¿Qué son los DataFrames en Pandas y para qué sirven?
Los DataFrames en Pandas son estructuras bidimensionales que permiten almacenar y manipular datos tabulares de manera eficiente. Estas estructuras son similares a las tablas en bases de datos o a las hojas de cálculo en Excel, y están diseñadas para manejar grandes volúmenes de datos de forma flexible y optimizada.
Un DataFrame se compone de filas y columnas, donde cada columna puede contener diferentes tipos de datos (números, cadenas, booleanos, etc.). Los DataFrames son fundamentales en el análisis de datos porque permiten realizar operaciones complejas de selección, filtrado, agregación y transformación de datos de manera sencilla y rápida.
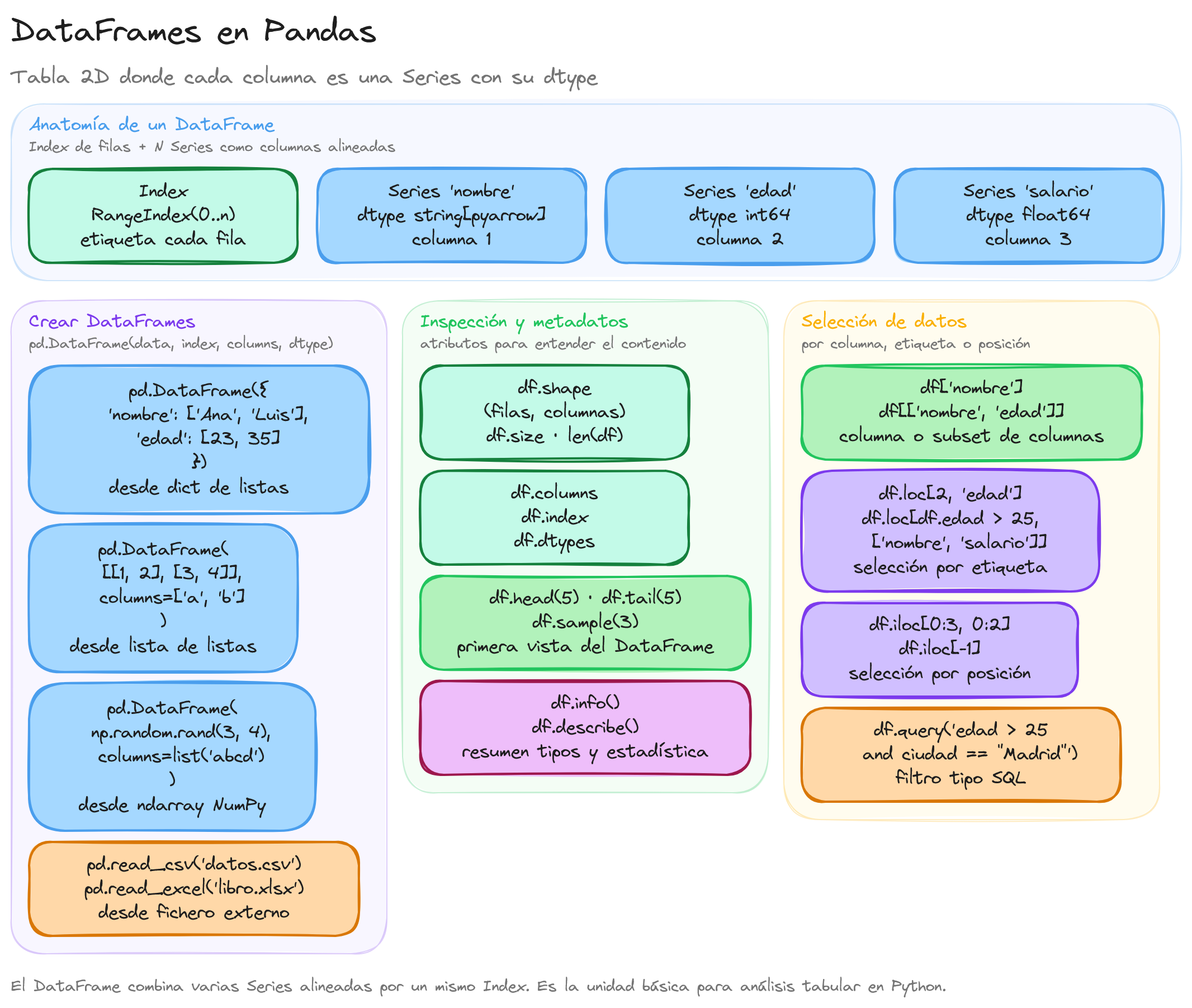
El siguiente diagrama ilustra la anatomía interna de un DataFrame: un RangeIndex o Index etiqueta las filas, cada columna es internamente una Series con su propio dtype, y el conjunto comparte el mismo índice para alinear valores.
