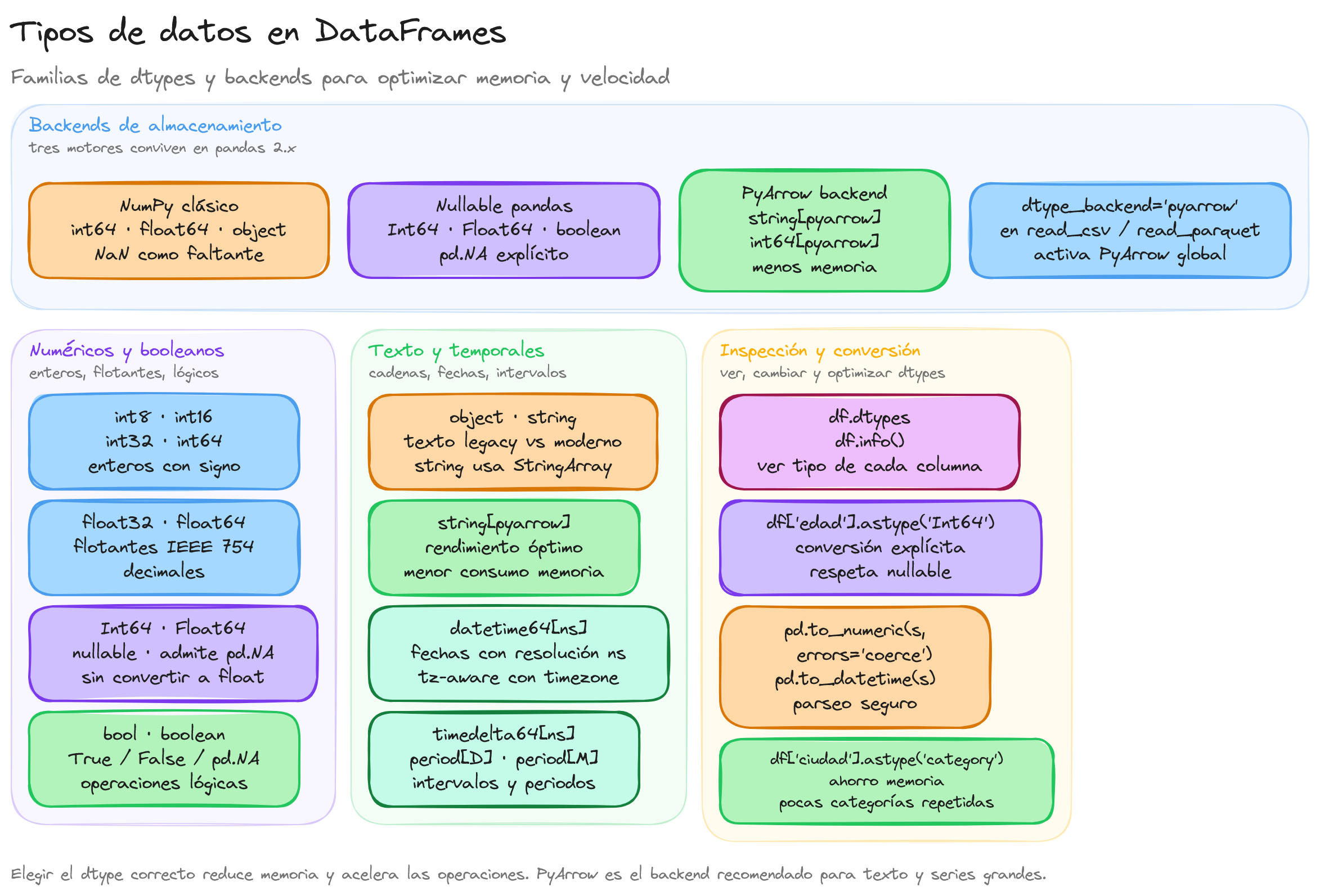
¿Qué son los tipos de datos en Pandas y por qué son importantes?
En Pandas, los tipos de datos (o dtypes) son fundamentales para el manejo eficaz y eficiente de los datos en DataFrames. Cada columna en un DataFrame tiene un tipo de dato asociado, lo que determina cómo se almacenan y procesan los datos en esa columna.
Los tipos de datos en Pandas están basados en los tipos de datos de NumPy, lo que permite que Pandas herede su eficiencia y velocidad en las operaciones numéricas y de manipulación de datos.
graph TB
DT["dtypes pandas 2.2+"] --> NUM[Numéricos]
DT --> TXT[Texto]
DT --> TMP[Temporales]
DT --> BOOL[Booleanos]
DT --> CAT[category]
NUM --> I64["int64 / Int64 nullable"]
NUM --> F64["float64 / Float64"]
NUM --> ARR[int64 backed by Arrow]
TXT --> OBJ[object - str legacy]
TXT --> STR[string PyArrow]
TMP --> DT64[datetime64 ns con timezone]
TMP --> TD64[timedelta64 ns]
CAT -->|Reduce memoria| DF[DataFrame]
Los tipos de datos son importantes por varias razones:
- Eficiencia en el almacenamiento: Diferentes tipos de datos ocupan diferentes cantidades de memoria. Por ejemplo, los enteros (
int64) ocupan menos espacio que los números de punto flotante (float64). Al especificar correctamente los tipos de datos, se puede optimizar el uso de la memoria. - Velocidad de las operaciones: Las operaciones aritméticas y de comparación son más rápidas cuando se realizan en tipos de datos homogéneos y bien definidos. Por ejemplo, las operaciones con enteros son generalmente más rápidas que con flotantes.
- Integridad de los datos: Definir correctamente los tipos de datos ayuda a mantener la integridad de los datos. Por ejemplo, una columna que almacena fechas debe ser del tipo
datetime64para asegurar que todas las entradas son válidas fechas y permitir operaciones específicas de fechas. - Compatibilidad con otras herramientas: Muchas herramientas y librerías de análisis de datos esperan que los datos estén en tipos específicos. Definir correctamente los tipos de datos facilita la interoperabilidad con estas herramientas.
Para ver los tipos de datos de un DataFrame, se puede utilizar el atributo .dtypes:
import pandas as pd
# Crear un DataFrame de ejemplo
data = {
'columna_entero': [1, 2, 3],
'columna_flotante': [1.1, 2.2, 3.3],
'columna_texto': ['a', 'b', 'c'],
'columna_fecha': pd.to_datetime(['2023-01-01', '2023-01-02', '2023-01-03'])
}
df = pd.DataFrame(data)
# Ver los tipos de datos
print(df.dtypes)
El resultado sería:
columna_entero int64
columna_flotante float64
columna_texto object
columna_fecha datetime64[ns]
dtype: object
Es crucial entender que Pandas utiliza el tipo object para almacenar datos de texto, pero esto puede ser ineficiente en términos de memoria y velocidad. A partir de versiones recientes, se recomienda usar el tipo string para cadenas de texto, lo que proporciona una mejor optimización y coherencia.
# Convertir una columna de texto a tipo string
df['columna_texto'] = df['columna_texto'].astype('string')
# Ver los tipos de datos actualizados
print(df.dtypes)
El resultado sería:
columna_entero int64
columna_flotante float64
columna_texto string
columna_fecha datetime64[ns]
dtype: object
La correcta gestión y comprensión de los tipos de datos en Pandas es fundamental para realizar análisis de datos eficientes y precisos, asegurando que los DataFrames no solo sean correctos en términos de contenido, sino también optimizados en términos de rendimiento.
¿Qué tipos de datos existen en Pandas?
En Pandas, los tipos de datos son fundamentales para definir cómo se almacenan y manipulan los datos en un DataFrame. A continuación, se describen los principales tipos de datos que se pueden encontrar en Pandas:
- int64: Representa números enteros de 64 bits. Es el tipo de datos por defecto para columnas que contienen valores enteros.
import pandas as pd
df = pd.DataFrame({'enteros': [1, 2, 3]})
print(df.dtypes) # enteros int64
- float64: Representa números de punto flotante de 64 bits. Este tipo es utilizado para columnas que contienen valores decimales.
df = pd.DataFrame({'flotantes': [1.1, 2.2, 3.3]})
print(df.dtypes) # flotantes float64
- bool: Utilizado para valores booleanos (
TrueoFalse).
df = pd.DataFrame({'booleanos': [True, False, True]})
print(df.dtypes) # booleanos bool
- datetime64[ns]: Representa marcas de tiempo con precisión de nanosegundos. Es el tipo adecuado para datos de fecha y hora.
df = pd.DataFrame({'fechas': pd.to_datetime(['2023-01-01', '2023-01-02', '2023-01-03'])})
print(df.dtypes) # fechas datetime64[ns]
- timedelta64[ns]: Utilizado para representar diferencias de tiempo con precisión de nanosegundos.
df = pd.DataFrame({'deltas': pd.to_timedelta(['1 days', '2 days', '3 days'])})
print(df.dtypes) # deltas timedelta64[ns]
- category: Este tipo de dato es útil para columnas que contienen un número limitado de categorías únicas. Permite una compresión eficiente y mejora el rendimiento en ciertas operaciones.
df = pd.DataFrame({'categorias': pd.Categorical(['a', 'b', 'a'])})
print(df.dtypes) # categorias category
- string: A partir de versiones recientes de Pandas, se recomienda utilizar el tipo
stringen lugar deobjectpara almacenar datos de texto. Este tipo es más eficiente y coherente.
df = pd.DataFrame({'texto': ['a', 'b', 'c']}, dtype='string')
print(df.dtypes) # texto string
- object: Tradicionalmente utilizado para datos de texto, aunque también puede almacenar cualquier tipo de objeto de Python. Sin embargo, su uso puede ser menos eficiente comparado con
stringpara cadenas de texto.
df = pd.DataFrame({'objetos': ['a', 'b', 'c']})
print(df.dtypes) # objetos object
Pandas también soporta otros tipos de datos menos comunes, como interval, period, Sparse (para datos esparcidos), entre otros. La elección del tipo de dato adecuado para cada columna es esencial para asegurar un manejo eficiente y preciso de los datos en un DataFrame.
Cambiar el tipo de dato
En Pandas, cambiar el tipo de dato de una columna en un DataFrame es una operación común y necesaria para asegurar que los datos se manejen de manera eficiente y precisa. La función principal para realizar esta tarea es astype(), que permite convertir una columna a un tipo de dato específico.
Para cambiar el tipo de dato de una columna, se puede utilizar el método astype() de la siguiente manera:
import pandas as pd
# Crear un DataFrame de ejemplo
data = {
'columna_entero': [1, 2, 3],
'columna_flotante': [1.1, 2.2, 3.3],
'columna_texto': ['a', 'b', 'c']
}
df = pd.DataFrame(data)
# Convertir la columna 'columna_entero' a tipo float
df['columna_entero'] = df['columna_entero'].astype('float64')
print(df.dtypes)
El resultado sería:
columna_entero float64
columna_flotante float64
columna_texto object
dtype: object
Pandas también permite convertir múltiples columnas a diferentes tipos de datos utilizando un diccionario con el método astype():
# Convertir múltiples columnas a diferentes tipos
df = df.astype({'columna_entero': 'float64', 'columna_texto': 'string'})
print(df.dtypes)
El resultado sería:
columna_entero float64
columna_flotante float64
columna_texto string
dtype: object
En algunos casos, puede ser necesario convertir una columna a un tipo de dato que no sea compatible con todos los valores actuales. El parámetro errors='ignore' en astype() esta obsoleto. En su lugar, se recomienda usar funciones específicas como pd.to_numeric() con el parámetro errors='coerce', que convierte los valores no válidos a pd.NA.
# Convertir valores a numerico, reemplazando errores con pd.NA
df['columna_texto'] = pd.to_numeric(df['columna_texto'], errors='coerce')
print(df.dtypes)
El resultado sería:
columna_entero float64
columna_flotante float64
columna_texto float64
dtype: object
También se puede usar un bloque try/except para manejar errores de conversión con astype():
try:
df['columna'] = df['columna'].astype('int64')
except (ValueError, TypeError):
print("No se pudo convertir la columna a int64")
Para convertir una columna de tipo datetime, Pandas proporciona la función pd.to_datetime(), que es más robusta que astype() para este tipo de conversión.
# Crear un DataFrame de ejemplo
data = {
'columna_fecha': ['2023-01-01', '2023-01-02', '2023-01-03']
}
df = pd.DataFrame(data)
# Convertir la columna 'columna_fecha' a tipo datetime
df['columna_fecha'] = pd.to_datetime(df['columna_fecha'])
print(df.dtypes)
El resultado sería:
columna_fecha datetime64[ns]
dtype: object
Para convertir una columna a tipo category, se puede usar el método astype() o la función pd.Categorical():
# Crear un DataFrame de ejemplo
data = {
'columna_texto': ['a', 'b', 'a']
}
df = pd.DataFrame(data)
# Convertir la columna 'columna_texto' a tipo category
df['columna_texto'] = df['columna_texto'].astype('category')
print(df.dtypes)
El resultado sería:
columna_texto category
dtype: object
Cambiar el tipo de dato de las columnas de un DataFrame puede mejorar significativamente la eficiencia del almacenamiento y la velocidad de las operaciones. Es una práctica recomendada revisar y ajustar los tipos de datos después de cargar y limpiar un conjunto de datos para asegurar un rendimiento óptimo.
Optimización y rendimiento
El rendimiento es un aspecto crucial cuando se trabaja con grandes volúmenes de datos en Pandas. Optimizar el uso de los tipos de datos puede llevar a mejoras significativas en términos de velocidad y uso de memoria. A continuación, se presentan algunas estrategias y técnicas avanzadas para optimizar el rendimiento de los DataFrames en Pandas.
Uso de tipos de datos adecuados
La elección del tipo de dato adecuado puede reducir el uso de memoria y acelerar las operaciones. Utilizar tipos de datos más específicos y ligeros es una de las formas más efectivas de optimización. Por ejemplo:
int8,int16,int32yint64: Para columnas de enteros, el uso de tipos de enteros más pequeños (int8,int16,int32) puede reducir significativamente el uso de memoria.float32en lugar defloat64: Para columnas de números decimales, si la precisión no es crítica,float32puede ser una opción más eficiente quefloat64.- Categorías: Convertir columnas con un número limitado de valores únicos a tipo
categorypuede ahorrar memoria y mejorar el rendimiento en operaciones de filtrado y agrupamiento.
import pandas as pd
# Crear un DataFrame de ejemplo
data = {
'id': [1, 2, 3, 4],
'age': [25, 30, 35, 40],
'salary': [50000.0, 60000.0, 70000.0, 80000.0],
'department': ['HR', 'Engineering', 'Marketing', 'HR']
}
df = pd.DataFrame(data)
# Optimizar tipos de datos
df['id'] = df['id'].astype('int8')
df['age'] = df['age'].astype('int8')
df['salary'] = df['salary'].astype('float32')
df['department'] = df['department'].astype('category')
print(df.dtypes)
Reducción de uso de memoria
El método memory_usage() permite analizar el uso de memoria de un DataFrame. Para reducir el uso de memoria, se pueden convertir las columnas a tipos de datos más eficientes.
# Ver el uso de memoria antes de la optimización
print(df.memory_usage(deep=True))
# Optimizar tipos de datos
df['id'] = df['id'].astype('int8')
df['age'] = df['age'].astype('int8')
df['salary'] = df['salary'].astype('float32')
df['department'] = df['department'].astype('category')
# Ver el uso de memoria después de la optimización
print(df.memory_usage(deep=True))
Vectorización de operaciones
La vectorización consiste en aplicar operaciones a arrays enteros en lugar de iterar fila por fila. Esto aprovecha las optimizaciones internas de NumPy y Pandas, resultando en un rendimiento significativamente mejorado. Evita el uso de bucles for y utiliza funciones vectorizadas siempre que sea posible.
import numpy as np
import pandas as pd
# Crear un generador aleatorio con una semilla para reproducibilidad
rng = np.random.default_rng(seed=42)
# Crear un DataFrame grande de ejemplo
n = 1000000
df = pd.DataFrame({
'a': rng.random(n),
'b': rng.random(n)
})
# Operación vectorizada: suma de las columnas 'a' y 'b'
df['c'] = df['a'] + df['b']
# Evitar bucles for:
# for i in range(n):
# df.loc[i, 'c'] = df.loc[i, 'a'] + df.loc[i, 'b']
Uso de métodos eficientes para operaciones comunes
Algunas operaciones comunes tienen métodos específicos en Pandas que están optimizados para el rendimiento. Por ejemplo, el método pd.concat() es más eficiente que utilizar bucles para concatenar DataFrames.
