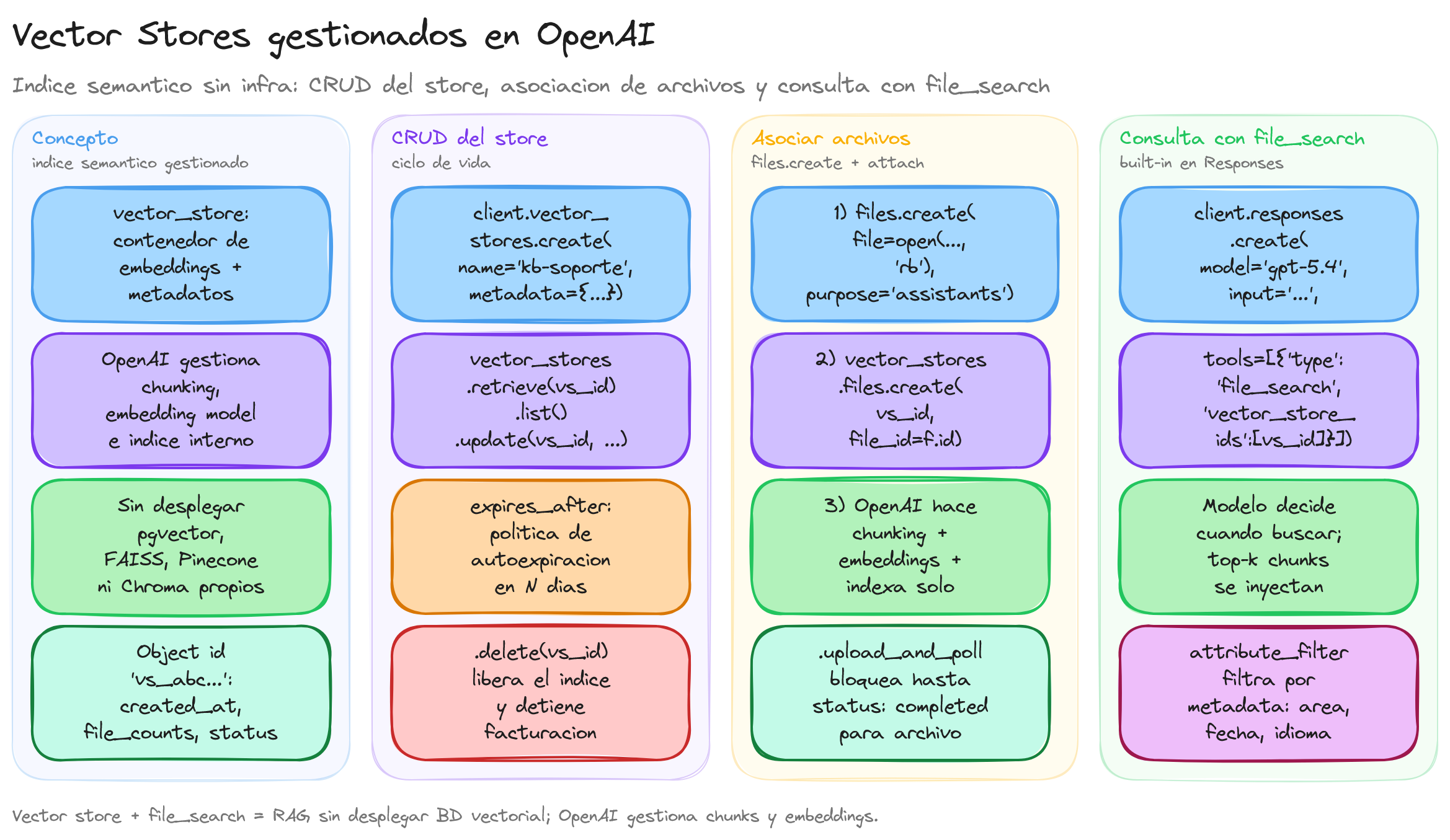
Qué son los Vector Stores
Un vector store en la plataforma de OpenAI es un contenedor especializado donde se almacenan representaciones numéricas de datos, conocidas como vectores o embeddings, generadas a partir de textos u otros contenidos. Estas representaciones capturan el significado semántico del contenido, lo que permite realizar operaciones posteriores basadas en similitud de significado y no solo en coincidencia literal de palabras.
Cada elemento dentro de un vector store combina al menos tres piezas de información: el embedding numérico, una referencia al contenido original (por ejemplo, un fragmento de un documento) y un conjunto de metadatos que describen el contexto de ese fragmento. Gracias a esta estructura, el sistema puede gestionar colecciones amplias de conocimiento sin tener que recorrer todo el texto en bruto en cada operación.
En la API, un vector store se representa como un objeto vector_store identificado por un id único y acompañado de atributos como name, marcas de tiempo de creación, contadores de archivos y, en muchos casos, una política de expiración. Estos campos permiten controlar el ciclo de vida del almacenamiento, monitorizar cuánto espacio se está utilizando y describir con claridad para qué se utiliza cada almacén.
Desde un punto de vista conceptual, un vector store se puede imaginar como una tabla lógica en la que cada fila representa un fragmento de contenido y contiene su vector, sus metadatos y la referencia al dato original. Las columnas de esta tabla conceptual corresponden a las distintas dimensiones del espacio vectorial, junto con las columnas auxiliares de contexto (metadatos, nombre de archivo, etc.), sobre las que más adelante se apoyarán las consultas semánticas y otros flujos de trabajo.
Aunque los vector stores suelen usarse en combinación con funcionalidades de búsqueda y recuperación, en esta lección nos centraremos únicamente en qué son a nivel de recurso y en cómo se gestionan a través de la API de OpenAI. La integración con File Search y con flujos de RAG se tratará en secciones posteriores, una vez asentados estos conceptos de base.
Operaciones
La API de Vector Stores de OpenAI expone un conjunto de operaciones centradas en el ciclo de vida del recurso: creación, consulta, listado, actualización y eliminación. Todas estas operaciones se realizan sobre el objeto vector_store y se consumen de forma directa desde el SDK oficial de Python mediante el cliente OpenAI.
En los ejemplos siguientes se asume que la clave de API ya está configurada en el entorno y que se ha creado un cliente básico de la forma recomendada por la documentación oficial.
1. Crear un vector store
Crear un vector store es el primer paso para organizar el conocimiento que se indexará después. En este momento es habitual asignarle un nombre claro, añadir metadatos y, si procede, establecer una política de expiración para evitar que el almacén permanezca activo indefinidamente.
from openai import OpenAI
client = OpenAI()
# Crear un vector store para documentación interna
vector_store = client.vector_stores.create(
name="documentacion_interna",
metadata={"area": "it", "entorno": "produccion"},
)
print(vector_store.id) # Identificador único del vector store
print(vector_store.name) # Nombre legible asignado
En la respuesta se obtiene un objeto vector_store con campos como id, name, created_at, metadata y contadores básicos de archivos, lo que permite integrar rápidamente este almacén en el resto de la aplicación.
2. Consultar un vector store por id
Una vez creado un vector store, resulta frecuente querer inspeccionar su estado o recuperar su configuración para mostrarla en una herramienta interna de administración. Para ello se utiliza la operación de recuperación por identificador, que devuelve el objeto completo asociado a ese almacén.
vector_store_id = "vs_abc123"
# Recuperar la información de un vector store existente
vector_store = client.vector_stores.retrieve(vector_store_id)
print(vector_store.name) # Nombre actual
print(vector_store.metadata) # Metadatos asociados
Este patrón de lectura es útil tanto en scripts de mantenimiento como en paneles donde se muestran los distintos almacenes de conocimiento y su configuración actual.
3. Listar vector stores de un proyecto
En proyectos reales suele haber varios vector stores, por ejemplo separados por dominio funcional (soporte, producto, legal) o por entorno (desarrollo, preproducción, producción). La operación de listado permite obtener un conjunto paginado de estos recursos y aplicar lógica de gobernanza o limpieza sobre ellos.
# Listar los primeros vector stores disponibles
resultado = client.vector_stores.list(limit=10)
for store in resultado.data:
print(store.id, store.name)
Este listado facilita tareas como localizar almacenes antiguos, revisar su nomenclatura o identificar aquellos que deberían consolidarse por razones de mantenimiento.
4. Actualizar nombre o metadatos de un vector store
A medida que evoluciona una solución, puede ser necesario renombrar un vector store, ajustar sus metadatos o reflejar cambios de entorno sin recrear el almacén desde cero. La operación de actualización permite modificar campos como name y metadata sobre un recurso ya existente.
vector_store_id = "vs_abc123"
# Actualizar la información de un vector store existente
vector_store_actualizado = client.vector_stores.update(
vector_store_id=vector_store_id,
name="documentacion_interna_v2",
metadata={"area": "it", "entorno": "preproduccion"},
)
print(vector_store_actualizado.name)
print(vector_store_actualizado.metadata.get("entorno"))
El uso coherente de los metadatos ayuda a clasificar los distintos almacenes por dominio, entorno o nivel de confidencialidad, haciendo más sencillo interpretar su función sin necesidad de inspeccionar directamente los datos que contienen.
5. Eliminar un vector store que ya no se utiliza
Cuando un vector store deja de ser necesario, conviene eliminarlo para liberar recursos y simplificar la gestión del proyecto. La operación de borrado elimina el recurso identificado por su id y hace que deje de estar disponible para futuras operaciones.
vector_store_id = "vs_abc123"
# Eliminar definitivamente un vector store
client.vector_stores.delete(vector_store_id)
En entornos profesionales es frecuente combinar esta operación con políticas internas de retención de datos, de manera que los vector stores se eliminen o roten de forma controlada cuando se sustituyen versiones antiguas de la base de conocimiento o cuando expira su periodo de uso previsto.
En la documentación oficial de la API de Vector Stores de OpenAI se detallan todos los campos y parámetros disponibles, incluidos los relacionados con límites, almacenamiento y estrategias de fragmentación. A partir de estas operaciones básicas se construyen más adelante flujos de trabajo centrados en búsqueda semántica y recuperación de información, que se apoyan precisamente en la correcta definición y gestión de estos almacenes.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
- Comprender qué son los vector stores y su función en la gestión de información semántica.
- Aprender el proceso de creación, carga y gestión de archivos en vector stores mediante la API de OpenAI.
- Entender el funcionamiento interno de la búsqueda por similitud vectorial y la indexación automática.
- Conocer la metodología RAG (Retrieval-Augmented Generation) y su implementación con vector stores para mejorar la generación de respuestas.
- Explorar las ventajas y opciones de personalización que ofrece el uso de vector stores y RAG gestionados por OpenAI.