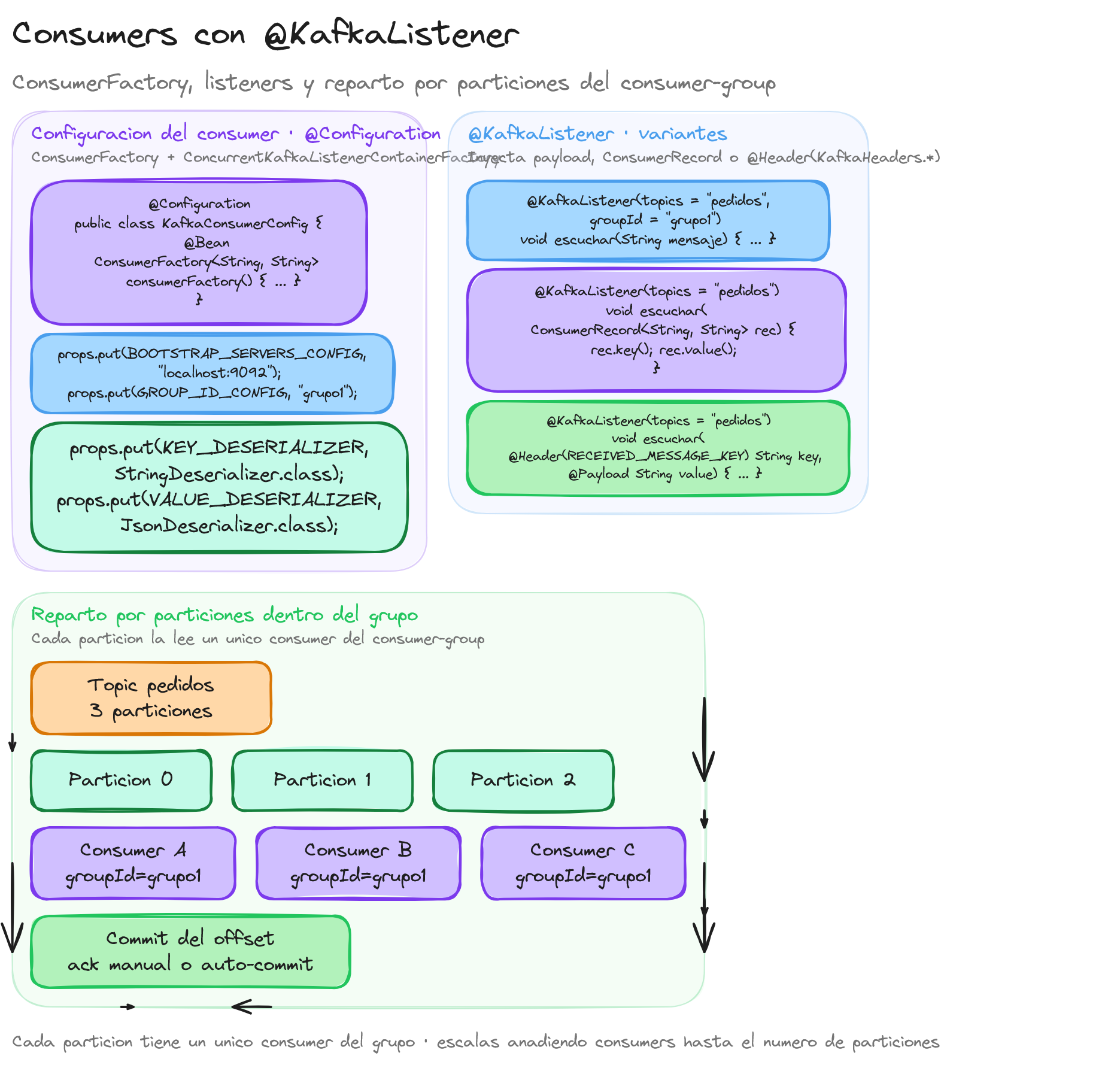
Consumidores con @KafkaListener para consumir string sin y con clave
En aplicaciones que utilizan Apache Kafka para la mensajería asíncrona, es común necesitar consumir mensajes de tipo string, tanto aquellos que no tienen clave asociada como los que sí la tienen. En Spring Boot 4, podemos utilizar la anotación @KafkaListener para simplificar la creación de consumidores. A continuación, exploraremos cómo configurar y utilizar @KafkaListener para consumir mensajes de string sin clave y con clave.
El siguiente diagrama resume visualmente los conceptos clave introducidos en esta seccion:
flowchart LR
PROD[Productor con KafkaTemplate] --> TOPIC[Topic con N particiones]
TOPIC --> P0["(Partición 0)"]
TOPIC --> P1["(Partición 1)"]
TOPIC --> P2["(Partición 2)"]
P0 --> CG[Consumer Group pedidos-service]
P1 --> CG
P2 --> CG
CG --> C1[Consumer 1 KafkaListener]
CG --> C2[Consumer 2 KafkaListener]
CG --> C3[Consumer 3 KafkaListener]
C1 --> COMMIT[Auto commit offset o manual ack]
C2 --> COMMIT
C3 --> COMMIT
Note1["Cada partición es leída<br>por un único consumer del grupo"]
Configuración del consumidor
Además de configurar consumer en application.properties, es posible definir una configuración de consumidor que especifique cómo conectarse al clúster de Kafka y cómo deserializar los mensajes. Podemos crear una clase de configuración como la siguiente:
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> propiedades = new HashMap<>();
propiedades.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
propiedades.put(ConsumerConfig.GROUP_ID_CONFIG, "grupo1");
propiedades.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propiedades.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(propiedades);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, String>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
En esta configuración, hemos definido un ConsumerFactory que utiliza StringDeserializer tanto para las claves como para los valores de los mensajes. Además, hemos creado un ConcurrentKafkaListenerContainerFactory que utilizará este ConsumerFactory.