flowchart LR
subgraph DF[DataFrame]
direction LR
Idx["Index<br>0, 1, 2, 3"]
S1["Series col A<br>dtype int64"]
S2["Series col B<br>dtype string pyarrow"]
S3["Series col C<br>dtype float64"]
end
Idx -.alinea.-> S1
Idx -.alinea.-> S2
Idx -.alinea.-> S3
S1 --> Op["Operaciones<br>loc, iloc, groupby, merge"]
S2 --> Op
S3 --> Op
A continuación se detallan algunas de las características y funcionalidades clave de los DataFrames en Pandas:
- Estructura tabular: Cada DataFrame tiene un esquema de filas y columnas, donde cada columna puede tener un nombre y un tipo de dato específico.
- Indexación: Los DataFrames utilizan un índice para identificar de forma única cada fila. Este índice puede ser un rango de números enteros, etiquetas o una combinación de ambos.
- Operaciones de selección y filtrado: Los DataFrames permiten seleccionar y filtrar datos utilizando diversas técnicas, como el acceso por etiquetas (con
loc) o por posición (coniloc). - Manipulación de datos: Los DataFrames soportan una amplia gama de operaciones de manipulación de datos, incluyendo la adición y eliminación de columnas, la fusión de DataFrames, el agrupamiento y la agregación de datos.
- Integración con otras herramientas: Los DataFrames se integran fácilmente con otras bibliotecas de análisis de datos y aprendizaje automático en Python, como NumPy, SciPy y scikit-learn.
Ejemplo básico de creación y manipulación de un DataFrame:
import pandas as pd
# Crear un DataFrame a partir de un diccionario
data = {
'Nombre': ['Ana', 'Luis', 'Marta'],
'Edad': [23, 35, 29],
'Ciudad': ['Madrid', 'Barcelona', 'Valencia']
}
df = pd.DataFrame(data)
# Mostrar el DataFrame
print(df)
# Seleccionar una columna
print(df['Nombre'])
# Filtrar filas donde la edad es mayor de 25
filtered_df = df[df['Edad'] > 25]
print(filtered_df)
# Añadir una nueva columna
df['Salario'] = [50000, 60000, 55000]
print(df)
# Eliminar una columna
df = df.drop(columns=['Ciudad'])
print(df)
Este ejemplo ilustra algunas de las operaciones básicas que se pueden realizar con un DataFrame, como la creación a partir de un diccionario, la selección de columnas, el filtrado de filas, la adición de nuevas columnas y la eliminación de columnas existentes.
Los DataFrames en Pandas son esenciales para cualquier tarea de análisis de datos en Python debido a su flexibilidad y a las capacidades avanzadas que proporcionan para la manipulación y análisis de datos tabulares.
Formas de crear DataFrames
Pandas ofrece diversas maneras de crear DataFrames, permitiendo la flexibilidad de construir estas estructuras a partir de diferentes tipos de datos.
A continuación, se describen varias formas comunes de crear DataFrames con ejemplos de código correspondientes.
1. Crear DataFrames a partir de diccionarios:
Los diccionarios son una manera común y conveniente de crear DataFrames. Cada clave del diccionario representa el nombre de una columna y su valor es una lista de elementos que conforman las filas de esa columna.
import pandas as pd
data = {
'Nombre': ['Ana', 'Luis', 'Marta'],
'Edad': [23, 35, 29],
'Ciudad': ['Madrid', 'Barcelona', 'Valencia']
}
df = pd.DataFrame(data)
print(df)
2. Crear DataFrames a partir de listas de listas:
También se pueden crear DataFrames a partir de listas de listas, especificando los nombres de las columnas.
data = [
['Ana', 23, 'Madrid'],
['Luis', 35, 'Barcelona'],
['Marta', 29, 'Valencia']
]
df = pd.DataFrame(data, columns=['Nombre', 'Edad', 'Ciudad'])
print(df)
3. Crear DataFrames a partir de listas de diccionarios:
Otra forma es utilizar una lista de diccionarios, donde cada diccionario representa una fila del DataFrame.
data = [
{'Nombre': 'Ana', 'Edad': 23, 'Ciudad': 'Madrid'},
{'Nombre': 'Luis', 'Edad': 35, 'Ciudad': 'Barcelona'},
{'Nombre': 'Marta', 'Edad': 29, 'Ciudad': 'Valencia'}
]
df = pd.DataFrame(data)
print(df)
4. Crear DataFrames a partir de arrays de NumPy:
Para usuarios que trabajen con datos numéricos, es común crear DataFrames a partir de arrays de NumPy.
import pandas as pd
import numpy as np
data = np.array([
['Ana', 23, 'Madrid'],
['Luis', 35, 'Barcelona'],
['Marta', 29, 'Valencia']
])
df = pd.DataFrame(data, columns=['Nombre', 'Edad', 'Ciudad'])
print(df)
5. Crear DataFrames a partir de series de Pandas:
Se pueden combinar múltiples series de Pandas en un solo DataFrame. Cada serie se convierte en una columna del DataFrame.
nombres = pd.Series(['Ana', 'Luis', 'Marta'])
edades = pd.Series([23, 35, 29])
ciudades = pd.Series(['Madrid', 'Barcelona', 'Valencia'])
df = pd.DataFrame({
'Nombre': nombres,
'Edad': edades,
'Ciudad': ciudades
})
print(df)
6. Crear DataFrames a partir de archivos CSV:
Una de las formas más comunes de crear DataFrames es cargando datos desde archivos CSV utilizando el método read_csv.
df = pd.read_csv('ruta_al_archivo.csv')
print(df)
7. Crear DataFrames a partir de otros formatos de archivo:
Pandas también permite la creación de DataFrames a partir de otros formatos de archivo como Excel, JSON, SQL, entre otros.
# Desde un archivo Excel
df_excel = pd.read_excel('ruta_al_archivo.xlsx')
# Desde un archivo JSON
df_json = pd.read_json('ruta_al_archivo.json')
# Desde una consulta SQL
import sqlite3
conn = sqlite3.connect('base_de_datos.db')
df_sql = pd.read_sql_query('SELECT * FROM tabla', conn)
Estas son algunas de las formas más utilizadas para crear DataFrames en Pandas. La elección del método adecuado depende del formato y la estructura de los datos de origen.
Entender el índice en DataFrames
El índice en un DataFrame de Pandas es una estructura fundamental que permite identificar de manera única cada fila dentro del DataFrame. Comprender cómo funciona el índice y cómo manipularlo es crucial para realizar operaciones avanzadas de análisis y manipulación de datos.
Cada DataFrame tiene un índice que puede ser explícito o implícito. Por defecto, Pandas asigna un índice implícito que es una secuencia de enteros comenzando desde 0. Sin embargo, es posible personalizar este índice para que utilice valores significativos extraídos de los datos, lo que puede facilitar la manipulación y el análisis de los mismos.
Tipos de índices
Índice numérico secuencial (por defecto):
import pandas as pd
data = {'Nombre': ['Ana', 'Luis', 'Marta'], 'Edad': [23, 35, 29]}
df = pd.DataFrame(data)
print(df)
Este DataFrame tendrá un índice numérico secuencial por defecto (0, 1, 2).
Índice basado en una columna existente:
df = df.set_index('Nombre')
print(df)
Aquí, el índice se establece en la columna Nombre, permitiendo identificar las filas por el valor del nombre.
