Las asociaciones de Entidades JPA (Java Persistence API) son una funcionalidad que permite representar relaciones entre distintas tablas en una base de datos en el nivel de las clases de Java.
Esto significa que podemos relacionar clases de Java por medio de Composición y en base de datos se generen claves foráneas apuntando a claves primarias, de modo que las tablas estén relacionadas.
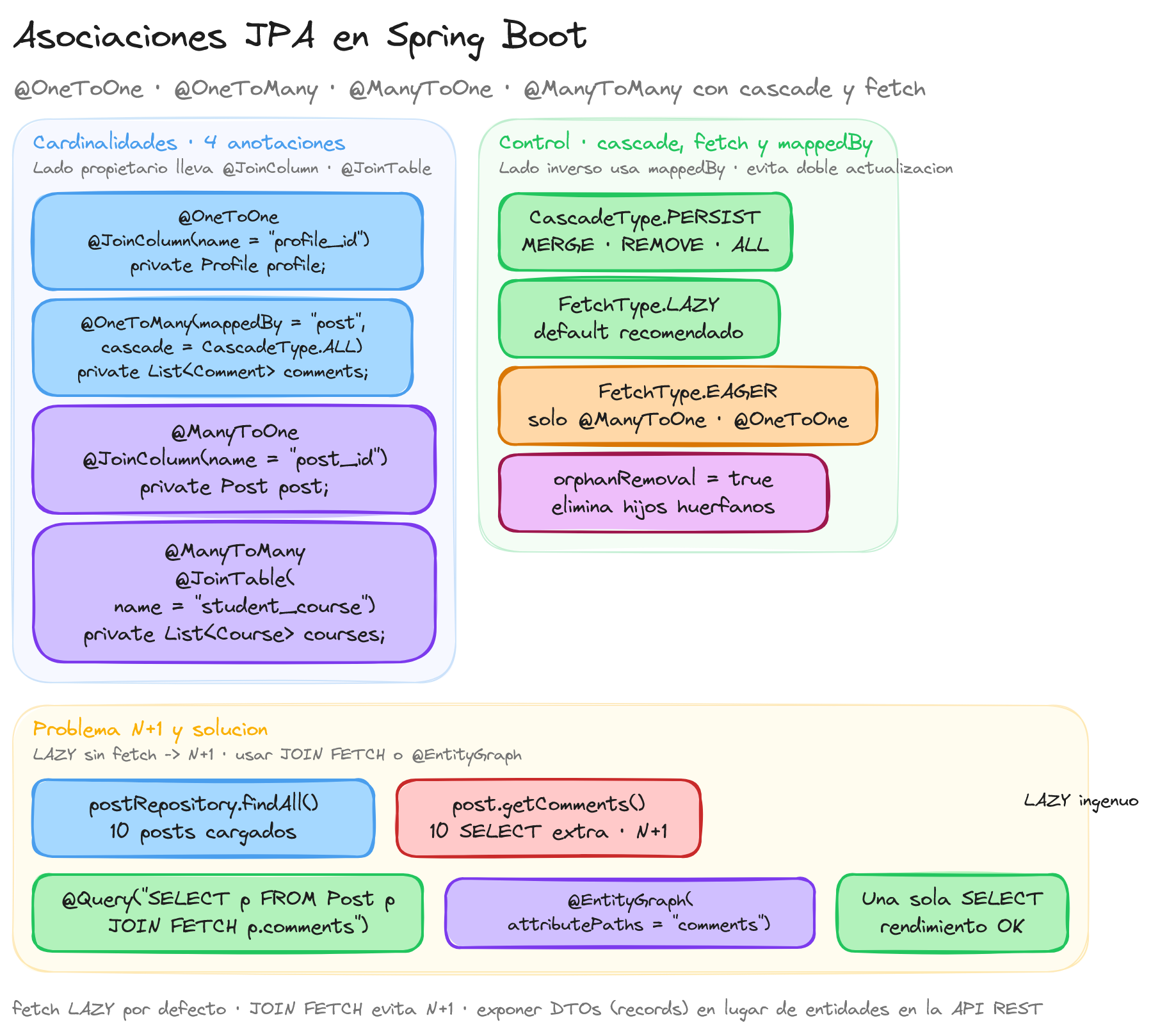
Las asociaciones de Entidades pueden ser de varios tipos, dependiendo de cómo se relacionan las entidades entre sí. Estas pueden ser:
- uno a uno (One-to-One)
- uno a muchos (One-to-Many)
- muchos a uno (Many-to-One)
- muchos a muchos (Many-to-Many)
One-to-One (Uno a Uno)
La relación One-to-One indica que una instancia de una entidad A sólo puede estar asociada con una única instancia de otra entidad B, y viceversa.