Consumir mensajes sin clave
Para consumir mensajes que no tienen clave, podemos utilizar @KafkaListener de la siguiente manera:
@Service
public class SinClaveConsumer {
@KafkaListener(topics = "topico_sin_clave", groupId = "grupo1")
public void escucharMensajes(String mensaje) {
System.out.println("Mensaje recibido: " + mensaje);
}
}
En este ejemplo, el método escucharMensajes recibe directamente el valor del mensaje como un String. La anotación @KafkaListener está configurada para escuchar el tópico "topico_sin_clave" y pertenece al grupo de consumidores "grupo1".
Consumir mensajes con clave
Cuando los mensajes tienen una clave asociada, es útil acceder a ella para realizar operaciones adicionales como particionamiento personalizado o para mantener el orden de los mensajes. Podemos modificar nuestro @KafkaListener para recibir tanto la clave como el valor:
@Service
public class ConClaveConsumer {
@KafkaListener(topics = "topico_con_clave", groupId = "grupo1")
public void escucharMensajesConClave(ConsumerRecord<String, String> record) {
String clave = record.key();
String mensaje = record.value();
System.out.println("Clave: " + clave + ", Mensaje: " + mensaje);
}
}
En este caso, el método escucharMensajesConClave recibe un ConsumerRecord<String, String>, lo que nos permite acceder a la clave y al valor del mensaje. Esto es especialmente útil cuando necesitamos procesar la clave para fines específicos en nuestra aplicación.
Otra forma de acceder directamente a la clave es mediante el uso de la anotación @Header:
@Service
public class ConClaveConsumer {
@KafkaListener(topics = "topico_con_clave", groupId = "grupo1")
public void escucharMensajesConClave(
@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) String clave,
String mensaje) {
System.out.println("Clave: " + clave + ", Mensaje: " + mensaje);
}
}
Aquí, utilizamos @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) para inyectar la clave del mensaje en el parámetro clave. El valor del mensaje se recibe como un String en el parámetro mensaje.
Configuración adicional
Es importante configurar correctamente el deserializador de claves si las claves son de un tipo diferente a String. En nuestro ConsumerFactory, podemos especificar el deserializador adecuado:
propiedades.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
Si las claves fueran de otro tipo, como Integer, deberíamos cambiar a IntegerDeserializer.class.
Manejo de particiones y ordenación
Al consumir mensajes con clave, Kafka garantiza que los mensajes con la misma clave se envíen a la misma partición, preservando el orden. Esto es esencial cuando el orden de procesamiento es crítico para la lógica de negocio. Al utilizar @KafkaListener y acceder a la clave, podemos implementar lógica específica basada en este comportamiento.
ConcurrentKafkaListenerContainerFactory y concurrencia
Podemos configurar el grado de concurrencia de nuestros consumidores ajustando la propiedad concurrency en el ConcurrentKafkaListenerContainerFactory:
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, String>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(3);
return factory;
}
Esto permite que múltiples hilos consuman mensajes en paralelo, mejorando el rendimiento de la aplicación. Es importante equilibrar el número de hilos con el número de particiones de los tópicos para evitar situaciones de desequilibrio en el consumo.
Ejemplo completo
A continuación, presentamos un ejemplo completo que integra todo lo anterior:
@Service
public class MensajeConsumer {
@KafkaListener(topics = "topico_general", groupId = "grupo1")
public void procesarMensaje(
@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) String clave,
String mensaje) {
if (clave != null) {
System.out.println("Procesando mensaje con clave: " + clave + ", valor: " + mensaje);
} else {
System.out.println("Procesando mensaje sin clave: " + mensaje);
}
// Lógica de procesamiento adicional
}
}
Este método procesarMensaje maneja ambos casos: cuando el mensaje tiene clave y cuando no la tiene. Utilizamos una condición para determinar si la clave es null y actuamos en consecuencia.
Importancia del groupId
El parámetro groupId en @KafkaListener es fundamental para determinar el comportamiento del consumidor. Todos los consumidores que pertenecen al mismo grupo comparten la carga de mensajes de los tópicos suscritos. Si queremos que todos los consumidores reciban todos los mensajes, deben pertenecer a grupos diferentes.
Configuración de logging
Es recomendable configurar un sistema de logs para monitorear el consumo de mensajes y facilitar la resolución de problemas. Podemos utilizar el marco de trabajo SLF4J junto con Logback o Log4j2 para este propósito:
@Service
public class MensajeConsumer {
private static final Logger logger = LoggerFactory.getLogger(MensajeConsumer.class);
@KafkaListener(topics = "topico_general", groupId = "grupo1")
public void procesarMensaje(
@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) String clave,
String mensaje) {
if (clave != null) {
log.info("Procesando mensaje con clave: {}, valor: {}", clave, mensaje);
} else {
log.info("Procesando mensaje sin clave: {}", mensaje);
}
// Lógica de procesamiento adicional
}
}
Con esta configuración, podemos realizar un seguimiento más detallado del flujo de mensajes y detectar posibles incidencias en el procesamiento.
Buenas prácticas
- Validación de mensajes: Es aconsejable validar el contenido de los mensajes antes de procesarlos para evitar errores.
- Manejo de excepciones: Implementar bloques
try-catcho utilizar capacidades de manejo de errores de Kafka para gestionar excepciones. - Escalabilidad: Configurar adecuadamente la concurrencia y el número de particiones para asegurar que la aplicación pueda manejar cargas crecientes.
Con estas configuraciones y prácticas, podemos crear consumidores robustos y eficaces en Spring Boot 4 que aprovechen al máximo las capacidades de Apache Kafka para la mensajería asíncrona.
Consumidores con @KafkaListener para consumir JSON y objetos sin usar Schema Registry
Al trabajar con Apache Kafka, es común enviar y recibir mensajes en formato JSON para representar objetos complejos. Consumir estos mensajes JSON y convertirlos en instancias de clases Java es esencial para el procesamiento de datos en aplicaciones modernas.
A continuación, exploraremos cómo configurar un consumidor que utiliza @KafkaListener para consumir mensajes JSON y mapearlos a objetos Java sin la necesidad de utilizar Schema Registry.
Para empezar, es necesario definir la clase del modelo que representará la estructura del mensaje JSON. Por ejemplo, consideremos una clase Usuario:
public class Usuario {
private String nombre;
private String correoElectronico;
private int edad;
// Constructores, getters y setters
}
Es fundamental que esta clase contenga los constructores y los métodos getters y setters necesarios para que el deserializador pueda instanciar y poblar el objeto correctamente.
Configuración del deserializador JSON
Para consumir mensajes JSON, debemos configurar un deserializador que convierta el JSON en objetos Java. En lugar de utilizar el StringDeserializer, utilizaremos el JsonDeserializer proporcionado por Spring Kafka. En la configuración del consumidor, especificaremos este deserializador y le indicaremos la clase de destino.
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, Usuario> consumerFactory() {
Map<String, Object> propiedades = new HashMap<>();
propiedades.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
propiedades.put(ConsumerConfig.GROUP_ID_CONFIG, "grupoUsuarios");
propiedades.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propiedades.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
propiedades.put(JsonDeserializer.TRUSTED_PACKAGES, "com.ejemplo.modelo");
return new DefaultKafkaConsumerFactory<>(propiedades);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Usuario> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, Usuario>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
En esta configuración:
- JsonDeserializer es el deserializador utilizado para los valores de los mensajes.
- La propiedad
JsonDeserializer.TRUSTED_PACKAGESse establece para especificar los paquetes que contienen las clases a deserializar. El valor"com.ejemplo.modelo"debe reemplazarse por el paquete de la claseUsuario. - No es necesario utilizar Schema Registry, ya que el deserializador trabaja directamente con la clase especificada.
Consumir mensajes JSON con @KafkaListener
Con la configuración establecida, podemos crear un consumidor que utilice @KafkaListener para recibir los mensajes y procesarlos como objetos Usuario.
@Service
public class UsuarioConsumer {
@KafkaListener(topics = "topicoUsuarios", groupId = "grupoUsuarios", containerFactory = "kafkaListenerContainerFactory")
public void escucharUsuario(Usuario usuario) {
System.out.println("Usuario recibido: " + usuario);
// Lógica de procesamiento
}
}
En este ejemplo:
- El método
escucharUsuariorecibe directamente una instancia deUsuario, gracias al deserializador configurado. - La propiedad
containerFactoryen@KafkaListenerse establece para indicar qué fábrica de contenedores utilizar, en caso de tener múltiples configuraciones.
Manejo de la clave del mensaje
Si los mensajes incluyen una clave, podemos modificar el método para acceder a ella. Esto es útil cuando la clave tiene significado en el procesamiento de los datos.
@Service
public class UsuarioConsumer {
@KafkaListener(topics = "topicoUsuarios", groupId = "grupoUsuarios", containerFactory = "kafkaListenerContainerFactory")
public void escucharUsuario(@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) String clave, Usuario usuario) {
System.out.println("Clave: " + clave + ", Usuario recibido: " + usuario);
// Lógica de procesamiento
}
}
Al utilizar @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY), podemos inyectar la clave del mensaje en el parámetro clave. Esto nos permite tomar decisiones basadas en la clave recibida.
Configuración de confianza en paquetes
Es importante configurar la propiedad JsonDeserializer.TRUSTED_PACKAGES para evitar excepciones de seguridad. Al especificar los paquetes confiables, el deserializador puede instanciar las clases sin restricciones.
propiedades.put(JsonDeserializer.TRUSTED_PACKAGES, "com.ejemplo.modelo");
Si deseamos confiar en todos los paquetes (lo cual no es recomendado por razones de seguridad), podemos establecer:
propiedades.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
Sin embargo, es preferible limitar los paquetes confiables para mantener un nivel adecuado de seguridad en la aplicación.
Uso de tipos genéricos
En casos donde se consumen mensajes con diferentes tipos de objetos, podemos utilizar un deserializador genérico. El deserializador puede determinar el tipo de clase basado en los encabezados del mensaje o mediante una propiedad específica.
public class MiDeserializador<T> extends JsonDeserializer<T> {
public MiDeserializador() {
super();
}
}
Y en la configuración:
propiedades.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, MiDeserializador.class);
Este enfoque permite mayor flexibilidad al consumir distintos tipos de mensajes, siempre y cuando se maneje adecuadamente la deserialización.
