Fusionar DataFrames
La fusión de DataFrames en pandas se realiza principalmente mediante la función merge(), que permite combinar dos DataFrames en uno solo, basándose en una o más claves. Esta operación es esencial para la manipulación avanzada de datos y se asemeja a las uniones (joins) en SQL.
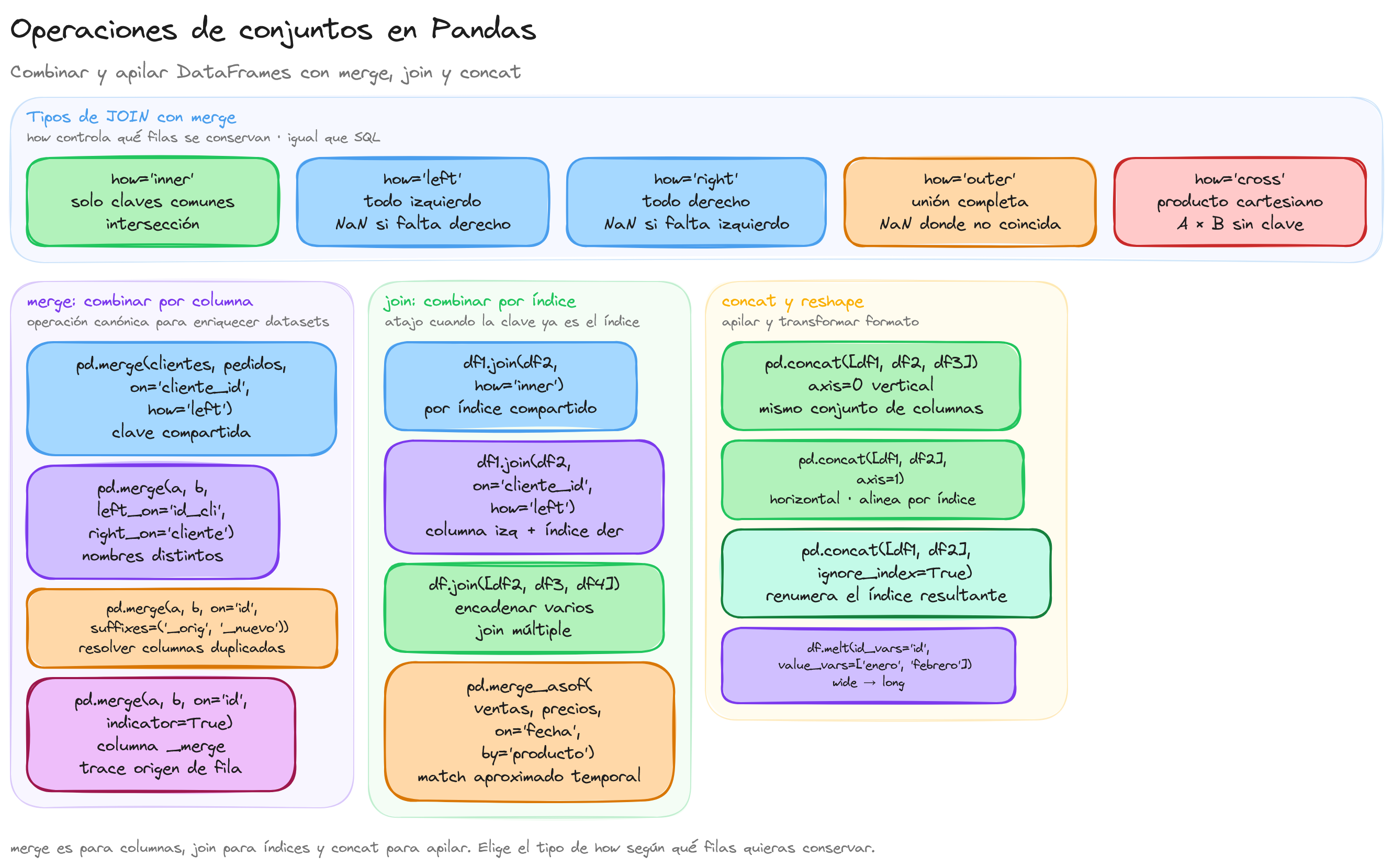
El siguiente diagrama resume los tipos de join disponibles en merge() mediante el parámetro how: inner conserva las claves presentes en ambos DataFrames, left y right preservan todo el DataFrame indicado rellenando con NaN lo que falte del otro, outer devuelve la unión completa y cross genera el producto cartesiano.
flowchart TB
A["DataFrame A<br>claves: 1, 2, 3"] --> M{"merge how=..."}
B["DataFrame B<br>claves: 2, 3, 4"] --> M
M -->|inner| R1["Solo coincidencias<br>2, 3"]
M -->|left| R2["Todo A + match B<br>1 NaN, 2, 3"]
M -->|right| R3["Todo B + match A<br>2, 3, 4 NaN"]
M -->|outer| R4["Unión completa<br>1, 2, 3, 4 con NaN"]
M -->|cross| R5["Producto cartesiano<br>A x B"]
Sintaxis básica de merge()
La función merge() tiene la siguiente sintaxis básica:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), indicator=False, validate=None)
Parámetros principales
leftyright: Los DataFrames que se van a fusionar.how: El tipo de unión a realizar. Los valores posibles son:
'left': Realiza una unión por la izquierda (left join).'right': Realiza una unión por la derecha (right join).'outer': Realiza una unión externa completa (full outer join).'inner': Realiza una unión interna (inner join). Es el valor por defecto.
on: Nombre de la(s) columna(s) común(es) a ambas tablas para realizar la fusión. Si no se específica, se busca una intersección de las columnas de ambas tablas.left_onyright_on: Nombres de las columnas en los DataFrames izquierdo y derecho para realizar la fusión, si son diferentes.left_indexyright_index: Si se establece enTrue, se utilizan los índices de los DataFrames izquierdo y derecho para realizar la fusión.suffixes: Tuplas de sufijos que se añadirán a las columnas superpuestas en el DataFrame resultante.
Con la activación de Copy-on-Write en Pandas, las copias de datos se gestionan de forma automática e internamente. Por tanto, el parámetro copy que existia en funciones como merge(), concat() y reindex() ya no es necesario y se ha eliminado de las versiones recientes.
Ejemplos de uso
Unión interna (inner join)
La unión interna devuelve solo las filas que tienen claves coincidentes en ambos DataFrames. Esto significa que únicamente se conservan los registros que están presentes en ambos conjuntos de datos. Este tipo de unión es útil cuando necesitas encontrar intersecciones o coincidencias exactas entre dos conjuntos de datos.
import pandas as pd
df1 = pd.DataFrame({
'key': ['A', 'B', 'C'],
'value1': [1, 2, 3]
})
df2 = pd.DataFrame({
'key': ['B', 'C', 'D'],
'value2': [4, 5, 6]
})
result = pd.merge(df1, df2, on='key', how='inner')
print(result)
Resultado:
key value1 value2
0 B 2 4
1 C 3 5
Unión externa completa (full outer join)
La unión externa completa devuelve todas las filas cuando hay una coincidencia en una de las tablas. Si no hay coincidencias en ambos DataFrames, las entradas faltantes se llenan con NaN. Este tipo de unión es útil para mantener todos los registros de ambos conjuntos de datos, combinando los datos donde hay coincidencias y llenando con valores nulos donde no las hay.
result = pd.merge(df1, df2, on='key', how='outer')
print(result)
Resultado:
key value1 value2
0 A 1.0 NaN
1 B 2.0 4.0
2 C 3.0 5.0
3 D NaN 6.0
Unión por la izquierda (left join)
La unión por la izquierda devuelve todas las filas del DataFrame izquierdo y las filas coincidentes del DataFrame derecho. Si no hay coincidencias, los valores del DataFrame derecho se rellenan con NaN. Este tipo de unión es útil cuando se quiere conservar todos los registros de un DataFrame específico y solo agregar información adicional desde otro DataFrame donde haya coincidencias.
result = pd.merge(df1, df2, on='key', how='left')
print(result)
Resultado:
key value1 value2
0 A 1 NaN
1 B 2 4.0
2 C 3 5.0
Unión por la derecha (right join)
La unión por la derecha es similar a la unión por la izquierda, pero se enfoca en mantener todas las filas del DataFrame derecho y agregar filas coincidentes del DataFrame izquierdo. Los valores del DataFrame izquierdo que no tienen coincidencias en el derecho se rellenan con NaN. Esta operación es útil cuando el DataFrame derecho es el conjunto de datos principal y quieres complementar su información con datos del DataFrame izquierdo.
result = pd.merge(df1, df2, on='key', how='right')
print(result)
Resultado:
key value1 value2
0 B 2.0 4
1 C 3.0 5
2 D NaN 6
Fusión usando índices
Además de usar columnas para realizar un merge, Pandas permite fusionar DataFrames utilizando sus índices. Esta funcionalidad es útil cuando las relaciones entre los DataFrames están basadas en las posiciones o en etiquetas de los índices, en lugar de una columna específica.
import pandas as pd
df1 = pd.DataFrame({
'value1': [1, 2, 3]
}, index=['A', 'B', 'C'])
df2 = pd.DataFrame({
'value2': [4, 5, 6]
}, index=['B', 'C', 'D'])
result = pd.merge(df1, df2, left_index=True, right_index=True, how='inner')
print(result)
Resultado:
value1 value2
B 2 4
C 3 5
Indicador de fusión
El parámetro indicator agrega una columna adicional al DataFrame resultante que indica de qué DataFrame proviene cada fila. Esto es especialmente útil para depurar y entender mejor cómo se realizó la fusión, mostrando claramente las filas que coincidieron en ambos DataFrames y aquellas que no.
import pandas as pd
df1 = pd.DataFrame({
'key': ['A', 'B', 'C'],
'value1': [1, 2, 3]
})
df2 = pd.DataFrame({
'key': ['B', 'C', 'D'],
'value2': [4, 5, 6]
})
result = pd.merge(df1, df2, on='key', how='outer', indicator=True)
print(result)
Resultado:
key value1 value2 _merge
0 A 1.0 NaN left_only
1 B 2.0 4.0 both
2 C 3.0 5.0 both
3 D NaN 6.0 right_only
Validación de la fusión
El parámetro validate permite verificar si la fusión cumple con ciertas condiciones de relación entre los DataFrames, tales como "one_to_one" (una a una), "one_to_many" (una a muchas), "many_to_one" (muchas a una) y "many_to_many" (muchas a muchas). Esta opción es crucial para asegurar la integridad de los datos durante una fusión, especialmente en contextos donde la relación entre los datos debe seguir reglas estrictas.
result = pd.merge(df1, df2, on='key', how='inner', validate='one_to_one')
print(result)
Estos ejemplos muestran cómo utilizar la función merge() para fusionar DataFrames en pandas de manera eficiente y flexible, adaptándose a diferentes necesidades de análisis de datos.
Concatenar DataFrames
La concatenación de DataFrames en pandas se realiza mediante la función concat(). Esta función permite unir múltiples DataFrames a lo largo de un eje especificado (filas o columnas). La concatenación es útil cuando se desea combinar datos sin la necesidad de una clave común, a diferencia de la fusión.
Sintaxis básica de concat()
La función concat() tiene la siguiente sintaxis básica:
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False)
Parámetros principales
objs: Una lista o diccionario de objetos pandas (Series, DataFrame) a concatenar.axis: El eje a lo largo del cual concatenar.0para concatenar filas (por defecto),1para concatenar columnas.join: Método de unión de los ejes. Puede ser'inner'o'outer'.'outer'es el valor por defecto.ignore_index: Si se establece enTrue, los índices en el DataFrame resultante serán nuevos índices secuenciales.keys: Si se específica, se usará para crear un índice jerárquico en el DataFrame resultante.verify_integrity: Si se establece enTrue, verifica si hay duplicados en los índices y lanza una excepción si los hay.sort: Si se establece enTrue, ordena los ejes que no se están concatenando.
Ejemplos de uso
Concatenación de filas
La concatenación de filas une dos o más DataFrames apilando las filas de uno sobre el otro. Esto es útil cuando se desea combinar conjuntos de datos que comparten las mismas columnas pero contienen diferentes observaciones (filas). Por defecto, los índices originales se mantienen, lo que puede resultar en índices duplicados.
Concatenar filas de dos DataFrames:
import pandas as pd
df1 = pd.DataFrame({
'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']
})
df2 = pd.DataFrame({
'A': ['A3', 'A4', 'A5'],
'B': ['B3', 'B4', 'B5']
})
result = pd.concat([df1, df2], axis=0)
print(result)
Resultado:
A B
0 A0 B0
1 A1 B1
2 A2 B2
0 A3 B3
1 A4 B4
2 A5 B5
Concatenación de columnas
La concatenación de columnas combina DataFrames lado a lado (en columnas). Esto es útil cuando se tienen diferentes conjuntos de datos que comparten las mismas filas (índices) pero contienen diferentes atributos (columnas). Las columnas se alinean según el índice, y si no coinciden, se generan valores faltantes (NaN).
Concatenar columnas de dos DataFrames:
result = pd.concat([df1, df2], axis=1)
print(result)
Resultado:
A B A B
0 A0 B0 A3 B3
1 A1 B1 A4 B4
2 A2 B2 A5 B5
Concatenación con reindexación
Para evitar problemas de índices duplicados al concatenar filas, se puede usar el parámetro ignore_index=True. Esto reinicia los índices del DataFrame resultante, asegurando que los índices sean únicos y secuenciales. Es especialmente útil cuando los índices originales no tienen relevancia en el contexto de los datos combinados. Por ejemplo:
result = pd.concat([df1, df2], axis=0, ignore_index=True)
print(result)
Resultado:
A B
0 A0 B0
1 A1 B1
2 A2 B2
3 A3 B3
4 A4 B4
5 A5 B5
Concatenación con claves
Al concatenar DataFrames, el parámetro keys permite crear un índice jerárquico en el DataFrame resultante. Esto es útil cuando se desea conservar la identificación de la fuente original de los datos después de la concatenación, facilitando la referencia a los DataFrames originales dentro del DataFrame concatenado. Por ejemplo:
result = pd.concat([df1, df2], keys=['df1', 'df2'])
print(result)
Resultado:
A B
df1 0 A0 B0
1 A1 B1
2 A2 B2
df2 0 A3 B3
1 A4 B4
2 A5 B5
Concatenación con unión interna
La concatenación con unión interna (join='inner') permite combinar solo las columnas que son comunes a todos los DataFrames involucrados en la concatenación. Esto es útil cuando se quiere asegurar que solo se incluyan las columnas presentes en todos los DataFrames, evitando la creación de columnas con valores faltantes (NaN). Por ejemplo:
df3 = pd.DataFrame({
'A': ['A0', 'A1', 'A2'],
'C': ['C0', 'C1', 'C2']
})
result = pd.concat([df1, df3], axis=1, join='inner')
print(result)
Resultado:
A B A C
0 A0 B0 A0 C0
1 A1 B1 A1 C1
2 A2 B2 A2 C2
Verificación de integridad
El parámetro verify_integrity=True se utiliza para asegurar que la concatenación no resultará en un DataFrame con índices duplicados. Esto es útil en situaciones donde la unicidad de los índices es crítica para el análisis. Si se encuentran duplicados, se lanza un ValueError, permitiendo al usuario manejar el problema de manera controlada.
Para verificar la integridad de los índices y evitar duplicados:
try:
result = pd.concat([df1, df2], verify_integrity=True)
except ValueError as e:
print(f'Error: {e}')
Estos ejemplos muestran cómo utilizar la función concat() para concatenar DataFrames en pandas de manera eficiente y flexible, adaptándose a diferentes necesidades de análisis de datos.
Reindexado
El reindexado en pandas es una operación crucial que permite alinear un DataFrame con un nuevo índice, ya sea para añadir, eliminar o reordenar las etiquetas del índice. Esta funcionalidad es particularmente útil cuando se trabaja con conjuntos de datos que requieren una estructura de índice específica para el análisis o la manipulación de datos.
La función principal para realizar el reindexado es reindex(), que proporciona una interfaz flexible para ajustar los índices de los DataFrames.
Sintaxis básica de reindex()
La función reindex() tiene la siguiente sintaxis básica:
DataFrame.reindex(labels=None, index=None, columns=None, axis=None, method=None, level=None, fill_value=nan, limit=None, tolerance=None)
Parámetros principales
labels: Nueva lista de etiquetas del índice.index: Nueva lista de etiquetas para el índice de filas.columns: Nueva lista de etiquetas para el índice de columnas.axis: Eje a lo largo del cual se reindexa.0o'index'para filas y1o'columns'para columnas.method: Método de relleno para etiquetas faltantes. Opciones incluyen'ffill'(relleno hacia adelante) y'bfill'(relleno hacia atrás).level: Nivel (en el caso de índices jerárquicos) al que se aplica el reindexado.fill_value: Valor con el que se llenan las etiquetas faltantes en el nuevo índice.limit: Número máximo de elementos consecutivos a rellenar.tolerance: Tolerancia máxima de distancia para el método de relleno.
Ejemplos de uso
Reindexado básico
El reindexado básico permite reorganizar las filas de un DataFrame de acuerdo con un nuevo índice. Este proceso es útil cuando se necesita alinear datos con un nuevo esquema de índices, lo que puede resultar en la aparición de valores faltantes (NaN) si el nuevo índice incluye etiquetas que no estaban en el DataFrame original.
Reindexar un DataFrame con un nuevo índice:
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': ['foo', 'bar', 'baz'],
'B': [1, 2, 3]
})
new_index = [0, 2, 4]
df_reindexed = df.reindex(new_index)
print(df_reindexed)
Resultado:
A B
0 foo 1.0
2 baz 3.0
4 NaN NaN
Reindexado con relleno hacia adelante
Este tipo de reindexado utiliza el método de relleno hacia adelante (ffill) para llenar los valores faltantes generados por el reindexado. Es particularmente útil en series temporales o cuando se desea extender los últimos valores conocidos hacia adelante en el nuevo índice.
Utilizar ffill para llenar los valores faltantes:
df_reindexed_ffill = df.reindex(new_index, method='ffill')
print(df_reindexed_ffill)
Resultado:
A B
0 foo 1.0
2 baz 3.0
4 baz 3.0
Reindexado de columnas
Reindexar columnas permite reorganizar o seleccionar un subconjunto de columnas en un DataFrame. Esto es útil cuando se necesita ajustar la estructura de un DataFrame a un esquema de columnas específico, a menudo para asegurar la compatibilidad con otros DataFrames o para preparar los datos para el análisis.
Reindexar las columnas de un DataFrame:
df = pd.DataFrame({
'A': ['foo', 'bar', 'baz'],
'B': [1, 2, 3]
})
new_columns = ['B', 'C']
df_reindexed_columns = df.reindex(columns=new_columns)
print(df_reindexed_columns)
Resultado:
B C
0 1.0 NaN
1 2.0 NaN
2 3.0 NaN
Reindexado con índices jerárquicos
El reindexado de un DataFrame con un índice jerárquico (MultiIndex) permite extender o modificar estructuras de datos más complejas. Este tipo de reindexado es útil cuando se trabaja con datos multidimensionales que requieren una organización jerárquica, como series temporales con múltiples niveles de granularidad.
Reindexar un DataFrame con un índice jerárquico:
index = pd.MultiIndex.from_product([['A', 'B'], [1, 2]])
df = pd.DataFrame({
'data': [1, 2, 3, 4]
}, index=index)
new_index = pd.MultiIndex.from_product([['A', 'B', 'C'], [1, 2]])
df_reindexed_hierarchical = df.reindex(new_index)
print(df_reindexed_hierarchical)
Resultado:
data
A 1 1.0
2 2.0
B 1 3.0
2 4.0
C 1 NaN
2 NaN
Reindexado con valores de relleno
Cuando se reindexa un DataFrame y se encuentran etiquetas faltantes, se puede especificar un valor de relleno predeterminado para llenar esos espacios. Esto es útil cuando se desea evitar valores faltantes (NaN) y asegurar que el DataFrame resultante esté completamente poblado con datos válidos.
Especificar un valor de relleno para las etiquetas faltantes:
df_reindexed_fill_value = df.reindex(new_index, fill_value=0)
print(df_reindexed_fill_value)
Resultado:
data
A 1 1
2 2
B 1 3
2 4
C 1 0
2 0
El reindexado es una operación flexible y potente en pandas que permite ajustar los índices de un DataFrame según las necesidades del análisis de datos. Los ejemplos anteriores muestran cómo se puede utilizar la función reindex() para realizar diversas operaciones de reindexado, incluyendo el uso de métodos de relleno, valores de relleno y tolerancias.
Cambiar la forma de DataFrames y Series
En pandas, cambiar la forma de un DataFrame o una Serie es una operación fundamental para la manipulación de datos. La función principal para realizar estas operaciones es pivot(), pivot_table(), stack(), unstack(), y melt(). Estas funciones permiten reorganizar y transformar la estructura de los datos para análisis específicos.
pivot()
La función pivot() permite reorganizar un DataFrame según los valores de sus columnas. Esta operación es útil cuando se necesita transformar datos largos en datos anchos.
import pandas as pd
df = pd.DataFrame({
'date': ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-01', '2023-01-02', '2023-01-03'],
'city': ['New York', 'New York', 'New York', 'Los Angeles', 'Los Angeles', 'Los Angeles'],
'temperature': [32, 35, 28, 75, 78, 80]
})
pivoted_df = df.pivot(index='date', columns='city', values='temperature')
print(pivoted_df)
Resultado:
city Los Angeles New York
date
2023-01-01 75 32
2023-01-02 78 35
2023-01-03 80 28
pivot_table()
pivot_table() es una versión más flexible de pivot(), que permite agregar múltiples valores y aplicar funciones de agregación.
df = pd.DataFrame({
'date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'city': ['New York', 'Los Angeles', 'New York', 'Los Angeles'],
'humidity': [55, 65, 60, 70],
'temperature': [32, 75, 35, 78]
})
pivot_table_df = pd.pivot_table(df, values=['temperature', 'humidity'], index='date', columns='city', aggfunc='mean')
print(pivot_table_df)
Resultado:
humidity temperature
city Los Angeles New York Los Angeles New York
date
2023-01-01 65.0 55.0 75.0 32.0
2023-01-02 70.0 60.0 78.0 35.0
stack()yunstack()
stack() convierte un nivel de columnas en un índice, mientras que unstack() hace lo inverso, convirtiendo un nivel de índice en columnas.
df = pd.DataFrame({
'date': ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-01', '2023-01-02', '2023-01-03'],
'city': ['New York', 'New York', 'New York', 'Los Angeles', 'Los Angeles', 'Los Angeles'],
'temperature': [32, 35, 28, 75, 78, 80]
})
pivoted_df = df.pivot(index='date', columns='city', values='temperature')
stacked_df = pivoted_df.stack()
print(stacked_df)
Resultado:
date city
2023-01-01 Los Angeles 75
New York 32
2023-01-02 Los Angeles 78
New York 35
2023-01-03 Los Angeles 80
New York 28
dtype: int64
Deshaciendo el stack() con unstack():
unstacked_df = stacked_df.unstack()
print(unstacked_df)
Resultado:
city Los Angeles New York
date
2023-01-01 75 32
2023-01-02 78 35
2023-01-03 80 28
melt()
La función melt() transforma un DataFrame de formato ancho a formato largo, útil para normalizar datos.
melted_df = pd.melt(pivoted_df.reset_index(), id_vars=['date'], value_vars=['Los Angeles', 'New York'], var_name='city', value_name='temperature')
print(melted_df)
Resultado:
date city temperature
0 2023-01-01 Los Angeles 75
1 2023-01-02 Los Angeles 78
2 2023-01-03 Los Angeles 80
3 2023-01-01 New York 32
4 2023-01-02 New York 35
5 2023-01-03 New York 28
Estas operaciones permiten flexibilidad en la manipulación y transformación de datos, facilitando su análisis y visualización posterior.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Pandas es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Pandas
Explora más contenido relacionado con Pandas y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender el uso de la función merge() en pandas. Realizar uniones internas, externas, por la derecha y por la izquierda entre DataFrames. Fusionar DataFrames usando índices en lugar de columnas. Concatenar DataFrames mediante la función concat(). Entender el reindexado para alinear un DataFrame con un nuevo índice. Aprender a modificar la forma de un DataFrame o una Serie.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje