Creación de threads
La concurrencia es una característica fundamental en la programación moderna que permite ejecutar múltiples tareas simultáneamente. En Rust, la concurrencia se implementa de manera segura gracias a su sistema de propiedad y préstamo, evitando muchos problemas comunes como las condiciones de carrera en tiempo de compilación.
Un thread (o hilo) es la unidad básica de ejecución que puede ser programada por el sistema operativo. Rust proporciona soporte para la creación y gestión de threads a través del módulo std::thread de su biblioteca estándar.
Creando threads con spawn
La forma más común de crear un nuevo thread en Rust es utilizando la función std::thread::spawn. Esta función recibe un closure que contiene el código que se ejecutará en el nuevo thread:
use std::thread;
fn main() {
// Creamos un nuevo thread
thread::spawn(|| {
println!("¡Hola desde un thread secundario!");
});
println!("¡Hola desde el thread principal!");
}
Al ejecutar este código, notarás que el orden de los mensajes puede variar entre ejecuciones. Esto se debe a que los threads se ejecutan de forma concurrente y el planificador del sistema operativo decide cuándo se ejecuta cada uno.
Capturando valores del entorno
Los closures en Rust pueden capturar valores del entorno donde son definidos. Cuando trabajamos con threads, necesitamos tener en cuenta las reglas de propiedad de Rust:
use std::thread;
fn main() {
let mensaje = String::from("¡Hola desde un thread!");
thread::spawn(move || {
// Usamos 'move' para transferir la propiedad de 'mensaje' al closure
println!("{}", mensaje);
});
// Error: no podemos usar 'mensaje' aquí porque su propiedad fue transferida
// println!("{}", mensaje);
}
La palabra clave move es crucial cuando trabajamos con threads en Rust. Fuerza al closure a tomar posesión de todas las variables que captura del entorno, lo que es necesario porque:
- El thread principal podría terminar antes que el thread secundario
- Las referencias a variables locales podrían quedar invalidadas
Devolviendo valores desde threads
Para obtener un valor calculado en un thread, necesitamos un mecanismo para recuperar ese resultado. La función spawn devuelve un JoinHandle<T>, que podemos utilizar para interactuar con el thread:
use std::thread;
fn main() {
// spawn devuelve un JoinHandle
let handle = thread::spawn(|| {
// Calculamos algo
let resultado = 42;
// El valor devuelto por el closure será el resultado del thread
resultado
});
// Continuamos con otras operaciones mientras el thread trabaja
println!("Trabajando en el thread principal...");
// Obtenemos el resultado cuando lo necesitemos
// (veremos más sobre join en la siguiente sección)
}
Creando múltiples threads
Podemos crear múltiples threads para realizar tareas en paralelo:
use std::thread;
fn main() {
let mut handles = vec![];
// Creamos 5 threads
for id in 0..5 {
// Clonamos el id para moverlo al closure
let thread_id = id;
// Almacenamos el handle para usarlo después
let handle = thread::spawn(move || {
println!("Thread {} ejecutándose", thread_id);
thread_id
});
handles.push(handle);
}
println!("Todos los threads han sido creados");
// Los handles se pueden usar posteriormente para sincronización
}
Configuración de threads
Rust permite configurar ciertos aspectos de los threads antes de crearlos mediante el builder pattern:
use std::thread;
fn main() {
// Usamos el builder para configurar el thread
let handle = thread::Builder::new()
.name("thread-personalizado".to_string()) // Asignamos un nombre
.stack_size(32 * 1024) // Configuramos el tamaño de la pila (32KB)
.spawn(|| {
println!("Thread con configuración personalizada");
// Podemos obtener información sobre el thread actual
let thread = thread::current();
println!("Nombre del thread: {:?}", thread.name());
})
.unwrap(); // spawn devuelve un Result que debemos manejar
}
El builder pattern nos permite:
- Asignar nombres a los threads para facilitar la depuración
- Configurar el tamaño de la pila según las necesidades de la tarea
- Controlar otros parámetros específicos del thread
Consideraciones de rendimiento
Al trabajar con threads, es importante tener en cuenta algunas consideraciones de rendimiento:
- La creación de threads tiene un coste asociado en términos de recursos del sistema
- Cada thread consume memoria para su pila (por defecto varios MB en la mayoría de sistemas)
- Demasiados threads pueden degradar el rendimiento debido al cambio de contexto
use std::thread;
use std::time::Duration;
fn main() {
// Ejemplo de creación de threads con trabajo simulado
let handles: Vec<_> = (0..4)
.map(|id| {
thread::spawn(move || {
// Simulamos trabajo que toma tiempo
let trabajo_ms = (id + 1) * 250;
println!("Thread {} iniciando trabajo de {}ms", id, trabajo_ms);
thread::sleep(Duration::from_millis(trabajo_ms));
println!("Thread {} completó su trabajo", id);
id
})
})
.collect();
println!("Threads creados, continuando con el thread principal");
}
Threads para operaciones de E/S
Los threads son especialmente útiles para operaciones de entrada/salida que pueden bloquear la ejecución, como lecturas de archivos o solicitudes de red:
use std::thread;
use std::fs::File;
use std::io::{self, Read};
fn leer_archivo(ruta: &str) -> io::Result<Vec<u8>> {
let mut archivo = File::open(ruta)?;
let mut contenido = Vec::new();
archivo.read_to_end(&mut contenido)?;
Ok(contenido)
}
fn main() -> io::Result<()> {
// Rutas de ejemplo (asegúrate de que existan)
let rutas = vec!["archivo1.txt", "archivo2.txt", "archivo3.txt"];
// Creamos un thread para cada archivo
let handles: Vec<_> = rutas
.into_iter()
.map(|ruta| {
let ruta_owned = ruta.to_owned();
thread::spawn(move || {
match leer_archivo(&ruta_owned) {
Ok(contenido) => println!("Leídos {} bytes de {}", contenido.len(), ruta_owned),
Err(e) => eprintln!("Error al leer {}: {}", ruta_owned, e),
}
})
})
.collect();
println!("Threads de lectura iniciados");
// Continuamos con otras operaciones mientras los archivos se leen
Ok(())
}
Limitaciones y alternativas
Aunque los threads son potentes, tienen algunas limitaciones:
- Son recursos del sistema operativo con cierta sobrecarga
- El número óptimo de threads suele estar relacionado con el número de núcleos de CPU
- Para concurrencia a gran escala, Rust ofrece alternativas como async/await
use std::thread;
fn main() {
// Obtenemos el número de CPUs lógicas
let num_cpus = num_cpus::get();
println!("Este sistema tiene {} núcleos lógicos", num_cpus);
// Creamos un thread pool del tamaño óptimo (normalmente igual al número de núcleos)
let handles: Vec<_> = (0..num_cpus)
.map(|id| {
thread::spawn(move || {
println!("Worker thread {} iniciado", id);
// Trabajo intensivo en CPU
})
})
.collect();
println!("Pool de threads creado con {} workers", num_cpus);
}
Para usar el ejemplo anterior, necesitarías agregar la dependencia num_cpus a tu archivo Cargo.toml:
[dependencies]
num_cpus = "1.13"
Los threads de Rust proporcionan una base sólida para la programación concurrente, permitiéndote aprovechar los sistemas multinúcleo modernos mientras mantienes la seguridad que caracteriza al lenguaje. En las siguientes secciones, exploraremos cómo sincronizar estos threads y compartir datos entre ellos de manera segura.
Join y sincronización
Cuando trabajamos con threads en Rust, necesitamos mecanismos para coordinar su ejecución y asegurarnos de que completen sus tareas antes de que el programa termine. La sincronización entre threads es fundamental para construir programas concurrentes robustos.