Configuración de ObjectMapper personalizado
En ocasiones, es necesario personalizar el comportamiento de deserialización. Podemos configurar un ObjectMapper personalizado y asignarlo al deserializador.
@Bean
public ObjectMapper objectMapper() {
var mapper = new ObjectMapper();
// Configuraciones adicionales
return mapper;
}
@Bean
public ConsumerFactory<String, Usuario> consumerFactory(ObjectMapper objectMapper) {
var deserializador = new JsonDeserializer<Usuario>(Usuario.class, objectMapper, false);
Map<String, Object> propiedades = new HashMap<>();
propiedades.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
propiedades.put(ConsumerConfig.GROUP_ID_CONFIG, "grupoUsuarios");
propiedades.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propiedades.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deserializador);
propiedades.put(JsonDeserializer.TRUSTED_PACKAGES, "com.ejemplo.modelo");
return new DefaultKafkaConsumerFactory<>(propiedades, new StringDeserializer(), deserializador);
}
Con esta configuración, podemos ajustar aspectos como el manejo de fechas, formatos numéricos y otras características de deserialización que necesitemos en nuestra aplicación.
Consideraciones sobre la compatibilidad de clases
Al no utilizar Schema Registry, es crucial que tanto el productor como el consumidor compartan la misma definición de la clase Usuario. Cualquier cambio en la estructura de la clase debe ser coordinado entre ambas partes para evitar problemas de deserialización.
Manejo de excepciones durante la deserialización
Es posible que ocurran errores durante la deserialización de los mensajes. Para manejar estas situaciones, podemos implementar un ErrorHandler personalizado.
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Usuario> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, Usuario>();
factory.setConsumerFactory(consumerFactory());
factory.setErrorHandler((thrownException, data) -> {
System.err.println("Error al deserializar el mensaje: " + data);
// Lógica de manejo de errores
});
return factory;
}
Este manejador nos permite capturar excepciones y decidir cómo proceder, ya sea registrando el error, enviando el mensaje a un tópico de errores o aplicando medidas correctivas.
Uso de RecordFilterStrategy para filtrar mensajes
Si deseamos filtrar mensajes antes de que sean procesados, podemos utilizar una estrategia de filtrado en el KafkaListenerContainerFactory.
factory.setRecordFilterStrategy(record -> {
// Filtrar mensajes basados en una condición
return record.value().getEdad() < 18;
});
En este ejemplo, los mensajes donde el usuario es menor de 18 años serán filtrados y no procesados por el @KafkaListener.
Ventajas de no utilizar Schema Registry
Al no depender de Schema Registry, simplificamos la arquitectura y reducimos la complejidad de la infraestructura. Sin embargo, debemos gestionar manualmente la compatibilidad entre productores y consumidores, asegurándonos de que las clases utilizadas sean coherentes.
La capacidad de consumir mensajes JSON y mapearlos a objetos Java sin utilizar Schema Registry es una funcionalidad poderosa de Spring Boot 4. Mediante la configuración adecuada del deserializador y el uso de @KafkaListener, podemos integrar fácilmente la mensajería asíncrona en nuestras aplicaciones, manteniendo un código limpio y eficiente.
Configuración de concurrencia y particiones
En Apache Kafka, la concurrencia y el manejo de particiones juegan un papel crucial en el rendimiento y escalabilidad de las aplicaciones que consumen mensajes. En Spring Boot 4, es posible configurar la concurrencia de los consumidores para optimizar la capacidad de procesamiento y aprovechar al máximo las ventajas que ofrece Kafka en términos de distribución de carga y paralelismo.
Entendiendo las particiones en Kafka
Cada tópico de Kafka se divide en múltiples particiones, lo que permite distribuir los datos y equilibrar la carga entre varios consumidores. Las particiones son unidades básicas de paralelismo en Kafka; cada partición puede ser consumida por un solo consumidor dentro de un mismo grupo de consumidores (Consumer Group). Esto significa que si tenemos más consumidores que particiones, algunos consumidores permanecerán inactivos.
Configuración de la concurrencia en Spring Boot
Para aumentar la capacidad de procesamiento de los consumidores, podemos configurar la propiedad de concurrencia en el ConcurrentKafkaListenerContainerFactory. Esta propiedad determina el número de hilos que se crearán para consumir mensajes en paralelo.
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> propiedades = new HashMap<>();
propiedades.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
propiedades.put(ConsumerConfig.GROUP_ID_CONFIG, "grupo1");
propiedades.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propiedades.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(propiedades);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, String>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(3);
return factory;
}
}
En este ejemplo, hemos establecido la concurrencia a 3 mediante el método setConcurrency(3). Esto significa que el KafkaListener asociado utilizará tres hilos para consumir mensajes, permitiendo que hasta tres particiones se consuman en paralelo.
Relación entre concurrencia y particiones
Es importante comprender que el nivel de concurrencia debe estar equilibrado con el número de particiones del tópico. Si configuramos una concurrencia superior al número de particiones, los hilos adicionales no recibirán mensajes, ya que no hay particiones disponibles para asignarles. Por el contrario, si el número de particiones es mayor que la concurrencia, algunas particiones no serán consumidas a menos que existan otros consumidores en el mismo grupo.
Por ejemplo, si tenemos un tópico con 5 particiones y configuramos la concurrencia a 3, nuestro consumidor manejará 3 particiones, y las 2 restantes quedarán sin consumir por este consumidor específico.
Configuración del número de particiones
Para aprovechar al máximo la concurrencia configurada, es esencial que el tópico tenga un número de particiones adecuado. Al crear un tópico en Kafka, podemos especificar el número de particiones:
kafka-topics.sh --create --topic miTopico --bootstrap-server localhost:9092 --partitions 5 --replication-factor 1
En este comando, estamos creando un tópico llamado miTopico con 5 particiones. Esto permitirá que hasta 5 consumidores en el mismo grupo puedan consumir mensajes en paralelo de este tópico.
Ejemplo de uso con @KafkaListener
Al utilizar @KafkaListener, no es necesario realizar cambios adicionales para aprovechar la concurrencia configurada. El KafkaListener automáticamente utilizará la configuración del kafkaListenerContainerFactory.
@Service
public class MiConsumer {
@KafkaListener(topics = "miTopico", groupId = "grupo1")
public void escucharMensajes(String mensaje) {
System.out.println("Mensaje recibido: " + mensaje);
// Procesamiento del mensaje
}
}
Con la concurrencia establecida en 3, este consumidor procesará mensajes en tres hilos separados, permitiendo un procesamiento más rápido de los mensajes entrantes.
Verificación de la concurrencia
Es útil verificar que la configuración de concurrencia está funcionando como se espera. Podemos agregar logs o imprimir el identificador del hilo en el que se está procesando cada mensaje:
@Service
public class MiConsumer {
@KafkaListener(topics = "miTopico", groupId = "grupo1")
public void escucharMensajes(String mensaje) {
System.out.println("Mensaje recibido en el hilo " + Thread.currentThread().getName() + ": " + mensaje);
// Procesamiento del mensaje
}
}
Al ejecutar la aplicación, observaremos que los mensajes se procesan en diferentes hilos, como org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1, org.springframework.kafka.KafkaListenerEndpointContainer#0-1-C-1, etc.
Consideraciones sobre el orden de los mensajes
Al aumentar la concurrencia y consumir mensajes desde múltiples particiones en paralelo, el orden de los mensajes no está garantizado de forma global. Kafka garantiza el orden de los mensajes dentro de una partición, pero no entre diferentes particiones. Si el orden de los mensajes es crítico para la aplicación, se debe diseñar la lógica teniendo en cuenta esta característica.
Gestión de la carga de trabajo
La configuración de la concurrencia permite distribuir la carga de trabajo entre varios hilos, pero también es esencial considerar el rendimiento y la eficiencia de los consumidores. Demasiados hilos pueden generar sobrecarga en el sistema, mientras que muy pocos pueden no aprovechar plenamente el potencial de procesamiento. Es recomendable realizar pruebas de rendimiento y ajustar la concurrencia según las necesidades específicas de la aplicación.
Balanceo de carga entre consumidores
En entornos de producción, es común desplegar múltiples instancias de una aplicación para mejorar la escalabilidad y tolerancia a fallos. Al tener varias instancias con consumidores en el mismo grupo, Kafka distribuirá automáticamente las particiones entre los consumidores disponibles. Esto permite escalar horizontalmente la capacidad de consumo simplemente agregando más instancias de la aplicación.
Por ejemplo, si tenemos un tópico con 6 particiones y dos instancias de la aplicación, y cada una tiene una concurrencia configurada de 3, en conjunto podrán consumir las 6 particiones de manera equilibrada.
Reasignación de particiones
Cuando se agregan o eliminan consumidores de un grupo, Kafka realiza un reequilibrio (rebalance) de las particiones asignadas. Esto puede causar breves interrupciones en el consumo de mensajes mientras se reorganiza la asignación. Es importante diseñar la aplicación para manejar estos eventos y garantizar que no se pierdan mensajes durante el proceso.
Configuración avanzada
Además de la propiedad concurrency, existen otras configuraciones que pueden optimizar el rendimiento de los consumidores:
max.poll.records: Controla el número máximo de registros que el consumidor recupera en una sola llamada de poll. Ajustar este valor puede mejorar la eficiencia del procesamiento por lote.
sessión.timeout.ms y heartbeat.interval.ms: Ajustan los parámetros relacionados con la detección de fallos de los consumidores. Configurarlos adecuadamente puede mejorar la estabilidad del grupo de consumidores.
Estas propiedades se pueden establecer en la configuración del consumidor:
propiedades.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 1000);
propiedades.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 15000);
propiedades.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 3000);
Uso de particiones para garantizar el orden
Si es necesario mantener el orden de los mensajes para ciertos casos, se puede implementar una estrategia donde los mensajes relacionados se envíen a la misma partición utilizando una clave de partición (partition key). De esta manera, aunque haya concurrencia, los mensajes relacionados entre sí serán procesados secuencialmente por un solo hilo.
Monitoreo y métricas
Es fundamental implementar herramientas de monitoreo para observar el comportamiento de los consumidores y ajustar la configuración según sea necesario. Métricas como el lag de los consumidores, el throughput y la latencia pueden proporcionar información valiosa para optimizar la concurrencia y el número de particiones.
Resumen de recomendaciones
- Establecer la concurrencia en función del número de particiones del tópico y el rendimiento deseado.
- Realizar pruebas y monitorear la aplicación para ajustar la configuración de manera óptima.
- Considerar el impacto en el orden de los mensajes al incrementar la concurrencia.
- Diseñar la aplicación para manejar la reasignación de particiones y los eventos de reequilibrio.
- Aprovechar el balanceo automático de carga al desplegar múltiples instancias de la aplicación.
- Con una configuración adecuada de concurrencia y particiones, es posible mejorar significativamente el rendimiento y la escalabilidad de las aplicaciones que consumen mensajes de Kafka en Spring Boot 4.
Manejo de offset: automático vs manual
En el procesamiento de mensajes con Apache Kafka, el offset es un concepto fundamental que determina la posición actual de un consumidor en un tópico. El manejo adecuado del offset garantiza que los mensajes se consuman de manera eficiente y sin pérdidas. En Spring Boot 4, podemos gestionar el offset de forma automática o manual, dependiendo de las necesidades de nuestra aplicación. A continuación, exploraremos en detalle ambas opciones y cómo implementarlas utilizando las prácticas más modernas de Java.
Compromiso automático del offset
Por defecto, Kafka utiliza un compromiso automático del offset, lo que significa que después de consumir un mensaje, el consumidor actualiza automáticamente su posición. Esto se gestiona a través de la propiedad enable.auto.commit.
propiedades.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
Con esta configuración, el consumer se encarga de enviar periódicamente, cada intervalo definido por auto.commit.interval.ms, el offset más reciente al coordinador del grupo. Esto simplifica el proceso, pero conlleva ciertos riesgos si el procesamiento de los mensajes implica operaciones lentas o susceptibles a errores.
Por ejemplo:
propiedades.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000); // 1 segundo
Ventajas del compromiso automático
- Simplicidad: No es necesario añadir lógica adicional para gestionar el offset.
- Menor carga de código: El consumidor se centra únicamente en procesar los mensajes.
Desventajas del compromiso automático
- Riesgo de pérdida de mensajes: Si ocurre una excepción después de que se haya comprometido el offset, el mensaje podría considerarse procesado cuando no lo ha sido.
- Procesamiento duplicado: En caso de reinicio del consumidor, es posible que se vuelvan a procesar mensajes ya comprometidos si el compromiso se produjo antes de finalizar el procesamiento.
Implementación del compromiso automático
Al utilizar @KafkaListener, por defecto se aplica el compromiso automático. Un ejemplo sencillo sería:
@KafkaListener(topics = "topico_autocommit", groupId = "grupo_autocommit")
public void consumirMensaje(String mensaje) {
System.out.println("Mensaje recibido: " + mensaje);
// Lógica de procesamiento
}
En este caso, no es necesario configurar nada más, ya que Spring Boot utilizará las propiedades predeterminadas del consumidor.
Compromiso manual del offset
Para tener un mayor control sobre cuándo se compromete el offset, podemos optar por un compromiso manual. Esto es especialmente útil cuando el procesamiento de los mensajes es complejo o si necesitamos garantizar que un mensaje se ha procesado exitosamente antes de avanzar al siguiente.
Para establecer el compromiso manual, debemos ajustar las propiedades del consumidor:
propiedades.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
Al desactivar el compromiso automático, somos responsables de indicar explícitamente cuándo se debe actualizar el offset.
Ventajas del compromiso manual
- Control preciso: Podemos asegurarnos de que el offset se compromete solo después de un procesamiento exitoso.
- Evitar pérdida de mensajes: En caso de fallo, el consumidor retomará desde el último offset comprometido conocido.
Desventajas del compromiso manual
- Complejidad añadida: Se requiere manejar manualmente el compromiso, lo que implica más código y potencialmente más errores.
- Sobrecarga: Si no se gestiona adecuadamente, puede afectar al rendimiento del consumidor.
Implementación del compromiso manual
Para implementar el compromiso manual en Spring Boot 4, podemos utilizar la interfaz Acknowledgment que proporciona @KafkaListener. Este objeto nos permite controlar el momento exacto en que se compromete el offset.
@KafkaListener(topics = "topico_manualcommit", groupId = "grupo_manualcommit")
public void consumirMensaje(String mensaje, Acknowledgment acknowledgment) {
try {
System.out.println("Mensaje recibido: " + mensaje);
// Lógica de procesamiento
acknowledgment.acknowledge(); // Compromiso del offset
} catch (Exception e) {
// Manejo de excepciones
System.err.println("Error al procesar el mensaje: " + e.getMessage());
}
}
En este ejemplo:
- Procesamos el mensaje dentro de un bloque
try-catchpara capturar posibles excepciones. - Solo llamamos a
acknowledge()si el procesamiento fue exitoso. - Si ocurre una excepción, no se compromete el offset, lo que permite reintentar el procesamiento en el futuro.
Uso de sincronicidad en el compromiso manual
En situaciones donde sea necesario asegurar que el compromiso del offset se ha realizado correctamente antes de continuar, es posible utilizar métodos sincrónicos. Podemos configurar el consumidor para utilizar compromiso de offset sincrónico:
propiedades.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
propiedades.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 1);
Con MAX_POLL_RECORDS_CONFIG establecido en 1, controlamos el número de registros que se recuperan en cada poll, facilitando el manejo individual de los mensajes.
Compromiso manual con lote de mensajes
Si deseamos procesar mensajes en lotes y comprometer los offsets después de procesar cada lote, podemos modificar el @KafkaListener para recibir una lista de mensajes:
@KafkaListener(topics = "topico_batch", groupId = "grupo_batch", containerFactory = "kafkaListenerContainerFactory")
public void consumirMensajes(List<String> mensajes, Acknowledgment acknowledgment) {
System.out.println("Mensajes recibidos: " + mensajes.size());
try {
for (String mensaje : mensajes) {
// Lógica de procesamiento para cada mensaje
System.out.println("Procesando mensaje: " + mensaje);
}
acknowledgment.acknowledge(); // Compromiso del offset del lote
} catch (Exception e) {
// Manejo de excepciones
System.err.println("Error al procesar el lote de mensajes: " + e.getMessage());
}
}
Para que este método funcione, debemos configurar el ConcurrentKafkaListenerContainerFactory para soportar el modo de lote:
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, String>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true); // Activar modo de lote
return factory;
}
En este caso:
- Procesamos múltiples mensajes en una única invocación del método.
- Comprometemos el offset solo después de procesar exitosamente todo el lote.
- Esto puede mejorar la eficiencia en escenarios con alto volumen de mensajes.
Estrategias avanzadas de compromiso
Compromiso asíncrono
Podemos realizar un compromiso asíncrono del offset para evitar bloquear el hilo de procesamiento:
acknowledgment.acknowledgeAsync((offsets, exception) -> {
if (exception != null) {
System.err.println("Error al comprometer el offset: " + exception.getMessage());
} else {
System.out.println("Offset comprometido: " + offsets);
}
});
Esta técnica es útil para reducir la latencia en aplicaciones de alto rendimiento.
Compromiso explícito del offset
También es posible utilizar el objeto Consumer para un control más granular:
@KafkaListener(topics = "topico_consumer", groupId = "grupo_consumer")
public void consumirMensaje(String mensaje, org.apache.kafka.clients.consumer.Consumer<?, ?> consumer, ConsumerRecord<?, ?> record) {
try {
System.out.println("Mensaje recibido: " + mensaje);
// Lógica de procesamiento
Map<TopicPartition, OffsetAndMetadata> offsets = Collections.singletonMap(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1)
);
consumer.commitSync(offsets); // Compromiso sincrónico del offset
} catch (Exception e) {
// Manejo de excepciones
System.err.println("Error al procesar el mensaje: " + e.getMessage());
}
}
Con este enfoque:
- Utilizamos
consumer.commitSync()para comprometer el offset específico. - Sumamos
1al offset actual para indicar el siguiente mensaje a consumir. - Tenemos un control total sobre el proceso de compromiso.
Configuración de políticas de reinicio
Es importante considerar cómo el consumidor manejará los offsets en caso de reinicios o fallos. Podemos configurar la propiedad auto.offset.reset para especificar el comportamiento cuando no hay un offset inicial:
propiedades.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // Desde el principio
Las opciones disponibles son:
- earliest: El consumidor empezará desde el offset más antiguo disponible.
- latest: Comenzará desde el offset más reciente.
- none: Lanza una excepción si no hay un offset previo.
Esta configuración es crucial para aplicaciones que no pueden permitirse perder mensajes o que deben evitar procesar mensajes antiguos.
Manejo de commits fallidos
En escenarios donde el compromiso del offset pueda fallar, es recomendable implementar mecanismos de reintento y métrica de monitoreo. Por ejemplo, usando un contador de intentos:
int intentos = 0;
boolean comprometido = false;
while (!comprometido && intentos < MAX_INTENTOS) {
try {
acknowledgment.acknowledge();
comprometido = true;
} catch (Exception e) {
intentos++;
System.err.println("Reintentando compromiso del offset. Intento: " + intentos);
// Esperar antes de reintentar
Thread.sleep(1000);
}
}
if (!comprometido) {
// Acción en caso de fallo
System.err.println("No se pudo comprometer el offset después de varios intentos.");
}
Con este enfoque, aumentamos la robustez del consumidor ante posibles fallos transitorios.
Buenas prácticas en el manejo de offsets
Procesamiento idempotente: Diseñar el procesamiento de los mensajes de manera que, si se procesan varias veces, no generen inconsistencias. Esto es vital cuando existe la posibilidad de reintentos o duplicados.
Monitoreo: Implementar herramientas de monitoreo para rastrear el progreso del consumidor y detectar posibles atascos o retrasos en el compromiso de offsets.
Transacciones: Considerar el uso de transacciones cuando se interactúa con sistemas externos. Esto garantiza la atomicidad entre el procesamiento y el compromiso del offset.
Control de flujo: Ajustar propiedades como max.poll.interval.ms y max.poll.records para equilibrar el rendimiento y la estabilidad del consumidor.
Consideraciones sobre el reequilibrio de consumidores
Cuando se añaden o eliminan consumidores en un grupo, Kafka realiza un reequilibrio de las particiones asignadas. Durante este proceso, es posible que se interrumpa temporalmente el consumo y, si no se ha comprometido el offset adecuadamente, podrían procesarse mensajes de nuevo o perderse algunos.
Para mitigar este efecto:
- Mantener sesiones estables: Evitar que los consumidores se desconecten frecuentemente.
- Gestionar las excepciones: Asegurarse de que el consumidor maneja las excepciones sin cerrar la sesión abruptamente.
- Configurar el timeout de sesión: Ajustar
sessión.timeout.mspara dar margen suficiente al consumidor antes de ser considerado inactivo.
Ejemplo completo de compromiso manual
A continuación, se presenta un ejemplo que integra varias de las prácticas mencionadas:
@KafkaListener(topics = "topico_ejemplo", groupId = "grupo_ejemplo")
public void consumirMensaje(ConsumerRecord<String, String> record, Acknowledgment acknowledgment) {
try {
String mensaje = record.value();
System.out.println("Mensaje recibido: " + mensaje);
// Lógica de procesamiento
acknowledgment.acknowledge(); // Comprometer offset
} catch (Exception e) {
// Manejo de excepciones
System.err.println("Error al procesar el mensaje: " + e.getMessage());
// Opcional: enviar el mensaje a un tópico de fallos
}
}
En este código:
- Utilizamos
ConsumerRecordpara acceder a metadatos del mensaje, como el offset y la partición. - Implementamos un manejo de excepciones robusto.
- Realizamos el compromiso manual del offset solo después de un procesamiento exitoso.
El manejo del offset en consumidores de Kafka es un aspecto crítico que afecta directamente a la fiabilidad y consistencia de las aplicaciones. Elegir entre el compromiso automático y manual depende de los requisitos específicos de procesamiento y del nivel de control que se necesita.
Manejo de errores y reintentos en consumidores
El manejo de errores y la implementación de reintentos en consumidores de Apache Kafka son aspectos cruciales para garantizar la fiabilidad y resiliencia de las aplicaciones. En Spring Boot 4, contamos con herramientas para gestionar excepciones y configurar políticas de reintento de forma efectiva. A continuación, se detallan las estrategias y configuraciones necesarias para implementar un manejo robusto de errores en consumidores.
Control de excepciones en métodos @KafkaListener
Cuando se utiliza @KafkaListener para consumir mensajes, pueden ocurrir excepciones durante el procesamiento. Por defecto, estas excepciones son capturadas por el contenedor y se realiza un reintento infinito, lo que puede provocar bloqueos si el error es permanente. Para manejar esto, es recomendable capturar las excepciones dentro del método y aplicar una lógica adecuada.
@KafkaListener(topics = "topico_errores", groupId = "grupo_errores")
public void consumirMensaje(String mensaje) {
try {
// Lógica de procesamiento
procesarMensaje(mensaje);
} catch (Exception e) {
// Manejo de la excepción
registrarError(e, mensaje);
}
}
En este ejemplo, se captura cualquier excepción y se puede decidir cómo proceder, ya sea registrando el error, enviando una alerta o almacenando el mensaje para su posterior análisis.
Configuración de un ErrorHandler personalizado
Spring Kafka permite configurar un ErrorHandler para manejar excepciones de manera centralizada. Podemos definir un CommonErrorHandler y asignarlo al ConcurrentKafkaListenerContainerFactory.
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, String>();
factory.setConsumerFactory(consumerFactory());
factory.setCommonErrorHandler(errorHandler());
return factory;
}
@Bean
public CommonErrorHandler errorHandler() {
var errorHandler = new DefaultErrorHandler(
new FixedBackOff(1000L, 3L) // Retraso de 1 segundo y 3 reintentos
);
errorHandler.setRetryListeners((record, ex, deliveryAttempt) -> {
System.out.println("Intento de reintento: " + deliveryAttempt);
});
return errorHandler;
}
Con este ErrorHandler, se configura un FixedBackOff que realiza hasta 3 reintentos con un retraso de 1 segundo entre cada uno. Además, se puede agregar un RetryListener para registrar los intentos de reintento.
Uso de RetryTemplate para control avanzado de reintentos
Para necesidades más avanzadas, es posible utilizar un RetryTemplate que ofrece mayor flexibilidad en la estrategia de reintento. Podemos configurar el RetryTemplate y asignarlo al ConcurrentKafkaListenerContainerFactory.
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, String>();
factory.setConsumerFactory(consumerFactory());
factory.setRetryTemplate(retryTemplate());
return factory;
}
@Bean
public RetryTemplate retryTemplate() {
var retryTemplate = new RetryTemplate();
var fixedBackOffPolicy = new FixedBackOffPolicy();
fixedBackOffPolicy.setBackOffPeriod(2000L); // Retraso de 2 segundos
retryTemplate.setBackOffPolicy(fixedBackOffPolicy);
var simpleRetryPolicy = new SimpleRetryPolicy();
simpleRetryPolicy.setMaxAttempts(5); // Hasta 5 intentos
retryTemplate.setRetryPolicy(simpleRetryPolicy);
return retryTemplate;
}
En esta configuración, se establece una política de reintento con un máximo de 5 intentos y un retraso fijo de 2 segundos entre ellos. El RetryTemplate permite combinar diferentes políticas y manejar excepciones específicas.
Implementación de un Dead Letter Topic
Cuando un mensaje no puede procesarse después de varios reintentos, es recomendable enviarlo a un Dead Letter Topic para su posterior análisis. Esto se puede configurar utilizando el DeadLetterPublishingRecoverer.
@Bean
public CommonErrorHandler errorHandler(KafkaTemplate<String, String> kafkaTemplate) {
var recoverer = new DeadLetterPublishingRecoverer(kafkaTemplate);
var errorHandler = new DefaultErrorHandler(recoverer, new FixedBackOff(1000L, 3L));
return errorHandler;
}
Es esencial configurar un KafkaTemplate adecuado y asegurarse de que el tópico de dead letters esté creado en el clúster de Kafka.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Spring Boot es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Spring Boot
Explora más contenido relacionado con Spring Boot y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Aprender qué es un Consumer. Saber cómo crear consumers con @KafkaListener. Aprender a configurar Consumers. Aprender qué son los grupos de Consumers.