Por qué cachear
Los endpoints más frecuentes de cualquier aplicación suelen leer datos que cambian poco: el catálogo de departamentos, el listado de roles, la configuración del usuario, una traducción i18n, un perfil público. Sin cache, cada petición pega a la base de datos. Con cache, la primera carga la respuesta y las siguientes la sirven en microsegundos.
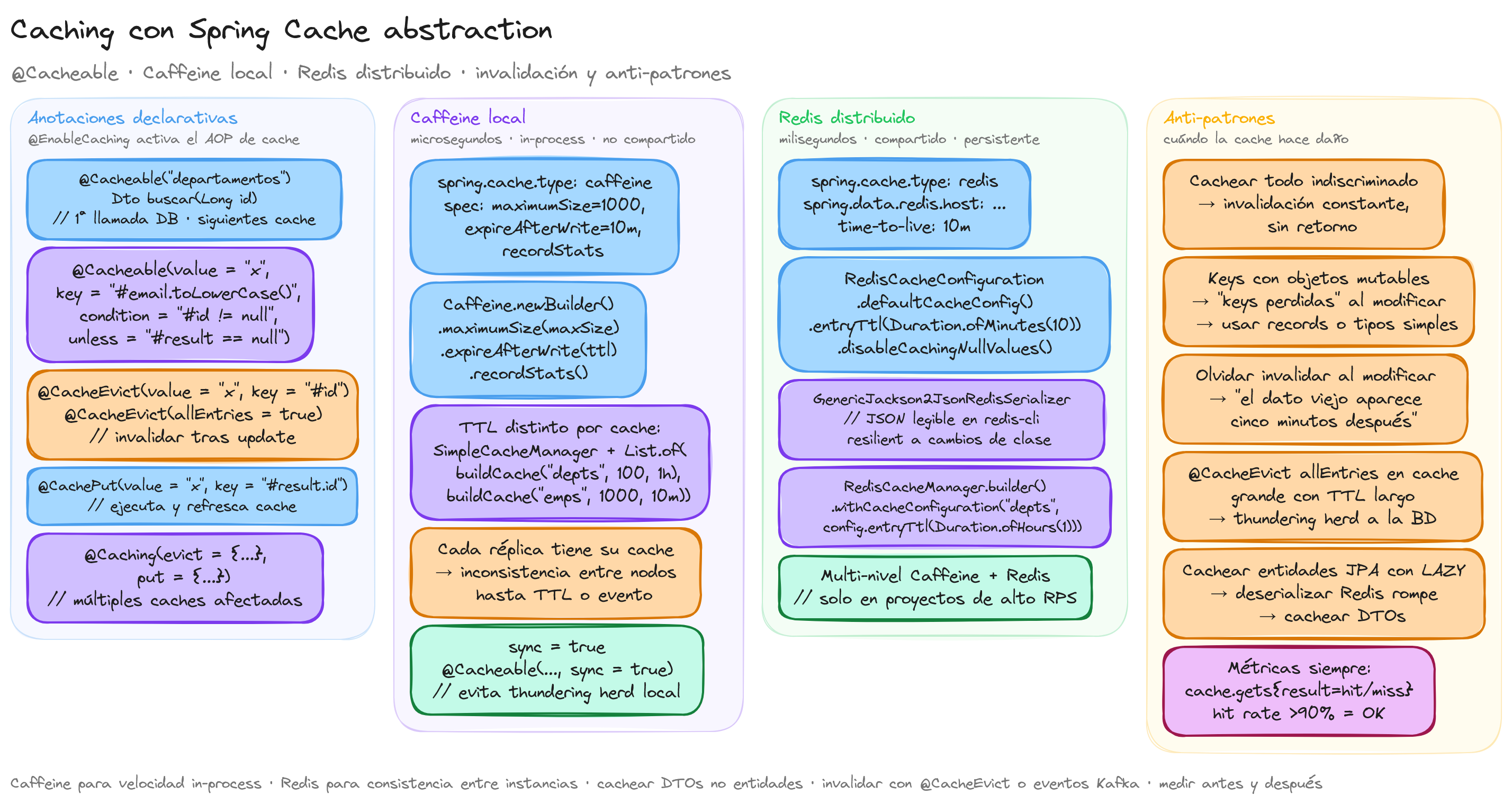
Spring Cache abstrae el caching detrás de anotaciones (@Cacheable, @CacheEvict, @CachePut). El código de negocio no sabe si la cache es local en memoria, distribuida en Redis o multi-nivel. La elección se hace en configuración.
Activación
@SpringBootApplication
@EnableCaching
public class EmpleadosApplication { ... }
@Cacheable: cachear el resultado
@Service
@RequiredArgsConstructor
public class DepartamentoService {
private final DepartamentoRepository repository;
@Cacheable("departamentos")
public DepartamentoDto buscarPorId(Long id) {
log.info("BD hit: buscando departamento {}", id);
return repository.findById(id)
.map(this::toDto)
.orElseThrow();
}
}
La primera llamada con un id ejecuta el método y guarda el resultado en la cache "departamentos". Las siguientes llamadas con el mismo id devuelven el valor cacheado sin entrar al método. El log "BD hit" solo aparece la primera vez.
La key por defecto es el conjunto de parámetros (en este caso id). Si hay varios parámetros, se compone una key compuesta.
Key personalizada con SpEL
@Cacheable(value = "empleados", key = "#email.toLowerCase()")
public EmpleadoDto buscarPorEmail(String email) { ... }
@Cacheable(value = "empleados", key = "#empleadoId + ':' + #fecha")
public NominaDto buscarNomina(Long empleadoId, LocalDate fecha) { ... }
SpEL accede a los parámetros (#email, #empleadoId) y permite componer la key. Útil para normalizar (lowercase) o componer keys jerárquicas.
Cache condicional
condition evalúa antes de ejecutar el método: si es false, no se cachea.
unless evalúa después: si es true, no se cachea (útil para no cachear null o resultados vacíos):
@Cacheable(value = "empleados", key = "#id",
condition = "#id != null",
unless = "#result == null")
public EmpleadoDto buscarPorId(Long id) { ... }
@CacheEvict: invalidar entradas
Cuando el dato cambia, hay que invalidar la cache:
@CacheEvict(value = "departamentos", key = "#id")
public void actualizar(Long id, DepartamentoDto dto) {
var entity = repository.findById(id).orElseThrow();
entity.setNombre(dto.nombre());
repository.save(entity);
}
@CacheEvict(value = "departamentos", allEntries = true)
public void invalidarTodos() { ... }
allEntries = true borra todas las entradas de esa cache. Útil cuando un cambio masivo invalida todo (importación masiva, cambio de configuración global).
@CachePut: actualizar la cache
@CachePut(value = "departamentos", key = "#result.id")
public DepartamentoDto crear(DepartamentoCrearDto dto) {
var entity = repository.save(toEntity(dto));
return toDto(entity);
}
@CachePut siempre ejecuta el método y luego guarda el resultado en la cache. Útil cuando se crea o actualiza una entidad y se quiere que la cache refleje el estado más reciente.
@Caching: combinar varias anotaciones
@Caching(
evict = {
@CacheEvict(value = "empleados", key = "#id"),
@CacheEvict(value = "departamentos", key = "#result.departamentoId")
},
put = {
@CachePut(value = "empleados", key = "#id")
}
)
public EmpleadoDto actualizar(Long id, EmpleadoActualizarDto dto) { ... }
Útil cuando un método afecta a varias caches (actualizar empleado invalida cache de empleado y de departamento).
Caffeine: cache local en memoria
Caffeine es la implementación recomendada para cache local. Alta velocidad, baja huella de memoria, soporte nativo para TTL y eviction policies.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
spring:
cache:
type: caffeine
caffeine:
spec: maximumSize=1000,expireAfterWrite=10m,recordStats
Para configuración por cache (TTL distinto por nombre):
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
var manager = new SimpleCacheManager();
manager.setCaches(List.of(
buildCache("departamentos", 100, Duration.ofHours(1)),
buildCache("empleados", 1000, Duration.ofMinutes(10)),
buildCache("traducciones", 500, Duration.ofDays(1))
));
return manager;
}
private CaffeineCache buildCache(String name, int maxSize, Duration ttl) {
var cache = Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(ttl)
.recordStats()
.build();
return new CaffeineCache(name, cache);
}
}
recordStats() permite acceder a métricas (hit rate, miss rate, eviction count) vía Micrometer.
Limitación: no se comparte entre instancias
Cache local significa que cada réplica de la aplicación tiene su propia cache. Si la instancia A invalida una entrada, la instancia B sigue teniendo el valor obsoleto hasta que su TTL expire o reciba un evento.
Esto es aceptable cuando:
- El TTL es corto (minutos) y la inconsistencia de segundos a minutos no daña.
- El dato es de solo lectura o cambia muy poco (catálogos, configuración).
- La aplicación corre con pocas instancias.
Para inconsistencia inaceptable o muchas instancias, Redis es la opción.
Redis: cache distribuido
Redis es un store en memoria compartido entre instancias. Una sola fuente de verdad para la cache, accesible desde cualquier réplica.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
spring:
cache:
type: redis
redis:
time-to-live: 10m
cache-null-values: false
key-prefix: "empleados:"
use-key-prefix: true
data:
redis:
host: ${REDIS_HOST:localhost}
port: ${REDIS_PORT:6379}
password: ${REDIS_PASSWORD:}
Para TTL distinto por cache:
@Configuration
@EnableCaching
public class RedisCacheConfig {
@Bean
public CacheManager cacheManager(RedisConnectionFactory connectionFactory) {
var defaultConfig = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(10))
.disableCachingNullValues()
.serializeValuesWith(RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer()));
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(defaultConfig)
.withCacheConfiguration("departamentos",
defaultConfig.entryTtl(Duration.ofHours(1)))
.withCacheConfiguration("empleados",
defaultConfig.entryTtl(Duration.ofMinutes(5)))
.withCacheConfiguration("traducciones",
defaultConfig.entryTtl(Duration.ofDays(1)))
.build();
}
}
Serialización JSON
Por defecto, Spring Cache + Redis usa Java serialization, que es frágil entre versiones de clase. Lo idiomático es Jackson JSON:
.serializeValuesWith(RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer()))
Esto serializa el objeto a JSON usando el ObjectMapper configurado. Las entradas de cache son legibles con redis-cli (útil para debugging) y resilientes a cambios en clases (con @JsonIgnoreUnknown adecuado).
Multi-nivel: Caffeine + Redis
En aplicaciones de alto rendimiento, lo idiomático es dos niveles: cache local Caffeine (microsegundos) sobre cache distribuido Redis (milisegundos). El flujo:
- Petición llega → busca en Caffeine local. Si está, devuelve.
- Si no, busca en Redis. Si está, guarda en Caffeine y devuelve.
- Si no, ejecuta el método, guarda en Redis y Caffeine.
Spring Cache no lo soporta nativamente. Hay que usar Spring Boot Cache2k o construir un CacheManager custom que delegue en dos. La complejidad solo se justifica en aplicaciones con alta presión de RPS.
Patrones de invalidación
Invalidación por evento
Para invalidar la cache cuando algo cambia desde otro servicio:
@Component
@RequiredArgsConstructor
public class CacheInvalidationListener {
private final CacheManager cacheManager;
@KafkaListener(topics = "departamentos.actualizados")
public void invalidar(DepartamentoActualizadoEvent event) {
var cache = cacheManager.getCache("departamentos");
if (cache != null) cache.evict(event.departamentoId());
}
}
Esto es esencial en arquitecturas event-driven: si el servicio A actualiza un departamento, publica un evento a Kafka. El servicio B lo escucha e invalida su cache local de departamentos. Así sus instancias dejan de servir el valor obsoleto.
Refresh proactivo
Para datos críticos que no pueden estar obsoletos, mejor refrescar antes de que expire:
@Scheduled(fixedDelay = 9 * 60 * 1000) // 9 minutos (TTL = 10)
public void refreshCacheCritica() {
departamentoRepository.findAll()
.forEach(d -> cacheManager.getCache("departamentos").put(d.getId(), toDto(d)));
}
Métricas con Micrometer
Spring Boot expone métricas de cache automáticamente si Caffeine tiene recordStats():
cache.gets{cache="departamentos",result="hit"} 4523
cache.gets{cache="departamentos",result="miss"} 87
cache.puts{cache="departamentos"} 87
cache.evictions{cache="departamentos"} 0
Hit rate alto (>90%) significa que la cache hace su trabajo. Hit rate bajo (<50%) o evictions altos indican TTL muy corto o cache muy pequeña.
Anti-patrones
Cachear todo
@Cacheable indiscriminado degrada en lugar de mejorar:
- Cachear datos que cambian a cada petición → invalidación constante, no aporta.
- Cachear datos masivos (listas grandes) → presión de memoria, evictions frecuentes.
- Cachear datos por usuario sin TTL corto → la cache crece sin límite.
Regla: cachear lo que se lee mucho y cambia poco. Empezar sin cache, medir hot paths, cachear los específicos.
Keys con objetos mutables
@Cacheable("x")
public Foo buscar(MutableKey k) { ... }
Si MutableKey tiene equals basado en estado mutable y se modifica fuera, las keys "se pierden". Usar value objects inmutables (records de Java) o tipos simples (Long, String).
Olvidar invalidar
Cualquier método que modifica un dato cacheado debe tener @CacheEvict o @CachePut correspondiente. Olvidar invalidar es la causa #1 de bugs sutiles ("aparece el dato viejo cinco minutos después de cambiarlo").
Cache aside con race conditions
Si dos peticiones simultáneas hacen miss para la misma key, ambas ejecutan el método. Para datos costosos (consulta lenta), usar sync = true:
@Cacheable(value = "departamentos", key = "#id", sync = true)
public DepartamentoDto buscarPorId(Long id) { ... }
sync = true serializa las llamadas concurrentes para la misma key. Solo una ejecuta el método, las demás esperan al resultado. Caffeine lo soporta nativamente; con Redis depende de la implementación.
Thundering herd al invalidar caches grandes
Invalidar allEntries = true en una cache grande con TTL largo puede colapsar la BD: miles de peticiones simultáneas hacen miss y disparan miles de queries. Mitigar con:
Cache.putproactivo en lugar deevict + reload.RefreshAheadCache(Caffeine soportarefreshAfterWrite).- Jitter en TTLs para que no expiren todas las entradas a la vez.
Buenas prácticas
- TTL distinto por cache, no global. Catálogo: 1h. Resultados de búsqueda: 5 min. Configuración: 1 día.
- Métricas siempre: hit rate, miss rate, evictions. Sin estos números no se sabe si la cache está aportando.
- Caffeine local para velocidad, Redis distribuido para consistencia. Multi-nivel solo en proyectos grandes.
- Invalidar con
@CacheEvicto eventos Kafka entre servicios. No confiar solo en TTL. - Cachear DTOs, no entidades JPA. Las entidades pueden tener proxies LAZY que rompen al deserializar de Redis.
- Tests de cache: levantar el contexto con
@CacheConfigy verificar que la segunda llamada no toca el repository. sync = trueen métodos costosos para evitar thundering herd local.
El caching es la herramienta de mayor retorno por mínimo esfuerzo en Spring Boot. Bien aplicado divide la latencia y el coste de BD por 10. Mal aplicado introduce inconsistencias sutiles y bugs intermitentes. La regla es medir antes y después: la cache es buena si las métricas lo demuestran, no por intuición.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Aplicar @Cacheable, @CacheEvict y @CachePut a métodos de servicio. Diferenciar cache local con Caffeine y cache distribuido con Redis. Configurar TTL y políticas de evicción por cache. Diseñar keys consistentes con SpEL. Detectar y evitar el cache aside problem y el thundering herd.