Índice multi-nivel (MultiIndex):
import pandas as pd
arrays = [['Ana', 'Ana', 'Luis', 'Luis'], ['Math', 'Science', 'Math', 'Science']]
index = pd.MultiIndex.from_arrays(arrays, names=('Nombre', 'Asignatura'))
data = {'Notas': [90, 85, 88, 92]}
df = pd.DataFrame(data, index=index)
print(df)
Un MultiIndex permite tener múltiples niveles de índices, lo que es útil para datos jerárquicos.
Manipulación del índice
Restablecer el índice a su valor por defecto:
import pandas as pd
# Crear un DataFrame de ejemplo con un índice personalizado
data = {
'Nombre': ['Ana', 'Juan', 'Pedro', 'Laura'],
'Edad': [23, 25, 30, 28],
'Ciudad': ['Madrid', 'Barcelona', 'Sevilla', 'Valencia']
}
df = pd.DataFrame(data)
df = df.set_index('Nombre')
print("DataFrame con indice personalizado:")
print(df)
# Restablecer el indice al valor por defecto
df = df.reset_index()
print("\nDataFrame despues de restablecer el indice:")
print(df)
Este comando restablece el índice al valor por defecto, convirtiendo el índice actual en una columna del DataFrame.
Renombrar el índice:
# Renombrar el índice
df.index.name = 'Identificador'
print(df)
Se puede asignar un nombre al índice para mayor claridad.
Seleccionar datos mediante el índice:
# Establecer la columna 'Nombre' como indice
df = df.set_index('Nombre')
# Seleccionar datos mediante el indice
fila_ana = df.loc['Ana']
print(fila_ana)
Utilizando loc, se puede acceder a las filas directamente mediante el valor del índice.
Índice temporal
Para series temporales, es común utilizar un índice basado en fechas, lo que facilita la manipulación de datos temporales.
Crear un índice de fechas:
import pandas as pd
date_rng = pd.date_range(start='2023-01-01', end='2023-01-10', freq='D')
df = pd.DataFrame(date_rng, columns=['Fecha'])
df['Datos'] = range(10)
df = df.set_index('Fecha')
print(df)
Operaciones con índices temporales:
# Seleccionar datos de una fecha específica
print(df.loc['2023-01-03'])
# Seleccionar datos de un rango de fechas
print(df.loc['2023-01-03':'2023-01-05'])
Índice duplicado
Es posible que un DataFrame tenga índices duplicados, aunque en general no es recomendable porque puede complicar las operaciones de manipulación y análisis.
Detectar índices duplicados:
import pandas as pd
df = pd.DataFrame({'Nombre': ['Ana', 'Luis', 'Ana'], 'Edad': [23, 35, 29]})
df = df.set_index('Nombre')
print(df.index.duplicated())
Eliminar índices duplicados:
df = df[~df.index.duplicated(keep='first')]
print(df)
Índice jerárquico (MultiIndex)
En situaciones donde los datos tienen múltiples niveles de categorización, se puede utilizar un índice jerárquico o MultiIndex.
Crear un MultiIndex:
import pandas as pd
arrays = [['Ana', 'Ana', 'Luis', 'Luis'], ['Math', 'Science', 'Math', 'Science']]
index = pd.MultiIndex.from_arrays(arrays, names=('Nombre', 'Asignatura'))
data = {'Notas': [90, 85, 88, 92]}
df = pd.DataFrame(data, index=index)
print(df)
Acceso a datos con MultiIndex:
# Seleccionar todas las asignaturas de 'Ana'
print(df.loc['Ana'])
# Seleccionar la nota de 'Luis' en 'Math'
print(df.loc[('Luis', 'Math')])
El índice en los DataFrames de Pandas es una herramienta fundamental que facilita la identificación y manipulación de datos de manera eficiente. Entender como configurar y utilizar el índice adecuadamente es esencial para aprovechar al máximo las capacidades de los DataFrames en Pandas.