import numpy as np
import pandas as pd
# Crear un generador aleatorio con una semilla para reproducibilidad
rng = np.random.default_rng(seed=42)
# Crear múltiples DataFrames pequeños usando el nuevo generador aleatorio
dfs = [pd.DataFrame(rng.standard_normal((100, 4))) for _ in range(10)]
# Concatenar DataFrames de manera eficiente
df_concatenated = pd.concat(dfs, ignore_index=True)
Evitar copias innecesarias de DataFrames
Las operaciones que modifican DataFrames pueden crear copias innecesarias, lo que consume más memoria y tiempo. Para evitar esto, es recomendable reasignar el DataFrame después de realizar la operación en lugar de modificarlo directamente. Esta práctica mantiene el código más claro y eficiente.
import numpy as np
import pandas as pd
# Crear un generador aleatorio con una semilla para reproducibilidad
rng = np.random.default_rng(seed=42)
# Crear un DataFrame de ejemplo utilizando el nuevo generador aleatorio
df = pd.DataFrame(rng.standard_normal((1000, 4)), columns=list('ABCD'))
# Eliminar columnas reasignando el DataFrame
df = df.drop(columns=['B', 'C'])
Uso de eval() y query()
Pandas proporciona las funciones eval() y query() para realizar operaciones y consultas que son más rápidas y eficientes que las operaciones estándar, especialmente para grandes DataFrames.
import numpy as np
import pandas as pd
# Crear un generador aleatorio con una semilla para reproducibilidad
rng = np.random.default_rng(seed=42)
# Crear un DataFrame de ejemplo utilizando el nuevo generador aleatorio
df = pd.DataFrame({
'A': rng.standard_normal(1000000),
'B': rng.standard_normal(1000000),
'C': rng.standard_normal(1000000)
})
# Utilizar eval para una operación aritmética
df['D'] = pd.eval('df.A + df.B - df.C')
# Utilizar query para filtrar datos
filtered_df = df.query('A > 0 and B < 0')
Implementar estas técnicas de optimización y rendimiento en Pandas puede resultar en un manejo más eficiente de los datos, mejorando tanto la velocidad de procesamiento como el uso de memoria.
Tipos de datos con PyArrow
Pandas permite utilizar tipos de datos respaldados por PyArrow, que ofrecen mejor rendimiento y menor consumo de memoria. El tipo pd.ArrowDtype permite acceder a cualquier tipo de dato de PyArrow.
import pandas as pd
# Crear un DataFrame con tipos PyArrow
df = pd.DataFrame({
'nombre': pd.array(['Ana', 'Luis', 'Marta'], dtype='string[pyarrow]'),
'edad': pd.array([23, 35, 29], dtype='int64[pyarrow]')
})
print(df.dtypes)
El resultado sería:
nombre string[pyarrow]
edad int64[pyarrow]
dtype: object
Al leer archivos, se puede especificar el parámetro dtype_backend="pyarrow" para que todas las columnas utilicen tipos PyArrow automáticamente:
# Leer un CSV con backend PyArrow
df = pd.read_csv('archivo.csv', dtype_backend='pyarrow')
# Leer un archivo Parquet con backend PyArrow
df = pd.read_parquet('archivo.parquet', dtype_backend='pyarrow')
Valor nulo pd.NA
Pandas proporciona pd.NA como escalar de valor nulo para los tipos nullable. A diferencia de float('nan'), pd.NA funciona de forma consistente con tipos enteros, booleanos y cadenas de texto nullable.
import pandas as pd
# Crear una Serie con tipo nullable y pd.NA
serie = pd.array([1, 2, pd.NA, 4], dtype='Int64')
print(serie)
# pd.NA se propaga en operaciones
print(pd.NA + 1) # <NA>
print(pd.isna(pd.NA)) # True
Implementar estas técnicas en Pandas puede resultar en un manejo más eficiente de los datos, mejorando tanto la velocidad de procesamiento como el uso de memoria.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Pandas es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Pandas
Explora más contenido relacionado con Pandas y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Comprender ¿Qué son los tipos de datos en Pandas y por qué son importantes?
- Aplicar ¿Qué tipos de datos existen en Pandas?
- Identificar cambiar el tipo de dato
- Implementar optimización y rendimiento
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje