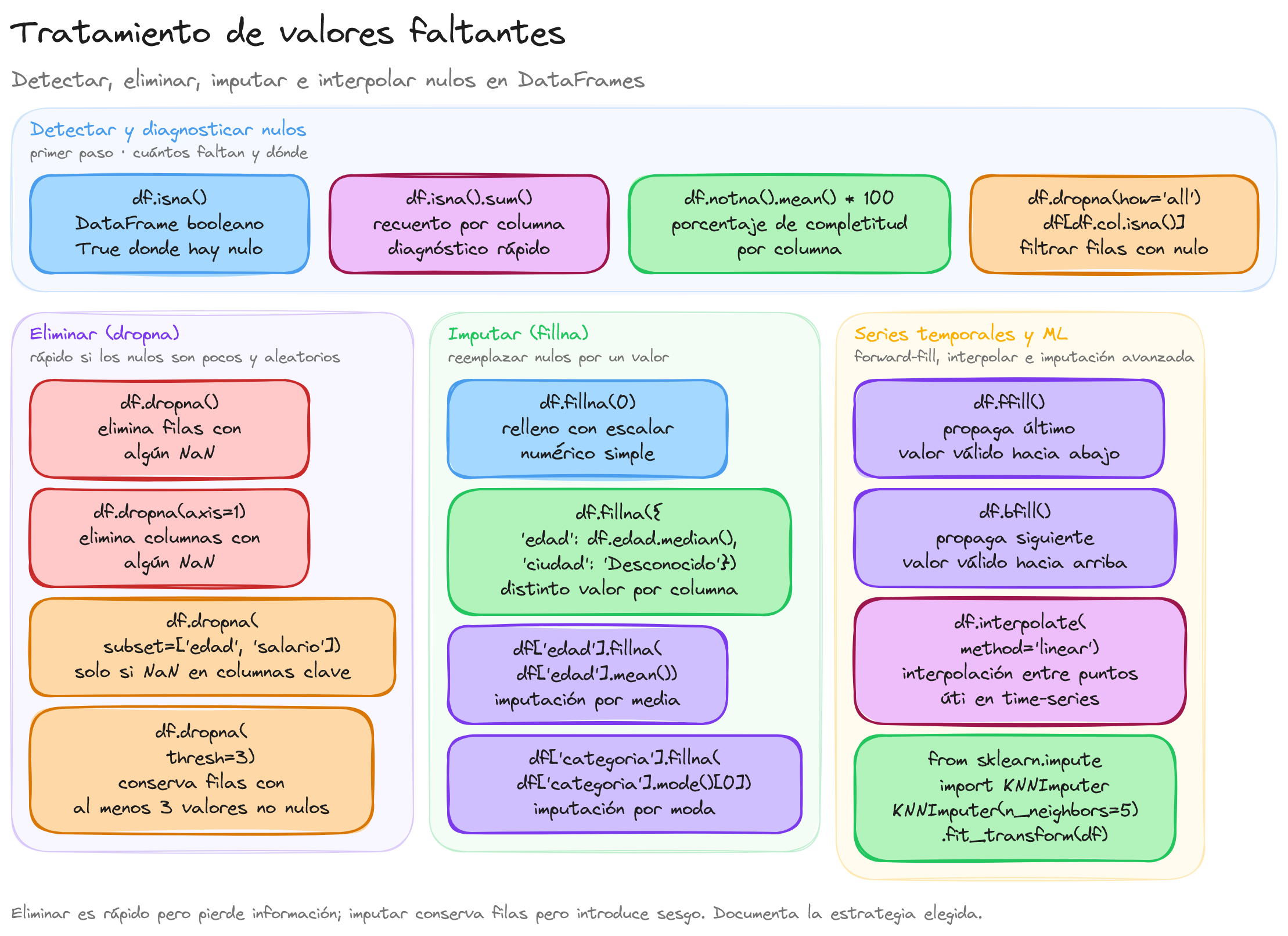
¿Por qué se deben tratar los valores faltantes?
Los valores faltantes en un conjunto de datos pueden tener un impacto significativo en el análisis y modelado de datos. Ignorar estos valores puede llevar a resultados engañosos y a modelos de predicción poco precisos.