Atributos de DataFrames
Los DataFrames en Pandas cuentan con varios atributos que permiten acceder a información importante sobre su estructura y contenido. Estos atributos proporcionan detalles sobre las dimensiones, tipos de datos, etiquetas de filas y columnas, entre otros aspectos. A continuación, se describen los principales atributos de los DataFrames:
shape: Este atributo devuelve una tupla que representa las dimensiones del DataFrame, donde el primer elemento es el número de filas y el segundo es el número de columnas.
import pandas as pd
data = {'Nombre': ['Ana', 'Luis', 'Marta'], 'Edad': [23, 35, 29]}
df = pd.DataFrame(data)
print(df.shape) # Salida: (3, 2)
size: Este atributo devuelve el número total de elementos en el DataFrame (filas multiplicadas por columnas).
print(df.size) # Salida: 6
ndim: Este atributo devuelve el número de dimensiones del DataFrame, que siempre será 2 para los DataFrames.
print(df.ndim) # Salida: 2
columns: Este atributo devuelve unIndexcon las etiquetas de las columnas del DataFrame.
print(df.columns) # Salida: Index(['Nombre', 'Edad'], dtype='object')
index: Este atributo devuelve unIndexcon las etiquetas de las filas del DataFrame.
print(df.index) # Salida: RangeIndex(start=0, stop=3, step=1)
dtypes: Este atributo devuelve una serie con los tipos de datos de cada columna del DataFrame.
print(df.dtypes)
# Salida:
# Nombre object
# Edad int64
# dtype: object
En versiones modernas de Pandas, las columnas de texto utilizan el tipo string respaldado por PyArrow en lugar de object. Este tipo es más eficiente en memoria y ofrece mejor rendimiento. Se puede especificar al crear el DataFrame con dtype="string" o convertir con df['col'] = df['col'].astype('string').
values: Este atributo devuelve una representación en forma de array de NumPy de los datos del DataFrame. Nota: Aunque el atributovaluessigue funcionando, se recomienda utilizar el métodoto_numpy()por ser más flexible y seguro en ciertas operaciones.
print(df.values)
# Salida:
# [['Ana' 23]
# ['Luis' 35]
# ['Marta' 29]]
T: Este atributo devuelve la transposición del DataFrame, intercambiando filas por columnas.
print(df.T)
# Salida:
# 0 1 2
# Nombre Ana Luis Marta
# Edad 23 35 29
head(n): Este método (aunque no es un atributo, es útil mencionarlo) devuelve las primerasnfilas del DataFrame. Por defecto,nes 5.
print(df.head(2))
# Salida:
# Nombre Edad
# 0 Ana 23
# 1 Luis 35
tail(n): Similar ahead, este método devuelve las últimasnfilas del DataFrame.
print(df.tail(2))
# Salida:
# Nombre Edad
# 1 Luis 35
# 2 Marta 29
memory_usage(deep=True): Este atributo devuelve una serie con el uso de memoria de cada columna en bytes. Sideep=True, incluye el uso de memoria de objetos.
print(df.memory_usage(deep=True))
# Salida:
# Index 132
# Nombre 159
# Edad 24
# dtype: int64
empty: Este atributo devuelveTruesi el DataFrame está vacío (no contiene elementos) yFalseen caso contrario.
print(df.empty) # Salida: False
Estos atributos son esenciales para comprender y manipular la estructura y los datos contenidos en un DataFrame de Pandas. Conocerlos y utilizarlos adecuadamente facilita la realización de análisis de datos y permite optimizar el rendimiento de las operaciones sobre los DataFrames.
Métodos básicos de DataFrames
Los DataFrames en Pandas ofrecen una amplia variedad de métodos que permiten realizar operaciones avanzadas de análisis y manipulación de datos. A continuación, se describen algunos de los métodos básicos más utilizados:
head(n=5): Devuelve las primerasnfilas del DataFrame. Por defecto,nes 5.
import pandas as pd
data = {'Nombre': ['Ana', 'Luis', 'Marta', 'Juan', 'Carlos'], 'Edad': [23, 35, 29, 40, 22]}
df = pd.DataFrame(data)
print(df.head(3))
# Salida:
# Nombre Edad
# 0 Ana 23
# 1 Luis 35
# 2 Marta 29
tail(n=5): Devuelve las últimasnfilas del DataFrame. Por defecto,nes 5.
print(df.tail(2))
# Salida:
# Nombre Edad
# 3 Juan 40
# 4 Carlos 22
to_numpy(): Este método devuelve los datos del DataFrame como un array de NumPy. Se recomienda utilizarto_numpy()en lugar devalues, ya que es más flexible y menos propenso a errores cuando se trabaja con diferentes tipos de datos y estructuras.