El método join
El método join es la forma más básica de sincronización en Rust. Este método, disponible en el tipo JoinHandle<T> que obtenemos al crear un thread, bloquea el thread actual hasta que el thread asociado al handle termine su ejecución:
use std::thread;
fn main() {
let handle = thread::spawn(|| {
// Simulamos una tarea que toma tiempo
println!("Thread secundario: iniciando trabajo...");
thread::sleep(std::time::Duration::from_millis(1000));
println!("Thread secundario: trabajo completado");
// Valor de retorno del thread
"Resultado del thread secundario"
});
println!("Thread principal: esperando a que el thread secundario termine...");
// join() bloquea el thread principal hasta que el secundario termine
let resultado = handle.join().unwrap();
println!("Thread principal: thread secundario completado");
println!("Resultado obtenido: {}", resultado);
}
El método join devuelve un Result<T, E> donde:
Tes el tipo de retorno del closure del threadErepresenta un error si el thread entró en pánico
Manejo de errores con join
Si un thread termina con un pánico, el método join devolverá un Err que contiene el valor de pánico. Podemos manejar esta situación de forma elegante:
use std::thread;
fn main() {
let handle = thread::spawn(|| {
if rand::random::<bool>() {
panic!("¡Algo salió mal en el thread!");
}
"Operación exitosa"
});
// Manejamos el resultado de join
match handle.join() {
Ok(valor) => println!("Thread completado con éxito: {}", valor),
Err(e) => println!("El thread entró en pánico: {:?}", e),
}
}
Para ejecutar este ejemplo, necesitarás agregar la dependencia rand a tu Cargo.toml:
[dependencies]
rand = "0.8"
Sincronización de múltiples threads
Cuando trabajamos con múltiples threads, podemos usar join para esperar a que todos completen su ejecución:
use std::thread;
use std::time::Duration;
fn main() {
let mut handles = vec![];
// Creamos varios threads
for i in 0..5 {
let handle = thread::spawn(move || {
let tiempo_espera = Duration::from_millis(i * 200);
thread::sleep(tiempo_espera);
println!("Thread {} completado", i);
i
});
handles.push(handle);
}
println!("Todos los threads han sido creados");
// Recolectamos los resultados
let resultados: Vec<_> = handles
.into_iter()
.map(|h| h.join().unwrap())
.collect();
println!("Todos los threads han terminado");
println!("Resultados: {:?}", resultados);
}
Este patrón es muy útil para implementar paralelismo de datos, donde dividimos un problema grande en partes más pequeñas que pueden procesarse concurrentemente.
Barreras de sincronización
A veces necesitamos que varios threads lleguen a un punto específico antes de continuar. Para esto, Rust proporciona la estructura Barrier en el módulo std::sync:
use std::sync::{Arc, Barrier};
use std::thread;
fn main() {
let num_threads = 5;
// Arc permite compartir la barrera entre múltiples threads
let barrera = Arc::new(Barrier::new(num_threads));
let mut handles = vec![];
for id in 0..num_threads {
let b = Arc::clone(&barrera);
let handle = thread::spawn(move || {
println!("Thread {} realizando fase 1", id);
thread::sleep(std::time::Duration::from_millis(id * 100));
// Todos los threads esperarán aquí hasta que los 5 lleguen
b.wait();
println!("Thread {} comenzando fase 2", id);
// Segunda fase del trabajo...
id
});
handles.push(handle);
}
// Esperamos a que todos los threads terminen
for handle in handles {
handle.join().unwrap();
}
println!("Todas las fases completadas");
}
La barrera garantiza que todos los threads completen la primera fase antes de que cualquiera comience la segunda, lo que es útil para algoritmos que requieren sincronización en etapas.
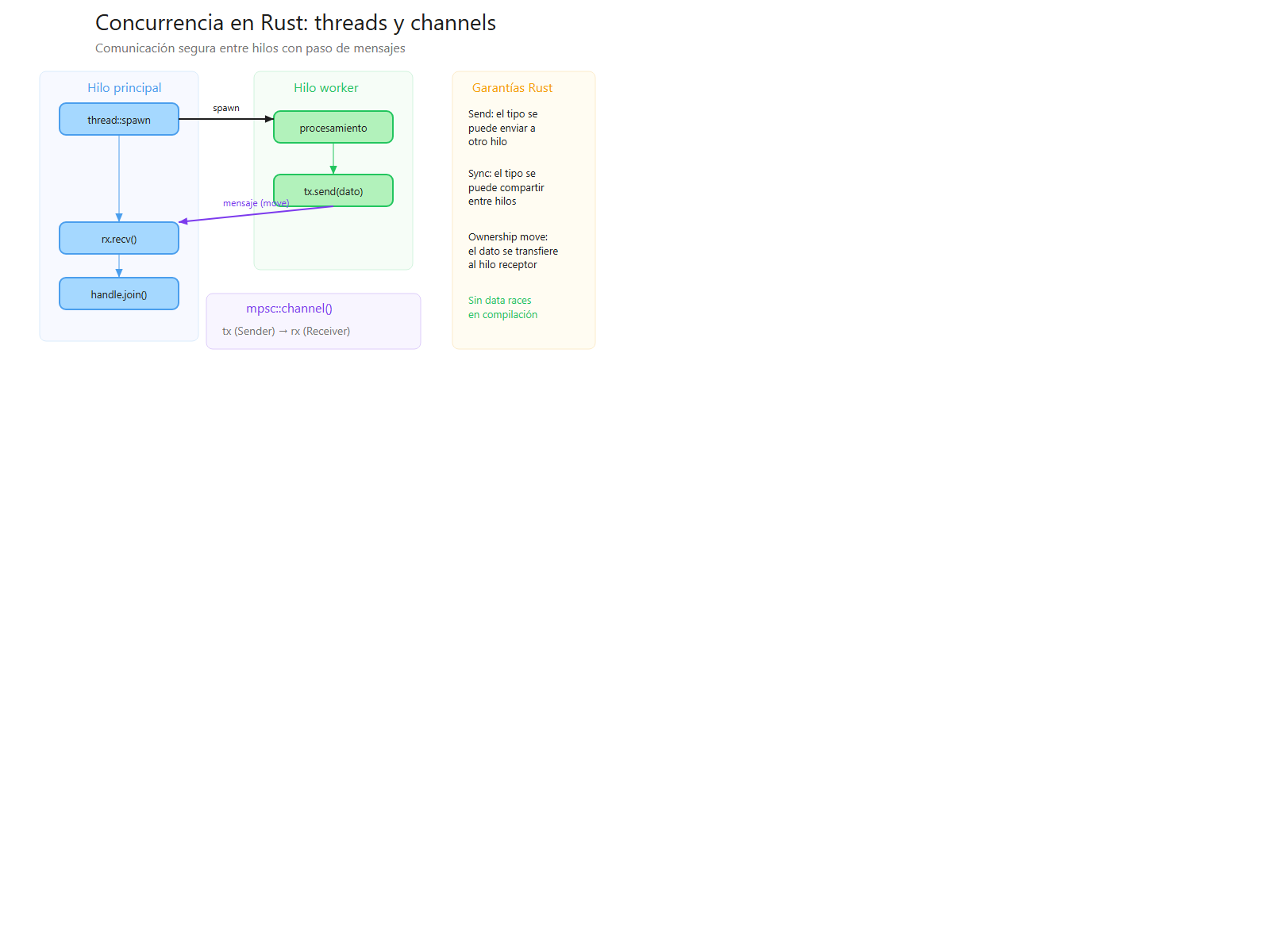
Comunicación entre threads con canales
Además de sincronizar la ejecución, a menudo necesitamos que los threads se comuniquen entre sí. Rust proporciona canales para este propósito:
use std::sync::mpsc; // multiple producer, single consumer
use std::thread;
fn main() {
// Creamos un canal
let (tx, rx) = mpsc::channel();
// Movemos el transmisor al thread secundario
let handle = thread::spawn(move || {
// Realizamos algún trabajo
let resultado = 42;
// Enviamos el resultado al thread principal
tx.send(resultado).unwrap();
println!("Resultado enviado desde el thread secundario");
});
// Recibimos el resultado en el thread principal
let valor_recibido = rx.recv().unwrap();
println!("Recibido en el thread principal: {}", valor_recibido);
// Esperamos a que el thread termine
handle.join().unwrap();
}
Los canales proporcionan una forma segura de transferir datos entre threads sin necesidad de compartir memoria directamente, siguiendo el principio de "comunicar compartiendo, no compartir comunicando".
Sincronización con temporizadores
A veces necesitamos sincronizar threads basándonos en el tiempo. Rust proporciona funciones para pausar la ejecución durante un período específico:
use std::thread;
use std::time::{Duration, Instant};
fn main() {
let inicio = Instant::now();
let handle = thread::spawn(move || {
println!("Thread secundario: iniciando trabajo largo...");
thread::sleep(Duration::from_secs(2));
println!("Thread secundario: trabajo completado");
});
// Esperamos un tiempo máximo
let timeout = Duration::from_secs(1);
thread::sleep(timeout);
println!("Thread principal: han pasado {} segundos", inicio.elapsed().as_secs());
println!("Thread principal: continuando sin esperar más");
// Aún podemos esperar a que el thread termine
handle.join().unwrap();
println!("Tiempo total: {} segundos", inicio.elapsed().as_secs());
}
Este patrón es útil para implementar timeouts en operaciones concurrentes, permitiendo que el programa continúe incluso si algún thread tarda demasiado.
Sincronización con park y unpark
Para casos de sincronización más específicos, Rust proporciona los métodos park y unpark:
use std::thread;
use std::time::Duration;
fn main() {
let parked_thread = thread::spawn(|| {
println!("Thread secundario: esperando señal...");
// El thread se "estaciona" hasta que reciba una señal
thread::park();
println!("Thread secundario: señal recibida, continuando");
// Continuamos con el trabajo
"Trabajo completado"
});
// Damos tiempo para que el thread secundario llegue a park()
thread::sleep(Duration::from_millis(500));
println!("Thread principal: enviando señal al thread secundario");
parked_thread.thread().unpark();
let resultado = parked_thread.join().unwrap();
println!("Resultado: {}", resultado);
}
Este mecanismo de bajo nivel permite implementar patrones de sincronización personalizados cuando las barreras o los canales no son suficientes.
Sincronización cooperativa
A diferencia de algunos lenguajes que ofrecen primitivas para forzar la terminación de threads, Rust promueve un enfoque cooperativo donde los threads verifican periódicamente si deben continuar:
use std::sync::atomic::{AtomicBool, Ordering};
use std::sync::Arc;
use std::thread;
use std::time::Duration;
fn main() {
// Flag compartido para indicar si el thread debe continuar
let ejecutar = Arc::new(AtomicBool::new(true));
let ejecutar_clon = Arc::clone(&ejecutar);
let handle = thread::spawn(move || {
let mut contador = 0;
// El thread verifica periódicamente si debe continuar
while ejecutar_clon.load(Ordering::Relaxed) {
contador += 1;
println!("Trabajando... (iteración {})", contador);
thread::sleep(Duration::from_millis(200));
// Simulamos que el trabajo está completo después de algunas iteraciones
if contador >= 5 {
break;
}
}
println!("Thread finalizado (completado: {})", contador >= 5);
contador
});
// Esperamos un poco
thread::sleep(Duration::from_secs(1));
// Señalamos al thread que debe terminar
println!("Solicitando finalización del thread");
ejecutar.store(false, Ordering::Relaxed);
// Esperamos a que el thread termine
let iteraciones = handle.join().unwrap();
println!("Thread completó {} iteraciones", iteraciones);
}
Este patrón de cancelación cooperativa es más seguro que forzar la terminación de threads, ya que permite que los recursos se liberen adecuadamente.
La sincronización de threads en Rust combina mecanismos de bajo nivel con abstracciones de alto nivel, permitiéndote elegir las herramientas adecuadas para cada situación. El sistema de tipos de Rust garantiza que estas operaciones sean seguras, evitando problemas comunes en la programación concurrente como las condiciones de carrera.
Mutex y RwLock
Cuando trabajamos con concurrencia en Rust, uno de los mayores desafíos es compartir datos entre múltiples threads de forma segura. El sistema de ownership de Rust previene muchos problemas en tiempo de compilación, pero necesitamos mecanismos específicos para compartir estado mutable entre threads.
Mutex: Exclusión mutua
Un Mutex (abreviatura de "mutual exclusion" o exclusión mutua) es una primitiva de sincronización que garantiza que solo un thread a la vez pueda acceder a los datos protegidos. En Rust, los mutex se implementan a través de la estructura std::sync::Mutex<T>:
use std::sync::Mutex;
use std::thread;
use std::sync::Arc;
fn main() {
// Creamos un mutex que contiene un contador
let contador = Arc::new(Mutex::new(0));
let mut handles = vec![];
// Creamos 10 threads que incrementarán el contador
for _ in 0..10 {
let contador_clon = Arc::clone(&contador);
let handle = thread::spawn(move || {
// Bloqueamos el mutex para obtener acceso exclusivo
let mut num = contador_clon.lock().unwrap();
// Modificamos el valor protegido
*num += 1;
// Al salir del scope, el bloqueo se libera automáticamente
});
handles.push(handle);
}
// Esperamos a que todos los threads terminen
for handle in handles {
handle.join().unwrap();
}
// Verificamos el resultado final
println!("Valor final del contador: {}", *contador.lock().unwrap());
}
En este ejemplo, Arc (Atomic Reference Counting) nos permite compartir la propiedad del mutex entre múltiples threads. Algunos puntos importantes sobre los mutex:
- El método
lock()bloquea el thread actual hasta obtener acceso exclusivo a los datos - Devuelve un guard (guardia) que implementa
DerefyDerefMut, permitiendo acceder a los datos - Cuando el guard sale del ámbito, el bloqueo se libera automáticamente
lock()devuelve unResultporque el bloqueo puede fallar si otro thread que lo tenía entró en pánico
Manejo de errores con Mutex
Si un thread que tiene bloqueado un mutex entra en pánico, el mutex queda en estado "envenenado" (poisoned). Esto es una característica de seguridad para indicar que los datos pueden estar en un estado inconsistente:
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let datos = Arc::new(Mutex::new(vec![1, 2, 3]));
let datos_clon = Arc::clone(&datos);
let handle = thread::spawn(move || {
// Obtenemos acceso exclusivo a los datos
let mut vector = datos_clon.lock().unwrap();
// Modificamos el vector
vector.push(4);
// Simulamos un pánico
panic!("¡Oh no! Algo salió mal mientras teníamos el bloqueo");
});
// Esperamos a que el thread termine (con pánico)
let _ = handle.join();
// Intentamos acceder a los datos después del pánico
match datos.lock() {
Ok(vector) => println!("Vector: {:?}", *vector),
Err(e) => {
// Podemos recuperar los datos incluso si el mutex está envenenado
println!("Mutex envenenado: {:?}", e);
let vector = e.into_inner();
println!("Vector recuperado: {:?}", *vector);
}
}
}
Este comportamiento nos permite detectar y manejar situaciones donde los datos compartidos pueden haber quedado en un estado inconsistente.
Patrones de uso con Mutex
Es importante mantener los bloqueos por el menor tiempo posible para maximizar la concurrencia. Un patrón común es limitar el ámbito del bloqueo:
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let datos = Arc::new(Mutex::new(vec![0; 10]));
let mut handles = vec![];
for id in 0..5 {
let datos_clon = Arc::clone(&datos);
let handle = thread::spawn(move || {
// Mal patrón: mantener el bloqueo durante todo el procesamiento
// let mut vector = datos_clon.lock().unwrap();
// thread::sleep(std::time::Duration::from_millis(100));
// vector[id] = id;
// Buen patrón: minimizar la duración del bloqueo
{
// Calculamos el valor fuera del bloqueo
let valor = procesar_datos(id);
// Bloqueamos solo para la actualización
let mut vector = datos_clon.lock().unwrap();
vector[id] = valor;
// El bloqueo se libera aquí al salir del ámbito
}
// Continuamos con otras operaciones sin bloquear el mutex
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Resultado final: {:?}", *datos.lock().unwrap());
}
fn procesar_datos(id: usize) -> usize {
// Simulamos procesamiento que no requiere el bloqueo
thread::sleep(std::time::Duration::from_millis(100));
id * 10
}
RwLock: Lecturas concurrentes, escrituras exclusivas
Mientras que un Mutex proporciona acceso exclusivo, un RwLock (Read-Write Lock) permite múltiples lectores simultáneos o un único escritor. Esto es útil cuando las lecturas son mucho más frecuentes que las escrituras:
use std::sync::{Arc, RwLock};
use std::thread;
fn main() {
// Creamos un RwLock que contiene datos compartidos
let datos = Arc::new(RwLock::new(vec![1, 2, 3, 4]));
let mut handles = vec![];
// Creamos threads de lectura
for id in 0..3 {
let datos_clon = Arc::clone(&datos);
let handle = thread::spawn(move || {
// Obtenemos acceso de lectura (múltiples threads pueden leer simultáneamente)
let vector = datos_clon.read().unwrap();
println!("Lector {}: vector actual = {:?}", id, *vector);
// El bloqueo de lectura se libera cuando vector sale del ámbito
});
handles.push(handle);
}
// Creamos un thread de escritura
let datos_clon = Arc::clone(&datos);
let handle = thread::spawn(move || {
// Esperamos un poco para que los lectores puedan obtener sus bloqueos primero
thread::sleep(std::time::Duration::from_millis(50));
// Obtenemos acceso de escritura (exclusivo)
let mut vector = datos_clon.write().unwrap();
println!("Escritor: modificando el vector");
vector.push(5);
// El bloqueo de escritura se libera cuando vector sale del ámbito
});
handles.push(handle);
// Esperamos a que todos los threads terminen
for handle in handles {
handle.join().unwrap();
}
// Verificamos el resultado final
println!("Vector final: {:?}", *datos.read().unwrap());
}
Los métodos principales de RwLock son:
read(): Obtiene un bloqueo de lectura compartido (múltiples threads pueden tener bloqueos de lectura simultáneamente)write(): Obtiene un bloqueo de escritura exclusivo (solo un thread puede tener el bloqueo de escritura, y ningún thread puede tener un bloqueo de lectura mientras existe un bloqueo de escritura)
Comparación entre Mutex y RwLock
Elegir entre Mutex y RwLock depende del patrón de acceso a los datos compartidos:
use std::sync::{Arc, Mutex, RwLock};
use std::thread;
use std::time::{Duration, Instant};
fn demostrar_mutex() {
let datos = Arc::new(Mutex::new(0));
let mut handles = vec![];
let inicio = Instant::now();
// 95% lecturas, 5% escrituras
for i in 0..100 {
let datos_clon = Arc::clone(&datos);
let handle = thread::spawn(move || {
if i % 20 == 0 { // 5% escrituras
let mut valor = datos_clon.lock().unwrap();
*valor += 1;
} else { // 95% lecturas
let valor = datos_clon.lock().unwrap();
let _ = *valor; // Solo lectura
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Mutex: {} ms", inicio.elapsed().as_millis());
}
fn demostrar_rwlock() {
let datos = Arc::new(RwLock::new(0));
let mut handles = vec![];
let inicio = Instant::now();
// 95% lecturas, 5% escrituras
for i in 0..100 {
let datos_clon = Arc::clone(&datos);
let handle = thread::spawn(move || {
if i % 20 == 0 { // 5% escrituras
let mut valor = datos_clon.write().unwrap();
*valor += 1;
} else { // 95% lecturas
let valor = datos_clon.read().unwrap();
let _ = *valor; // Solo lectura
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("RwLock: {} ms", inicio.elapsed().as_millis());
}
fn main() {
demostrar_mutex();
demostrar_rwlock();
}
En general:
-
Usa
Mutexcuando: -
Las operaciones de lectura y escritura son igualmente frecuentes
-
La operación protegida es muy rápida
-
La simplicidad es prioritaria
-
Usa
RwLockcuando: -
Las lecturas son mucho más frecuentes que las escrituras
-
Múltiples threads necesitan leer los datos simultáneamente
-
El rendimiento en escenarios de lectura intensiva es crítico
Prevención de deadlocks
Un deadlock (interbloqueo) ocurre cuando dos o más threads se bloquean mutuamente esperando recursos que el otro tiene. Rust no puede prevenir deadlocks en tiempo de compilación, pero podemos seguir buenas prácticas:
use std::sync::{Arc, Mutex};
use std::thread;
use std::time::Duration;
fn main() {
let recurso_a = Arc::new(Mutex::new(0));
let recurso_b = Arc::new(Mutex::new(0));
// Potencial deadlock: dos threads adquieren recursos en orden diferente
let recurso_a_clon = Arc::clone(&recurso_a);
let recurso_b_clon = Arc::clone(&recurso_b);
let thread_1 = thread::spawn(move || {
// Thread 1 adquiere primero A, luego B
let _guard_a = recurso_a_clon.lock().unwrap();
println!("Thread 1: Recurso A adquirido");
// Simulamos trabajo para aumentar la probabilidad de deadlock
thread::sleep(Duration::from_millis(10));
let _guard_b = recurso_b_clon.lock().unwrap();
println!("Thread 1: Recurso B adquirido");
});
let recurso_a_clon = Arc::clone(&recurso_a);
let recurso_b_clon = Arc::clone(&recurso_b);
let thread_2 = thread::spawn(move || {
// Thread 2 adquiere primero B, luego A (orden inverso)
let _guard_b = recurso_b_clon.lock().unwrap();
println!("Thread 2: Recurso B adquirido");
thread::sleep(Duration::from_millis(10));
let _guard_a = recurso_a_clon.lock().unwrap();
println!("Thread 2: Recurso A adquirido");
});
// Este programa puede entrar en deadlock
thread_1.join().unwrap();
thread_2.join().unwrap();
}
Para evitar deadlocks:
- Establece un orden consistente para adquirir múltiples bloqueos
- Minimiza el tiempo que mantienes los bloqueos
- Considera usar
try_lock()con reintentos y tiempos de espera - Utiliza estructuras de datos sin bloqueo cuando sea posible
Mutex interior mutable
Una aplicación común de Mutex es proporcionar mutabilidad interior a tipos que de otro modo serían inmutables:
use std::sync::{Arc, Mutex};
use std::thread;
struct Contador {
valor: Mutex<i32>,
}
impl Contador {
fn new(inicial: i32) -> Self {
Contador {
valor: Mutex::new(inicial),
}
}
fn incrementar(&self) {
let mut valor = self.valor.lock().unwrap();
*valor += 1;
}
fn obtener(&self) -> i32 {
*self.valor.lock().unwrap()
}
}
fn main() {
let contador = Arc::new(Contador::new(0));
let mut handles = vec![];
for _ in 0..10 {
let contador_clon = Arc::clone(&contador);
let handle = thread::spawn(move || {
contador_clon.incrementar();
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Valor final: {}", contador.obtener());
}
Este patrón es muy útil para encapsular el estado mutable compartido dentro de una API segura para concurrencia.
Seguridad en tiempo de compilación
Una de las grandes ventajas del modelo de concurrencia de Rust es que muchos errores comunes se detectan en tiempo de compilación:
use std::sync::Mutex;
use std::thread;
fn main() {
let contador = Mutex::new(0);
// Esto NO compilará: no podemos mover contador a múltiples threads
// let handle = thread::spawn(move || {
// *contador.lock().unwrap() += 1;
// });
// let handle2 = thread::spawn(move || {
// *contador.lock().unwrap() += 1;
// });
// Solución: usar Arc para compartir la propiedad
let contador = std::sync::Arc::new(Mutex::new(0));
let contador_clon = std::sync::Arc::clone(&contador);
let handle = thread::spawn(move || {
*contador_clon.lock().unwrap() += 1;
});
let contador_clon = std::sync::Arc::clone(&contador);
let handle2 = thread::spawn(move || {
*contador_clon.lock().unwrap() += 1;
});
handle.join().unwrap();
handle2.join().unwrap();
println!("Contador: {}", *contador.lock().unwrap());
}
El sistema de tipos de Rust garantiza que:
- Los datos compartidos entre threads deben implementar
SendySync - No puedes acceder a datos mutables desde múltiples threads sin sincronización
- Los bloqueos deben liberarse correctamente
Estas garantías eliminan categorías enteras de errores de concurrencia que son comunes en otros lenguajes.
Las primitivas de sincronización como Mutex y RwLock son fundamentales para construir programas concurrentes seguros en Rust. Combinadas con el sistema de ownership y borrowing, proporcionan un marco robusto para trabajar con datos compartidos entre threads, eliminando muchos errores comunes en tiempo de compilación mientras mantienen un rendimiento excelente.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en Rust
Documentación oficial de Rust
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Rust es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Rust
Explora más contenido relacionado con Rust y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender cómo crear y gestionar threads en Rust usando std::thread. Aprender a sincronizar threads mediante join, barreras y comunicación con canales. Entender el uso de Mutex y RwLock para proteger datos compartidos entre threads. Identificar patrones para evitar deadlocks y manejar errores en concurrencia. Conocer las garantías de seguridad en tiempo de compilación que ofrece Rust para la programación concurrente.