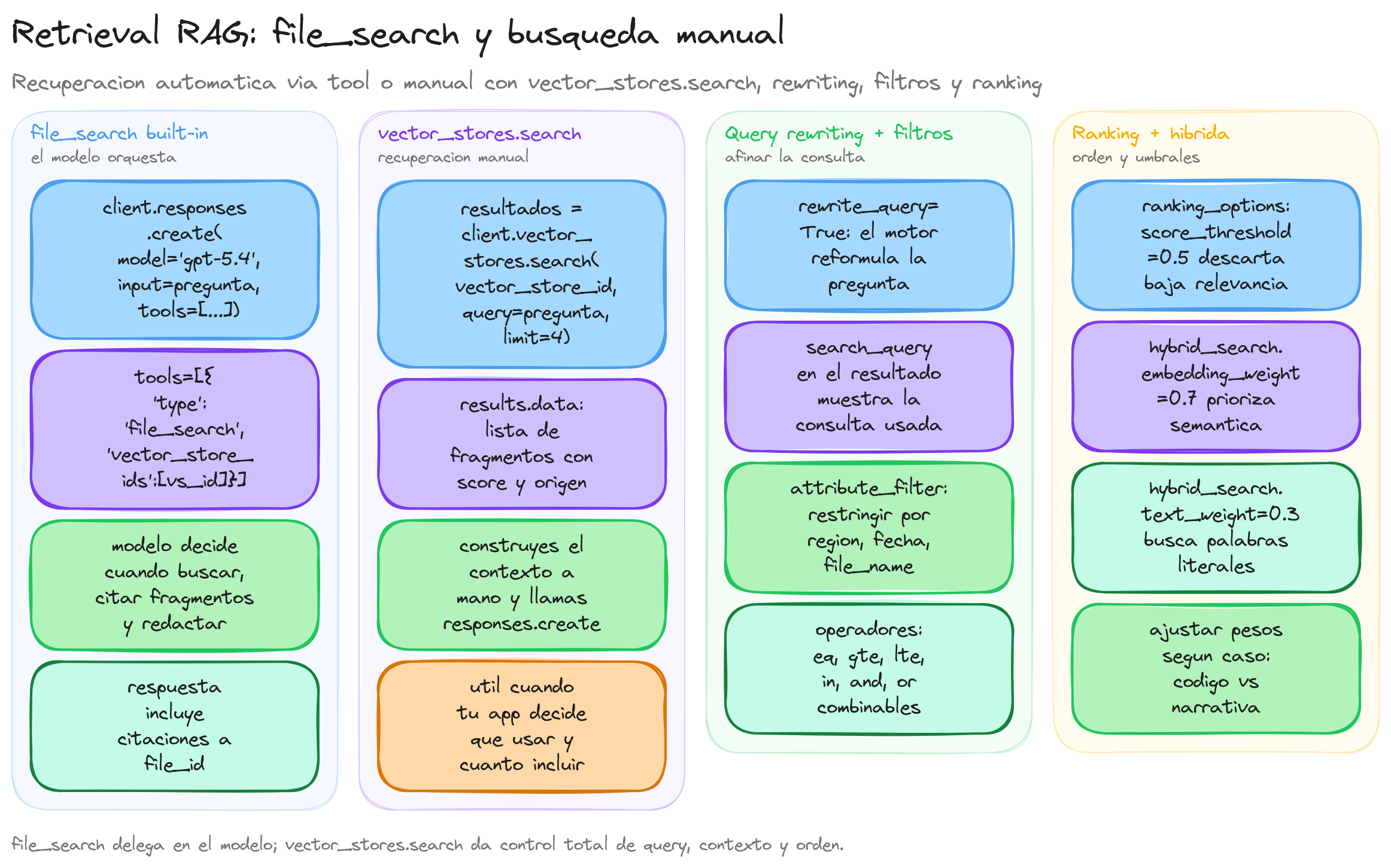
File Search
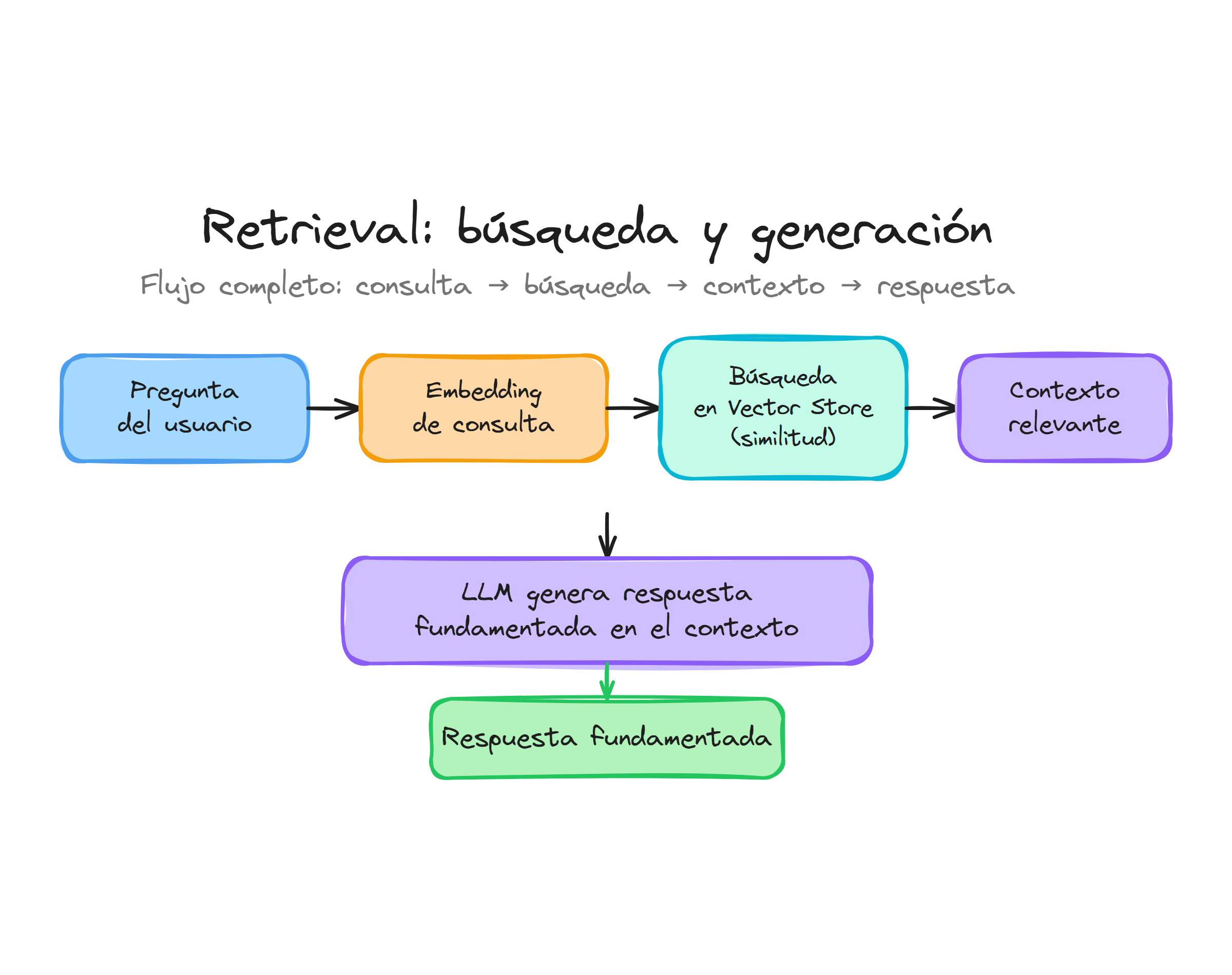
La técnica de RAG se apoya en dos pasos: primero se recupera información relevante de una base de conocimiento y después el modelo genera la respuesta usando ese contexto. Con la herramienta file_search este flujo se gestiona casi por completo desde la plataforma, ya que el modelo decide cuándo buscar, qué fragmentos usar y cómo citarlos dentro de la respuesta.
En este enfoque trabajamos con tres piezas: un vector store que ya contiene nuestros documentos, la tool file_search que sabe cómo consultar ese almacén y una llamada a la API que activa el uso de la herramienta dentro del modelo. La idea es que tu código se centre en definir los documentos disponibles y el rol del asistente, mientras que OpenAI se encarga de los detalles de recuperación.
- 1. Crear o reutilizar un vector store con tus documentos:
El primer paso práctico consiste en preparar el vector store que actuará como base de conocimiento. Partiendo de que ya dominas su gestión, aquí solo mostramos un ejemplo mínimo de creación y carga de un archivo para usarlo después con file_search.
from openai import OpenAI
client = OpenAI()
# Crear un vector store para la base de conocimiento
vector_store = client.vector_stores.create(
name="base_conocimiento_soporte",
)
# Subir e indexar un documento al vector store
with open("faq_suscripciones.pdf", "rb") as f:
client.vector_stores.files.upload_and_poll(
vector_store_id=vector_store.id,
file=f,
)
Aquí el método upload_and_poll se ocupa de subir el archivo, fragmentarlo, generar embeddings y dejarlo listo para ser usado en las consultas de búsqueda posteriores.
- 2. Consulta con file search:
Una vez que el vector store está disponible, se define un asistente que conoce la herramienta file_search y está conectado a ese almacén concreto. De este modo, cada vez que el asistente necesite contexto adicional, podrá invocar la herramienta sin que tengas que gestionar manualmente las búsquedas.
response = client.responses.create(
model="gpt-5.4",
input="¿Cuánto vale la suscripción mensual?",
tools=[{
"type": "file_search",
"vector_store_ids": [vector_store.id] # aquí ponemos los ids de los vector_store
}]
)
print(response)
En este punto el LLM puede llamar a file_search y que dispone de un vector store concreto que actúa como base de conocimiento autorizada.
Vector Store search
En algunos escenarios puedes preferir un enfoque de RAG más manual, en el que tu aplicación controle explícitamente qué se busca, cuántos fragmentos se utilizan y cómo se construye el contexto que verá el modelo.
Para estos casos, la API expone el método search sobre los vector stores, que permite recuperar directamente los fragmentos más relevantes para una consulta.
La idea general es separar el flujo en dos pasos: primero se llama a client.vector_stores.search para obtener los mejores fragmentos y, a continuación, se pasa ese contenido como contexto a una llamada normal al modelo de lenguaje.
- 1. Buscar fragmentos relevantes en el vector store:
Partiendo de un vector store ya cargado con tus documentos, se puede lanzar una búsqueda semántica utilizando una pregunta en lenguaje natural. La API devuelve los fragmentos ordenados por relevancia, junto con metadatos útiles para inspeccionar el resultado.
vector_store_id = "vs_abc123" # Identificador de un vector store existente
consulta_usuario = "¿Cuál es la política de devoluciones para pagos anuales?"
# Realizar una búsqueda semántica (semantic search) en el vector store
resultados = client.vector_stores.search(
vector_store_id=vector_store_id,
query=consulta_usuario,
limit=4,
)
Cada elemento de resultados.data representa un fragmento candidato junto con su puntuación de similitud, información de procedencia y el contenido textual que se podrá inyectar posteriormente en el contexto del modelo.
Opciones
Query rewriting:
La reescritura de consultas permite que el sistema transforme la pregunta original del usuario en una versión más directa y optimizada para la búsqueda semántica. Activando esta opción con rewrite_query=True en la llamada a search, el vector store genera internamente una consulta reformulada que se almacena en el campo search_query del resultado, manteniendo a la vez la pregunta original para poder comparar ambas formulaciones de la búsqueda.
En la práctica, esto ayuda cuando los usuarios escriben consultas largas, poco precisas o muy conversacionales, ya que el motor de recuperación las adapta a frases más cortas y centradas en las palabras clave semánticas más relevantes, mejorando la calidad de los fragmentos que se devuelven en el resultado.
Attribute filtering:
El filtrado por atributos permite restringir los resultados de una búsqueda a un subconjunto concreto de documentos utilizando condiciones sobre los metadatos. Estos filtros se definen en un bloque attribute_filter, donde se pueden combinar operadores de comparación como eq, gte, lte o in con operadores lógicos and y or para construir reglas más complejas sobre los atributos de los archivos.
Por ejemplo, es posible limitar la búsqueda a una región específica, a un rango de fechas o a ciertos nombres de archivo, lo que resulta especialmente útil cuando el vector store contiene información de distintos países, periodos temporales o niveles de confidencialidad y solo queremos recuperar fragmentos que cumplan unas condiciones determinadas.
Ranking:
La fase de ranking controla cómo se ordenan y filtran los fragmentos recuperados para que los más relevantes aparezcan primero. Mediante el uso de ranking_options es posible seleccionar un ranker concreto, establecer un score_threshold mínimo para descartar resultados con baja puntuación y ajustar el equilibrio entre coincidencias semánticas y coincidencias de texto cuando se utiliza búsqueda híbrida.
En búsquedas híbridas se pueden afinar pesos como hybrid_search.embedding_weight y hybrid_search.text_weight para decidir hasta qué punto se priorizan las similitudes en el espacio de embeddings frente a las coincidencias de palabras, lo que permite adaptar el comportamiento del ranking a casos de uso donde sea más importante la cercanía conceptual, la coincidencia literal o una combinación equilibrada de ambas.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Configurar file_search como herramienta para que el modelo recupere contexto automáticamente de un vector store. Realizar busquedas semánticas manuales con client.vector_stores.search para controlar los fragmentos recuperados. Aplicar query rewriting para mejorar la calidad de las consultas semánticas. Filtrar resultados por atributos y metadatos de los documentos indexados. Ajustar el ranking con score_threshold y pesos de busqueda híbrida para optimizar la relevancia.