A continuación se detallan algunas razones clave por las que es crucial tratar los valores faltantes:
graph TB
NAN[Valores NaN detectados] --> EST{Estrategia}
EST -->|Eliminar| DROP["dropna axis=0/1<br/>thresh=N filas mínimas"]
EST -->|Imputar simple| IMP1["fillna media/mediana/moda"]
EST -->|Interpolar series temporales| INT["interpolate linear/spline/time"]
EST -->|Forward/backward| FFB["ffill / bfill"]
EST -->|ML| KNN["KNNImputer / IterativeImputer"]
EST -->|Marcar| MRK["Categoría Desconocido<br/>o flag binario"]
DROP --> CLN[DataFrame limpio]
IMP1 --> CLN
INT --> CLN
KNN --> CLN
CLN --> ML2[Modelo Machine Learning]
- Impacto en las estadísticas descriptivas: La presencia de valores faltantes puede distorsionar las estadísticas descriptivas como la media, la mediana y la desviación estándar. Por ejemplo, al calcular la media de una columna con valores faltantes, pandas ignora estos valores, lo que puede llevar a una interpretación incorrecta de los datos.
import pandas as pd
import numpy as np
data = {'A': [1, 2, np.nan, 4, 5]}
df = pd.DataFrame(data)
print(df['A'].mean()) # Resultado: 3.0, ignora el valor faltante
- Problemas en el modelado predictivo: Muchos algoritmos de aprendizaje automático no pueden manejar valores faltantes de manera nativa y requieren que los datos estén completos. La falta de tratamiento de estos valores puede resultar en errores durante el entrenamiento del modelo.
from sklearn.linear_model import LinearRegression
import pandas as pd
import numpy as np
data = {'A': [1, 2, np.nan, 4, 5], 'B': [5, 4, 3, 2, 1]}
df = pd.DataFrame(data)
X = df[['A']]
y = df['B']
model = LinearRegression()
try:
model.fit(X, y)
except ValueError as e:
print(f"Error: {e}") # El algoritmo no puede manejar valores faltantes
- Bias en los resultados: La eliminación de filas con valores faltantes sin un análisis adecuado puede introducir sesgos en los resultados. Esto es especialmente crítico en estudios donde la muestra debe ser representativa de la población.
- Integridad de los datos: Los valores faltantes pueden ser indicativos de problemas en la recolección de datos o en el proceso de almacenamiento. Identificar y tratar estos valores puede ayudar a mejorar la calidad general del conjunto de datos.
- Análisis de correlación: Los valores faltantes pueden afectar las medidas de correlación entre variables. Al ignorar estos valores, las correlaciones calculadas pueden no reflejar con precisión las relaciones entre las variables.
data = {'A': [1, 2, np.nan, 4, 5], 'B': [5, 4, 3, 2, 1]}
df = pd.DataFrame(data)
print(df.corr(numeric_only=True)) # La correlación puede verse afectada por los valores faltantes
- Visualización de datos: Las visualizaciones pueden ser engañosas si no se tratan los valores faltantes. Gráficos como histogramas o diagramas de dispersión pueden no representar adecuadamente la distribución de los datos si hay valores faltantes.
import matplotlib.pyplot as plt
df['A'].plot(kind='hist')
plt.show() # El histograma puede no ser representativo si hay valores faltantes
En resumen, el tratamiento adecuado de los valores faltantes es esencial para asegurar la precisión y la integridad de los análisis de datos y para evitar problemas en el modelado predictivo.
Tratamiento de valores faltantes en columnas numéricas
El tratamiento de valores faltantes en columnas numéricas es una tarea esencial en la limpieza y preparación de datos, ya que estos valores pueden afectar significativamente los análisis estadísticos y los modelos predictivos. A continuación, se describen algunas técnicas avanzadas y recomendadas para tratar valores faltantes en columnas numéricas utilizando pandas.
Identificación de valores faltantes
Antes de tratar los valores faltantes, es fundamental identificarlos. Pandas proporciona métodos como .isna() y .isnull() para este propósito.
import pandas as pd
import numpy as np
data = {'A': [1, 2, np.nan, 4, 5]}
df = pd.DataFrame(data)
print(df['A'].isna()) # Identifica valores faltantes en la columna 'A'
Eliminación de valores faltantes
Una técnica común pero arriesgada es eliminar las filas o columnas que contienen valores faltantes. Esta técnica puede introducir sesgos si no se usa con cautela.
