configuración. Debe ser menor que cualquier timeout aguas arriba: firewall, balanceador, configuración del servidor de BD. Si el firewall corporativo cierra conexiones idle a los 30 minutos sin avisar (lo hacen muchos), y max-lifetime = 1800000 (30 min) o más, HikariCP creerá que la conexión sigue válida y la pasará a la siguiente petición, que fallará con un misterioso "Connection reset" o "broken pipe".
La regla práctica: max-lifetime al menos 30 segundos por debajo del firewall timeout de tu infra. En AWS RDS por defecto el timeout es 1 hora; en infra cloud nativa con NAT Gateway el típico es 350 segundos. Pregunta a tu equipo de infra antes de fijar el valor.
keepalive-time
Envía un ping a cada conexión idle cada N milisegundos para mantenerla viva:
spring:
datasource:
hikari:
keepalive-time: 120000 # 2 minutos
Útil cuando la app tiene picos de inactividad seguidos de bursts y no quieres reabrir conexiones. El ping es un SELECT 1 (configurable con connection-test-query).
keepalive-time debe ser menor que max-lifetime y mayor que cualquier ventana de inactividad esperada. Un valor entre 30 segundos y 5 minutos es habitual.
Leak detection: conexiones que no se devuelven
Una conexión que no se devuelve al pool es un leak. Causas típicas: un try-with-resources mal puesto, un repositorio de Spring Data que no cierra el EntityManager por error, una transacción long-running que no termina, una excepción que escapa del proxy AOP.
spring:
datasource:
hikari:
leak-detection-threshold: 60000 # 60 segundos
Cuando una conexión está prestada más de 60 segundos sin volver al pool, HikariCP loguea un WARN con el stack trace del thread que la pidió:
WARN HikariPool-1 - Connection leak detection triggered for ConnectionImpl@...
java.lang.Exception
at PedidoService.procesarPedidoLargo(PedidoService.java:42)
at ...
Esto te dice exactamente qué línea de código no devolvió la conexión. Sin esta opción activa, los leaks se manifiestan como saturación del pool en producción y tienes que adivinar dónde está la fuga.
El threshold tiene un coste pequeño (HikariCP rastrea cada conexión prestada) pero el beneficio es enorme. En producción siempre activado, típicamente entre 30 y 120 segundos según la duración esperada de tus operaciones más largas.
Métricas Micrometer
Spring Boot expone métricas de HikariCP automáticamente cuando hay micrometer-registry-prometheus u otro registry. Las métricas críticas son:
| Métrica | Descripción | Qué buscar |
|---------|-------------|------------|
| hikaricp.connections.active | Conexiones en uso | Cerca del max indica saturación |
| hikaricp.connections.idle | Conexiones libres en el pool | Si está siempre a 0, el pool es pequeño |
| hikaricp.connections.pending | Hilos esperando conexión | Cualquier valor > 0 sostenido es alarma |
| hikaricp.connections.timeout | Total de timeouts | Debe ser 0; cualquier valor es bug |
| hikaricp.connections.acquire | Latencia de borrow (timer) | p99 < 5ms; valores altos indican espera |
| hikaricp.connections.usage | Tiempo en que la conexión está prestada | Permite detectar queries lentas |
| hikaricp.connections.creation | Latencia de abrir conexión nueva | Si pool fijo está bien dimensionado, se llama solo al arranque |
management:
metrics:
enable:
hikaricp: true
endpoints:
web:
exposure:
include: health,metrics,prometheus
Una alerta de Prometheus razonable:
- alert: HikariPoolPending
expr: hikaricp_connections_pending > 0
for: 1m
labels:
severity: warning
annotations:
summary: "Pool HikariCP con threads en espera más de 1 minuto"
Diagnóstico de problemas comunes
Pool saturado bajo carga
Síntomas: connection.timeout aumenta, connections.pending crece, peticiones devuelven 500 con SQLTransientConnectionException.
Causas (en orden de probabilidad):
- Queries lentas que no devuelven la conexión rápido. Diagnóstico:
connections.usagecon percentiles altos. Solución: optimizar las queries (lección de explain plan e índices). - Pool insuficiente para el tráfico real. Solución: subir
maximum-pool-sizecautelosamente y verificar que la BD soporta el aumento. - Transacción mantenida mientras se llama a una API externa lenta dentro de
@Transactional. Solución: extraer la llamada externa fuera de la transacción. - Leak de conexiones por código que no cierra correctamente. Diagnóstico:
leak-detection-thresholdactivo encontrará el culpable.
Conexiones rotas tras inactividad
Síntomas: la app funciona durante el día y a las primeras horas de la mañana fallan las primeras peticiones con "Connection reset" o "broken pipe", luego se recupera sola.
Causa: el firewall corporativo o el NAT Gateway cierra conexiones idle por la noche, pero max-lifetime no se ajustó. Solución: bajar max-lifetime por debajo del timeout del firewall y activar keepalive-time.
Tiempo alto en abrir conexión
Síntomas: connection.creation con p99 > 200 ms, latencia errática en periodos de baja carga.
Causa: el pool no es fijo y reabre conexiones cuando el tráfico baja por idle-timeout. Solución: pool fijo (minimum-idle = maximum-pool-size).
Tuning para read replica vs primario
En arquitecturas con primario y réplica de lectura, ambos datasources tienen perfiles distintos.
Primario (escrituras + lecturas críticas):
primary:
hikari:
maximum-pool-size: 20
minimum-idle: 20
connection-timeout: 5000
max-lifetime: 1500000
leak-detection-threshold: 60000
Read replica (consultas pesadas, reporting):
replica:
hikari:
maximum-pool-size: 30
minimum-idle: 10
connection-timeout: 10000
max-lifetime: 1500000
leak-detection-threshold: 120000
La réplica suele tener pool más grande porque las queries son más largas (reporting, agregaciones). El connection-timeout puede ser más generoso porque la criticidad es menor (un reporte puede esperar 10 segundos; una petición de checkout no). El leak-detection-threshold es más permisivo por la misma razón.
Para detalles de cómo configurar dos datasources con AbstractRoutingDataSource y el flag
@Transactional(readOnly = true)para enrutar al replica, consulta la lección sobre multi-datasource en este mismo módulo.
Comparativa con otros pools
| Pool | Velocidad | Configuración | Mantenimiento | Recomendación 2026 | |------|-----------|---------------|---------------|---------------------| | HikariCP | Más rápido | Mínima, sensata | Activo | Default | | Tomcat JDBC | Bueno | Más opciones, más cuerda para colgarse | Mantenido | Solo si ya está en uso | | c3p0 | Lento | Compleja, propensa a leaks | Mantenimiento bajo | Migrar | | DBCP2 | Lento | Compleja | Apache lo mantiene pero está superado | Migrar | | Agroal | Comparable a Hikari | Sencilla, integrado en Quarkus | Activo | Si usas Quarkus, sí |
En proyectos Spring Boot la decisión está tomada desde el upstream: HikariCP es el default desde Spring Boot 2.0 y sigue siéndolo en Spring Boot 4. Las únicas razones legítimas para no usarlo son compatibilidad con un broker XA específico (algún ESB legacy) o requisitos regulatorios que exijan un pool certificado por un proveedor concreto.
Buenas prácticas
- Pool fijo en producción:
minimum-idle = maximum-pool-size. Latencia consistente, sin sorpresas en los picos. - Tamaño según fórmula, no según intuición. Empezar con
(núcleos * 2) + 1y subir solo con métricas que lo justifiquen. connection-timeout: 5000o menos en producción. Fallar rápido es mejor que clavar al servlet thread.max-lifetimemenor que el firewall timeout menos 30 segundos. Pregunta a infra el valor exacto.leak-detection-threshold: 60000activo siempre en producción. Coste mínimo, valor enorme cuando hay un bug.- Métricas Micrometer expuestas a Prometheus, alertas sobre
pending > 0ytimeout > 0. Sin observabilidad no se detecta saturación incipiente. - No reutilices la configuración entre primario y replica. Tienen perfiles distintos y mezclarlos da lo peor de los dos mundos.
- Auditar el pool al deployment: anotar el tamaño efectivo, los timeouts y el
pool-nameen el log de arranque. Cuando aparece un incidente a las 3 AM, querrás esos datos visibles sin tener que descifrar la config.
El pool de conexiones es uno de esos componentes invisibles cuando funciona y devastador cuando falla. Su configuración por defecto no es producción: la primera tarea de cualquier proyecto Spring Boot serio es revisar HikariCP, calcular el tamaño con datos reales y activar leak detection. Hacerlo después de un incidente cuesta diez veces más que hacerlo el día uno.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Calcular el maximum-pool-size correcto según núcleos del servidor y latencia de queries. Configurar timeouts coherentes con el firewall y la infraestructura. Activar leak-detection-threshold para detectar conexiones no devueltas. Interpretar las métricas Micrometer hikaricp.connections.* para diagnosticar saturación y leaks. Diferenciar configuración del primario y de las réplicas de lectura.