print(df.to_numpy())
# Salida:
# [['Ana' 23]
# ['Luis' 35]
# ['Marta' 29]]
info(): Proporciona un resumen conciso del DataFrame, incluyendo el índice, el tipo de datos de cada columna y el uso de memoria.
df.info()
# Salida:
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 5 entries, 0 to 4
# Data columns (total 2 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Nombre 5 non-null object
# 1 Edad 5 non-null int64
# dtypes: int64(1), object(1)
# memory usage: 208.0+ bytes
describe(): Genera estadísticas descriptivas que resumen la tendencia central, la dispersión y la forma de la distribución de un conjunto de datos, excluyendo valores NaN.
print(df.describe())
# Salida:
# Edad
# count 5.000000
# mean 29.800000
# std 7.726578
# min 22.000000
# 25% 23.000000
# 50% 29.000000
# 75% 35.000000
# max 40.000000
mean(): Devuelve el promedio de los valores de cada columna numérica.
print(df['Edad'].mean())
# Salida: 29.8
sum(): Devuelve la suma de los valores de cada columna numérica.
print(df['Edad'].sum())
# Salida: 149
max(): Devuelve el valor máximo de cada columna.
print(df['Edad'].max())
# Salida: 40
min(): Devuelve el valor mínimo de cada columna.
print(df['Edad'].min())
# Salida: 22
count(): Devuelve el número de valores no nulos en cada columna.
print(df.count())
# Salida:
# Nombre 5
# Edad 5
# dtype: int64
value_counts(): Devuelve una serie con la frecuencia de cada valor único en una columna.
print(df['Nombre'].value_counts())
# Salida:
# Ana 1
# Luis 1
# Marta 1
# Juan 1
# Carlos 1
# Name: count, dtype: int64
drop(columns): Elimina una o más columnas del DataFrame.
df_sin_edad = df.drop(columns=['Edad'])
print(df_sin_edad)
# Salida:
# Nombre
# 0 Ana
# 1 Luis
# 2 Marta
# 3 Juan
# 4 Carlos
dropna(): Elimina las filas con valores nulos (NaN).
df_con_na = pd.DataFrame({'Nombre': ['Ana', 'Luis', None], 'Edad': [23, None, 29]})
df_sin_na = df_con_na.dropna()
print(df_sin_na)
# Salida:
# Nombre Edad
# 0 Ana 23.0
fillna(valor): Rellena los valores nulos (NaN) con un valor especificado.
df_rellenado = df_con_na.fillna(0)
print(df_rellenado)
# Salida:
# Nombre Edad
# 0 Ana 23.0
# 1 Luis 0.0
# 2 0 29.0
sort_values(by): Ordena el DataFrame por los valores de una o más columnas.
df_ordenado = df.sort_values(by='Edad')
print(df_ordenado)
# Salida:
# Nombre Edad
# 4 Carlos 22
# 0 Ana 23
# 2 Marta 29
# 1 Luis 35
# 3 Juan 40
groupby(by): Agrupa el DataFrame utilizando una o más columnas y aplica una función agregada a cada grupo.
import pandas as pd
data = {'Nombre': ['Ana', 'Luis', 'Marta', 'Ana', 'Luis'],
'Edad': [23, 35, 29, 22, 36],
'Ciudad': ['Madrid', 'Barcelona', 'Valencia', 'Madrid', 'Barcelona']}
df = pd.DataFrame(data)
df_agrupado = df.groupby('Ciudad').mean(numeric_only=True)
print(df_agrupado)
# Salida:
# Edad
# Ciudad
# Barcelona 35.5
# Madrid 22.5
# Valencia 29.0
Estos métodos básicos proporcionan una base sólida para comenzar a trabajar con DataFrames en Pandas. La comprensión y el uso efectivo de estos métodos permiten realizar análisis de datos de manera eficiente y efectiva.
