Habilitar Streaming de respuestas
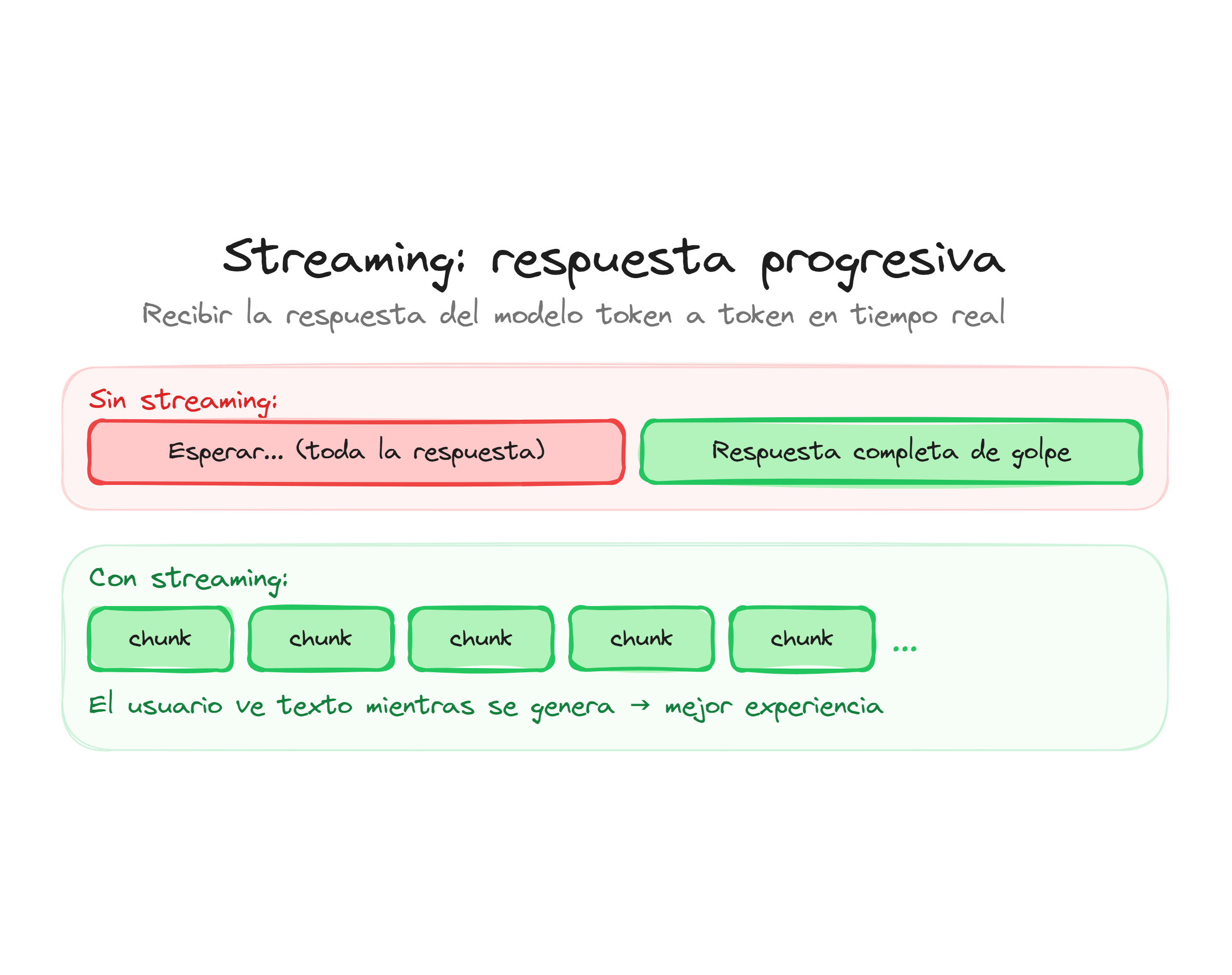
El streaming de respuestas permite que las salidas del modelo se transmitan gradualmente, en lugar de esperar a que el modelo genere la respuesta completa. De forma predeterminada, la API espera a que se complete toda la generación antes de devolver una respuesta, lo que puede resultar en tiempos de espera prolongados para salidas extensas. Al habilitar el streaming, puedes comenzar a procesar y mostrar el contenido casi instantáneamente mientras el modelo continúa generando en segundo plano.
Activar el streaming
Para habilitar streaming, establece el parámetro stream=True en tu solicitud al endpoint de Responses. Esta es la forma más directa de acceder a las capacidades de transmisión de datos:
from openai import OpenAI
client = OpenAI()
stream = client.responses.create(
model="gpt-5.4",
input=[
{
"role": "user",
"content": "Explica en detalle cómo funcionan los transformers en el aprendizaje automático.",
},
],
stream=True,
)
for event in stream:
print(event)
Con stream=True, en lugar de recibir una respuesta única y completa, obtienes un iterador de eventos. Cada evento representa un cambio o actualización en el estado de la generación: desde la creación inicial de la respuesta, pasando por fragmentos de texto que se generan progresivamente, hasta eventos finales de finalización.
Estructura de datos en streaming
Cuando activas el streaming, la respuesta se convierte en un objeto iterable que emite eventos tipificados según su contenido. Cada evento contiene información específica sobre el estado de la generación. Los eventos principales que recibirás incluyen:
- Eventos de ciclo de vida: como
response.createdal iniciar la generación, eresponse.completedcuando todo termina - Eventos de contenido: como
response.output_text.delta, que transmiten fragmentos de texto conforme se generan - Eventos de error: si algo falla durante la generación, recibirás un evento
error
Patrón de iteración
El patrón de streaming sigue una estructura clara. Configuras el parámetro, ejecutas la solicitud y luego iteras sobre los eventos que llegan:
import OpenAI from "openai";
const client = new OpenAI();
const stream = await client.responses.create({
model: "gpt-5.4",
input: [
{
role: "user",
content: "Describe las técnicas modernas de optimización en redes neuronales.",
},
],
stream: true,
});
for await (const event of stream) {
console.log(event);
}
Observa que el bucle de iteración es el mismo, solo que la sintaxis varía según el lenguaje: en Python usamos for event in stream, mientras que en JavaScript usamos for await (const event of stream). Esta diferencia es importante porque el streaming en JavaScript es inherentemente asincrónico.
Casos de uso del streaming
El streaming es especialmente útil en escenarios donde la latencia es crítica o donde el usuario se beneficia de ver la progresión de la generación. Por ejemplo, en una aplicación de chatbot, puedes mostrar las respuestas conforme se generan en lugar de hacer que el usuario espere en una pantalla en blanco. Del mismo modo, en herramientas de análisis, el streaming permite que los usuarios comiencen a revisar resultados parciales mientras el modelo sigue procesando.
La activación del streaming no requiere configuración adicional más allá del parámetro stream=True. Todo lo demás—incluyendo el modelo, los parámetros de temperatura o los límites de tokens—funciona exactamente igual que en una solicitud sin streaming. La diferencia radical está en cómo recibes y consumes la respuesta, no en cómo la generas.
Lectura de respuestas con Streaming
Una vez que activas el streaming, procesar los eventos correctamente es clave para extraer la información que necesitas de la generación progresiva del modelo. No todos los eventos contienen los mismos datos, por lo que es importante identificar qué tipo de evento recibes y cómo acceder a su contenido de forma segura.
Identificar tipos de eventos
El SDK de OpenAI tipifica cada evento automáticamente, lo que significa que puedes saber exactamente qué información contiene cada uno. Los eventos más relevantes durante una generación típica son:
**response.created** marca el inicio de la generación. Se emite una sola vez al principio y contiene metadatos sobre la respuesta como su identificador único.
**response.output_text.delta** es el evento que transporta los fragmentos de texto generados. Cada vez que el modelo genera un trozo nuevo de texto, recibes uno de estos eventos con ese fragmento específico en el campo delta.
**response.completed** señala que la generación ha terminado. Se emite una única vez al final y contiene la respuesta final completa, información de tokens utilizados, y otros metadatos.
**error** aparece si algo falla durante la generación. Contiene detalles sobre qué salió mal.
Construir la respuesta completa desde deltas
El patrón típico es acumular los fragmentos de texto delta en una variable para reconstruir la respuesta completa a medida que llegan. Este enfoque es especialmente útil en aplicaciones interactivas donde quieres mostrar el texto mientras se genera:
from openai import OpenAI
client = OpenAI()
stream = client.responses.create(
model="gpt-5.4",
input=[
{
"role": "user",
"content": "¿Cuáles son las fases del ciclo de vida del desarrollo de software?",
},
],
stream=True,
)
full_response = ""
for event in stream:
if event.type == "response.output_text.delta":
# El delta contiene el fragmento de texto nuevo
text_chunk = event.delta
full_response += text_chunk
# Mostrar el fragmento inmediatamente (sin esperar al final)
print(text_chunk, end="", flush=True)
En este ejemplo, cada response.output_text.delta contiene un delta con el texto que se acaba de generar. Al usar flush=True en print, el texto aparece instantáneamente en pantalla, dando la sensación de que el modelo está escribiendo en tiempo real.
Filtrar y procesar eventos específicos
Frecuentemente solo te interesan ciertos tipos de eventos. Puedes filtrar sobre la marcha según el atributo type de cada evento:
from openai import OpenAI
client = OpenAI()
stream = client.responses.create(
model="gpt-5.4",
input=[
{
"role": "user",
"content": "Resume las ventajas del aprendizaje automático.",
},
],
stream=True,
)
for event in stream:
# Procesar solo los eventos de texto
if hasattr(event, "type") and event.type == "response.output_text.delta":
print(event.delta, end="")
# Procesar cuando la generación termine
elif hasattr(event, "type") and event.type == "response.completed":
print(f"\n\nGeneración completada")
Esta técnica permite que tu código se enfoque únicamente en los eventos relevantes, ignorando los demás sin procesarlos innecesariamente.
Acceder a metadatos de la respuesta
Los eventos de ciclo de vida contienen información adicional más allá del texto. Por ejemplo, cuando recibes response.created, puedes acceder al identificador de la respuesta:
import OpenAI from "openai";
const client = new OpenAI();
const stream = await client.responses.create({
model: "gpt-5.4",
input: [
{
role: "user",
content: "Explica brevemente qué es una API.",
},
],
stream: true,
});
for await (const event of stream) {
if (event.type === "response.created") {
console.log(`ID de respuesta: ${event.id}`);
console.log(`Modelo: ${event.model}`);
}
if (event.type === "response.output_text.delta") {
process.stdout.write(event.delta);
}
if (event.type === "response.completed") {
console.log(`\nTokens de entrada: ${event.usage.input_tokens}`);
console.log(`Tokens de salida: ${event.usage.output_tokens}`);
}
}
De esta forma, captas tanto el contenido generado como información operativa sobre cuántos tokens se consumieron, el modelo usado, y otros detalles técnicos.
Manejar errores durante el streaming
Aunque el streaming sea fluido, pueden surgir errores en cualquier momento. Es importante capturarlos y reaccionar apropiadamente:
from openai import OpenAI
client = OpenAI()
try:
stream = client.responses.create(
model="gpt-5.4",
input=[
{
"role": "user",
"content": "¿Cuáles son los principales paradigmas de programación?",
},
],
stream=True,
)
for event in stream:
if event.type == "error":
print(f"Error durante la generación: {event.error.message}")
break
elif event.type == "response.output_text.delta":
print(event.delta, end="")
except Exception as e:
print(f"Excepción en el streaming: {str(e)}")
Los eventos de error dentro del stream tienen prioridad y permiten que discontinúes la iteración de forma controlada si algo falla.
Patrones avanzados: estadísticas en tiempo real
El streaming permite realizar análisis mientras la respuesta se genera, sin esperar al final. Por ejemplo, contar palabras o caracteres:
from openai import OpenAI
client = OpenAI()
stream = client.responses.create(
model="gpt-5.4",
input=[
{
"role": "user",
"content": "Describe tres beneficios de la computación en la nube.",
},
],
stream=True,
)
word_count = 0
character_count = 0
for event in stream:
if event.type == "response.output_text.delta":
delta = event.delta
character_count += len(delta)
word_count += len(delta.split())
print(delta, end="", flush=True)
print(f"\n\nPalabras generadas: {word_count}")
print(f"Caracteres generados: {character_count}")
Este enfoque demuestra la flexibilidad de trabajar con datos parciales en lugar de solo con la respuesta final completa.
Optimización de latencia y costes con streaming
El streaming es una herramienta clave para mejorar la latencia percibida por el usuario sin cambiar el coste base de los tokens procesados. Aunque el precio por token es el mismo con y sin streaming, poder empezar a mostrar contenido en milisegundos reduce la sensación de espera y permite al usuario decidir antes si necesita seguir generando texto o puede detener la respuesta.
Una ventaja práctica del streaming en términos de costes es que puedes cortar la generación cuando ya tienes información suficiente, evitando tokens de salida innecesarios. En una interfaz basada en terminal o en una aplicación web, esto se traduce en dejar de iterar sobre el stream cuando detectas cierta condición, como haber alcanzado un número máximo de caracteres o cuando el modelo ya ha contestado a la pregunta principal.
1. Cortar el streaming para ahorrar tokens:
from openai import OpenAI
client = OpenAI()
def respuesta_rapida(prompt, max_caracteres=600):
stream = client.responses.create(
model="gpt-5.4-mini",
input=prompt,
stream=True,
)
acumulado = ""
for event in stream:
if event.type == "response.output_text.delta":
delta = event.delta
acumulado += delta
print(delta, end="", flush=True)
if len(acumulado) >= max_caracteres:
# Dejamos de consumir el stream para no generar más tokens de salida
break
return acumulado
Con este patrón mantienes la latencia baja y controlas mejor el número de tokens de salida, algo especialmente útil cuando tus usuarios suelen hacer preguntas abiertas que podrían dar lugar a respuestas muy largas.
2. Reducir picos de latencia en aplicaciones interactivas:
En una API síncrona clásica, todas las peticiones largas compiten por el mismo presupuesto de rate limits, y cualquier retraso se traduce directamente en mala experiencia de usuario. Al activar streaming en tus endpoints HTTP (por ejemplo, en un backend FastAPI), puedes enviar al navegador los fragmentos de texto a medida que llegan y liberar antes los hilos de tu servidor, mejorando la capacidad de concurrencia sin cambiar tu configuración de modelos ni parámetros de coste.
Fuentes y referencias
Documentación oficial y recursos externos para profundizar en OpenAI SDK
Documentación oficial de OpenAI SDK
Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es el streaming de respuestas y sus ventajas. Aprender a activar el streaming mediante el parámetro stream=True. Identificar y procesar los diferentes tipos de eventos emitidos durante el streaming. Implementar patrones para reconstruir respuestas completas a partir de fragmentos transmitidos. Manejar errores y extraer metadatos durante la transmisión de datos.