En otras palabras, hay una correspondencia uno a uno entre las entidades.
Por ejemplo, consideremos una aplicación donde cada User tiene un único Profile, y cada Profile pertenece a un único User.
En este caso, la relación entre User y Profile es One-to-One.
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@JoinColumn(name = "profile_id", unique = true)
private Profile profile;
}
@Entity
public class Profile {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@OneToOne(mappedBy = "profile")
private User user;
}
La anotación @JoinColumn se utiliza para especificar la columna que será usada para unir la tabla actual con la tabla referenciada. En este caso, se utiliza en la clase Comment para establecer una relación con Post:
Por otro lado, mappedBy se utiliza en el lado "no propietario" (en inglés "non-owning side") de la relación para especificar el campo dentro de la entidad propietaria (en inglés "owning side") que controla la relación:
Aquí, mappedBy = "profile" indica que la propiedad profile en la clase User es el lado "propietario" de la relación. Esto significa que cualquier cambio realizado en el campo profile de un objeto User se reflejará en la base de datos. Pero no al revés.
One-to-Many / Many-to-One (Uno a Muchos / Muchos a Uno)
La relación One-to-Many indica que una instancia de una entidad A puede estar asociada con múltiples instancias de otra entidad B, pero cada instancia de B está asociada con un único A.
Desde la perspectiva de B a A, esta relación es Many-to-One.
Por ejemplo, supongamos que en una aplicación de blog, un Post puede tener múltiples Comment, pero cada Comment pertenece a un único Post. Aquí, la relación entre Post y Comment es One-to-Many.
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL)
private List<Comment> comments;
}
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@ManyToOne
@JoinColumn(name = "post_id")
private Post post;
}
En una relación bidireccional, como @OneToMany y @ManyToOne, se debe designar un lado como el "propietario" de la relación.
El lado propietario es el que controla la actualización de la relación entre las dos entidades. En este caso, Comment es la entidad propietaria porque contiene el campo @JoinColumn. Esto significa que si quieres crear, actualizar o eliminar una relación entre un Post y un Comment, deberás hacerlo desde el lado de Comment.
Por ejemplo, si tienes un Post y quieres añadirle un nuevo Comment, normalmente lo harías de la siguiente manera:
Post post = new Post();
Comment comment1 = new Comment();
Comment comment2 = new Comment();
comment1.setPost(post);
comment2.setPost(post);
post.setComments(Arrays.asList(comment1, comment2));
Al guardar comment1 y comment2, la relación se reflejará en la base de datos porque Comment es el lado propietario de la relación.
Many-to-Many (Muchos a Muchos)
La relación Many-to-Many indica que múltiples instancias de una entidad A pueden estar asociadas con múltiples instancias de otra entidad B.
Por ejemplo, en un sistema de gestión de universidades, un Student puede estar inscrito en múltiples Course, y un Course puede tener múltiples Student inscritos. En este caso, la relación entre Student y Course es Many-to-Many.
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@ManyToMany
@JoinTable(name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id"))
private List<Course> courses;
}
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@ManyToMany(mappedBy = "courses")
private List<Student> students;
}
En cada uno de estos casos, se utilizan anotaciones específicas de JPA para definir la relación y las propiedades correspondientes de las entidades involucradas. En las relaciones Many-to-Many, se utiliza la anotación @JoinTable para definir la tabla de enlace que maneja la asociación entre las entidades.
En este caso, como la clase Student es quien tiene la anotación @JoinTable dentro, será el lado propietario (owner) por lo que para guardar la relación en base de datos será necesario añadir courses al listado de courses de un Student y persistirlo en base de datos.
Cascada y Fetch
Las operaciones de cascada y las estrategias de carga (fetch) son dos aspectos fundamentales de las relaciones entre entidades en JPA.
Cascada
Las operaciones en cascada son aquellas operaciones que se propagan de una entidad a las entidades relacionadas. Por ejemplo, si se guarda una entidad, y esta tiene una relación en cascada con otras entidades, entonces todas estas entidades se guardarán también.
Las operaciones de cascada disponibles en JPA son:
CascadeType.PERSIST: Cascada la operaciónpersist(guardar). Si guardas la entidad fuente, las entidades relacionadas también se guardarán.CascadeType.REMOVE: Cascada la operaciónremove(eliminar). Si eliminas la entidad fuente, las entidades relacionadas también se eliminarán.CascadeType.REFRESH: Cascada la operaciónrefresh(refrescar). Si refrescas la entidad fuente, las entidades relacionadas también se refrescarán.CascadeType.MERGE: Cascada la operaciónmerge(fusionar). Si fusionas la entidad fuente, las entidades relacionadas también se fusionarán.CascadeType.DETACH: Cascada la operacióndetach(desconectar). Si desconectas la entidad fuente, las entidades relacionadas también se desconectarán.CascadeType.ALL: Cascada todas las operaciones anteriores. Si cualquier operación se realiza en la entidad fuente, la misma operación se propagará a las entidades relacionadas.
Aquí hay un ejemplo de cómo se utiliza:
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL)
private List<Comment> comments;
}
En este ejemplo, si un Post se elimina, todos los Comment asociados también se eliminarán de la base de datos. Esto es porque la operación remove se propaga desde Post a Comment debido a la configuración CascadeType.ALL.
Fetch
Fetch se refiere a cuándo se deben cargar los datos de las entidades relacionadas desde la base de datos. JPA ofrece dos estrategias de carga: EAGER y LAZY.
FetchType.EAGER: Este tipo de carga significa que las entidades relacionadas se cargan al mismo tiempo que la entidad fuente. Por ejemplo, si se carga unPostdesde la base de datos, todos losCommentasociados también se cargan al mismo tiempo.FetchType.LAZY: Este tipo de carga significa que las entidades relacionadas se cargan a demanda, es decir, cuando se accede a ellas por primera vez. Por ejemplo, si se carga unPost, losCommentasociados no se cargarán hasta que se acceda a ellos mediantepost.getComments().
Aquí hay un ejemplo de cómo se utiliza:
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@OneToMany(mappedBy = "post", fetch = FetchType.LAZY)
private List<Comment> comments;
}
En este ejemplo, los Comment asociados a un Post no se cargarán de la base de datos hasta que se invoque post.getComments().
La elección de las estrategias de cascada y carga depende de las necesidades específicas de la aplicación y de las consideraciones de rendimiento.
Conclusión
En conclusión, las asociaciones de entidades JPA en Spring Boot proporcionan una forma poderosa y flexible de mapear las relaciones entre las entidades de la base de datos en un modelo de objetos de dominio. Estas asociaciones pueden representar diversas relaciones como One-to-One, One-to-Many, Many-to-One y Many-to-Many.
Las anotaciones como @OneToOne, @OneToMany, @ManyToOne, @ManyToMany, @JoinColumn, @JoinTable, entre otras, facilitan la configuración de estas relaciones. Además, JPA ofrece operaciones en cascada que permiten propagar ciertas operaciones desde una entidad a sus entidades relacionadas, lo que facilita el manejo de las operaciones de base de datos.
Además, JPA proporciona estrategias de carga EAGER y LAZY para optimizar el rendimiento de la base de datos. La estrategia EAGER carga las entidades relacionadas inmediatamente, mientras que la estrategia LAZY las carga a demanda, lo que puede ayudar a mejorar la eficiencia de la aplicación.
Caso B2B: modelado de dominio en banca, retail y AAPP
En entidades bancarias, el modelado de cliente y sus productos asociados (cuentas, tarjetas, préstamos) usa típicamente una @OneToMany desde Cliente a una colección de Producto (entidad base con herencia JOINED). Vuestro equipo gana porque la jerarquía de productos queda explícita y consultable con polimorfismo, y el modelo refleja la realidad del negocio. La organización gana porque los nuevos productos (criptoactivos, planes de pensiones) se añaden creando una nueva subclase sin tocar consultas existentes.
En retail con catálogos de producto, la relación @ManyToMany entre Producto y Categoria modela la pertenencia de un producto a varias categorías (un televisor está en "Electrónica" y en "Hogar"). La tabla intermedia con @JoinTable queda autogestionada por JPA. Vuestro equipo evita SQL manual para mantener el catálogo coherente.
En administraciones públicas con sistemas de tramitación, los expedientes (Expediente) tienen @OneToMany con documentos (Documento) y @ManyToOne con el procedimiento administrativo (Procedimiento). La relación con cascade PERSIST evita olvidar guardar los hijos. Las eliminaciones se controlan con orphanRemoval = true para que al desvincular un documento del expediente se elimine de la base.
En telco con plataformas OSS, los servicios contratados (Servicio) tienen relación con productos (Producto) y con incidencias (Incidencia) abiertas. El fetch LAZY por defecto evita cargar todas las incidencias históricas cuando solo se consulta el servicio.
Versiones (2025)
Spring Boot 4.0 (estable desde abril 2026) usa Spring Data JPA 4 sobre Hibernate 7+ y Jakarta Persistence 3.2 (paquete jakarta.persistence.*). Java 21 es el mínimo; Java 25 LTS es la versión recomendada en 2026. Spring Boot 3.4 (noviembre 2024) y 3.5 (mayo 2025) siguen en soporte con la rama 3.x.
Hibernate 6.x mejoró el soporte a @SqlResultSetMapping y añadió @Filter para soft-deletes condicionales. Spring Data JPA 4 (esperado finales 2025) introducirá soporte mejorado a virtual threads.
Anti-patrones y pitfalls
fetch = EAGER por defecto. JPA por defecto carga @ManyToOne y @OneToOne como EAGER, lo que provoca consultas adicionales no deseadas. Configurad fetch = LAZY siempre y usad JOIN FETCH o entity graphs cuando necesitéis cargar la asociación.
Problema N+1 sin diagnóstico. Cargar una lista de Post y luego acceder a post.getComments() para cada uno dispara N+1 consultas. Detectadlo con Hibernate Statistics o herramientas como Hypersistence Optimizer, DataSource Proxy o el plugin de IntelliJ. Solucionadlo con JOIN FETCH o @EntityGraph.
CascadeType.ALL indiscriminado. Eliminar un Post y arrastrar todos los Comment puede ser correcto, pero arrastrar todos los User desde Post.author es un desastre. Especificad solo los cascades necesarios (PERSIST, MERGE).
Entidades JPA expuestas en API REST. Genera ciclos de serialización, fetches inesperados (lazy initialization exception fuera de la transacción) y acopla el contrato API al modelo de dominio. Usad DTOs (records de Java 17+) y mapead con MapStruct o explícitamente.
@OneToMany con List<> sin equals/hashCode adecuado. Provoca duplicados en consultas con JOIN. Implementad equals/hashCode usando solo el id (con cuidado en entidades nuevas sin id) o usad Set<>.
Contraints de BD no reflejadas en el modelo JPA. Si la BD tiene UNIQUE(email, organization_id), declaradlo con @UniqueConstraint en @Table para que Hibernate lo respete y para que las migraciones lo generen.
Modelar herencia sin entender las estrategias. SINGLE_TABLE (rápida pero columnas nullable masivas), JOINED (normalizada, JOIN en cada consulta), TABLE_PER_CLASS (rara vez usada). En banca con productos heterogéneos, JOINED es la opción habitual.
Olvidar @Transactional en métodos que cargan asociaciones LAZY. Fuera de la transacción, acceder a post.getComments() lanza LazyInitializationException.
Comparativa con alternativas
Frente a MyBatis, JPA es más declarativo pero menos explícito en el SQL generado. MyBatis es preferible cuando vuestro equipo necesita control total sobre cada consulta (proyectos con DBA experimentados que optimizan a mano).
Frente a jOOQ, JPA mapea objeto-relacional y ofrece JPQL/Criteria. jOOQ ofrece type-safe SQL builder. Para reportes complejos y consultas analíticas, jOOQ rinde mejor; para CRUD de dominio, JPA es más productivo.
Frente a Spring JDBC o JdbcTemplate, JPA aporta cacheado L1, dirty checking automático y gestión de transacciones declarativa. Para microservicios CRUD, JPA es la opción canónica.
Frente a R2DBC (reactivo), JPA es bloqueante. Si vuestra aplicación es reactiva (Spring WebFlux), considerad R2DBC con Spring Data R2DBC.
Documentación oficial
Las referencias son docs.spring.io/spring-data/jpa/reference para Spring Boot 3.4+, docs.jboss.org/hibernate/orm/6.6/userguide para Hibernate 6.6, y jakarta.ee/specifications/persistence/3.2 para la especificación Jakarta Persistence. El libro "Hibernate in Action" (Manning) y "High-Performance Java Persistence" (Vlad Mihalcea) son referencias canónicas para optimización de rendimiento JPA en producción.
Las asociaciones JPA son la base del modelado de dominio en proyectos Spring Boot. Para vuestro equipo en proyectos B2B con dominios complejos (banca, telco, AAPP), dominar @OneToMany, @ManyToOne, @ManyToMany, junto con fetch LAZY y JOIN FETCH, evita los problemas de rendimiento más comunes y permite construir aplicaciones mantenibles a varios años vista.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Modelar relaciones JPA OneToOne, OneToMany, ManyToOne y ManyToMany con cascade, fetch LAZY y mappedBy en Spring Boot 4 evitando N+1.