Acceso a datos de Dataframe con iloc y loc
El acceso a datos en un DataFrame de Pandas puede realizarse de manera eficiente utilizando los métodos iloc y loc. Estos métodos permiten seleccionar subconjuntos de datos de diferentes maneras, ya sea por posición o por etiqueta, respectivamente.
iloc: acceso por posición
iloc permite acceder a las filas y columnas de un DataFrame utilizando índices de posición, similar a cómo se accede a los elementos de una lista o array en Python. Los índices de posición son enteros que comienzan desde 0.
Ejemplos de uso de iloc:
- Seleccionar una fila específica por su posición:
import pandas as pd
data = {'Nombre': ['Ana', 'Luis', 'Marta'], 'Edad': [23, 35, 29]}
df = pd.DataFrame(data)
# Seleccionar la primera fila
print(df.iloc[0])
- Seleccionar un rango de filas:
# Seleccionar las primeras dos filas
print(df.iloc[0:2])
- Seleccionar filas y columnas específicas:
# Seleccionar la primera fila y la segunda columna
print(df.iloc[0, 1])
- Seleccionar un rango de filas y columnas:
# Seleccionar las dos primeras filas y las dos primeras columnas
print(df.iloc[0:2, 0:2])
loc: acceso por etiqueta
loc permite acceder a las filas y columnas de un DataFrame utilizando las etiquetas de los índices y nombres de las columnas. Es útil cuando se trabaja con etiquetas significativas en lugar de posiciones numéricas.
Ejemplos de uso de loc:
- Seleccionar una fila específica por su etiqueta:
# Establecer 'Nombre' como indice
df = df.set_index('Nombre')
# Seleccionar la fila correspondiente a 'Ana'
print(df.loc['Ana'])
- Seleccionar un rango de filas por etiquetas:
# Seleccionar las filas correspondientes a 'Ana' y 'Luis'
print(df.loc['Ana':'Luis'])
- Seleccionar filas y columnas específicas por etiquetas:
# Seleccionar la fila correspondiente a 'Ana' y la columna 'Edad'
print(df.loc['Ana', 'Edad'])
- Seleccionar un rango de filas y columnas por etiquetas:
# Seleccionar las filas de 'Ana' a 'Luis' y las columnas 'Edad'
print(df.loc['Ana':'Luis', 'Edad'])
Diferencias clave entre iloc y loc
Tipo de acceso:
ilocutiliza índices de posición (enteros).locutiliza etiquetas (nombres de las filas y columnas).
Inclusividad de los rangos:
ilocexcluye el límite superior del rango.locincluye el límite superior del rango.
Compatibilidad con índices:
iloces útil cuando se trabaja con índices numéricos o cuando no se desea depender de las etiquetas.loces ideal cuando se trabaja con índices etiquetados que tienen significado semántico.
Ejemplos adicionales
- Seleccionar múltiples filas y columnas con
iloc:
# Seleccionar las dos primeras filas y las dos primeras columnas
print(df.iloc[0:2, 0:2])
- Seleccionar múltiples filas y columnas con
loc:
# Restablecer indice para usar etiquetas
df = df.reset_index()
# Seleccionar filas por etiquetas y columnas por nombres
print(df.loc[0:1, ['Nombre', 'Edad']])
- Filtrado de datos con condiciones utilizando
loc:
# Filtrar filas donde la edad es mayor de 25
print(df.loc[df['Edad'] > 25])
- Selección con condiciones complejas:
# Seleccionar filas donde la edad es mayor de 25 y el nombre es 'Luis'
print(df.loc[(df['Edad'] > 25) & (df['Nombre'] == 'Luis')])
El uso de iloc y loc en Pandas permite una gran flexibilidad y precisión al acceder y manipular datos en un DataFrame. Comprender la diferencia entre ambos métodos y saber cuándo utilizar cada uno es crucial para realizar un análisis de datos eficiente y efectivo.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, Pandas es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de Pandas
Explora más contenido relacionado con Pandas y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Entender qué son los DataFrames y su importancia en el análisis de datos. Crear DataFrames a partir de diferentes estructuras de datos (diccionarios, listas, arrays de NumPy, etc.). Manipular DataFrames mediante el acceso, selección y filtrado de datos. Aplicar operaciones de agregación y transformación en DataFrames. Utilizar el índice de los DataFrames para identificar y manipular filas. Integrar DataFrames con otras bibliotecas de análisis de datos en Python.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje