Qué es RAG
La Generación aumentada por recuperación (RAG) es un patrón de diseño que combina un modelo generativo con un sistema de recuperación de información externo, de forma que el modelo no responde solo "con lo que sabe", sino que se apoya en documentación, datos de negocio o conocimiento corporativo actualizado en cada petición.
En lugar de reentrenar continuamente un modelo de lenguaje para que incluya todas las novedades, RAG permite conectar el modelo con una base de conocimiento que se puede actualizar de forma independiente, lo que facilita mantener las respuestas alineadas con la realidad del negocio.
En un sistema RAG, ante cada pregunta del usuario, el flujo típico es recuperar primero información relevante y después generar la respuesta basándose en ese contexto recuperado.
Esto hace que las respuestas sean más precisas, más fáciles de justificar (se puede saber de qué documentos salen) y reduce el riesgo de que el modelo invente datos que no aparecen en ninguna fuente fiable.
Un modo sencillo de visualizar RAG es pensar en un diálogo entre tres piezas:
-
El usuario plantea una pregunta en lenguaje natural.
-
Un componente de búsqueda encuentra los fragmentos de información más relevantes en los datos de la organización.
-
El modelo de lenguaje utiliza la pregunta y esos fragmentos como contexto para redactar una respuesta clara y estructurada.
Esta idea es aplicable a muchos dominios: documentación técnica, manuales de producto, bases de conocimiento de soporte, normativa interna, catálogos de productos o incluso repositorios de código.
La clave es que el modelo ya no responde "en abstracto", sino anclado a fuentes de datos concretas.
Arquitectura RAG
A nivel conceptual, una arquitectura RAG suele descomponerse en varios bloques bien diferenciados que trabajan en cadena, aunque en la práctica se puedan empaquetar o delegar en servicios gestionados.
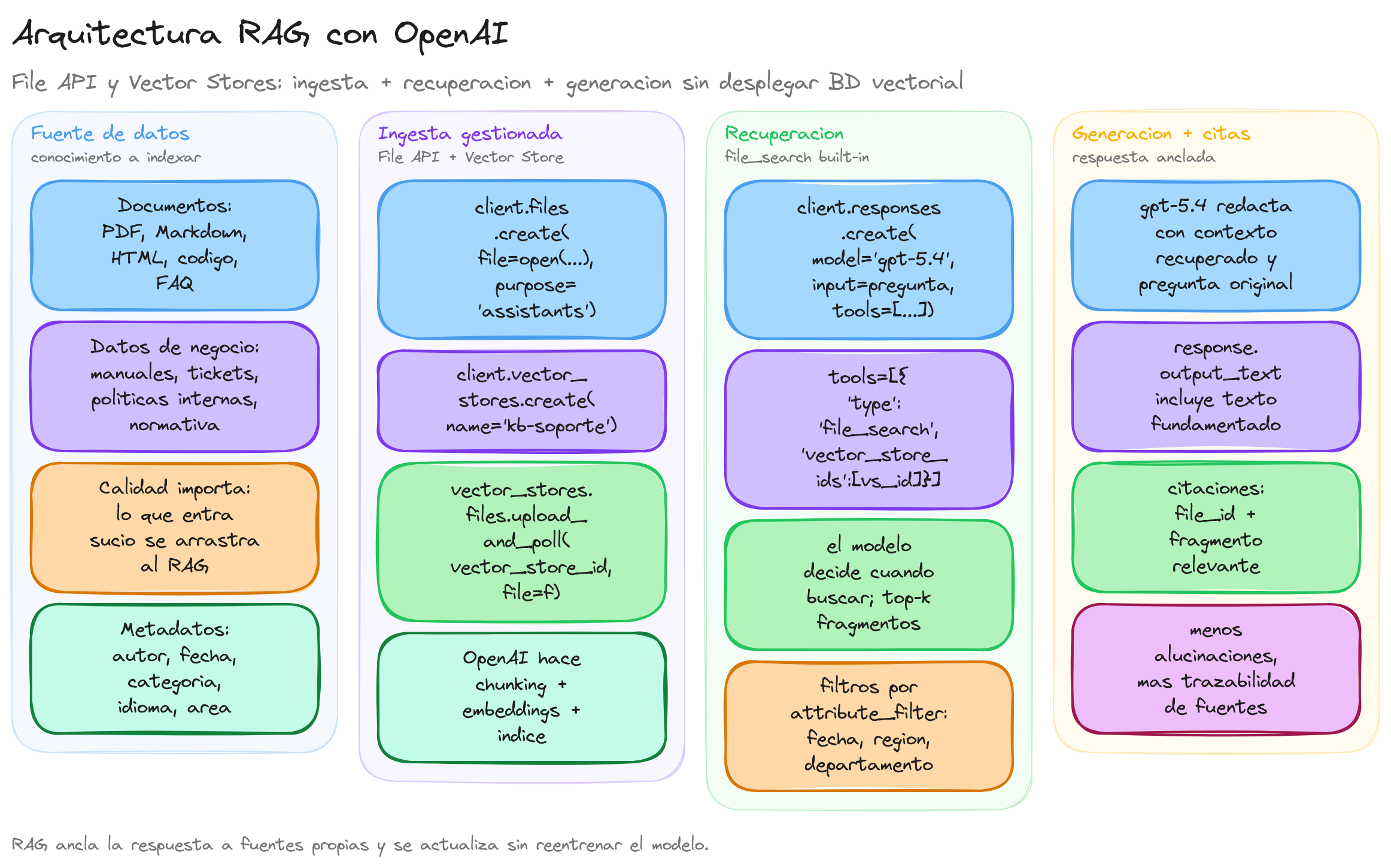
El diagrama muestra la versión gestionada que proporciona OpenAI con File API, Vector Stores y la built-in tool file_search. La fase de ingesta sube documentos con files.create, los asocia a un Vector Store que se encarga del chunking y el embedding, y la fase de consulta se resuelve con una sola llamada a responses.create que incluye file_search como tool.
Con esta arquitectura el desarrollador se despreocupa del chunking, los embeddings y la búsqueda vectorial: todo ocurre dentro de la plataforma. El código cliente solo declara la tool y el vector_store_id.
Entender estos bloques ayuda a diseñar soluciones más mantenibles y a localizar mejor los problemas cuando algo no funciona como se espera.
- 1. Fuente de datos
Los datos de partida pueden ser documentos (PDF, HTML, Markdown), registros de bases de datos, artículos de una intranet, tickets de soporte o cualquier repositorio de conocimiento corporativo.
En esta fase interesa pensar en calidad, formato y frecuencia de actualización de la información, porque todo lo que no esté bien preparado aquí se arrastrará al resto del sistema.
- 2. Ingesta y preparación
Antes de poder recuperar contenido de forma eficaz, suele ser necesario limpiar, normalizar y en muchos casos trocear los documentos en fragmentos manejables (por ejemplo, párrafos o secciones).
En esta etapa también se decide qué metadatos interesa conservar (autor, fecha, categoría, idioma, área de negocio), ya que después podrán utilizarse para filtrar resultados.
- 3. Representación y almacenamiento
En RAG moderno es habitual representar cada fragmento de texto mediante un embedding, es decir, un vector numérico que captura su significado semántico.
Estos vectores se almacenan normalmente en un almacenamiento vectorial, que puede ser una base de datos especializada o un servicio gestionado, para poder buscar después por similitud semántica.
- 4. Recuperación en tiempo de consulta
Cuando llega una pregunta, se genera también una representación vectorial de la consulta y se buscan los fragmentos más cercanos en el espacio vectorial.
Adicionalmente se pueden aplicar filtros por metadatos (por ejemplo, por idioma, producto o departamento) para limitar los resultados a lo realmente relevante para ese caso de uso concreto.
- 5. Composición del contexto
Con los fragmentos recuperados se construye un contexto que se entregará al modelo junto con la pregunta del usuario.
Aquí se decide cuánto texto se incluye, en qué orden y con qué formato, equilibrando entre "dar suficiente información" y no superar las ventanas de contexto de los modelos.
- 6. Generación y postprocesado
Finalmente, el modelo de lenguaje recibe la pregunta y el contexto y genera una respuesta.
En muchos sistemas profesionales se añade una capa de postprocesado para enriquecer el resultado, por ejemplo añadiendo referencias a los documentos utilizados, adaptando el tono o generando varias variantes de salida (resumen ejecutivo, respuesta técnica detallada, borrador de email, etc.).
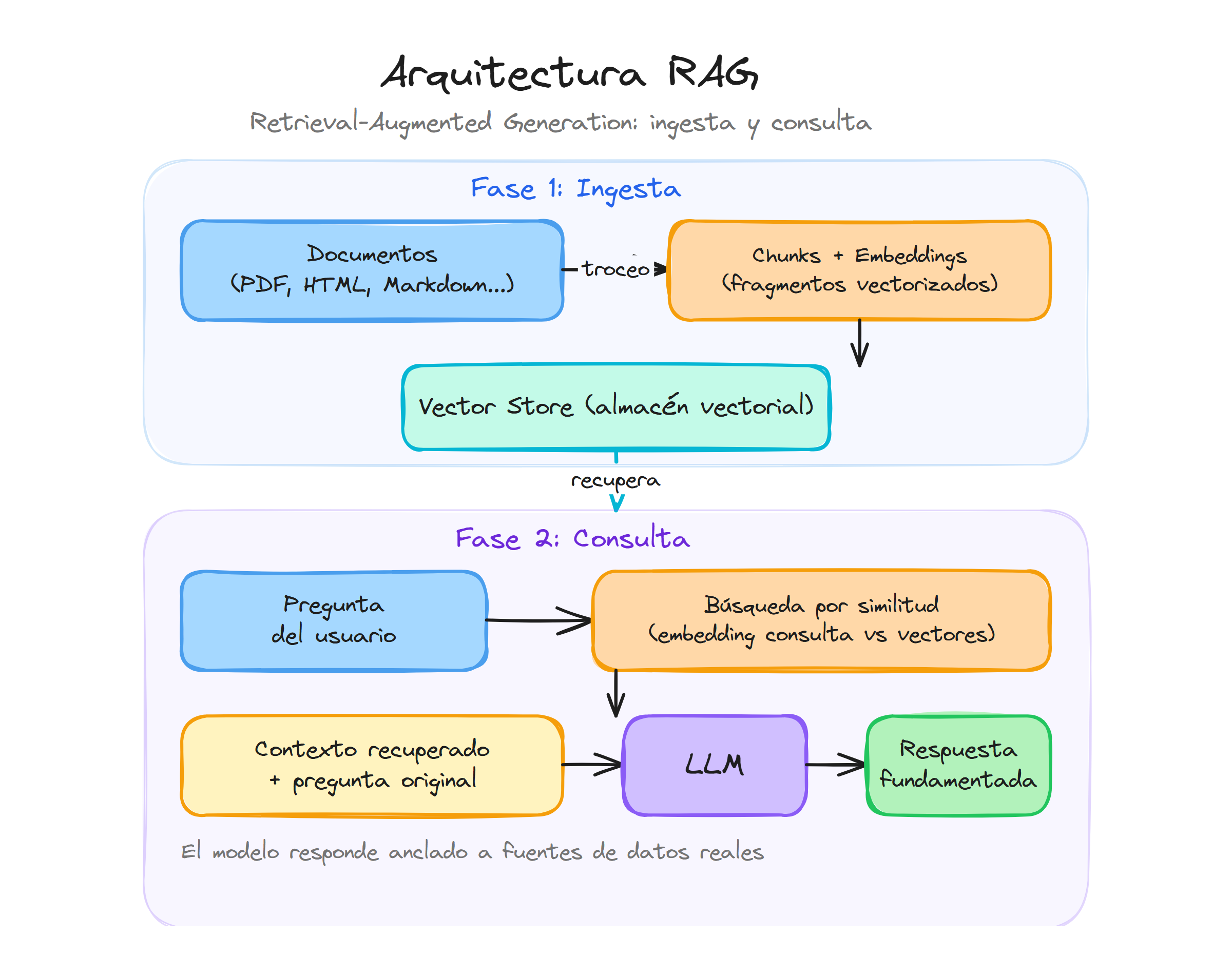
Podemos imaginar el flujo completo como un diagrama lineal:
-
datos brutos -> ingesta y limpieza -> embeddings y almacenamiento vectorial
-
usuario pregunta -> recuperación -> montaje del contexto -> generación de respuesta
RAG gestionado por OpenAI
Implementar RAG desde cero implica tomar muchas decisiones: elegir o desplegar una base de datos vectorial, diseñar el proceso de ingesta, mantener índices, gestionar escalabilidad y seguridad, entre otros aspectos.
Para simplificar este escenario, OpenAI ofrece capacidades de RAG gestionado que abstraen gran parte de esa complejidad y permiten centrarse en el diseño de la experiencia de usuario.
En este contexto, hay dos componentes clave que conviene conocer desde un punto de vista conceptual:
API File
La API de ficheros permite subir y gestionar archivos que servirán como base de conocimiento: documentos de producto, manuales internos, especificaciones técnicas, FAQs o datos estructurados serializados.
Estos ficheros se asocian a distintos usos (por ejemplo, como entrada para creación de almacenes vectoriales, para tareas de evaluación o para otros flujos internos de la plataforma).
A nivel conceptual, se puede pensar en la API File como la puerta de entrada de la información al ecosistema gestionado de OpenAI.
API Vector Stores
El servicio de almacenes vectoriales de OpenAI permite crear y gestionar colecciones de documentos indexados semánticamente sin tener que desplegar ni administrar una base de datos vectorial propia.
Estos almacenes se encargan de generar y almacenar los embeddings de los fragmentos de texto, mantener los índices de búsqueda y ofrecer operaciones de recuperación eficientes y escalables.
Desde el punto de vista de un sistema RAG, un vector store gestionado actúa como el núcleo de la fase de recuperación.
La combinación de la API File y la API Vector Stores hace posible construir un flujo de RAG en el que:
-
Los datos se suben y se organizan a través de ficheros.
-
Esos datos se indexan automáticamente en uno o varios almacenes vectoriales.
-
Las aplicaciones pueden recuperar contextos relevantes para las consultas de los usuarios sin conocer los detalles internos de cómputo y almacenamiento.
Esta aproximación da lugar a un modelo de "RAG como servicio", en el que gran parte del trabajo pesado (cálculo de embeddings, mantenimiento de índices, replicación, escalado, etc.) recae en la plataforma de OpenAI.
El equipo de desarrollo puede centrarse así en definir qué datos son relevantes, cómo se actualizan, qué políticas de acceso se aplican y qué tipo de respuestas se espera del sistema.
En las siguientes lecciones del módulo se verá con más detalle cómo se utilizan estas APIs para crear almacenes vectoriales, cómo se relacionan con las consultas de los usuarios y cómo se conectan con los modelos de lenguaje para construir soluciones RAG completas orientadas a casos de uso reales.
Para un mayor grado de personalización los equipos de GenAI suelen desplegar sus propias bases de datos vectoriales usando ChromaDB, QDrant, Milvus, FAISS, etc y gestionar todo el proceso RAG, pero es más costoso.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Comprender qué es RAG y por qué mejora las respuestas de un modelo de lenguaje. Identificar los bloques de una arquitectura RAG: fuente de datos, ingesta, embeddings, recuperación y generación. Entender el papel de los embeddings y los almacenes vectoriales en la búsqueda semántica. Conocer la API File y la API Vector Stores de OpenAI como solución de RAG gestionado. Comparar RAG gestionado frente a desplegar bases de datos vectoriales propias.