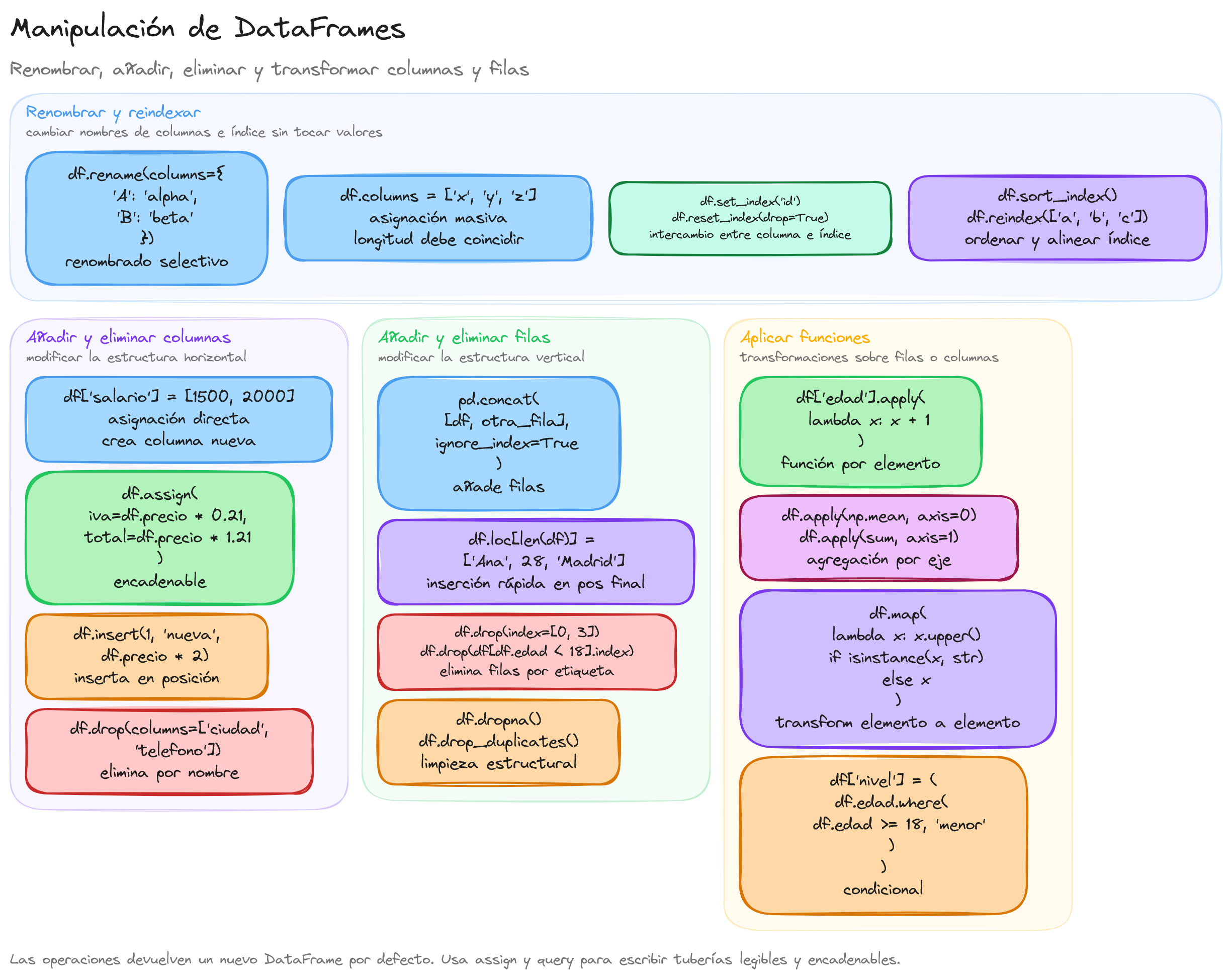
Cambiar el nombre de columnas y filas
En pandas, cambiar el nombre de columnas y filas es una operación común que facilita la manipulación y comprensión de los datos. A continuación, se describen las formas más eficaces y recomendadas para realizar estas tareas.
graph TB
DF[DataFrame original] -->|rename columns/index| DF2[DataFrame renombrado]
DF -->|assign / df col1=...| DF3[Añadir columnas]
DF -->|drop columns/index| DF4[Eliminar columnas o filas]
DF -->|loc fila nueva| DF5[Insertar filas]
DF -->|apply axis=0/1| DF6[Función por columna o fila]
DF -->|set_index columna| DF7[Cambiar índice]
DF -->|reset_index| DF8[Devolver índice numérico]
DF -->|inplace=True| MUT[Mutar DataFrame original]
DF -->|copy_on_write| INM[Devolver copia segura]
Para cambiar el nombre de las columnas de un DataFrame, se utiliza el método rename(). Este método permite modificar los nombres de las columnas especificando un diccionario donde las claves son los nombres actuales y los valores son los nuevos nombres.
import pandas as pd
# Crear un DataFrame de ejemplo
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# Cambiar el nombre de las columnas
df_renamed = df.rename(columns={'A': 'Alpha', 'B': 'Beta', 'C': 'Gamma'})
print(df_renamed)
Otra forma de cambiar los nombres de todas las columnas es asignar una lista con los nuevos nombres directamente al atributo columns del DataFrame:
# Asignar nuevos nombres a todas las columnas
df.columns = ['X', 'Y', 'Z']
print(df)
Para cambiar el nombre de las filas, también se puede utilizar el método rename(), especificando el diccionario correspondiente en el parámetro index:
# Cambiar el nombre de las filas
df_renamed_rows = df.rename(index={0: 'Row1', 1: 'Row2', 2: 'Row3'})
print(df_renamed_rows)
Si se desea cambiar el nombre de todas las filas, se puede asignar una lista con los nuevos nombres directamente al atributo index del DataFrame:
# Asignar nuevos nombres a todas las filas
df.index = ['First', 'Second', 'Third']
print(df)
Además, es posible cambiar el nombre tanto de las columnas como de las filas simultáneamente utilizando el método rename():
# Cambiar el nombre de columnas y filas simultáneamente
df_renamed_all = df.rename(columns={'X': 'Alpha', 'Y': 'Beta', 'Z': 'Gamma'}, index={'First': 'Row1', 'Second': 'Row2', 'Third': 'Row3'})
print(df_renamed_all)
Agregar columnas y eliminar columnas
En pandas, agregar y eliminar columnas son operaciones fundamentales para la manipulación de DataFrames. Estas operaciones permiten modificar la estructura de los datos de manera flexible, facilitando el análisis y procesamiento de la información.
Para agregar una columna a un DataFrame, se puede asignar una nueva serie de datos a través de una nueva clave en el DataFrame.
Por ejemplo, si se desea agregar una columna denominada D con valores específicos, se puede realizar de la siguiente manera:
import pandas as pd
# Crear un DataFrame de ejemplo
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# Agregar una nueva columna 'D'
df['D'] = [10, 11, 12]
print(df)
También es posible agregar una columna basada en una operación realizada sobre otras columnas existentes. Por ejemplo, si se desea crear una columna E que sea la suma de las columnas A y B:
# Agregar una columna 'E' que es la suma de 'A' y 'B'
df['E'] = df['A'] + df['B']
print(df)
Para eliminar una o más columnas, se utiliza el método drop(). Este método permite especificar las columnas a eliminar mediante el parámetro columns. A continuación se muestra cómo eliminar una única columna:
# Eliminar la columna 'D'
df = df.drop(columns=['D'])
print(df)
Si se desea eliminar múltiples columnas, se pueden pasar los nombres de las columnas en una lista:
# Eliminar las columnas 'B' y 'C'
df = df.drop(columns=['B', 'C'])
print(df)
Es importante notar que al agregar o eliminar columnas, el tamaño del DataFrame se ajusta automáticamente, y estas operaciones no afectan a otras columnas o filas del DataFrame. Por último, pandas también permite agregar columnas utilizando métodos como assign() que proporcionan una sintaxis más funcional y pueden ser encadenados:
# Utilizar assign() para agregar una nueva columna 'F'
df = df.assign(F=[13, 14, 15])
print(df)
El método assign() devuelve una nueva copia del DataFrame con las columnas añadidas, lo que puede ser útil cuando se desea mantener el DataFrame original sin modificar.
Aplicar funciones a columnas
En pandas, aplicar funciones a columnas es una operación esencial para transformar y analizar datos de manera eficiente.
Existen varias formas de aplicar funciones a columnas en un DataFrame, desde funciones básicas definidas por el usuario hasta funciones más complejas utilizando apply() y map().
Para aplicar una función a una columna específica, se puede utilizar el método apply(). Este método permite aplicar una función a lo largo de un eje del DataFrame (filas o columnas).
A continuación se muestra cómo aplicar una función lambda que multiplica por 2 los valores de la columna A:
import pandas as pd
# Crear un DataFrame de ejemplo
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# Aplicar una función a la columna 'A'
df['A'] = df['A'].apply(lambda x: x * 2)
print(df)
El método apply() es muy flexible y permite aplicar tanto funciones de numpy como funciones definidas por el usuario. Por ejemplo, se puede aplicar la función np.sqrt de numpy para calcular la raíz cuadrada de los valores de la columna B:
import numpy as np
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# Aplicar la función numpy sqrt a la columna 'B'
df['B'] = df['B'].apply(np.sqrt)
print(df)
Otra forma de aplicar funciones a columnas es utilizando el método map(). Este método es útil cuando se desea aplicar una función a cada elemento de una Serie. Por ejemplo, si se desea convertir los valores de la columna C en cadenas de texto:
# Aplicar la función str a la columna 'C'
df['C'] = df['C'].map(str)
print(df)
El método astype() en Pandas es una forma eficiente de transformar todos los elementos de un DataFrame a un tipo específico de datos. astype() permite convertir rápidamente todos los valores del DataFrame, por ejemplo, a cadenas de texto de manera uniforme. Esto es útil cuando se desea asegurar que todos los datos en el DataFrame sean de un tipo específico.
# Convertir todos los elementos del DataFrame a cadenas
df = df.astype(str)
print(df)
Además, pandas permite aplicar funciones de manera condicional utilizando np.where(). Este método es útil para aplicar transformaciones basadas en condiciones específicas. Por ejemplo, si se desea multiplicar por 2 los valores de la columna A solo si son mayores que 2:
# Aplicar una función condicional a la columna 'A'
df['A'] = np.where(df['A'] > 2, df['A'] * 2, df['A'])
print(df)
Finalmente, es importante mencionar que también se pueden aplicar funciones de agregación a columnas utilizando métodos como agg() o transform(). Estos métodos son útiles para realizar operaciones de resumen o transformaciones específicas en columnas de un DataFrame. Por ejemplo, para calcular la suma y la media de la columna B:
# Aplicar funciones de agregación a la columna 'B'
result = df['B'].agg(['sum', 'mean'])
print(result)
El método transform() permite aplicar una función a una columna y devolver un objeto que tiene el mismo tamaño que la columna original, lo cual es útil en operaciones de transformación que mantienen la estructura del DataFrame. Por ejemplo, para normalizar los valores de la columna A restando la media y dividiendo por la desviación estándar:
# Normalizar la columna 'A'
df['A'] = df['A'].transform(lambda x: (x - x.mean()) / x.std())
print(df)
Estas técnicas permiten una manipulación avanzada y eficiente de los datos en pandas, facilitando el análisis y la transformación de grandes conjuntos de datos.
Agregar y eliminar filas
En pandas, la manipulación de filas en un DataFrame es una tarea común y esencial para el análisis de datos.
A continuación, se describen las técnicas y métodos más actualizados y recomendados para agregar y eliminar filas.
El método pd.concat() es la forma recomendada para agregar nuevas filas a un DataFrame, reemplazando al método append() (deprecado en versiones recientes de Pandas). Este método permite concatenar uno o más DataFrames de manera eficiente. pd.concat() puede combinar DataFrames tanto horizontal como verticalmente (a lo largo de los ejes), lo que lo hace muy flexible.
Uso básico de pd.concat() para agregar filas:
import pandas as pd
# Crear un DataFrame de ejemplo
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# Crear una nueva fila como un DataFrame
new_row = pd.DataFrame({'A': [4], 'B': [7], 'C': [10]})
# Agregar la nueva fila al DataFrame original
df = pd.concat([df, new_row], ignore_index=True)
print(df)
En este ejemplo, pd.concat() combina el DataFrame original df con new_row a lo largo del eje 0 (filas), lo que resulta en un nuevo DataFrame que incluye la nueva fila. La opción ignore_index=True asegura que los índices se reasignen correctamente.
Otra forma de agregar filas es utilizando el método loc[], que permite asignar una nueva fila directamente mediante el índice. Este método es útil cuando se desea agregar una fila con un índice específico:
# Agregar una nueva fila utilizando loc[]
df.loc[4] = [5, 8, 11]
print(df)
Para eliminar filas de un DataFrame, se utiliza el método drop(), especificando los índices de las filas a eliminar mediante el parámetro index. Este método devuelve un nuevo DataFrame sin las filas eliminadas:
# Eliminar la fila con índice 2
df = df.drop(index=2)
print(df)
Si se desea eliminar múltiples filas, se pueden pasar los índices en una lista:
# Eliminar las filas con índices 0 y 1
df = df.drop(index=[0, 1])
print(df)
También se puede eliminar una fila reasignando el resultado de drop() al mismo DataFrame, que es el patrón recomendado frente al uso de inplace=True:
# Eliminar la fila con índice 3
df = df.drop(index=3)
print(df)
Además, pandas permite eliminar filas basadas en condiciones específicas utilizando técnicas de filtrado. Por ejemplo, si se desea eliminar todas las filas donde el valor de la columna 'A' sea mayor que 3:
# Eliminar filas donde el valor de 'A' es mayor que 3
df = df[df['A'] <= 3]
print(df)
Para agregar múltiples filas, se puede concatenar un DataFrame que contenga las nuevas filas utilizando pd.concat():
# Crear un DataFrame con nuevas filas
new_rows = pd.DataFrame({
'A': [6, 7],
'B': [12, 14],
'C': [18, 21]
})
# Agregar las nuevas filas al DataFrame original
df = pd.concat([df, new_rows], ignore_index=True)
print(df)
Estas técnicas permiten una manipulación flexible y eficiente de las filas en un DataFrame, facilitando la gestión y transformación de los datos en pandas.
Índice y manipulación de índice
En pandas, el índice de un DataFrame es una parte fundamental que permite acceder y manipular los datos de manera eficiente.
A continuación, se describen las técnicas y métodos más actualizados y recomendados para trabajar con índices en pandas.
El índice de un DataFrame puede ser configurado al momento de la creación del DataFrame o modificado posteriormente utilizando varios métodos.
Para establecer una columna como índice, se utiliza el método set_index(). Este método devuelve un nuevo DataFrame con la columna especificada como índice:
import pandas as pd
# Crear un DataFrame de ejemplo
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# Establecer la columna 'A' como índice
df_indexed = df.set_index('A')
print(df_indexed)
Para restablecer el índice a su estado original, se utiliza el método reset_index(), que devuelve el índice a una columna del DataFrame:
# Restablecer el índice a una columna
df_reset = df_indexed.reset_index()
print(df_reset)
Es posible establecer múltiples columnas como índice, creando un índice jerárquico (MultiIndex). Esto se puede lograr pasando una lista de columnas al método set_index():
# Establecer múltiples columnas como índice
df_multi_indexed = df.set_index(['A', 'B'])
print(df_multi_indexed)
El acceso a los datos en un DataFrame con un índice jerárquico se realiza utilizando el método xs() (cross-section), que permite seleccionar datos en niveles específicos del índice:
# Acceder a los datos en un índice jerárquico
cross_section = df_multi_indexed.xs(key=2, level='A')
print(cross_section)
Para renombrar el índice, se puede utilizar el método rename_axis(), que permite cambiar el nombre del índice sin modificar los datos:
# Renombrar el índice
df_renamed_index = df_indexed.rename_axis('NewIndex')
print(df_renamed_index)
En ocasiones, es útil cambiar el tipo de datos del índice. Esto se puede lograr utilizando el método astype():
# Cambiar el tipo de datos del índice a cadena de texto
df_indexed.index = df_indexed.index.astype(str)
print(df_indexed)
Para ordenar un DataFrame basado en su índice, se utiliza el método sort_index(), que ordena el DataFrame según los valores del índice:
# Ordenar el DataFrame basado en el índice
df_sorted = df_indexed.sort_index()
print(df_sorted)
Además, pandas permite la reindexación de un DataFrame utilizando el método reindex(), que ajusta el DataFrame a un nuevo índice, agregando filas con valores faltantes (NaN) si el nuevo índice contiene valores que no estaban en el índice original:
# Reindexar el DataFrame
new_index = [1, 2, 3, 4]
df_reindexed = df_indexed.reindex(new_index)
print(df_reindexed)
Finalmente, para trabajar con índices de fechas, pandas proporciona el método pd.date_range() para crear un índice de fechas y el método set_index() para establecerlo en el DataFrame:
# Crear un índice de fechas y establecerlo en el DataFrame
date_index = pd.date_range(start='2023-01-01', periods=3, freq='D')
df_date_indexed = df.set_index(date_index)
print(df_date_indexed)
Estas técnicas permiten una manipulación avanzada y eficiente del índice en pandas, facilitando el acceso, transformación y análisis de los datos en un DataFrame.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Pandas es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Pandas
Explora más contenido relacionado con Pandas y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Cambiar los nombres de columnas y filas en un DataFrame. Agregar y eliminar columnas en un DataFrame. Agregar y eliminar filas en un DataFrame. Aplicar funciones a columnas y filas en un DataFrame. Manipular y gestionar índices de un DataFrame.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje