Entender los rate limits en OpenAI
Los rate limits son las cuotas que OpenAI aplica para controlar cuántas solicitudes y cuántos tokens puede consumir tu organización en un periodo de tiempo determinado. No son un castigo, sino un mecanismo de protección que garantiza la estabilidad del servicio para todos los clientes y te ayuda a planificar el consumo de la API de forma predecible.
Cada organización dispone de límites diferentes según su historial de uso, método de pago y acuerdos comerciales, y esos límites se aplican por modelo y por tipo de recurso. Además, OpenAI clasifica a los clientes en distintos tiers de capacidad (por ejemplo, cuentas de prueba, pay‑as‑you‑go o enterprise) y cada tier tiene valores distintos para sus cuotas de consumo, así como opciones diferentes a la hora de solicitar ampliaciones.
En el panel de configuración de OpenAI puedes ver tus cuotas de requests per minute (RPM), tokens per minute (TPM) y, en algunos casos, límites diarios adicionales para recursos como imágenes, audio o batch. Desde ese mismo panel puedes revisar en qué tier se encuentra tu organización y qué pasos son necesarios para optar a límites superiores si tu caso de uso lo requiere.
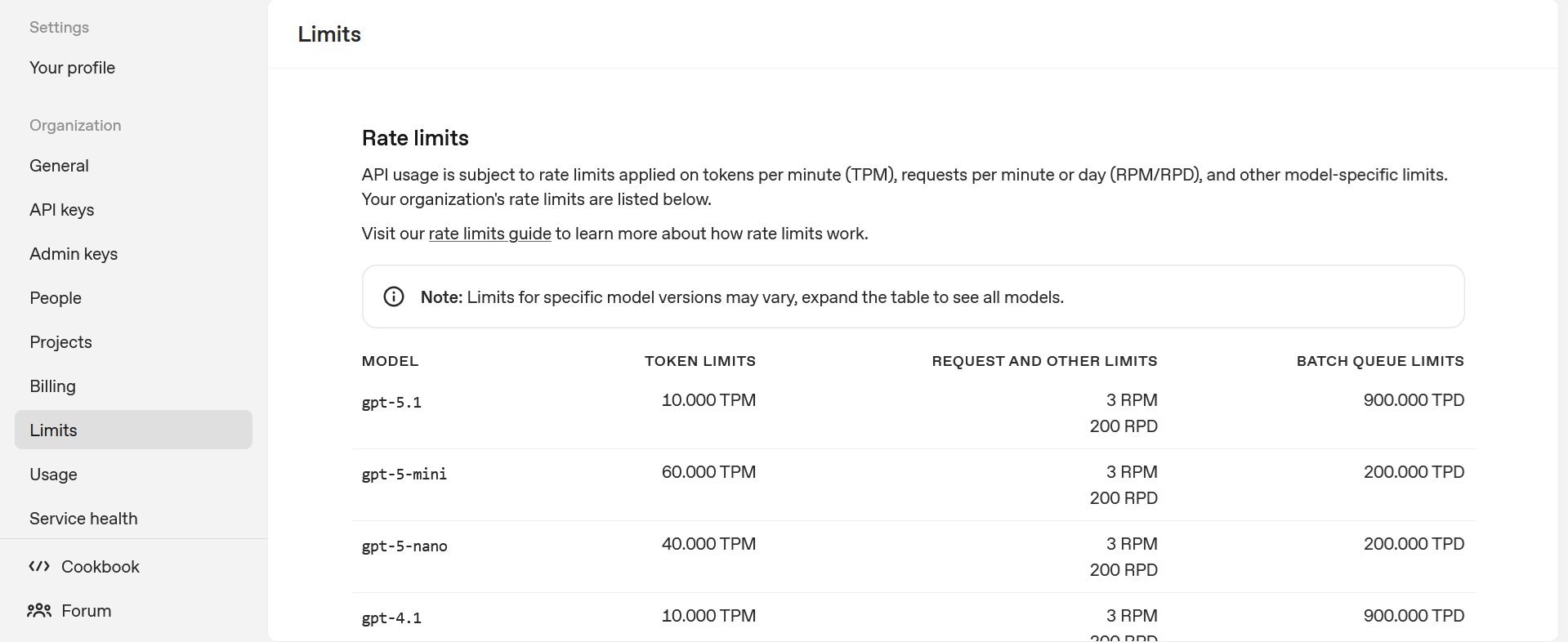
Tipos de límites habituales
En la práctica trabajarás con tres tipos de límites que afectan directamente al diseño de tus clientes en Python:
-
1. Límites por solicitudes (RPM): controlan cuántas peticiones puedes enviar por minuto a un determinado modelo o familia de modelos, y son los que más se notan cuando disparas muchas peticiones en paralelo.
-
2. Límites por tokens (TPM): limitan cuántos tokens de entrada y de salida puedes procesar por minuto; si envías prompts muy largos o generas respuestas extensas, este suele ser el cuello de botella real.
-
3. Límites específicos por recurso: algunos servicios como imágenes, audio o Batch API tienen buckets de rate limits separados; esto te permite descargar parte de la carga de tus endpoints síncronos a procesos batch sin consumir los mismos límites.
Cuando superas cualquiera de estos límites, la API responde con errores HTTP 429, que indican que necesitas reducir la velocidad de tus llamadas, espaciar las peticiones o mover parte del trabajo a mecanismos como Batch API o background mode.
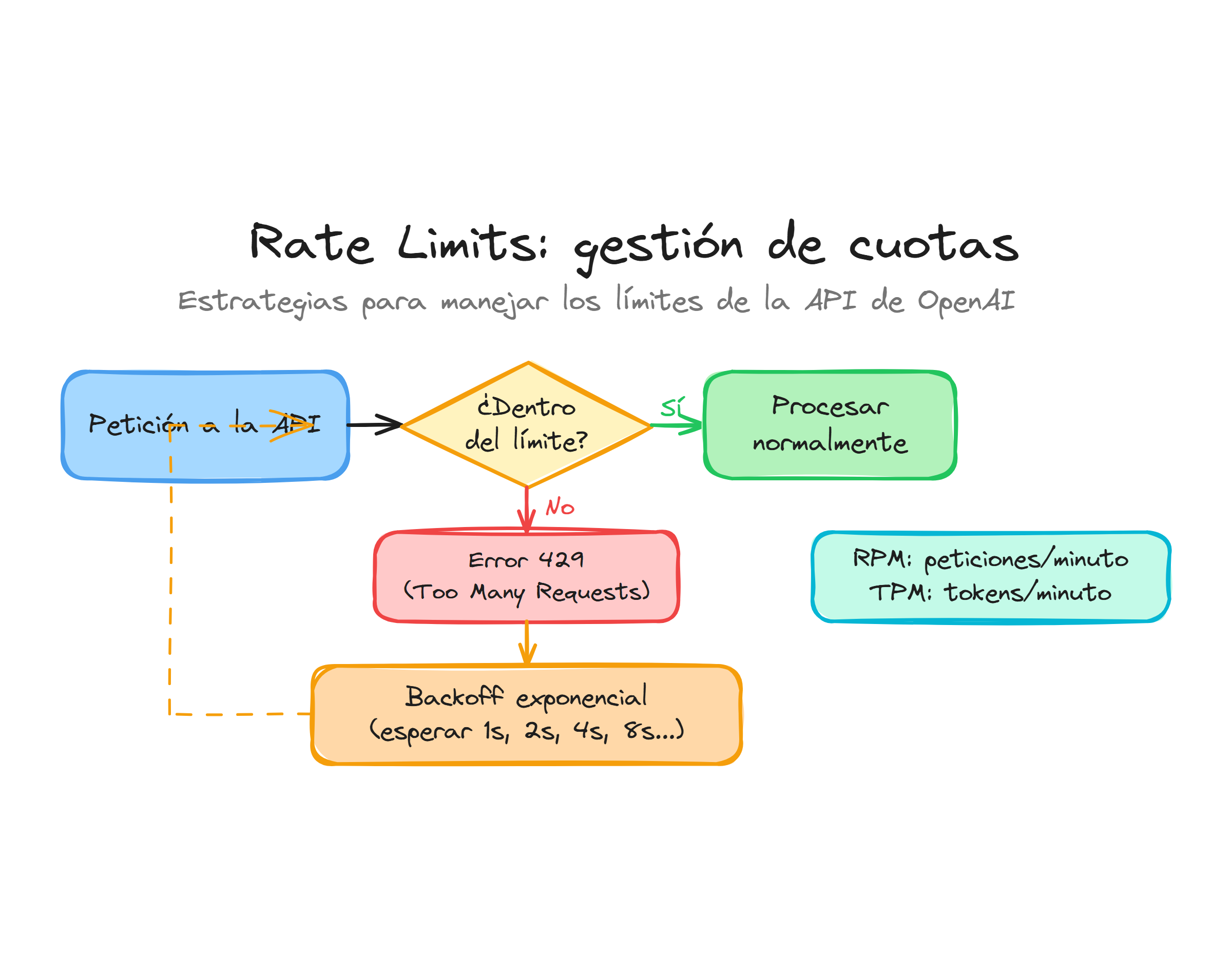
Detectar errores de rate limit desde Python
Desde el SDK oficial de Python puedes detectar excedentes de rate limit inspeccionando las excepciones que lanza el cliente. Un patrón básico consiste en capturar APIError, comprobar el status_code y utilizar la cabecera Retry-After para decidir cuánto esperar antes de reintentar.
import time
from openai import OpenAI, APIError
client = OpenAI()
def llamar_modelo_con_reintentos(prompt, max_reintentos=5):
espera = 1.0 # segundos
for intento in range(max_reintentos):
try:
response = client.responses.create(
model="gpt-5.4-mini",
input=prompt,
)
return response.output_text
except APIError as e:
if e.status_code == 429 and intento < max_reintentos - 1:
# Intentar respetar Retry-After si está disponible
headers = getattr(e, "response", None)
retry_after = None
if headers and hasattr(headers, "headers"):
retry_after = headers.headers.get("Retry-After")
if retry_after is not None:
espera = float(retry_after)
print(f"Rate limit excedido, reintentando en {espera:.1f}s...")
time.sleep(espera)
espera = min(espera * 2, 60.0)
else:
raise
raise RuntimeError("No se pudo completar la llamada sin exceder los rate limits")
Este patrón de backoff exponencial reduce la presión sobre la API y suele ser suficiente para servicios de baja o media concurrencia. En sistemas con mucho tráfico necesitarás complementar esta lógica con colas de trabajo y control explícito de concurrencia, de forma que el número de peticiones simultáneas nunca supere tu presupuesto de RPM y TPM.
Controlar la concurrencia y respetar las cuotas
Para evitar choques constantes con los rate limits, es recomendable centralizar todas las llamadas a OpenAI en un componente que actúe como puerta de entrada. Ese componente se encarga de limitar la concurrencia, aplicar reintentos y mantener un pequeño buffer de peticiones en cola cuando llegas al máximo de tu capacidad.
Un enfoque sencillo en Python para scripts o servicios modestos es usar un semáforo que limite el número de llamadas simultáneas al cliente:
import asyncio
from openai import OpenAI
client = OpenAI()
semaforo = asyncio.Semaphore(5) # máximo 5 peticiones concurrentes
async def llamada_controlada(prompt: str) -> str:
async with semaforo:
response = await client.responses.create_async(
model="gpt-5.4-mini",
input=prompt,
)
return response.output_text
En aplicaciones más grandes resulta habitual combinar este patrón con una cola (por ejemplo, Redis, RabbitMQ o una tabla de base de datos) y uno o varios workers que van consumiendo trabajo a la velocidad que permiten tus cuotas. De esta forma evitas picos de tráfico que provocarían errores 429 y consigues que la latencia media de las peticiones importantes sea más estable.
Estrategias para optimizar costes y latencia sin chocar con los límites
La gestión de rate limits está directamente relacionada con la optimización de costes y latencia. Si diseñas tus clientes pensando en estos límites, reduces el número de errores, de reintentos y de llamadas innecesarias a la API.
- 1. Reducir tokens de entrada y salida:
Cuantos menos tokens envíes y recibas, menos cerca estarás de tus TPM y menos pagarás por cada petición. Utiliza prompts más ajustados, recorta contexto irrelevante y limita max_output_tokens cuando no necesites respuestas largas.
- 2. Usar streaming para mejorar latencia percibida:
El streaming no cambia el coste base, pero reduce el tiempo hasta el primer token y te permite cortar la generación cuando ya tienes suficiente información. Esto mejora la experiencia de usuario y, si cortas pronto, también disminuye la cantidad total de tokens de salida.
- 3. Descargar trabajo masivo a Batch API:
Para grandes volúmenes de peticiones donde la latencia no es crítica, mueve el trabajo a Batch API, que ofrece un 50% de descuento y utiliza límites de tasa separados. De este modo liberas tus cuotas síncronas para las peticiones realmente interactivas.
- 4. Combinar background mode con colas de trabajo:
El modo background permite ejecutar tareas largas sin bloquear tu backend ni tus usuarios. Al procesar estas tareas en segundo plano en uno o varios workers, puedes ajustar el número de procesos simultáneos al presupuesto de rate limits de tu organización, manteniendo un equilibrio entre tiempo total de procesamiento y coste operativo.
- 5. Monitorizar uso y errores 429:
Registra sistemáticamente la información de usage de cada respuesta y los errores 429 que recibes, de modo que puedas detectar patrones de saturación. A partir de esos datos podrás ajustar el tamaño de tus lotes, el paralelismo máximo aceptable y la conveniencia de migrar determinadas cargas de trabajo a Batch API o a modelos más ligeros.
Trabajar de forma consciente con los rate limits te obliga a diseñar clientes de OpenAI más robustos, con colas, backoff y control de concurrencia. A cambio obtienes una plataforma más estable, menor latencia en los casos de uso interactivos y un control mucho más fino de los costes asociados a tus aplicaciones de inteligencia artificial.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender los tipos de rate limits de OpenAI: RPM, TPM y limites por recurso. Detectar errores 429 desde Python y aplicar reintentos con backoff exponencial y Retry-After. Controlar la concurrencia de peticiones mediante semaforos y colas de trabajo. Aplicar estrategias de optimización de costes: reducir tokens, streaming, Batch API y modo background. Monitorizar el uso de tokens y errores 429 para ajustar el paralelismo y la distribucion de carga.