# Elimina filas con valores faltantes
df_dropped = df.dropna(subset=['A'])
print(df_dropped)
# Elimina columnas con valores faltantes
df_dropped_col = df.dropna(axis=1)
print(df_dropped_col)
Imputación de valores faltantes
La imputación es una técnica más sofisticada que consiste en reemplazar los valores faltantes con otros valores. A continuación, se presentan algunas estrategias de imputación:
1.- Media, mediana y moda
Reemplazar los valores faltantes con la media, mediana o moda es una estrategia común y fácil de implementar.
# Imputación con la media
mean_value = df['A'].mean()
df['A'] = df['A'].fillna(mean_value)
# Imputación con la mediana
median_value = df['A'].median()
df['A'] = df['A'].fillna(median_value)
# Imputación con la moda (más común)
mode_value = df['A'].mode()[0]
df['A'] = df['A'].fillna(mode_value)
2.- Imputación con interpolación
La interpolación es una técnica que utiliza los valores circundantes para estimar los valores faltantes. Pandas proporciona el método .interpolate() para este propósito.
df['A'] = df['A'].interpolate(method='linear')
print(df)
3.- Imputación mediante algoritmos de aprendizaje automático
Para imputaciones más avanzadas, se pueden utilizar algoritmos de aprendizaje automático. Por ejemplo, el uso de KNNImputer de la biblioteca scikit-learn.
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=2)
df[['A']] = imputer.fit_transform(df[['A']])
print(df)
Detección de valores atípicos
Es importante detectar y tratar valores atípicos antes de imputar los valores faltantes, ya que los outliers pueden distorsionar la imputación.
import seaborn as sns
sns.boxplot(x=df['A'])
Uso de técnicas avanzadas de imputación
Además de las técnicas mencionadas, existen métodos avanzados como la imputación múltiple, que generan varias imputaciones para un valor faltante y luego combinan los resultados para obtener una estimación más robusta.
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
iter_imputer = IterativeImputer()
df[['A']] = iter_imputer.fit_transform(df[['A']])
print(df)
Estas técnicas permiten manejar los valores faltantes en columnas numéricas de manera efectiva, mejorando la calidad de los datos y la fiabilidad de los análisis y modelos predictivos.
Tratamiento de valores faltantes en columnas categóricas o texto
El tratamiento de valores faltantes en columnas categóricas o de texto es crucial para asegurar la calidad de los datos y la precisión de los modelos predictivos. A continuación, se detallan técnicas avanzadas y recomendadas para abordar estos valores faltantes utilizando pandas.
La identificación de valores faltantes en columnas categóricas o de texto se realiza de manera similar a las columnas numéricas.
import pandas as pd
import numpy as np
data = {'Category': ['A', 'B', np.nan, 'A', 'C']}
df = pd.DataFrame(data)
print(df['Category'].isna()) # Identifica valores faltantes en la columna 'Category'
Eliminación de valores faltantes
Eliminar filas o columnas con valores faltantes es una opción, aunque puede no ser ideal si resulta en la pérdida de datos significativos.
# Elimina filas con valores faltantes
df_dropped = df.dropna(subset=['Category'])
print(df_dropped)
# Elimina columnas con valores faltantes
df_dropped_col = df.dropna(axis=1)
print(df_dropped_col)
Imputación de valores faltantes
1.- Sustitución por una categoría específica
Una técnica básica pero efectiva es reemplazar los valores faltantes con una categoría específica, como "Desconocido" o "N/A".
df['Category'] = df['Category'].fillna('Desconocido')
print(df)
2.- Imputación con la moda
Reemplazar los valores faltantes con la categoría más frecuente (moda) es una estrategia común.
mode_value = df['Category'].mode()[0]
df['Category'] = df['Category'].fillna(mode_value)
print(df)
3.- Imputación basada en otras características
Más avanzado, se pueden usar técnicas de modelado para predecir los valores faltantes basándose en otras características del conjunto de datos. Por ejemplo, utilizando SimpleImputer de scikit-learn para imputación basada en frecuencia.
import pandas as pd
import numpy as np
from sklearn.impute import SimpleImputer
# Crear un DataFrame de ejemplo
data = {'Category': ['A', 'B', np.nan, 'A', 'C']}
df = pd.DataFrame(data)
# Crear el imputador
imputer = SimpleImputer(strategy='most_frequent')
# Imputar los valores faltantes y asignar el resultado a la columna
df['Category'] = imputer.fit_transform(df[['Category']]).ravel()
print(df)
Codificación de valores faltantes
Codificar explícitamente los valores faltantes puede ser útil, especialmente si se sospecha que la ausencia de datos tiene un significado.
df['Category_missing'] = df['Category'].isna().astype(int)
print(df)
Imputación múltiple
La imputación múltiple crea varias imputaciones posibles para los valores faltantes y combina los resultados para obtener una estimación más precisa.
