Local Shell: ejecutar comandos de shell desde tus modelos
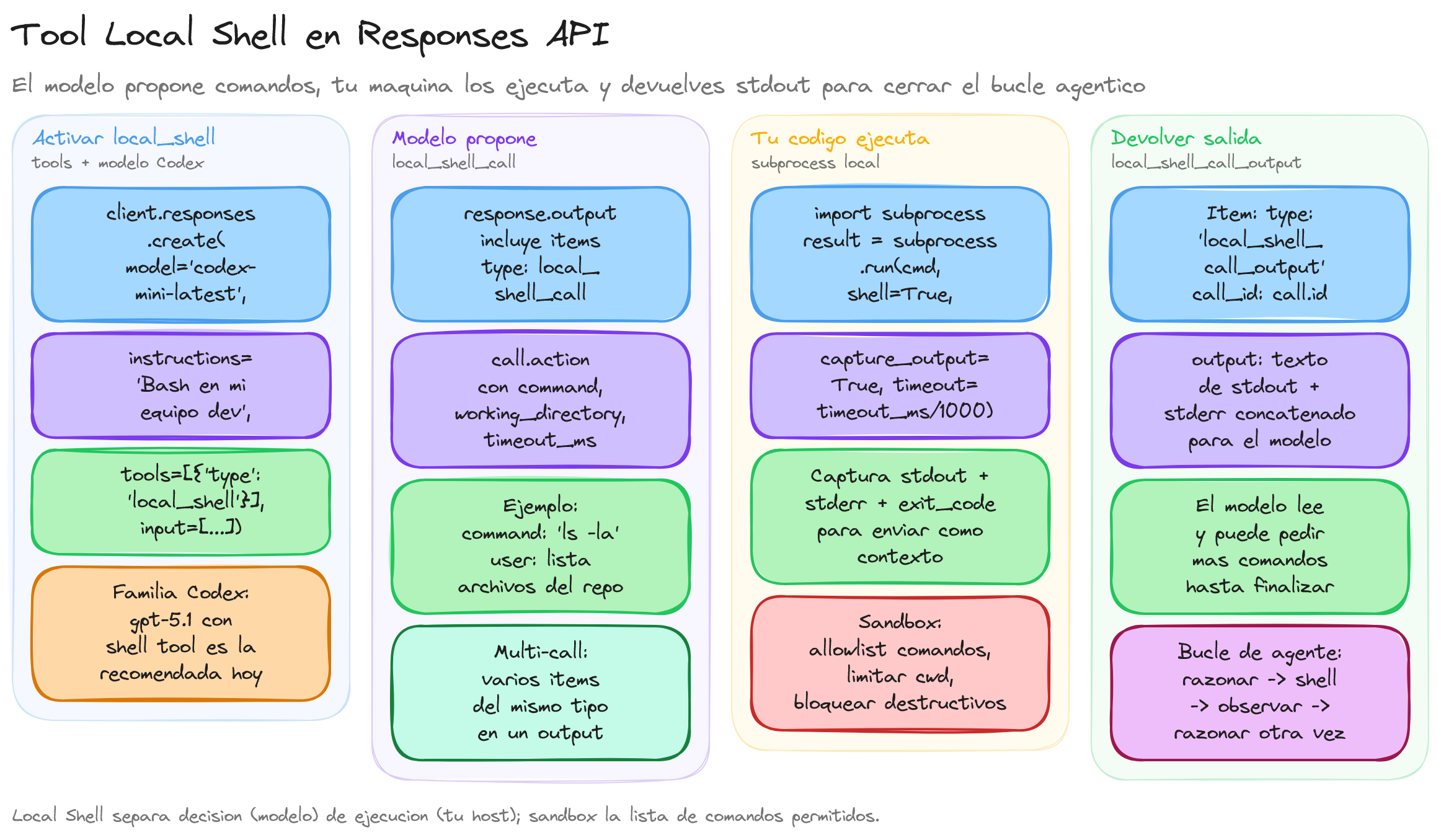
La herramienta Local Shell es una tool integrada de OpenAI que permite que un modelo genere y orqueste comandos de shell que se ejecutan en una máquina controlada por ti, no en la infraestructura de OpenAI. Esta herramienta resulta especialmente útil cuando quieres que un asistente de código o de automatización sea capaz de trabajar directamente con tu entorno, por ejemplo para listar archivos, ejecutar tests o lanzar pequeños scripts.
Aunque la documentación actual de OpenAI recomienda la herramienta shell con modelos como GPT‑5.1 para nuevos desarrollos, Local Shell sigue siendo relevante para entender el patrón de agente que habla con un terminal y para integraciones ya existentes basadas en Codex. En esta sección nos centraremos en cómo funciona Local Shell, cómo se configura en la API de Responses y qué precauciones de seguridad debes tener en cuenta.
Arquitectura y flujo general
La idea central de Local Shell es separar de forma clara quién decide el comando y quién lo ejecuta realmente. El modelo propone qué hacer, pero el proceso que lanza el comando se ejecuta en tu máquina local, en un contenedor o en un servidor que tú controlas.
De forma simplificada, el flujo se puede entender como un pequeño bucle de agente:
-
1. El modelo propone comandos: en la respuesta del modelo aparecen elementos de tipo local_shell_call que incluyen, por ejemplo, un comando
"command": "ls -la"y metadatos como"working_directory"o"timeout_ms". -
2. Tu código ejecuta el comando: tu aplicación lee esa llamada, ejecuta el comando en el sistema operativo mediante una librería como subprocess en Python y captura la salida estándar y de error.
-
3. Devuelves la salida al modelo: tu código envía de vuelta un elemento local_shell_call_output con el
call_idoriginal y el texto de salida, para que el modelo pueda seguir razonando con esa información. -
4. El bucle continúa: el modelo puede pedir nuevos comandos, inspeccionar resultados, modificar archivos o parar cuando considere que ya ha llegado a la respuesta final para el usuario.
Este patrón convierte al modelo en el cerebro que planifica y al proceso local en las manos que ejecutan operaciones reales sobre tu entorno.
Primera llamada con la tool local_shell
Para usar Local Shell con la API de Responses necesitas:
- Un modelo compatible, típicamente un modelo de la familia Codex, por ejemplo
"codex-mini-latest". - Declarar la tool incorporada con
{"type": "local_shell"}. - Proporcionar un mensaje de usuario que explique qué quieres que haga el asistente en tu entorno local.
Un ejemplo mínimo en Python sería:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="codex-mini-latest",
instructions="El entorno de shell local es una terminal bash en mi equipo de desarrollo.",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "Lista los archivos del directorio actual y dime si ves un archivo README.",
}
],
}
],
tools=[{"type": "local_shell"}],
)
En esta primera llamada el modelo ya sabe que dispone de la herramienta local_shell y que está hablando con un entorno de shell concreto, lo que le permite proponer comandos coherentes con tu sistema operativo y tu estructura de proyecto.
Implementar el bucle con local_shell_call
La clave práctica de Local Shell está en cómo procesas las tool calls que devuelve la respuesta. El objeto response.output contiene elementos heterogéneos, entre ellos las llamadas de tipo local_shell_call que indican qué comando ejecutar.
Un esquema típico de bucle en Python sería:
import os
import shlex
import subprocess
while True:
shell_calls = []
for item in response.output:
item_type = getattr(item, "type", None)
if item_type == "local_shell_call":
shell_calls.append(item)
elif item_type == "tool_call" and getattr(item, "tool_name", None) == "local_shell":
shell_calls.append(item)
if not shell_calls:
break # El modelo ya no quiere ejecutar más comandos
call = shell_calls[0]
args = getattr(call, "action", None) or getattr(call, "arguments", None)
En este fragmento se filtran los elementos de salida que representan llamadas a Local Shell, agrupándolos en la lista shell_calls. Si no hay más llamadas el bucle termina, lo que normalmente significa que el modelo ya ha generado una respuesta final para el usuario.
El siguiente paso es traducir esa llamada en una ejecución real de shell:
def _get(obj, key, default=None):
if isinstance(obj, dict):
return obj.get(key, default)
return getattr(obj, key, default)
timeout_ms = _get(args, "timeout_ms")
command = _get(args, "command")
if not command:
break
if isinstance(command, str):
command = shlex.split(command)
completed = subprocess.run(
command,
cwd=_get(args, "working_directory") or os.getcwd(),
env={**os.environ, **(_get(args, "env") or {})},
capture_output=True,
text=True,
timeout=(timeout_ms / 1000) if timeout_ms else None,
)
Aquí se extrae el comando, se convierte a lista si es una cadena y se ejecuta con subprocess.run, respetando el directorio de trabajo, las variables de entorno adicionales y un posible timeout. De esta forma controlas explícitamente dónde y cómo se ejecutan los comandos, algo crucial desde el punto de vista de la seguridad.
Una vez ejecutado el comando, devuelves el resultado al modelo para que pueda seguir trabajando:
output_item = {
"type": "local_shell_call_output",
"call_id": getattr(call, "call_id", None),
"output": completed.stdout + completed.stderr,
}
response = client.responses.create(
model="codex-mini-latest",
tools=[{"type": "local_shell"}],
previous_response_id=response.id,
input=[output_item],
)
print(response.output_text)
El campo call_id vincula la salida con la llamada original, y el modelo puede decidir si necesita nuevos comandos o si ya puede responder al usuario con una explicación más elaborada, por ejemplo resumiendo los resultados de varios comandos encadenados.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender la arquitectura agente-terminal de Local Shell, implementar en Python el bucle de ejecución de comandos a partir de local_shell_call y devolver resultados con local_shell_call_output, aplicando buenas prácticas de seguridad al exponer un shell local a modelos de OpenAI.