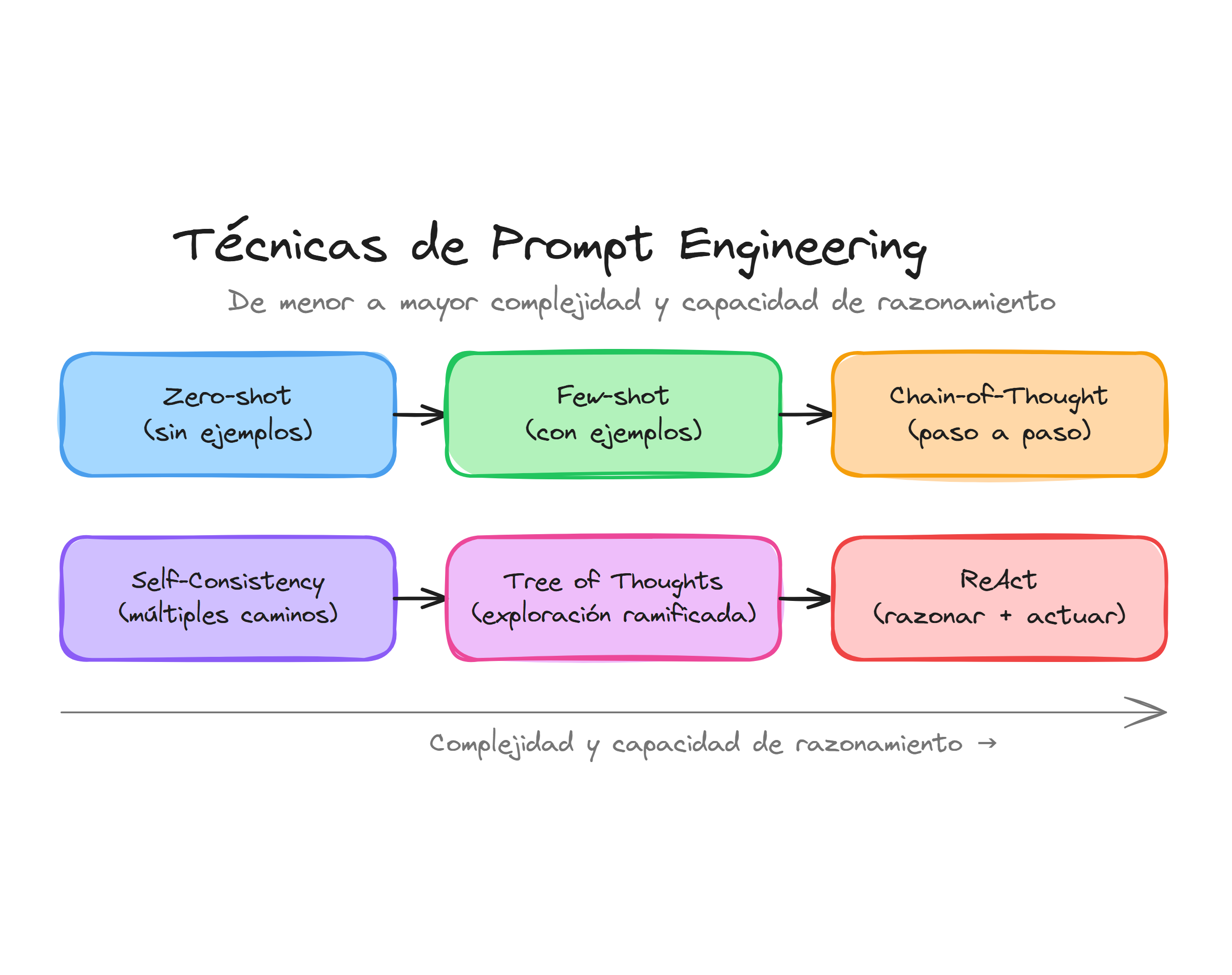
Técnica zero-one-few shot
La técnica shot hace referencia a la cantidad de ejemplos que proporcionamos al modelo antes de solicitar la tarea real. Esta aproximación resulta fundamental cuando queremos que el modelo identifique patrones o siga un formato específico sin necesidad de entrenamiento adicional.
Zero-shot: sin ejemplos
En zero-shot, confiamos completamente en el conocimiento previo del modelo. Proporcionamos solo la instrucción, sin ejemplos que ilustren cómo debe comportarse la respuesta.
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "user", "content": """
Clasifica el siguiente comentario como positivo, negativo o neutral:
"El producto llegó rápido pero la calidad no es la esperada"
"""}
]
)
print(response.choices[0].message.content)
Esta aproximación funciona bien cuando la tarea es clara y común (traducción, clasificación básica, resúmenes). El modelo puede inferir qué se espera de él basándose en su entrenamiento general.
One-shot: un ejemplo
Con one-shot proporcionamos un único ejemplo que ilustra el formato o estilo esperado. Esto ayuda al modelo a comprender mejor nuestras expectativas.
messages = [
{"role": "user", "content": """
Extrae información estructurada de descripciones de productos.
Ejemplo:
Entrada: "iPhone 14 Pro 256GB en color negro, precio 1200 euros"
Salida: {"producto": "iPhone 14 Pro", "capacidad": "256GB", "color": "negro", "precio": 1200}
Ahora extrae:
"Samsung Galaxy S23 128GB en color blanco, precio 899 euros"
"""}
]
El modelo puede identificar el patrón estructural y aplicarlo a la nueva entrada, manteniendo consistencia en el formato de salida.
Para salidas estructuradas con JSON solemos además especificar un modelo schema para validar que la respuesta del LLM se adhiere al esquema solicitado.
Few-shot: múltiples ejemplos
Few-shot proporciona varios ejemplos que permiten al modelo identificar patrones más complejos o casos especiales. Es la técnica más efectiva cuando necesitamos comportamientos específicos.
messages = [
{"role": "user", "content": """
Corrige errores gramaticales manteniendo el tono informal:
Entrada: "ayer fui al super y compre leche"
Salida: "Ayer fui al súper y compré leche"
Entrada: "no se porque no funciona mi ordenador"
Salida: "No sé por qué no funciona mi ordenador"
Entrada: "hola que tal estas como te llamas"
Salida: "Hola, ¿qué tal estás? ¿Cómo te llamas?"
Ahora corrige:
"hola me gustaria saber si podrias ayudarme con esto"
"""}
]
La cantidad óptima de ejemplos depende de la complejidad de la tarea. Generalmente, entre 2 y 5 ejemplos son suficientes, pero dependen de la tarea.
Dependiendo del número de ejemplos se puede decir que:
- zero-shot: sin ejemplos
- one-shot: con un ejemplo
- few-shot: con varios ejemplos, habitualmente entre dos y cinco
- multi-shot: término intercambiable con few-shot, aunque suele referirse cuando se trata de 10 ejemplos o más
Técnica chain of thought
Chain of thought (CoT) consiste en solicitar al modelo que muestre su razonamiento paso a paso antes de proporcionar la respuesta final. Esta técnica mejora significativamente el rendimiento en tareas que requieren lógica, matemáticas o análisis complejo.
CoT básico
La forma más simple es añadir instrucciones explícitas para que el modelo muestre su proceso de pensamiento:
messages = [
{"role": "user", "content": """
Resuelve el siguiente problema mostrando tu razonamiento paso a paso:
Una tienda ofrece un 20% de descuento en una compra de 150€.
Además, tienes un cupón de 10€ adicionales.
¿Cuánto pagas finalmente?
Piensa paso a paso antes de responder.
"""}
]
El modelo desglosará el problema:
- Calcula el 20% de 150€
- Resta ese descuento del total
- Aplica el cupón de 10€
- Proporciona el resultado final
CoT con few-shot
Combinar chain of thought con ejemplos produce los mejores resultados. Mostramos al modelo cómo queremos que razone:
messages = [
{"role": "user", "content": """
Resuelve problemas matemáticos mostrando el proceso:
P: Si tengo 15 manzanas y doy 1/3 a mi amigo, ¿cuántas me quedan?
R: Primero calculo 1/3 de 15: 15 ÷ 3 = 5 manzanas
Luego resto: 15 - 5 = 10 manzanas
Respuesta: Me quedan 10 manzanas
Ahora resuelve:
P: Un libro cuesta 24€. Si su precio aumenta un 25% y luego se aplica un 10% de descuento, ¿cuál es el precio final?
"""}
]
Esta técnica es especialmente útil en debugging de código, análisis de requisitos o toma de decisiones donde el proceso de razonamiento es tan importante como la respuesta final.
Tree of thoughts
Tree of Thoughts (ToT) es una extensión de chain of thought que explora múltiples caminos de razonamiento en paralelo, similar a un árbol de decisiones. En lugar de seguir una única cadena de pensamiento, el modelo genera varias ramas alternativas, las evalúa y selecciona las más prometedoras.
Esta técnica resulta valiosa cuando existen múltiples aproximaciones válidas a un problema y no está claro de antemano cuál será la mejor. Por ejemplo, en problemas de optimización, diseño de arquitecturas software o planificación de proyectos.
messages = [
{"role": "user", "content": """
Diseña una arquitectura para una aplicación de mensajería en tiempo real.
Explora tres enfoques diferentes:
Enfoque 1: Arquitectura basada en WebSockets
- Ventajas:
- Desventajas:
- Casos de uso ideales:
Enfoque 2: Arquitectura basada en Server-Sent Events
- Ventajas:
- Desventajas:
- Casos de uso ideales:
Enfoque 3: Arquitectura híbrida con polling largo
- Ventajas:
- Desventajas:
- Casos de uso ideales:
Después de analizar cada rama, recomienda cuál es la mejor para un sistema con 100.000 usuarios concurrentes.
"""}
]
El coste de implementar ToT es mayor (requiere más tokens y tiempo), pero proporciona análisis más completos al considerar múltiples perspectivas antes de llegar a una conclusión.
Modelos razonadores con CoT nativo
Los modelos de lenguaje modernos han evolucionado para incorporar capacidades de razonamiento interno mediante test-time computing, donde dedican tiempo computacional adicional durante la inferencia para razonar sobre el problema antes de responder.
A diferencia de implementar CoT manualmente en el prompt, los modelos actuales de OpenAI (como GPT-5 y GPT-5.1) y Anthropic (Claude con Extended Thinking) permiten activar el razonamiento mediante parámetros, en lugar de tener líneas de modelos completamente separadas.
Control del razonamiento mediante parámetros
Los proveedores actuales ofrecen un parámetro para controlar el esfuerzo de razonamiento que el modelo debe aplicar:
# API chat completions:
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "user", "content": """
Un libro cuesta 24€. Si su precio aumenta un 25% y luego se aplica un 10% de descuento, ¿cuál es el precio final?
"""}
],
reasoning_effort="high" # Opciones: "low", "medium", "high"
)
# API responses moderna
response = client.responses.create(
model="gpt-5.4",
input="How much gold would it take to coat the Statue of Liberty in a 1mm layer?",
reasoning={
"effort": "none"
}
)
El parámetro reasoning_effort determina cuánto tiempo computacional dedica el modelo al razonamiento interno:
- none: para evitar razonamiento
- minimal: para reducir razonamiento al mínimo
- low: Respuesta rápida con razonamiento mínimo, similar a modelos estándar
- medium: Balance entre velocidad y profundidad de razonamiento
- high: Razonamiento exhaustivo para problemas complejos
Anthropic ofrece funcionalidad similar con su parámetro de Extended Thinking en modelos Claude, permitiendo controlar la profundidad del pensamiento según la complejidad de la tarea.
¿Cuándo usar razonamiento interno vs CoT manual?
Usa razonamiento interno (reasoning_effort) cuando:
- Necesitas máxima precisión en matemáticas, lógica o análisis complejo
- Trabajas con problemas de programación competitiva o algoritmos
- Requieres planificación o razonamiento científico riguroso
- El coste y latencia adicionales son aceptables
Usa CoT manual cuando:
- Necesitas velocidad de respuesta y el problema no es extremadamente complejo
- Quieres control total sobre el proceso de razonamiento
- Deseas ver explícitamente los pasos intermedios
- Trabajas con presupuestos ajustados (el razonamiento interno es más costoso)
En la práctica, para la mayoría de tareas cotidianas el CoT manual sigue siendo efectivo y más económico. Reserva el razonamiento interno para situaciones donde la precisión es crítica y el coste adicional se justifica por la importancia del problema.
Técnica self-consistency
Self-consistency mejora la fiabilidad de las respuestas generando múltiples soluciones para el mismo problema y seleccionando la más frecuente. Esta técnica funciona excepcionalmente bien con chain of thought.
Implementación práctica
El proceso consiste en generar varias respuestas independientes y analizar cuál aparece con mayor frecuencia o coherencia:
from collections import Counter
def self_consistency_query(prompt, n=5):
client = OpenAI()
responses = []
for _ in range(n):
response = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7 # Mayor temperatura para diversidad
)
responses.append(response.choices[0].message.content)
return responses
# Ejemplo de uso
prompt = """
Resuelve paso a paso:
Si un tren viaja a 120 km/h durante 2.5 horas, ¿qué distancia recorre?
"""
responses = self_consistency_query(prompt, n=3)
for i, resp in enumerate(responses, 1):
print(f"Respuesta {i}:\n{resp}\n")
Esta técnica es útil cuando la precisión es crítica y podemos permitirnos múltiples llamadas a la API. El coste adicional se compensa con mayor confiabilidad en las respuestas.
Cuándo usar self-consistency
- Cálculos complejos donde un error puede ser costoso
- Análisis de código crítico para producción
- Toma de decisiones importantes basadas en IA
- Validación de información sensible
Técnica reflection
Reflection pide al modelo que critique y mejore su propia respuesta. Esta técnica implementa un ciclo de revisión automática que incrementa la calidad del resultado final.
Reflection en dos pasos
La forma más directa es generar una respuesta y luego solicitar al modelo que la revise:
# Paso 1: Respuesta inicial
messages = [
{"role": "user", "content": """
Escribe una función Python que valide direcciones de email.
"""}
]
response1 = client.chat.completions.create(
model="gpt-5.4",
messages=messages
)
initial_answer = response1.choices[0].message.content
# Paso 2: Reflexión y mejora
messages.append({"role": "assistant", "content": initial_answer})
messages.append({"role": "user", "content": """
Revisa el código anterior e identifica:
1. Posibles casos límite no contemplados
2. Mejoras en seguridad o rendimiento
3. Problemas de validación
Luego proporciona una versión mejorada.
"""})
response2 = client.chat.completions.create(
model="gpt-5.4",
messages=messages
)
print(response2.choices[0].message.content)
Reflection en un único prompt
Para reducir llamadas a la API, podemos solicitar reflexión en el prompt inicial:
messages = [
{"role": "user", "content": """
Escribe una función Python para validar emails.
Después de escribirla, revísala críticamente e identifica mejoras.
Finalmente, proporciona la versión mejorada.
"""}
]
Esta técnica funciona bien en generación de código, redacción de documentación o análisis técnico donde una revisión adicional mejora significativamente el resultado.
Técnica reAct
ReAct (Reasoning + Acting) combina razonamiento y acción en un ciclo iterativo. El modelo alterna entre pensar sobre el problema y ejecutar acciones concretas (como llamar APIs, buscar información o ejecutar código) hasta alcanzar la solución.
Estructura ReAct
El patrón básico sigue este ciclo:
- Thought: El modelo razona sobre qué hacer a continuación
- Action: Ejecuta una acción específica
- Observation: Observa el resultado de la acción
- Repite hasta resolver el problema
messages = [
{"role": "user", "content": """
Necesito analizar el rendimiento de una API REST. Sigue este proceso:
Thought: ¿Qué información necesito primero?
Action: Listar los endpoints disponibles
Observation: [El usuario proporcionará la lista]
Thought: ¿Qué métricas debo analizar?
Action: Solicitar tiempos de respuesta de cada endpoint
Observation: [El usuario proporcionará los datos]
Thought: ¿Cómo interpretar los resultados?
Action: Generar recomendaciones de optimización
Usa este patrón para ayudarme a optimizar mi API.
"""}
]
ReAct con herramientas
El verdadero valor de ReAct emerge cuando el modelo puede ejecutar acciones reales. Esto se implementa típicamente con sistemas de funciones o herramientas:
tools = [
{
"type": "function",
"function": {
"name": "buscar_documentacion",
"description": "Busca información en la documentación técnica",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Término de búsqueda"}
}
}
}
},
{
"type": "function",
"function": {
"name": "ejecutar_codigo",
"description": "Ejecuta código Python y devuelve el resultado",
"parameters": {
"type": "object",
"properties": {
"codigo": {"type": "string", "description": "Código Python a ejecutar"}
}
}
}
}
]
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "user", "content": "Calcula el promedio de [45, 67, 23, 89, 12] y busca cómo optimizar el cálculo"}
],
tools=tools
)
El modelo decide qué herramienta usar y cuándo, alternando entre razonamiento y acción hasta completar la tarea. Esta técnica es fundamental en agentes autónomos y sistemas complejos que integran múltiples capacidades.
La técnica reAct es habitual implementarla usando frameworks de Agentes de IA, como es el caso de OpenAI Agents SDK, LangChain-LangGraph, CrewAI, para no tener que lidiar manualmente con el bucle de procesar llamadas y respuestas a las tools.
Aplicaciones de ReAct
- Agentes de investigación: Buscar información, analizarla y generar informes
- Asistentes de desarrollo: Leer código, ejecutar tests, proponer correcciones
- Automatización de tareas: Descomponer objetivos complejos en acciones secuenciales
- Análisis de datos: Cargar datos, procesarlos, visualizarlos y extraer conclusiones
La combinación de estas técnicas según el contexto específico permite maximizar el rendimiento de los modelos de lenguaje, obteniendo respuestas más precisas, confiables y adaptadas a nuestras necesidades.

Alan Sastre
Ingeniero de Software y formador, CEO en CertiDevs
Ingeniero de software especializado en Full Stack y en Inteligencia Artificial. Como CEO de CertiDevs, OpenAI SDK es una de sus áreas de expertise. Con más de 15 años programando, 6K seguidores en LinkedIn y experiencia como formador, Alan se dedica a crear contenido educativo de calidad para desarrolladores de todos los niveles.
Más tutoriales de OpenAI SDK
Explora más contenido relacionado con OpenAI SDK y continúa aprendiendo con nuestros tutoriales gratuitos.
Aprendizajes de esta lección
Dominar las técnicas zero-shot, one-shot y few-shot para guiar al modelo con ejemplos. Aplicar chain of thought y tree of thoughts para mejorar el razonamiento del modelo paso a paso. Comprender cuándo usar razonamiento interno del modelo frente a CoT manual en los prompts. Implementar self-consistency y reflection para obtener respuestas más fiables y de mayor calidad. Utilizar el patrón reAct para combinar razonamiento y acciones con herramientas externas.
Cursos que incluyen esta lección
Esta lección forma parte de los siguientes cursos estructurados con rutas de aprendizaje