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
iter_imputer = IterativeImputer(max_iter=10, random_state=0)
df['Category'] = iter_imputer.fit_transform(df[['Category']].apply(lambda x: pd.factorize(x)[0]).astype(float))
df['Category'] = pd.Categorical.from_codes(df['Category'].astype(int), df['Category'].astype('category').cat.categories)
print(df)
Estas técnicas proporcionan un enfoque robusto para tratar los valores faltantes en columnas categóricas o de texto, asegurando la integridad de los datos y la fiabilidad de los análisis y modelos predictivos.
Tratamiento de valores faltantes en columnas fecha
El tratamiento de valores faltantes en columnas de tipo fecha es un aspecto crucial en la limpieza y preparación de datos, especialmente cuando se trabaja con series temporales o datos que dependen del tiempo. Pandas ofrece diversas herramientas y técnicas para manejar estos valores faltantes de manera efectiva.
La identificación de valores faltantes en columnas de fecha se puede realizar de manera similar a otros tipos de datos utilizando métodos como .isna() o .isnull().
import pandas as pd
import numpy as np
data = {'Fecha': ['2023-01-01', '2023-01-02', np.nan, '2023-01-04', '2023-01-05']}
df = pd.DataFrame(data)
# Convertir la columna 'Fecha' a tipo datetime
df['Fecha'] = pd.to_datetime(df['Fecha'])
print(df['Fecha'].isna()) # Identifica valores faltantes en la columna 'Fecha'
Eliminar filas o columnas con valores faltantes es una opción, aunque puede no ser ideal si resulta en la pérdida de datos significativos.
# Elimina filas con valores faltantes
df_dropped = df.dropna(subset=['Fecha'])
print(df_dropped)
# Elimina columnas con valores faltantes
df_dropped_col = df.dropna(axis=1)
print(df_dropped_col)
La imputación de valores faltantes en columnas de fecha puede realizarse utilizando varias técnicas, dependiendo del contexto y la naturaleza de los datos.
1.- Imputación con una fecha fija
Una técnica básica es reemplazar los valores faltantes con una fecha específica, como una fecha de referencia o una fecha inicial del conjunto de datos.
fixed_date = pd.Timestamp('2023-01-01')
df['Fecha'] = df['Fecha'].fillna(fixed_date)
print(df)
2.- Imputación hacia adelante y hacia atrás
Las técnicas de imputación hacia adelante (.ffill()) y hacia atrás (.bfill()) son útiles para mantener la continuidad temporal en los datos. Estos métodos directos sustituyen a la forma antigua fillna(method='ffill') que está obsoleta.
# Imputación hacia adelante
df['Fecha'] = df['Fecha'].ffill()
# Imputación hacia atrás
df['Fecha'] = df['Fecha'].bfill()
3.- Imputación con la media o la mediana de intervalos de tiempo
Para ciertos análisis, puede ser útil imputar los valores faltantes con la media o la mediana de los intervalos de tiempo. Esto se puede lograr calculando la diferencia de tiempo y luego usando estas estadísticas.
# Calcular la diferencia de tiempo
time_diff = df['Fecha'].diff().mean()
# Imputar con la media de los intervalos de tiempo
df['Fecha'] = df['Fecha'].fillna(df['Fecha'].shift() + time_diff)
print(df)
Estas técnicas permiten manejar los valores faltantes en columnas de fecha de manera efectiva, mejorando la calidad de los datos y la fiabilidad de los análisis y modelos predictivos que dependen de la integridad temporal.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Pandas es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Pandas
Explora más contenido relacionado con Pandas y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Identificar valores faltantes en un DataFrame de Pandas.
- Eliminar filas o columnas con valores faltantes de manera segura.
- Imputar valores faltantes usando técnicas como media, mediana, moda e interpolación.
- Aplicar técnicas avanzadas de imputación como KNN y métodos de aprendizaje automático.
- Tratar valores faltantes en columnas categóricas o de texto.
- Codificar explícitamente los valores faltantes.
- Manejar valores faltantes en columnas de fechas.
- Usar imputación múltiple para obtener estimaciones más precisas.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje